代替解密方法交流
一:看密文文件,这是我的密文文件。
QurgrgwemousswcwkionwbridVurxiubvkixjxgmubmpurpybswektubfpyooierrwxgbikiftgmpvwwbwprmvkupgwsmpmbmruibmkpremrwftgmpsemqbwzrwbpucwmrrwbruibUrxmboeicuswbwqpwxyeurtrwxgbikifuwpdiedubmbxumkpwxyeurtvtcuerywidswxwbremkulmruibsmrmueewcwepuvukurtmbsoeifemnnmvukurtGiqwcwergwxinokwzmkfieurgnpidvkixjxgmubmewgufgktubrwbpucwmbsrgwewmewnmbtjubspidmrrmxjprgmrbwwsrivwswrwxrwsmbsoewcwbrwsqgukwdubmbxumkpwecuxwpmewrgwjwtrmefwrpidbwrqiejmrrmxjpRgwmookuxmruibidvkixjxgmubrwxgbikiftqukkubwcurmvktveubfbwqpwxyeurtrgewmrprirgwdubmbxumkpwxriembsoipwbwqxgmkkwbfwprirgwpwxyeurtiddubmbxumkbwrqiejpUbieswerifymembrwwrgwpwxyeurtiddubmbxumkptprwnpvmpwsibvkixjxgmubrwxgbikifturupyefwbrrixmeetiyrewpwmexgibrgwswrwxruibmbsoewcwbruibidmrrmxjvwgmcuiemfmubprrgwubrwfemruibiddubmbxumkptprwnpewoewpwbrwsvtrgwPQUDRptprwnmbsvkixjxgmubRgwnmubewpwmexgriouxpubxkysw:cykbwemvukurtmbmktpupmbsmrrmxjvwgmcuieswrwxruibidPQUDRptprwnmrrmxjvwgmcuieswrwxruibmbsoewcwbruibidvkixjxgmubptprwnpwxyeurtmbmktpupmbsmrrmxj-swdwbpwcweuduxmruibidPQUDRptprwnvmpwsibvkixjxgmubRgwoeihwxrgmpunoiermbrrgwiewruxmkpufbuduxmbxwmbsxkwmemookuxmruiboeipowxrpUrupwzowxrwsripikcwrgwpwxyeurtoeivkwnidrgwubrwfemruibidvkixjxgmubrwxgbikiftmbsPQUDRptprwnpgwkodykriprewbfrgwbxinokumbxwewayuewnwbrpdieubrwebmruibmkxeipp-viesweomtnwbrppyxgmpomtnwbrpwxyeurtmbru-nibwtkmybsweubfmbsmbru-rweeieupndubmbxubfmbswddwxrucwibpmdwfymesubfrgwpwxyeurtidrgwdubmbxumkptprwnqguxgmewidfewmrpufbuduxmbxwrinmubrmububfrgwpwxyeurtmbsprmvukurtidiyexiybretpbwrqiejp
拿到密文,首先是统计文件中字母出现的频率
1:统计字符出现频率 的代码。如下:
#计算字母的出现频率 file = open("miwen","r",encoding="UTF-8") sum = [0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,] #创建list 第0 个存放总数 1-26 分别记录a-z 出现的次数 flag = 0 def calculate(): global flag while flag < 30: data_char = file.read(1) # print(data_char) if len(data_char) == 0: flag +=1 continue elif ord(data_char) in range(ord("a"),ord("z")): data_char = ord(data_char) - 96 sum[data_char] += 1 sum[0] += 1 elif ord (data_char) in range (ord ("A"), ord ("Z")): data_char = ord(data_char) - 64 sum[data_char] +=1 sum[0] +=1 else: pass calculate() for i in sum: print(i) file.close()
我没有计算出百分比,sum[0]存放了总的字符数,用各个直接除以num【0】即可得到百分比。
统计结果为:
1454
1
126
19
40
83
27
55
1
96
19
53
1
125
24
27
90
16
148
40
41
127
27
163
80
25
0
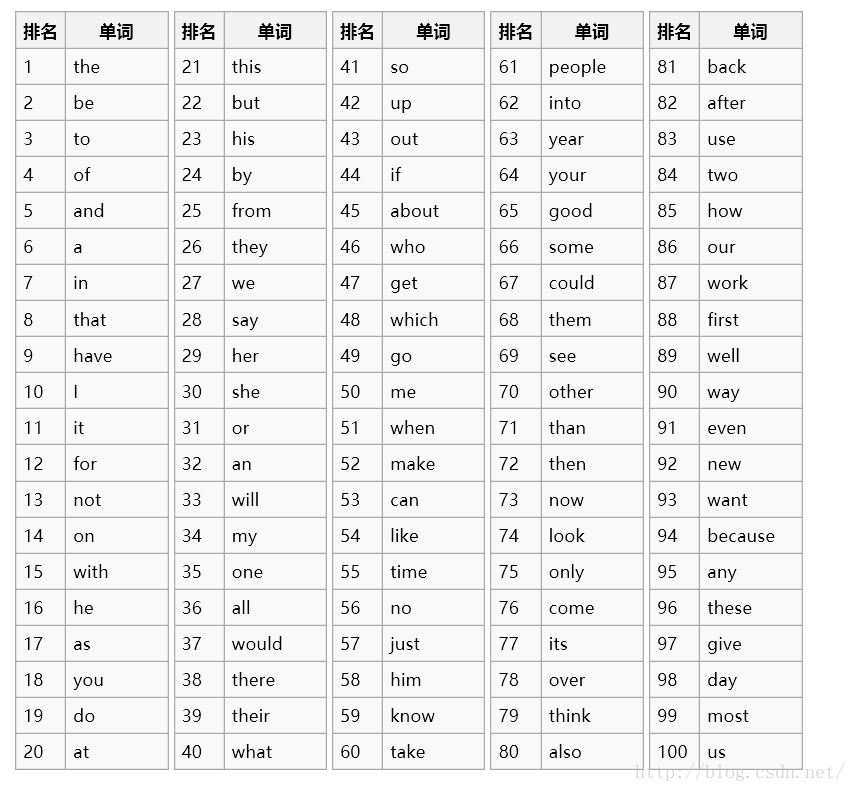
大数据测试的字母出现频率为:
e 16782 11.42% 11991 64.52% a 12574 8.56% 10050 54.08% i 11674 7.94% 9364 50.39% r 11042 7.51% 9337 50.24% t 10959 7.46% 8929 48.05% o 10466 7.12% 8259 44.44% n 9413 6.41% 7948 42.77% s 8154 5.55% 6859 36.91% l 8114 5.52% 6882 37.03% c 6968 4.74% 6028 32.44% u 5373 3.66% 4910 26.42% p 4809 3.27% 4283 23.05% m 4735 3.22% 4241 22.82% d 4596 3.13% 4186 22.52% h 4058 2.76% 3724 20.04% g 3380 2.30% 3061 16.47% b 3121 2.12% 2918 15.70% y 2938 2.00% 2815 15.15% f 2157 1.47% 1899 10.22% v 1574 1.07% 1531 8.24% w 1388 0.94% 1328 7.15% k 1235 0.84% 1183 6.37% x 507 0.35% 505 2.72% z 356 0.24% 309 1.66% q 343 0.23% 343 1.85% j 220 0.15% 217 1.17% 作为单词首字母出现频率较高的字母依次是: S, P, C, D, M, A... #
常见单词表为:
从上面的三个频率表我们很快可以确定:
w 对应 e
g 对应 h
r 对应 t
之后几乎没有思路:即进行第二步:
二: 找 字符串,(借助word 工具)
如图是字符串ptprwn 出现的次数。
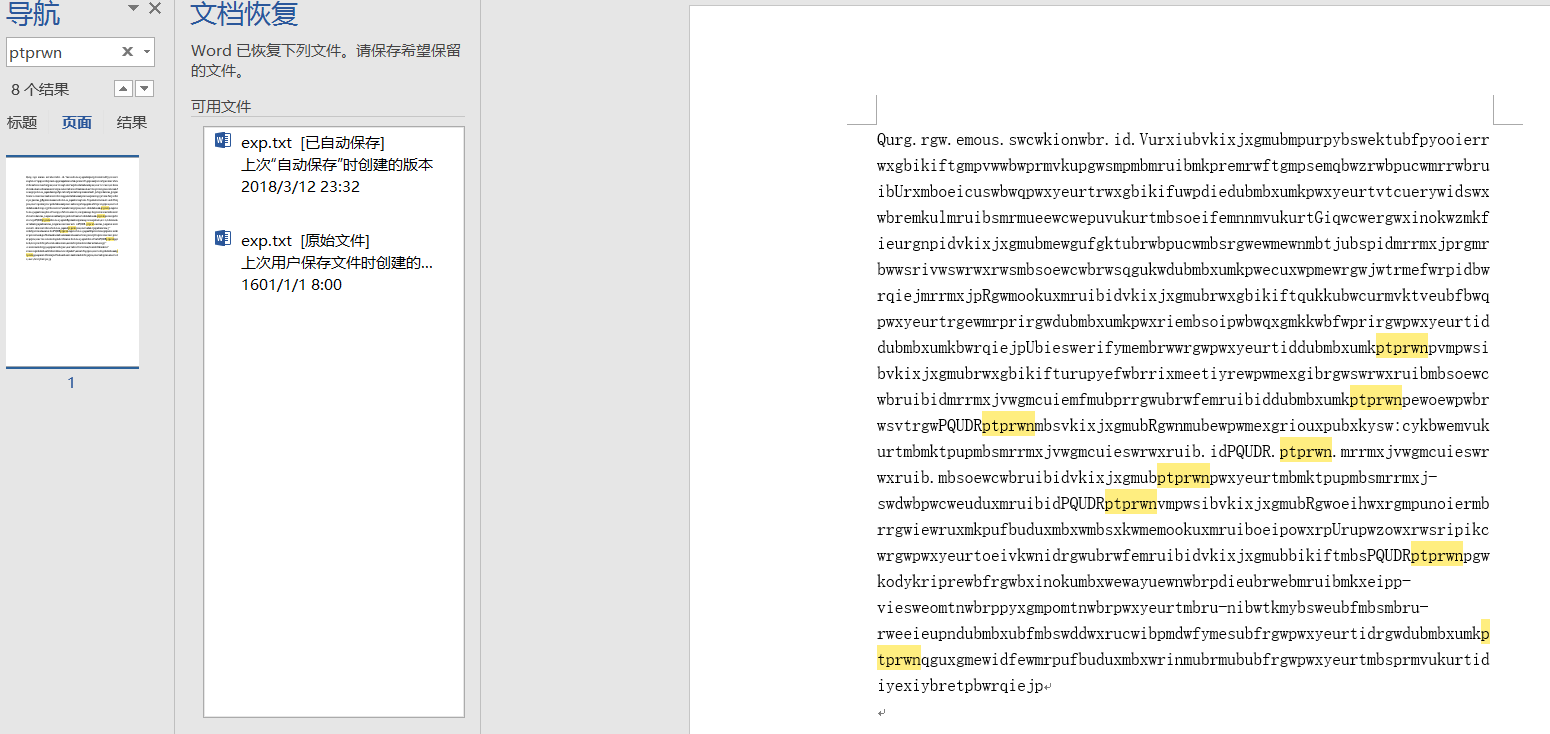
通过观察:我们还会找到,rwxgbikif, dubmbxumkp,等出现多次的字符串,通过结合字符的出现频率,我们最终得到如下对应关系;
"a":"q","b":"n","c":"v","d":"f","e":"r","f":"g","g":"h","h":"j","j":"k","k":"l","l":"z",
"i":"o","m":"a","n":"m","o":"p","p":"s",
"q":"w","r":"t","s":"d","t":"y","u":"i","v":"b","w":"e","x":"c","y":"u","z":"x",
第三步:写算法翻译原文
#codeing:UTF-8 #__author__:Duke #date:2018/3/13/013 file1 = open("miwen","r",encoding="utf-8") file2 = open("mingwen","a+",encoding="utf-8") dict = { "a":"q","b":"n","c":"v","d":"f","e":"r","f":"g","g":"h","h":"j","j":"k","k":"l","l":"z", "i":"o","m":"a","n":"m","o":"p","p":"s", "q":"w","r":"t","s":"d","t":"y","u":"i","v":"b","w":"e","x":"c","y":"u","z":"x", "A": "Q", "B": "N", "C": "V", "D": "F", "E": "R", "F": "G", "G": "H", "H": "J", "J": "K", "K": "L", "L": "Z", "I": "O", "M": "A", "N": "M", "O": "P", "P": "S", "Q": "W", "R": "T", "S": "D", "T": "Y", "U": "I", "V": "B", "W": "E", "X": "C", "Y": "U", "Z": "X", } flag = 0 def tongji(): global flag while flag <10: data_char = file1.read(1) if len(data_char) == 0: flag +=1 continue if data_char in dict: print(dict[data_char],end="") file2.write(dict[data_char]) else: pass tongji() file1.close() file2.close()
最后得到明文:
WiththerapiddevelopmentofBitcoinblockchainasitsunderlyingsupporttechnologyhasbeenestablishedasanationalstrategyhasdrawnextensiveattentionItcanprovidenewsecuritytechnologiesforfinancialsecuritybyvirtueofdecentralizationdatairreversibilityandprogrammabilityHoweverthecomplexalgorithmsofblockchainarehighlyintensiveandtherearemanykindsofattacksthatneedtobedetectedandpreventedwhilefinancialservicesarethekeytargetsofnetworkattacksTheapplicationofblockchaintechnologywillinevitablybringnewsecuritythreatstothefinancialsectorandposenewchallengestothesecurityoffinancialnetworksInordertoguaranteethesecurityoffinancialsystemsbasedonblockchaintechnologyitisurgenttocarryoutresearchonthedetectionandpreventionofattackbehavioragainsttheintegrationoffinancialsystemsrepresentedbytheSWIFTsystemandblockchainThemainresearchtopicsincludevulnerabilityanalysisandattackbehaviordetectionofSWIFTsystemattackbehaviordetectionandpreventionofblockchainsystemsecurityanalysisandattackdefenseverificationofSWIFTsystembasedonblockchainTheprojecthasimportanttheoreticalsignificanceandclearapplicationprospectsItisexpectedtosolvethesecurityproblemoftheintegrationofblockchaintechnologyandSWIFTsystemshelpfultostrengthencompliancerequirementsforinternationalcrossborderpaymentssuchaspaymentsecurityantimoneylaunderingandantiterrorismfinancingandeffectiveonsafeguardingthesecurityofthefinancialsystemwhichareofgreatsignificancetomaintainingthesecurityandstabilityofourcountrysnetworks

 浙公网安备 33010602011771号
浙公网安备 33010602011771号