数据湖的概念以及解决方案
今天这篇文章主要介绍数据湖(data lake)的定义,其次介绍各大云厂商的解决方案以及目前的开源解决方案。
定义
看下维基百科的定义:数据湖是一个以原始格式(通常是对象块或文件)存储数据的系统或存储库。数据湖通常是所有企业数据的单一存储。用于报告、可视化、高级分析和机器学习等任务。数据湖可以包括来自关系数据库的结构化数据(行和列)、半结构化数据(CSV、日志、XML、JSON)、非结构化数据(电子邮件、文档、pdf)和二进制数据(图像、音频、视频)。定义中的重点内容我用红色字体标注出来,简单说明一下这几点。
- 原始格式:数据不做预处理,保存数据的原始状态
- 单一存储:存储库中会汇总多种数据源,是一个单一库
- 用于机器学习:除了 BI 、报表分析,数据湖更适用于机器学习
数据湖并不是新概念,最早 2015 年就被提出来了,可以看到数据湖经常被拿来跟目前的数据仓库作比较。下面是谷歌搜到的一篇比较早的数据湖和数据仓库对比的文章

至于为什么数据湖慢慢走近大家的视野,并且越来越多的跟仓库作比较。我认为主要是跟机器学习的广泛应用有很大关系。
数据湖和数据仓库的对比
大数据刚兴起的时候,数据主要用途是 BI 、报表、可视化。因此数据需要是结构化的,并且需要 ETL 对数据进行预处理。这个阶段数据仓库更适合完成这样的需求,所以企业大部分需要分析的数据都集中到数据仓库中。而机器学习的兴起对数据的需求更加灵活,如果从数据仓库中提数会有一些问题。比如:数据都是结构化的;数据是经过处理的可能并不是算法想要的结果;算法同学与数仓开发同学沟通成本较大等。我在工作中就遇到这种情况,做算法的同学需要经常理解我们的数仓模型,甚至要深入到做了什么业务处理,并且我们的处理可能并不是他们的想要的。基于上面遇到的各种问题,数据湖的概念应运而生。下面的表格对比一下数据湖和数据仓库的区别,主要来自 AWS 。

从以上表格的区别上我们可以看到数据湖的应用场景主要在于机器学习,并且在用的时候再建 Schema 更加灵活。虽然数据湖能够解决企业中机器学习应用方面的数据诉求,可以与数据仓库团队解耦。但并不意味着数据湖可以取代数据仓库,数据仓库在高效的报表和可视化分析中仍有优势。
云厂商的解决方案
近几年云计算的概念也是非常火,各大云厂商自然不会错失数据湖的解决方案。下面简单介绍阿里云、AWS 和 Azure 分别的数据产品。
- 阿里云:Data Lake Analytics,通过标准JDBC直接对阿里云OSS,TableStore,RDS,MongoDB等不同数据源中存储的数据进行查询和分析。DLA 无缝集成各类商业分析工具,提供便捷的数据可视化。阿里云OSS 可以存储各种结构化、半结构化、非结构化的数据,可以当做一个数据湖的存储库。DLA 使用前需要创建 Schema 、定义表,再进行后续分析。
- AWS:Lake Formation,可以识别 S3 或关系数据库和 NoSQL 数据库中存储的现有数据,并将数据移动到 S3 数据湖中。使用 EMR for Apache Spark(测试版)、Redshift 或 Athena 进行分析。支持的数据源跟阿里云差不多。
- Azure:Azure Data Lake Storage,基于 Azure Blob 存储构建的高度可缩放的安全 Data Lake 功能,通过 Azure Databricks 对数据湖中的数据进行处理、分析。但文档中并没有看到支持其他数据源的说明
开源解决方案
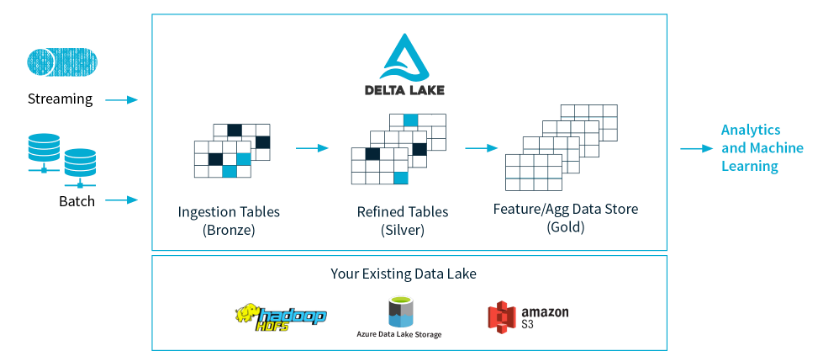
除了云厂商提供的方案外, 还有一个开源解决方案——kylo 。这个框架的关注度并不高,社区不是很活跃。大概看了下官网的介绍视频,基本上与云厂商的解决方案一致。支持多种数据源,分析时创建 Schema。另外,Databricks 团队(开源 Spark 框架)年初开源了 Delta lake 框架, Delta lake 是存储层,为数据湖带来了可靠性。Delta Lake 提供 ACID 事务、可伸缩的元数据处理,并统一流和批数据处理。Delta Lake运行在现有数据湖之上,与Apache Spark api完全兼容。架构图如下:
小结
今天这篇文章主要介绍了数据湖的概念,以及数据湖与数据仓库的区别,然后简单了解了目前数据湖在云厂商和开源软件中的解决方案。作为数仓建设和数据开发人员要密切关注这种新的概念,如果我们的工作中遇到这种问题我们也可以思考是否可以推动数据湖的建设。另外,作为中小企业上云的方案可能是一个比较好的选择,毕竟开源解决方案目前不是很成熟,社区还不是很强大。
公众号「渡码」,分享更多高质量内容


 浙公网安备 33010602011771号
浙公网安备 33010602011771号