Kubernetes 节点各组件概述
一、Master 节点概述
- Kubernetes 集群由控制平面(Master 节点)和若干工作节点(Worker Node)组成。控制平面负责管理整个集群的全局状态和资源调度。Master 节点相当于集群的大脑,中枢神经,运行着 API Server、etcd、Controller Manager、Scheduler 等组件,负责集群级别的调度、状态监控及自动化运维,确保实际状态与期望状态最终一致。在生产环境中,Master 节点通常采用多副本部署以提高可用性(如多台 API Server 负载均衡、etcd 采用奇数节点集群等),并对自身进行污点(Taint)管理,默认不调度普通业务 Pod。
1.1:Master 核心组件功能:
- kube-apiserver:集群的统一入口和通信枢纽,提供了RESTful API负责认证授权、资源校验等安全功能所有对资源对象的增删改查都通过 API Server 处理,并持久化到 etcd;只有 API Server 能直接访问 etcd,其他组件必须通过它间接读写数据。
- etcd:高可用的分布式键值存储数据库,是集群状态的后台存储。所有 Kubernetes 对象(如 Pod、Service、ConfigMap 等)及其状态都保存在 etcd 中。etcd 通常以奇数节点集群方式部署,以保证数据一致性和容错能力。
- kube-scheduler:调度器组件,负责将新创建的、尚未绑定到节点的 Pod 分配到最合适的节点上。调度器会综合考虑 Pod 资源需求、节点资源状况、亲和性/反亲和性、拓扑策略、污点容忍等因素,对符合条件的节点打分并选择得分最高的节点,然后通过 API Server 更新 Pod 的调度结果。
- kube-controller-manager:控制器管理器,运行多个控制器(如 ReplicaSet、Deployment、DaemonSet、Node、Endpoint 等控制循环)。它通过观察 API Server 上的对象变化来驱动集群状态修正:当资源实际状态与期望状态不符时,控制器管理器会创建、删除或调整 Pod 等对象,实现故障自愈、弹性伸缩、节点管理等功能。Kubernetes 采用最终一致策略,即 - Controller Manager 不断循环比较实际/期望状态并持续纠正,保障集群稳定运行。
- Cloud-Controller-Manager:可选组件在云环境中使用。它包含特定云平台的控制器(如云负载均衡、路由、节点控制器等),使集群可以对接云厂商 API。在纯本地或非云环境中可不部署。
1.2:组件间交互与数据流转
- Kubernetes 采用典型的控制平面–数据平面架构,各组件之间不直接通信,而是通过 kube-apiserver 作为中介进行交互。所有配置请求和组件事件都会通过 API Server 传递并持久化到 etcd。当用户或系统需要创建或修改资源时(如创建 Pod、ReplicaSet 等),请求首先到达 API Server,由其进行合法性校验后写入 etcd。其他组件(如 Scheduler、Controller Manager、kubelet 等)则持续监视(watch)API Server 上相应资源的变化,并在需要时发起进一步操作。
例如,一个新 Pod 的创建流程如下:
-
用户通过 kubectl 向 API Server 提交创建 ReplicaSet 或 Pod 的请求,API Server 将该资源写入 etcd 存储。
-
Controller Manager 监控到新创建的 ReplicaSet,发现集群状态与期望状态不一致后,通过 API Server 创建对应数量的 Pod 对象。
-
Scheduler 发现有待调度的 Pod 对象,运行调度算法选择合适的节点,并通过 API Server 更新该 Pod 的调度结果(Node 绑定信息)。
-
当某个 Pod 被分配到指定节点后,API Server 会通知对应节点上的 kubelet。Kubelet 进而拉取容器镜像并启动容器,同时将 Pod 运行状态上报回 Master。
![]()
上图展示了 Kubernetes 控制平面与节点的高层架构示意:Master 节点上运行 kube-apiserver、etcd、controller-manager、scheduler 等组件,节点上运行 kubelet、kube-proxy 等组件。所有组件通过 API Server 交换数据,形成完整的控制闭环。
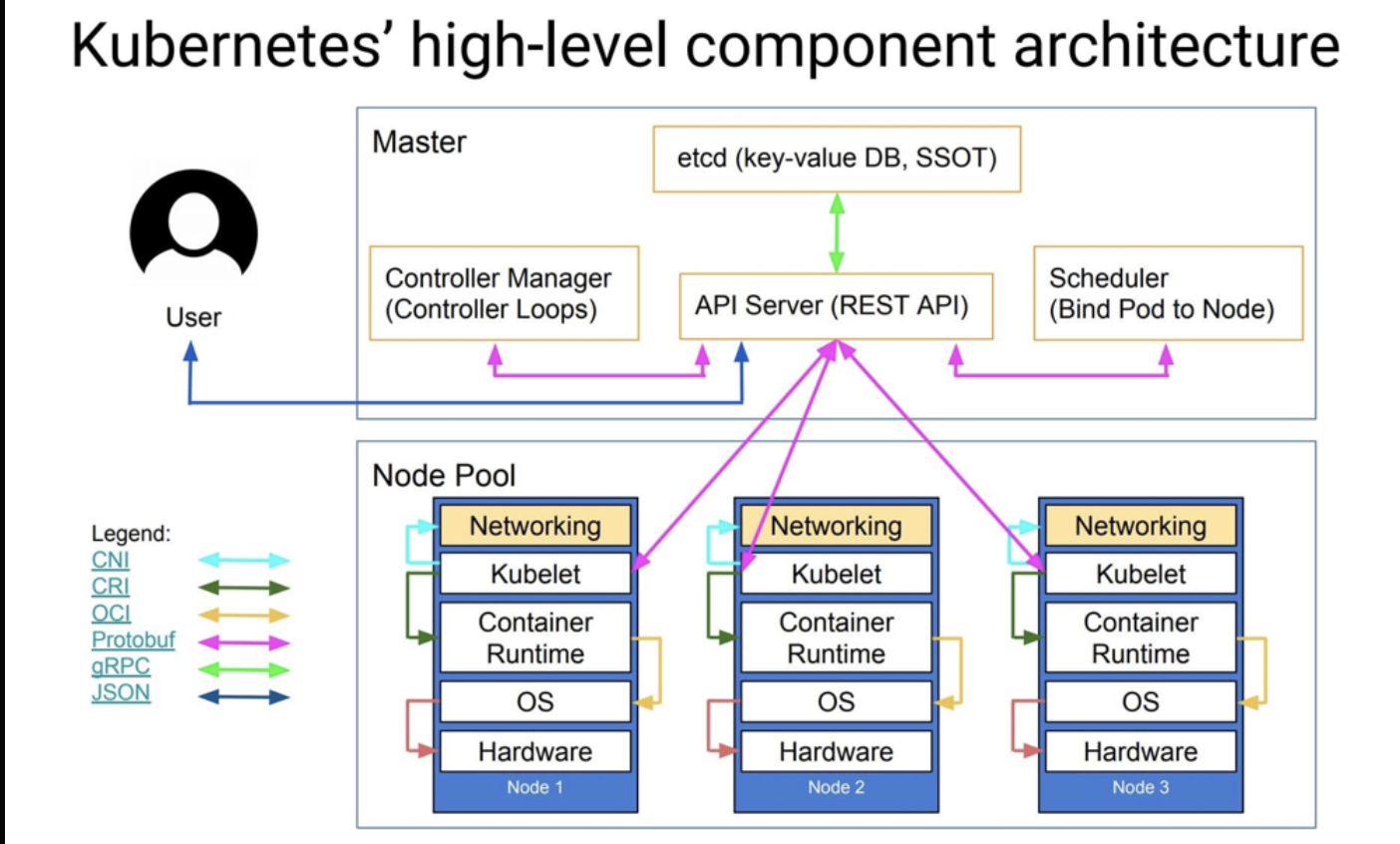
1.3:Master节点与工作节点的关系
- Master 节点只负责管理和控制,不运行实际业务容器;工作节点(Worker Node)提供计算资源,用于承载容器化应用。每个工作节点上都运行 kubelet 和 kube-proxy。kubelet 是节点上的核心代理(Agent),它主动向 API Server 注册自身节点并定期汇报资源和健康状况。当 Master 通过 Scheduler 将 Pod 分配到该节点后,kubelet 会接收通知、调用容器运行时创建和管理容器。kube-proxy 在节点上负责容器网络的代理和四层负载均衡功能,将访问 Pod 的流量转发到后端容器。Master 和 Node 之间所有通信都通过 API Server 完成,Master 发出的调度或指令最终通过 API Server 传递给 kubelet,由其在本地执行。
二、Node节点概述
2.1:node关键组件
- kubelet:Node 上的核心代理进程,负责接收 API Server 下发的 Pod 指令,并在本地启动容器。监控 Pod 状态并将运行状态上报给 API Server。可以拉取镜像、挂载卷、执行探针等操作。
- kube-proxy:实现 Kubernetes 的网络代理和负载均衡,基于 Service 的转发规则维护 iptables 或 IPVS 规则,将服务请求转发到对应 Pod 后端。
- 容器运行时:实际运行容器的底层引擎,常见的包括 containerd、CRI-O(均支持 Kubernetes 的 CRI 接口),负责镜像拉取、容器创建、资源隔离等底层操作。
2.2:node各组件工作机制与交互流程
- kubelet 工作流程:
- 启动时向 API Server 注册自己为 Node 资源对象。
- 定期向 API Server 汇报节点状态(资源容量、运行状况、Pod 状态等)。
- 监听 API Server 分配给本节点的 Pod,对应地拉取镜像并运行容器。
- 执行健康探针(Liveness/Readiness)和生命周期钩子。
- 通过 CRI 接口调用容器运行时完成容器管理。
- kube-proxy 工作流程:
- 监听 API Server 上 Service 和 Endpoint 的变化。
- 动态配置本地 iptables 或 IPVS 规则。
- 实现 Kubernetes Service 的四层负载均衡(TCP/UDP),转发访问请求至后端 Pod。
-
容器运行时:
接受 kubelet 通过 CRI 的调用,完成以下任务:- 镜像管理(拉取、缓存)
- 容器创建与销毁
- 网络与存储挂载
- 日志收集
2.3:Node与Master的关系和通信流程
- Node 上的 kubelet 会定期与 API Server 通信,获取最新的调度信息(如要创建哪些 Pod),并将当前节点的健康状态和 Pod 状态上报。
- kube-proxy 监听 API Server 获取最新的 Service 和 Endpoint 信息,配置本地网络规则,确保服务访问连通。
- Node 与 Master 的通信全部通过 kube-apiserver,使用 HTTPS 通道,默认是拉模型(pull)。
文本描述:
[Master: API Server] <---> [kubelet] --- 容器运行时
|
+---> [kube-proxy] --- iptables/IPVS 规则

 浙公网安备 33010602011771号
浙公网安备 33010602011771号