6.S081 Copy-on-Write Fork for xv6
Copy-on-Write Fork
写时复制 (Copy-on-write,简称COW) 是一种计算机程序设计领域的优化策略。其核心思想是,如果有多个调用者 (callers) 同时请求相同资源 (如内存或磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源(全局变量,动态链接库),直到某个调用者试图修改资源的内容时(堆栈),系统才会真正复制一份专用副本给该调用者,而其他调用者所见到的最初的资源仍然保持不变。这过程对其他的调用者都是透明的。此作法主要的优点是如果调用者没有修改该资源,就不会有副本被创建,因此多个调用者只是读取操作时可以共享同一份资源。
本实验跟着莫里斯教授一步一步修改源码,对错误原因进行分析
首先是修改fork(),以前的fork直接复制整个父进程到子进程中,为了实现cow fork,就要修改这一步,复制整个父进程到子进程这一步在uvmcopy()中实现
fork():
// Create a new process, copying the parent.
// Sets up child kernel stack to return as if from fork() system call.
int fork(void)
{
int i, pid;
struct proc *np;
struct proc *p = myproc();
// Allocate process.
if ((np = allocproc()) == 0) // 初始化一个proc变量
{
return -1;
}
// Copy user memory from parent to child.
if (uvmcopy(p->pagetable, np->pagetable, p->sz) < 0) // 将父进程全部复制给子进程
{
freeproc(np);
release(&np->lock);
return -1;
}
np->sz = p->sz;
np->parent = p;
// copy saved user registers.
*(np->tf) = *(p->tf);
// Cause fork to return 0 in the child.
np->tf->a0 = 0; // 这一步是区分父进程与子进程的关键
// increment reference counts on open file descriptors.
for (i = 0; i < NOFILE; i++)
if (p->ofile[i])
np->ofile[i] = filedup(p->ofile[i]);
np->cwd = idup(p->cwd);
safestrcpy(np->name, p->name, sizeof(p->name));
pid = np->pid;
np->state = RUNNABLE;
np->trace_mask = p->trace_mask;
release(&np->lock);
return pid;
}
uvmcopy()
uvmcopy():
// Given a parent process's page table, copy
// its memory into a child's page table.
// Copies both the page table and the
// physical memory.
// returns 0 on success, -1 on failure.
// frees any allocated pages on failure.
int uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)
{
pte_t *pte;
uint64 pa, i;
uint flags;
// char *mem;
for (i = 0; i < sz; i += PGSIZE)
{
if ((pte = walk(old, i, 0)) == 0)
panic("uvmcopy: pte should exist");
if ((*pte & PTE_V) == 0)
panic("uvmcopy: page not present");
pa = PTE2PA(*pte);
*pte = *pte & ~PTE_W; // 同时将父进程和子进程权限设置为不可写
flags = PTE_FLAGS(*pte);
//复制过程在异常处理函数中
// if ((mem = kalloc()) == 0)
// goto err;
// memmove(mem, (char *)pa, PGSIZE);
if (mappages(new, i, PGSIZE, (uint64)pa, flags) != 0)
{
// kfree(mem);
goto err;
}
}
return 0;
err:
uvmunmap(new, 0, i, 1);
return -1;
}
在uvmcopy()函数中,我们增加了
*pte = *pte & ~PTE_W;
它修改了父进程和子进程的权限为不可写,一旦我们将两个进程的虚拟内存指向了同一个物理内存,我们的操作就要更加谨慎。为了保证两个进程的隔离性,我们必须要把两个进程的权限都设为不可写,换句话说,一旦任何一个进程想要向其物理地址写入数据,都必须为他再单独分配一个物理内存,否则写入的数据将影响另外一个进程,父子进程都是如此。
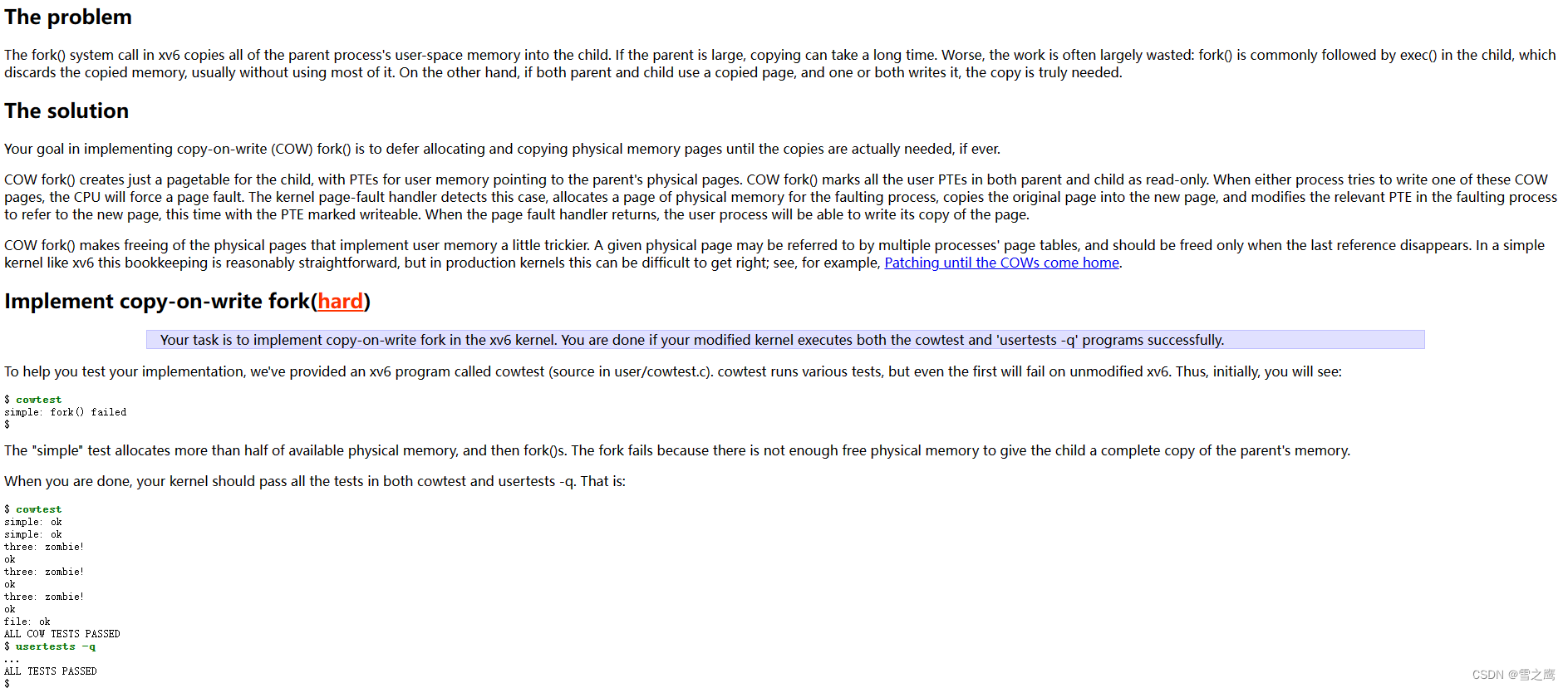
编译运行,当我们输入cowtest后,会出现以下的警告:
关注第一个usertrap,我们对这段信息进行分析:
- scause寄存器:记录异常原因,此处表示向内存中存数据引起page fault,与我们设置为不可写的预期情况一致
- stval 寄存器:记录发生异常的虚拟地址
- sepc 寄存器:记录发生异常之前的 PC 指令的虚拟地址
- pid:发生异常的进程号
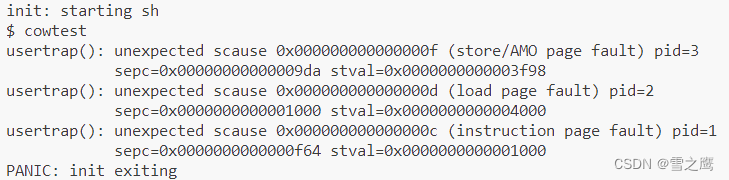
我们再通过gdb详细看看是怎么发生的。运行到sh的0x9da,这是异常发生的位置,可以看到这里是sd命令(存储数据到内存)错误,再打印发生错误的虚拟地址0x3f98,与警告的信息一一对应
我们的程序是在shell(pid=2)中运行的,那为什么输出的pid等于3(cowtest)呢?这里查看sh源码
int
main(void)
{
...
if(fork1() == 0)
runcmd(parsecmd(buf));
wait(0);
}
exit(0);
}
在fork1后并没有立即exec,也就是没有立即将cowtest加载到内存,而是做了些exec前的前期工作。所以在fork1后,子进程创建,pid也等于3,但是现在运行的依旧是父进程sh的内容。
这里有一个问题,既然我们都修改了uvmcopy(),让权限改为不可写,那为什么Init和子进程sh能顺利创建呢?
查看exec()源码,发现uvmalloc()函数里更改了权限
// Allocate PTEs and physical memory to grow process from oldsz to
// newsz, which need not be page aligned. Returns new size or 0 on error.
uint64
uvmalloc(pagetable_t pagetable, uint64 oldsz, uint64 newsz)
{
...
if (mappages(pagetable, a, PGSIZE, (uint64)mem, PTE_W | PTE_X | PTE_R | PTE_U) != 0)
{
kfree(mem);
uvmdealloc(pagetable, a, oldsz);
return 0;
}
...
}
usertrap()
我们现在已经能引发写异常了,现在需要对这个异常进行处理
usertrap():
int cowfault(pagetable_t pagetable, uint64 va)
{
if (va >= MAXVA)
return -1; // // walk中也有此步,但是会引发panic,陷入死循环
pte_t *pte = walk(pagetable, va, 0);
if (*pte == 0)
return -1;
uint64 pa1 = PTE2PA(*pte);
uint64 pa2 = (uint64)kalloc();
if (pa2 == 0)
{
printf("cow kalloc failed\n");
return -1;
}
memmove((void *)pa2, (void *)pa1, PGSIZE);
*pte = PA2PTE(pa2) | PTE_V | PTE_U | PTE_X | PTE_R | PTE_W;
return 0;
}
// COW Fork
void usertrap(void)
{
...
else if (r_scause() == 15)
{
if (cowfault(p->pagetable, r_stval()) < 0)
p->killed = 1;
}
...
}
编译运行,当我们输入cowtest后,会出现以下的警告:

这里发生的异常是非法指令异常。出现的原因是我们还没有修改内存释放相关的代码,用的kfree()还是以前直接复制情况的代码,我们还没有进程结束,那么在哪里会调用kfree()呢?
在shell创建子进程后,使用exec会释放以前的页面(包括指令所在页面),然后新页面会被重新装入
这里还有一个疑问,既然exec()会替换fork之后的内容,那为什么还要memmove((void *)pa2, (void *)pa1, PGSIZE)复制父进程的内容呢,将虚拟地址直接映射到新的物理地址不行吗?
对于这种假设,如果我们在fork()后直接跟exec(),其实是可行的;但是我们还是避免不了在exec()前进行一些其他操作,比如它会调用父进程的函数,dup()也需要父进程里的文件信息,甚至有的fork()后面就不会跟exec()
kfree()
加入COW Fork之后,kfree()就不是简单地释放内存了,因为有很多页面引用它。相应的kalloc()也要做修改。我们还需要引入全局变量refcount[]来记录每个物理页面被引用数量,只有引用为0才能释放内存
kalloc.c:
void incref(uint64 pa)
{
acquire(&kmem.lock);
int pn = pa / PGSIZE;
if (refcount[pn] < 1 || pa >= PHYSTOP)
panic("incref");
refcount[pn]++;
release(&kmem.lock);
}
// Free the page of physical memory pointed at by v,
// which normally should have been returned by a
// call to kalloc(). (The exception is when
// initializing the allocator; see kinit above.)
void kfree(void *pa)
{
struct run *r;
if (((uint64)pa % PGSIZE) != 0 || (char *)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
//加入锁是为了防止两个引用同一个物理内存的进程同时释放内存
acquire(&kmem.lock);
int pn = (uint64)pa / PGSIZE;
if (refcount[pn] < 1)
panic("kfree ref");
int tmp = --refcount[pn];
release(&kmem.lock);
if (tmp > 0)
return;
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run *)pa;
acquire(&kmem.lock);
r->next = kmem.freelist;
kmem.freelist = r;
release(&kmem.lock);
}
// Allocate one 4096-byte page of physical memory.
// Returns a pointer that the kernel can use.
// Returns 0 if the memory cannot be allocated.
void *
kalloc(void)
{
struct run *r;
acquire(&kmem.lock);
r = kmem.freelist;
if (r)
{
kmem.freelist = r->next;
int pn = (uint64)r / PGSIZE;
if (refcount[pn] != 0)
panic("kalloc ref");
refcount[pn] = 1;
}
release(&kmem.lock);
if (r)
memset((char *)r, 5, PGSIZE); // fill with junk
return (void *)r;
}
uvmcopy():
// Given a parent process's page table, copy
// its memory into a child's page table.
// Copies both the page table and the
// physical memory.
// returns 0 on success, -1 on failure.
// frees any allocated pages on failure.
int uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)
{
...
incref(pa);
...
}
cowfault():
int cowfault(pagetable_t pagetable, uint64 va)
{
...
memmove((void *)pa2, (void *)pa1, PGSIZE);
kfree((void *)pa1); // 不要忘记取消pa1的映射
*pte = PA2PTE(pa2) | PTE_V | PTE_U | PTE_X | PTE_R | PTE_W;
...
return 0;
}
至此,COW Fork机制更加完善,编译运行,得到以下结果

copyout()
前面的测试都通过了,出现了file error,打开cowtest.c,发现这一模块是为了测试copyout()函数
filetest():
// test whether copyout() simulates COW faults.
void filetest()
{
printf("file: ");
buf[0] = 99;
for (int i = 0; i < 3; i++)
{
if (pipe(fds) != 0)
{
printf("pipe() failed\n");
exit(-1);
}
int pid = fork();
if (pid < 0)
{
printf("fork failed\n");
exit(-1);
}
if (pid == 0)
{
sleep(1);
if (read(fds[0], buf, sizeof(i)) != sizeof(i))
{
printf("error: read failed\n");
exit(1);
}
sleep(1);
int j = *(int *)buf;
if (j != i)
{
printf("error: read the wrong value\n");
exit(1);
}
printf("exit fd0:%d", fds[0]);
exit(0);
}
if (write(fds[1], &i, sizeof(i)) != sizeof(i))
{
printf("error: write failed\n");
exit(-1);
}
}
int xstatus = 0;
for (int i = 0; i < 4; i++)
{
wait(&xstatus);
if (xstatus != 0)
{
exit(1);
}
}
if (buf[0] != 99)
{
printf("error: child overwrote parent\n");
exit(1);
}
printf("ok\n");
}
从打印的错误也可以看到,是read函数发生了错误,而read恰好也调用了copyout()函数,所以我们看看使用COW Fork的时候,会怎样影响copyout()
copyout():
// Copy from kernel to user.
// Copy len bytes from src to virtual address dstva in a given page table.
// Return 0 on success, -1 on error.
int copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len)
{
uint64 n, va0, pa0;
while (len > 0)
{
va0 = PGROUNDDOWN(dstva);
pa0 = walkaddr(pagetable, va0);
if (pa0 == 0)
return -1;
n = PGSIZE - (dstva - va0);
if (n > len)
n = len;
memmove((void *)(pa0 + (dstva - va0)), src, n);
len -= n;
src += n;
dstva = va0 + PGSIZE;
}
return 0;
}
先了解一下copyin和copyout的原理: copyin和copyout详解
了解了copyin和copyout的原理,它通过walk模拟了MMU的功能,对地址进行了转换。但它的整个过程都是在内核态进行的,也就是说,它使用的是内核页表,而内核对用户区的权限是很高的(可读可写,见kvminit())。所以,这样操作相当于是跳过了可写权限的检查,使得往这一区域写的数据由父子进程共享,破坏了隔离性。
copyout()应修改为:
int copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len)
{
uint64 n, va0, pa0;
while (len > 0)
{
va0 = PGROUNDDOWN(dstva);
pte_t *pte = walk(pagetable, va0, 0);
if (pte == 0 || (*pte & PTE_V) == 0 || (*pte & PTE_U) == 0)
return -1;
if ((*pte & PTE_W) == 0)
{
if (cowfault(pagetable, va0) < 0)
return -1;
}
pa0 = walkaddr(pagetable, va0);
if (pa0 == 0)
return -1;
n = PGSIZE - (dstva - va0);
if (n > len)
n = len;
memmove((void *)(pa0 + (dstva - va0)), src, n);
len -= n;
src += n;
dstva = va0 + PGSIZE;
}
return 0;
}
编译运行,成功


 浙公网安备 33010602011771号
浙公网安备 33010602011771号