
一、将爬虫大作业产生的csv文件上传到HDFS(对CSV文件进行预处理生成无标题文本文件)
1.准备本地数据文件 jin.csv(2500条数据)。
2.在本地中创建一个/usr/local/bigdatacase/dataset文件夹:
① cd /usr/local
② sudo mkdir bigdatacase/dataset
③ 把文件jin.csv用cp命令复制到此目录下

3.对数据进行预处理
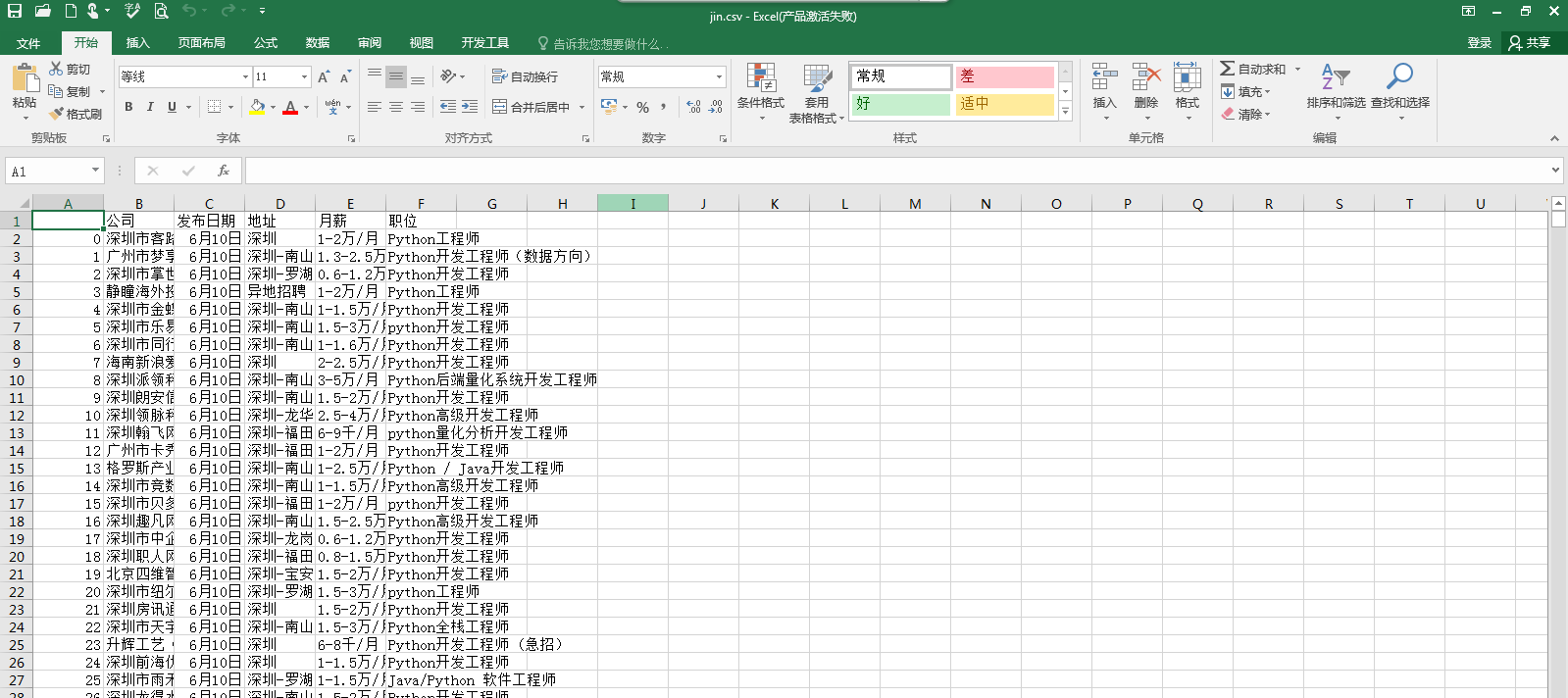
删除文件第一行生产无标题文件
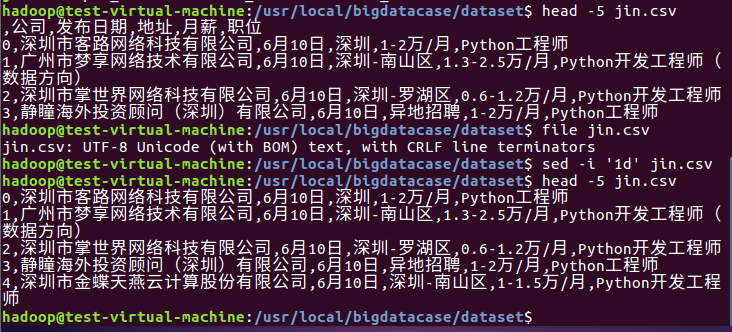
编辑pre_deal.sh文件对csv文件进行数据预处理:
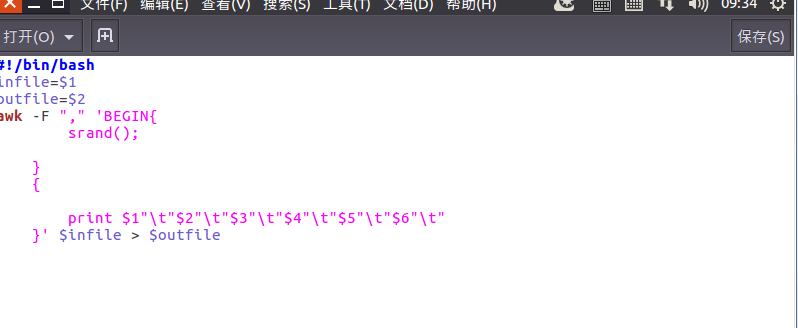
执行pre_deal.sh生成job.txt文件:
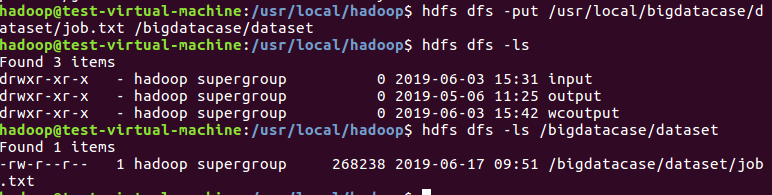
4.把job.txt上传到HDFS中:
启动HDFS:
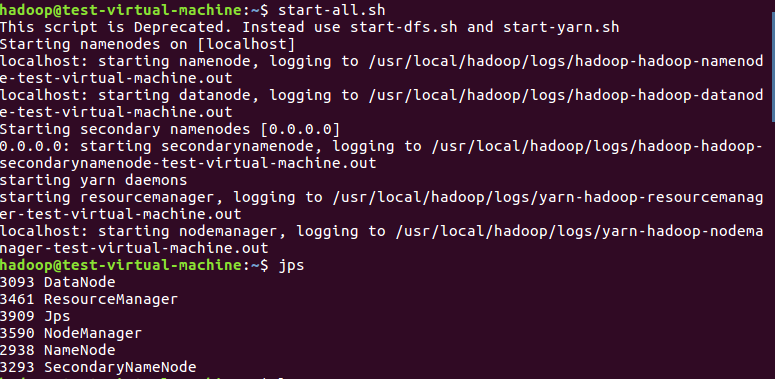
在HDFS中创建/bigdatacase/dataset文件夹,并把job.txt文件上传到该目录下:

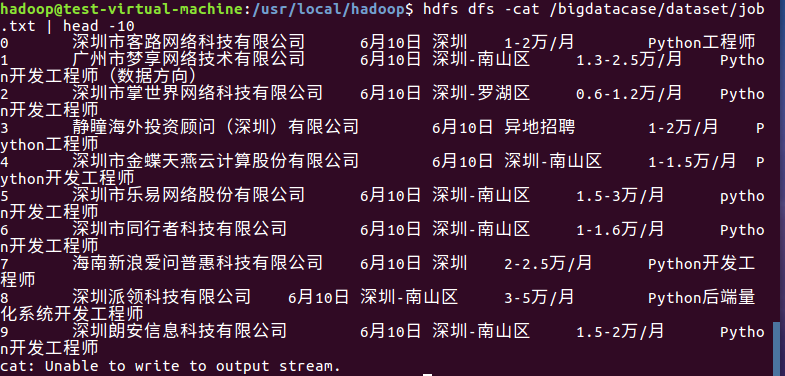
在HDFS中查看job.txt的前10条记录:
二、把hdfs中的文本文件最终导入到数据仓库Hive中
1.启动Hive:
2.创建数据库job

3.创建表jobs

4..查询表中的数据:
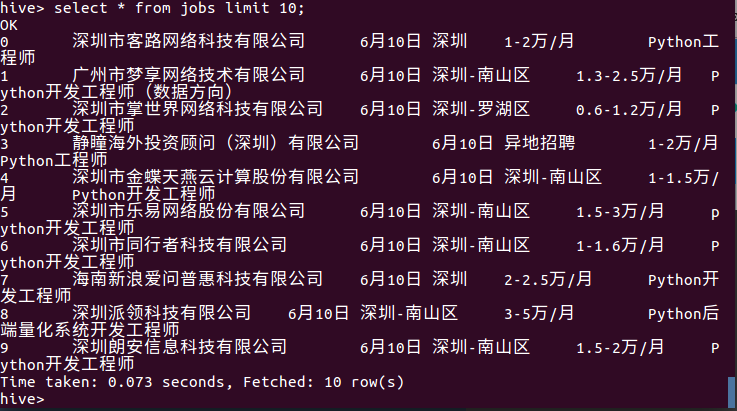
三、用Hive对爬虫大作业产生的进行数据分析(10条以上的查询分析)
1.查询哪个地方的招聘信息多

结果:
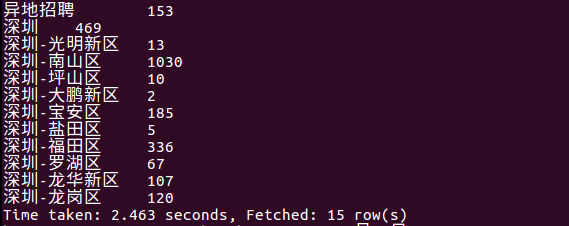
从上图可以看出,深圳南山区的招聘信息最多,从而得知这里可能互联网企业较多,想找工作的朋友可以到南山区试试。
2.查询哪天发布的招聘信息最多

结果:
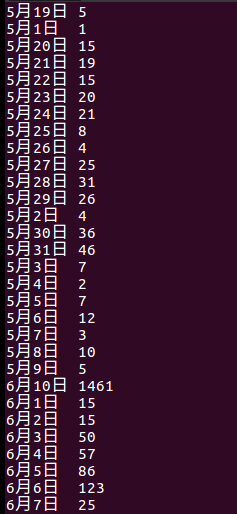
由上图可知,6月10号分布的招聘信息最多;
3.查询哪个公司发布的招聘信息最多

结果:
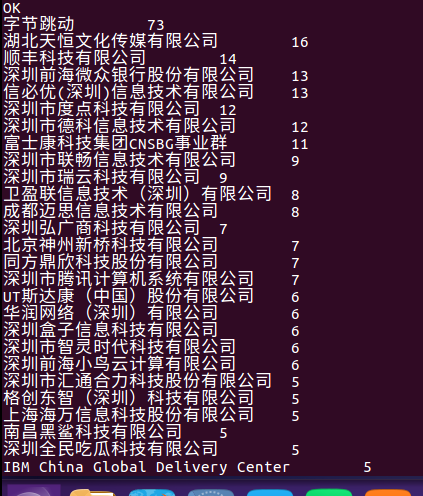
由上图可知,公司字节跳动发布的招聘信息最多。
4。查找哪种职位的工作最多

结果:
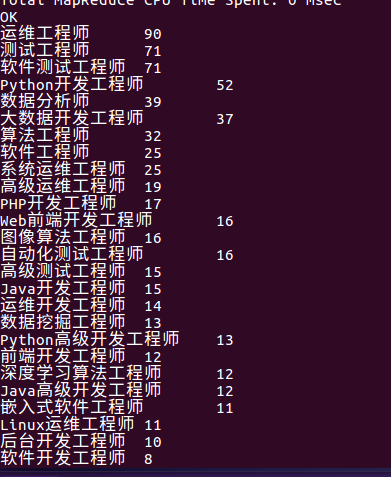
从上图可以看出,运维工程师类的招聘信息最多,测试工程师其次。可知运维工程师在该行业里需求大。
5.查找6月4号这天有多少公司发布了招聘信息

结果:

6.按最早日期查找宝安区的前10条招聘信息

结果:

7.查找AI工程师的招聘信息

结果:

8.查找深圳市度点科技有限公司发布的招聘信息。

结果:
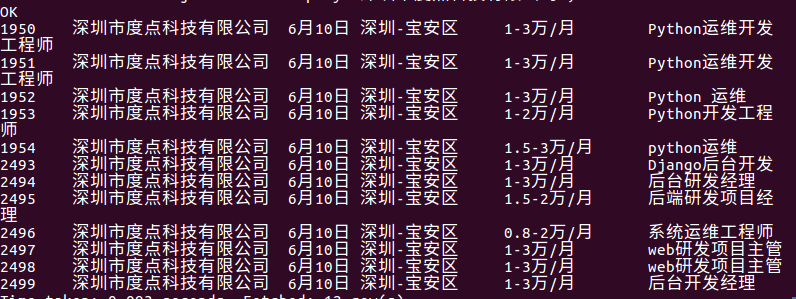
9.查询月薪为2.5-3万的工作有哪些

结果:

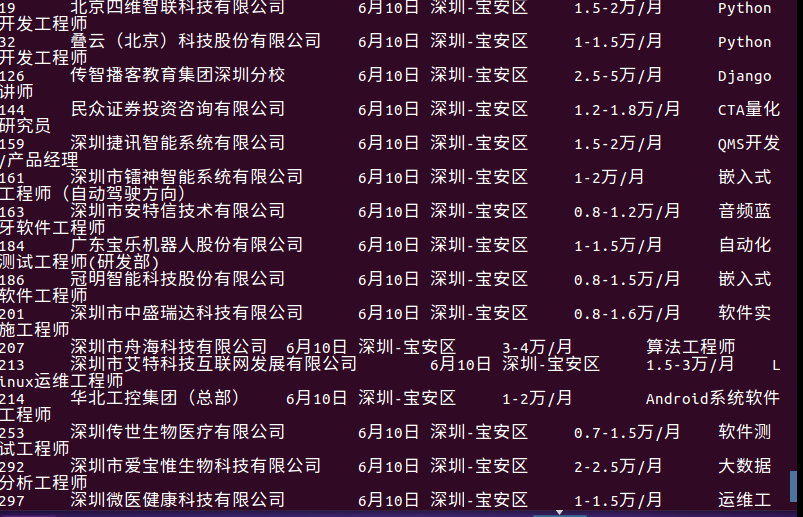
10.查找6月10号这天宝安区发布的招聘信息

结果:
四、总结
在完成这次作业的过程中,遇到了以下几个问题:
1.数据文件导入linux系统时出现了中文乱码。
解决方式:用npp转成utf-8格式。
2.创建数据库表后,表里插入了大量的空记录。
解决方式:用语句 insert overwrite table jobs select * from jobs where id is not NULL; 删除
