6.S081 Locks
Memory allocator
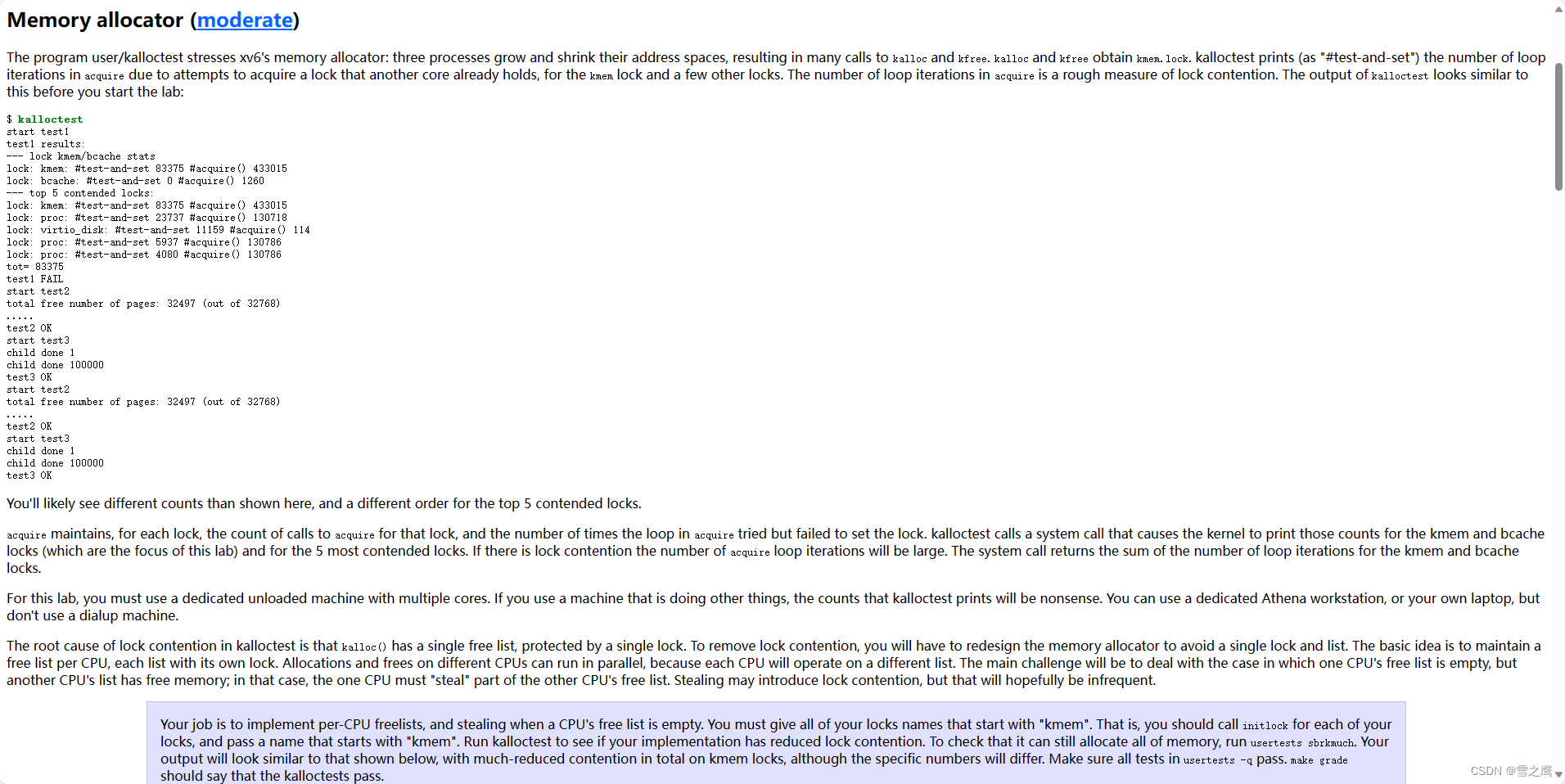
本测试用kalloctest例创造了3个进程,不断kalloc()和kfree(),这就意味着会频繁使用锁。然而我们的freelist只有1个,在多核里3个并行运行的进程必定会为了获得锁而自旋。
运行kalloctest可以看到结果。其中669281代表自旋次数,600057代表获得锁(进入acquire()的次数)。
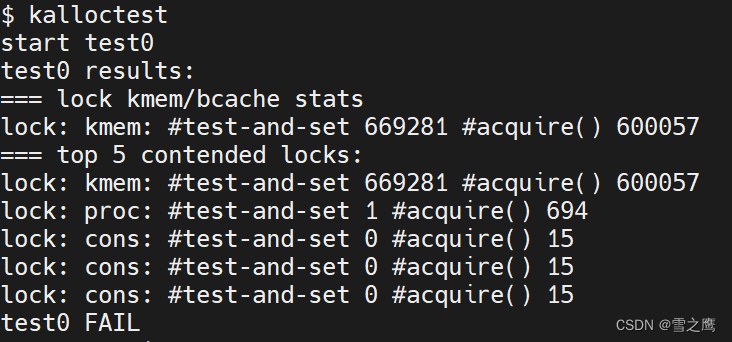
值得注意的是进行实验前一定要设置qemu为多核,否则单核的自旋次数将永远为0。
修改核心数(smp为处理器核心数):
在Makefile中修改smp:
qemu-system-riscv64 -machine virt -bios none -kernel kernel/kernel -m 128M -smp 3 -nographic -drive file=fs.img,if=none,format=raw,id=x0 -device virtio-blk-device,drive=x0,bus=virtio-mmio-bus.0
或者
make qemu CPUS=3
所以本实验的目的就是减少这种自旋,因为自旋会占用cpu资源。解决办法是为每一个核心都分配一个freelist,分别管理不同的物理地址,这样就不会有不通cpu修改同一物理地址的问题,自旋的问题也解决了。
但是就像实验所说,kalloc()的实现更复杂了,因为它需要在内存不够的时候(freelist为空),去别的核心的freelist中去“偷”内存块,放入自己的freelist里为己所用。所以在这里是会出现自旋的,我们的锁也是在这里应用。
此实验是在COW Fork实验基础上更改
freelist
将共享的一个freelist改为NCPU独享的freelist
struct kmem
{
struct spinlock lock;
struct run *freelist;
} kmem[NCPU];
kfree()
kfree():
// Free the page of physical memory pointed at by v,
// which normally should have been returned by a
// call to kalloc(). (The exception is when
// initializing the allocator; see kinit above.)
void kfree(void *pa)
{
struct run *r;
if (((uint64)pa % PGSIZE) != 0 || (char *)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
// 获得当前核心号
// 关闭中断是因为万一在返回了curcpu之后马上进入定时器中断,导致进程切换到别的cpu运行,那么cpu将不对应
push_off();
int curcpu = cpuid();
pop_off();
acquire(&kmem[curcpu].lock);
int pn = (uint64)pa / PGSIZE;
if (refcount[pn] < 1)
{
panic("kfree ref");
}
int tmp = --refcount[pn];
release(&kmem[curcpu].lock);
if (tmp > 0)
return;
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run *)pa;
acquire(&kmem[curcpu].lock);
r->next = kmem[curcpu].freelist;
kmem[curcpu].freelist = r; // 将pa加入freelist中
release(&kmem[curcpu].lock);
}
kalloc()
kalloc()是本实验的重点,本身逻辑不难,难的是容易出现各种bug。
以下是有问题的kalloc(),因为整个解决问题的过程很有价值,所以附上:
// Allocate one 4096-byte page of physical memory.
// Returns a pointer that the kernel can use.
// Returns 0 if the memory cannot be allocated.
void *
kalloc(void)
{
struct run *r;
int pn;
// 获得当前核心号
push_off();
int curcpu = cpuid();
pop_off();
acquire(&kmem[curcpu].lock);
r = kmem[curcpu].freelist;
if (r)
{
kmem[curcpu].freelist = r->next;
pn = (uint64)r / PGSIZE;
if (refcount[pn] != 0)
panic("kalloc ref");
refcount[pn] = 1;
}
else
{
// 从其他核心的freelist“偷”
for (int i = 0; i < NCPU; i++)
{
if (i == curcpu)
continue;
r = kmem[i].freelist;
acquire(&kmem[i].lock);
if (r)
{
// 将内存块从别的freelist中移出
kmem[i].freelist = r->next;
pn = (uint64)r / PGSIZE;
// printf("cpuid=%d,pn=%d\r\n ", curcpu, pn);
if (refcount[pn] != 0)
{
printf("cpuid=%d,refcount[pn]=%d,pn=%d ", curcpu, refcount[pn], pn);
panic("kalloc ref");
}
refcount[pn] = 1;
release(&kmem[i].lock);
break;
}
else
release(&kmem[i].lock);
}
}
release(&kmem[curcpu].lock);
if (r)
memset((char *)r, 5, PGSIZE); // fill with junk
return (void *)r;
}
运行结果:
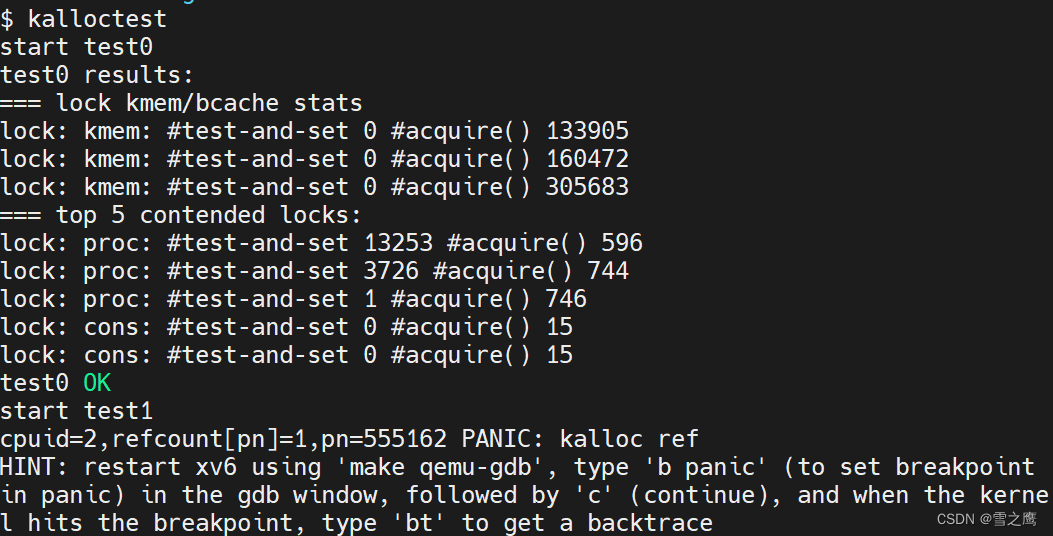
可以看到,lock kmem/bcache stats的结果符合预期,采用cpu独享freelist的方法确实减少了自旋,在此处直接为0,test0通过;可是test1就没那么幸运了,直接报错,定位到我们的代码:
// 从其他核心的freelist“偷”
for (int i = 0; i < NCPU; i++)
{
if (i == curcpu)
continue;
r = kmem[i].freelist;
acquire(&kmem[i].lock);
if (r)
{
// 将内存块从别的freelist中移出
kmem[i].freelist = r->next;
pn = (uint64)r / PGSIZE;
if (refcount[pn] != 0)
{
printf("cpuid=%d,refcount[pn]=%d,pn=%d ", curcpu, refcount[pn], pn);
panic("kalloc ref");
}
refcount[pn] = 1;
release(&kmem[i].lock);
break;
}
else
release(&kmem[i].lock);
报错出现在我们“偷”内存的地方。也就是说它在refcount[pn]已经被分配的情况下(!=0)的情况下仍想分配这一块内存。
我们再来试一下单核运行kalloctest,以此来排除是否是多核引发的并发错误。
make qemu CPUS=1
运行结果:
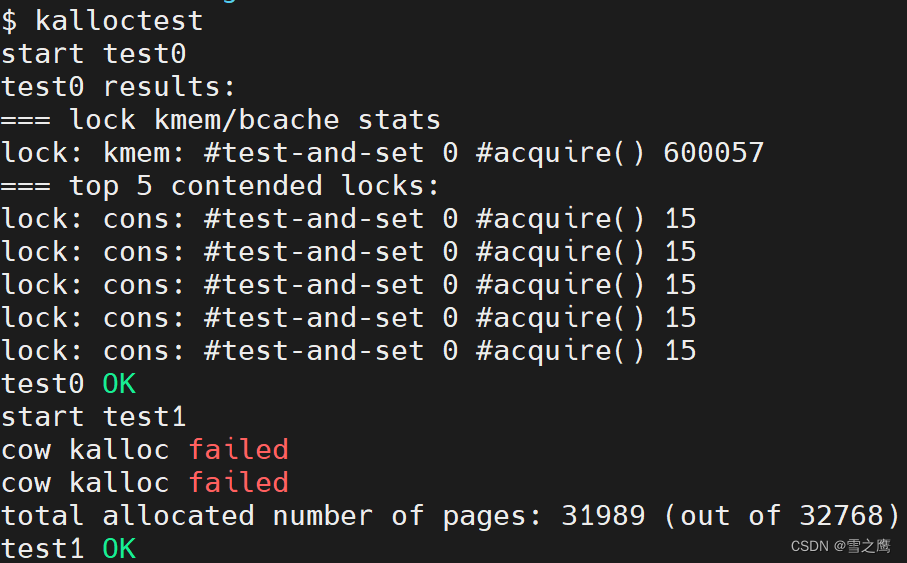
可以看到单核运行时正常,所以问题就出在我们多核“偷”内存那里。
我们的报错refcount[pn]在已经被引用一次的情况下再引用了一次,我们就要想多核可能引发的并发问题。
r = kmem[i].freelist;
acquire(&kmem[i].lock);
if (r)
看到这一段代码,多核会出现这样一种情况:两个进程同时运行到r = kmem[i].freelist,其中一个获得锁进入了if( r ) ,而另外一个再获得锁时,也可以进入if( r ) 里面,但此时该页已经被引用过了,所以出现了我们上面看到的bug。
知道原因后,现在对我们的代码进行修改,只用替换一下位置即可:
void *
kalloc(void)
{
···
else
{
// 从其他核心的freelist“偷”
for (int i = 0; i < NCPU; i++)
{
if (i == curcpu)
continue;
acquire(&kmem[i].lock); // 注意获得锁的位置,否则会出现bug
r = kmem[i].freelist;
···
}
运行结果:
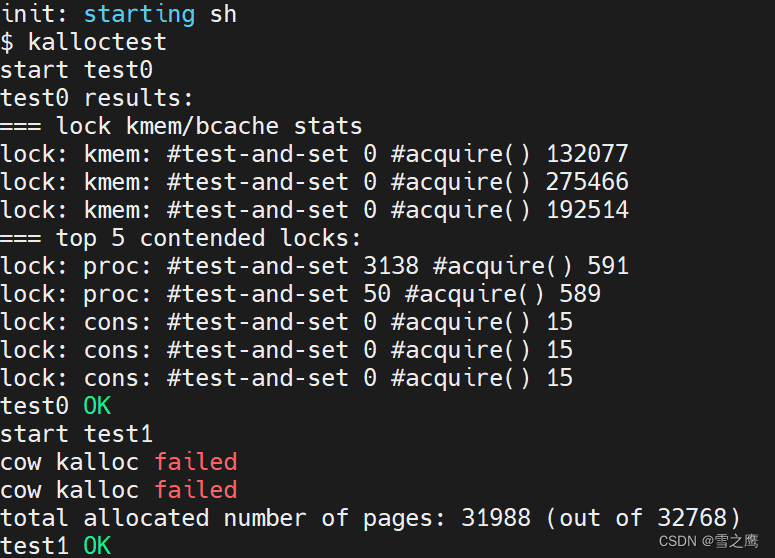
运行正确。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号