
Synchronized之三:实现原理
一、Java源代码级别
synchronized(对象)
字节码层级
使用idea插件jclasslib插件查看字节码,我们以之前代码为例
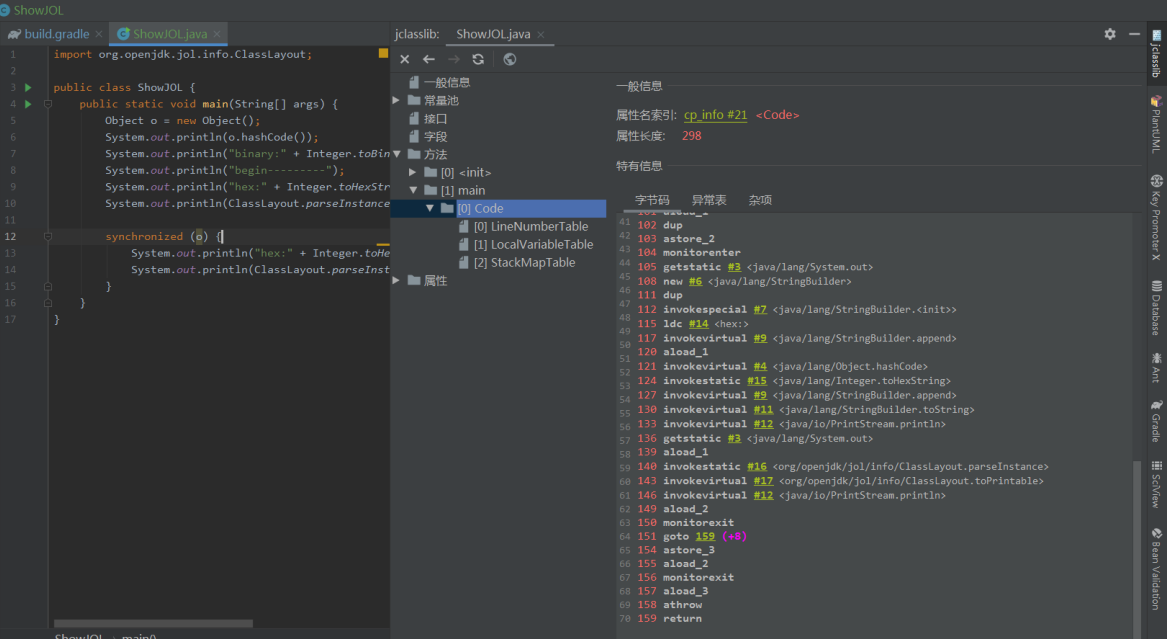
在字节码层面是以monitorenter作为开始锁的开始,以moniterexit作为结束。
汇编级别
我们使用hsdis工具对Java源码进行反编译为汇编代码
public class SynchronizedTest { private static int c; public static synchronized void sync() { } public static void noSynchronized() { int a = 1; int b = 2; c = a + b; } public static void main(String[] args) { for (int j = 0; j < 1000_000; j++) { sync(); noSynchronized(); } } }
0x00000001195d2e4e: lock cmpxchg %r11,(%r10)
0x00000001195d2e53: je 0x00000001195d2da0
0x00000001195d2e59: mov %r13,(%rsp)
0x00000001195d2e5d: movabs $0x79578d830,%rsi ; {oop(a 'java/lang/Class' = 'com/example/demo/SynchronizedTest')}
0x00000001195d2e67: lea 0x10(%rsp),%rdx
0x00000001195d2e6c: data32 xchg %ax,%ax
0x00000001195d2e6f: callq 0x0000000119525860 ; OopMap{off=404}
;*synchronization entry
; - com.example.demo.SynchronizedTest::sync@-1 (line 11)
我们看到了开篇提到的lock cmpxchg这条汇编命令,结论是synchronized底层也是使用cas的方式来实现锁。
二、对象头、Mark Word、monitor、synchronized怎么关联起来?
知道了java里面有synchronized这个关键字,是用来加锁的,但是它底层是怎么加锁的我一直没搞明白。大概知道是通过一个monitor监视器还有什么monitorenter、monitorexit这两条执行来进行加锁和释放锁的。现在讲讲具体实现的细节
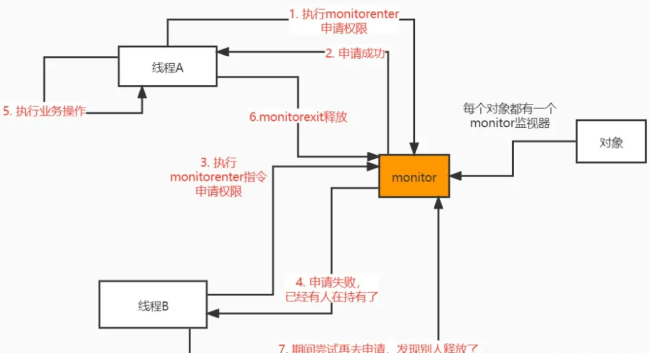
(1)首先java里面每个对象JVM底层都会为它创建一个监视器monitor,这个是JVM层次为我们保证的。这个监视器就类似一个锁,哪个线程持有这个monitor的操作权,就相当于获取到了锁
(2)其次synchronized 修饰的代码或者方法,底层会生成两条指令分别为monitorenter、monitorexit。
(3)进入synchronized的代码块之前会执行monitorenter指令,去申请monitor监视器的操作权,如果申请成功了,就相当于获取到了锁。
如果已经有别的线程申请成功monitor了,这个时候它就得等着,等别的线程执行完synchronized里面的代码之后就会执行monitorexit指令释放monitor监视器,这样其它在等待的线程就可以再次申请获取monitor监视器了。
monitor又是个啥东西?为什么monitor能当做锁?首先既然你知道每个对象都有一个monitor监视器,那你知道每个对象是怎么和它的monitor监视器关联起来的不?
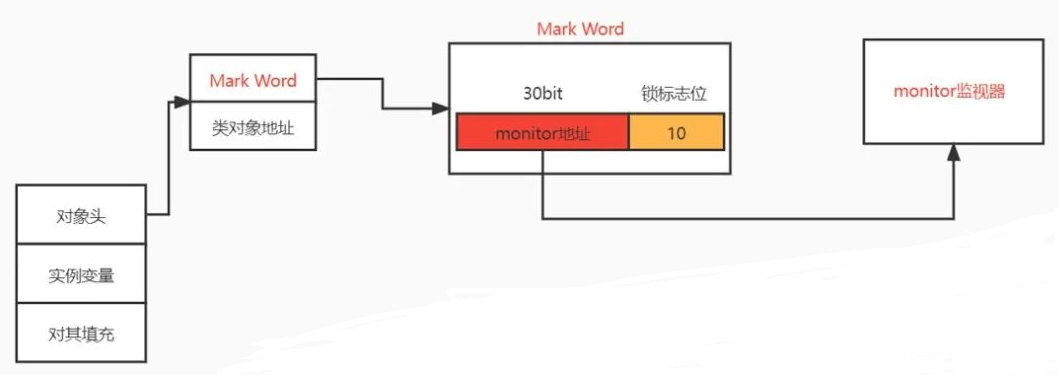
通过synchronized进行加锁,就是通过对象头的Mark Word关联起来的,里面记录着锁状态和占有锁的线程地址指针,详情见《java对象在内存中的结构(HotSpot虚拟机)》

当Mark Word中最后两位的锁标志位是10的时候,Mark Word的前面是monitor监视器的地址,我现在就给你画出来对象头、Mark Word 和 monitor之间的关系图(32位):
三、monitor内部结构
monitor叫做对象监视器、也叫作监视器锁,JVM规定了每一个java对象都有一个monitor对象与之对应,这monitor是JVM帮我们创建的,在底层使用C++实现的。
其实monitor在底层也是某个类的对象,那个类就是ObjectMonitor,它拥有的属性也字段如下:
ObjectMonitor() { _header; _count ; // 非常重要,表示锁计数器,_count = 0表示还没人加锁,_count > 0 表示加锁的次数 _waiters; _recursions; _owner; // 非常重要,指向加锁成功的线程,_owner = null 时候表示没人加锁 _waitset; // wait线程的集合,在synchorized代码块中调用wait()方法的线程会被加入到此集合中沉睡,等待别人叫醒它 _waitsetLock; _responsiable; _succ; _cxq; _freenext; _entrylist; // 非常重要,等待队列,加锁失败的线程会被加入到这个等待队列中,等待再次争抢锁 _spinFreq; // 获取锁之前的自旋的次数 _spinclock; // 获取之前每次锁自旋的时间 ownerIsThread; }
3.1、monitor加锁原理
_count : 这个属性非常重要,直接表示有没有被加锁,如果没被线程加锁则 _count=0,如果_count大于0则说明被加锁了
_owner:这个属性也非常重要,直接指向加锁的线程,比如线程A获取锁成功了,则_owner = 线程A;当_owner = null的时候表示没线程加锁
_waitset:当持有锁的线程调用wait()方法的时候,那个线程就会释放锁,然后线程被加入到monitor的waitset集合中等待,然后线程就会被挂起。只有有别的线程调用notify将它唤醒。
_entrylist:这个就是等待队列,当线程加锁失败的时候被block住,然后线程会被加入到这个entrylist队列中,等待获取锁。
_spinFreq:获取锁失败前自旋的次数;JDK1.6之后对synchronized进行优化;原先JDK1.6以前,只要线程获取锁失败,线程立马被挂起,线程醒来的时候再去竞争锁,这样会导致频繁的上下文切换,性能太差了。
JDK1.6后优化了这个问题,就是线程获取锁失败之后,不会被立马挂起,而是每个一段时间都会重试去争抢一次,这个_spinFreq就是最大的重试次数,也就是自旋的次数,如果超过了这个次数抢不到,那线程只能沉睡了。
_spinClock:上面说获取锁失败每隔一段时间都会重试一次,这个属性就是自旋间隔的时间周期,比如50ms,那么就是每隔50ms就尝试一次获取锁。
下面通过图文展示加锁过程:
(1)首先呢,没有线程对monitor进行加锁的时候是这样的:

说明:_count = 0 表示加锁次数是0,也就是没线程加锁;_owner 指向null,也就是没线程加锁
(2)然后呢,这个时候线程A、线程B来竞争加锁了,如下图所示: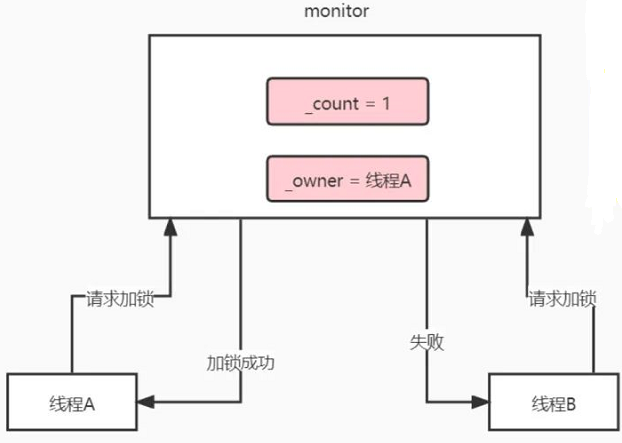
(3)线程A竞争到锁,将_count 修改为1,表示加锁次数为1,将_owner = 线程A,也就是指向自己,表示线程A获取到了锁。
在_count = 0,_owner = null的时候,表示monitor没人加锁,这个时候线程A和线程B同时请求加锁,也就是竞争将_count改为1。
由于线程A这哥们动作比较快,它将_count改为1,获取锁成功了。它还嘚瑟了一下,同时将_onwer = 线程A,表示自己获取了锁,告诉线程B,兄弟不好意思了,是我获取了锁,我先去操作了。
既然加锁就是将_count 设置为1,同时将_owner 指向自己。那反过来推测,释放锁的时候是不是将_count 设置为 0 , 将 _owner 设置为 null 就 OK了?是的,释放锁的过程就是这么简单:

加锁和释放锁说完了,我们接下来将的是_spinFreq、_spinclock、_entrylist这几个东西:
上面解释字段属性的时候说_spinFreq是等待锁期间自旋的次数、_spinclock是自旋的周期也就是每次自旋多久时间、_entrylist这个就是自旋次数用完了还没获取锁,只能放到_entrylist等待队列挂起了。
让我们继续接着图来讲:
(1)首先线程B获取锁的时候发现monitor已经被线程A加锁了
(2)然后monitor里面记录的_spinFreq 、spinclock 信息告诉线程B,你可以每隔50ms来尝试加锁一次,总共可以尝试10次
(3)如果线程B在10次尝试加锁期间,获取锁成功了,那线程B将_count 设置为 1,_owner 指向自己表示自己获取锁成功了
(4)如果10次尝试获取锁此时都用完了,那没辙了,它只能放到等待队列里面先睡觉去了,也就是线程B被挂起了
- _spinFreq和_spinclock 这两个monitor的属性主要是让线程自旋的时候使用的吧。
- entryList作用是当线程自旋次数都用完了之后,只能进入等待队列进行休眠了。
为啥线程B请求失败之后不直接进入队列挂起?而是要自旋之后再次尝试获取锁?
为啥不是一直自旋然后尝试获取锁,而是要设置一个最大尝试次数?
3.2、自旋优化
自旋优化,其实跟jvm获取monitor锁的优化有关,有什么好处:
(1)首先跟你说下,线程挂起之后唤醒的代价很大,底层涉及到上下文切换,用户态和内核态的切换,我打个比方可能最少耗时3000ms这样,这只是打个比方哈
(2)线程A获取了锁,这个时候线程B获取失败。按照上面自旋的数据_spinclock = 50ms(每次自旋50ms),_spinFreq = 10(最多10次自旋)
(3)假如线程A使用的时间很短,比如只使用150ms的时间;那么线程B自旋3次后就能获取到锁了,也就花费了150ms左右的时间,相比于挂起之后唤醒最少花费3000ms的时间,是不是大大减少了等待时间啊......,这也就提高了性能了。
(4)如果不设置自旋的次数限制,而是让它一直自旋。假如线程A这哥们耗时特别的久,比如它可能在里面搞一下磁盘IO或者网络的操作,花了5000ms!。
那线程B可不能在那一直自旋着等着它吧,毕竟自旋可是一直使用CPU不释放CPU资源的,CPU这时也在等着不能干别的事,这可是浪费资源啊,所以啊自旋次数也是要有限制的,不能一直等着,否则CPU的利用率大大被降低了。
所以在10次自旋之后,也就是500ms之后,还获取失败,那就把自己挂起,释放CPU资源咯。
举个例子:假如有两个人要上厕所,但是只有一个坑位,线程A去得比较早,先把坑位给占了:
(1)假如线程A加锁了,它只是上了个小厕所,用了150ms就完成了;然后线程B尝试几次之后就能获取成功了
(2)但是如果线程A拉肚子了,这家伙在里面蹲了一个多小时,线程B尝试了10次之后,发现坑还是没有空的。这个时候线程B发现自己还有好多代码没写,害~,不等了,先释放CPU去写写代码,待会再来看看......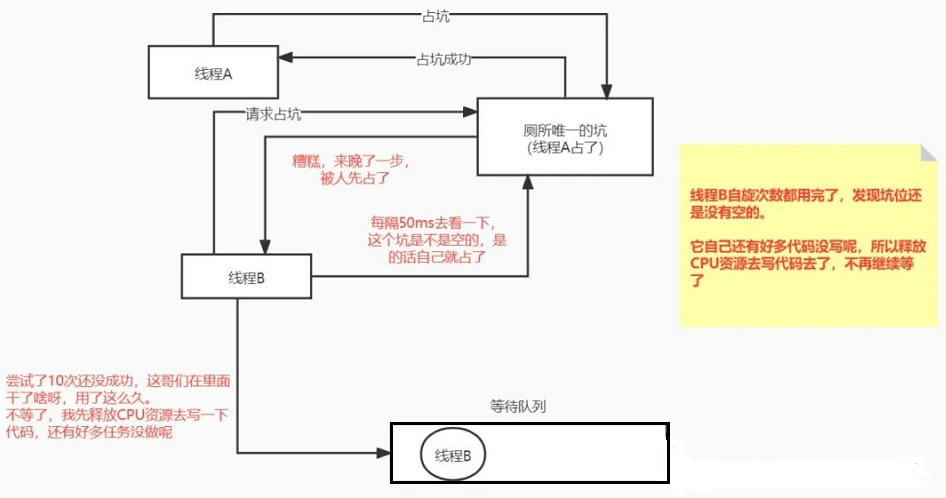
3.3、wait和notify
说起monitor里面的waitset,上面讲的就是一个集合。这个waitset集合存放的就是调用wait方法陷入而沉睡的线程。
必须是当线程获取锁之后,才能调用wait()方法,然后此时释放锁,将_count恢复为0,将_owner指向 null,然后将自己加入到waitset集合中,等待别人调用notify或者notifyAll将其中waitset的线程唤醒。
notify和notifyAll有啥区别啊?
简单说就是notify就是从waitset中随机挑一个线程来唤醒,只唤醒一个。notifyAll这方法就是将waitset中所有等着的线程全部唤醒了
示例:
线程A执行如下代码:
synchronized(this) { if (某个条件) { wait(); } }
线程B执行如下代码:
synchronized(this) { // 某些业务逻辑 ...... notify(); }
下面画个图来说一下: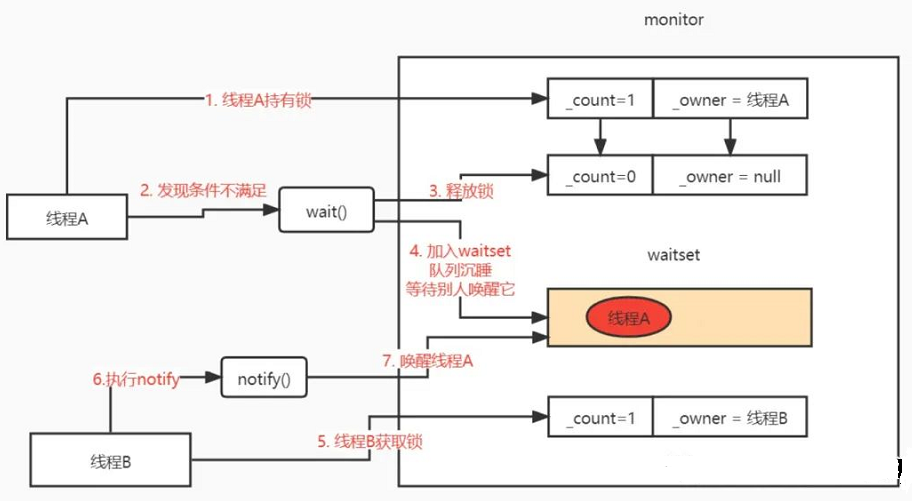
(1)首先啊还是线程A这哥们动作比较快,先获取到了锁。
(2)然后线程A发现条件不满足,想了想,算了,我先释放锁,睡个觉,等条件满足了,别人再唤醒我,岂不是美滋滋。于是释放了锁,睡觉去了
(3)然后线程B自己可以加锁了,执行了一些业务逻辑,然后去调用notify方法唤醒线程A,嘿兄弟,别睡了,到你了...
(4)线程A醒来之后,还是要再去去竞争锁的,也就是醒来之后还要竞争将_count修改为1,竞争_owner指向自己,毕竟它还在synchronized代码块内部嘛,只有获取锁之后才能执行synchronized代码块的代码。
所以只有它再次获取到锁了之后,才会执行代码块内部的逻辑。也即是wait和notify的原理了,也知道为啥要结合synchronized一起使用了,因为waitset集合是monitor对象的一个属性,所以调用之前必须要获取到monitor对象的操作权限,也就是获取到锁,notify要操作waitset也是一样。所以wait和notify方法之后在获取了锁之后才能调用的,所以才需要写在synchronized方法块的内部啊,进入synchronized获取锁了之后才能执行。
3.4、wait和sleep的区别
wait() 和 Thread.sleep()的区别,说wait()会释放锁,而Thread.sleep()不释放锁,
wait:
synchronized(this) {
// 这个时候线程释放锁,然后将自己放入monitor的waitset队列,
// 等待别人调用notify/notifyAll将唤醒
wait();
}sleep:
synchronized(this) {
// 这种情况不释放锁,就是睡个500ms然后醒来持有锁继续干活
Thread.sleep(500);
}四、synchronized的锁重入、锁优化、和锁升级的原理
4.1、synchronized锁重入
所谓锁重入,就是支持正在持有锁的线程支持再次获取锁,不会出现自己锁死自己的问题。
比如:
synchronized(this) { synchronized(this){ synchronized(this){ synchronized(this){ synchronized(this){ ........ } } } } }
可能对应下面的指令:
monitorenter
monitorenter
monitorenter
monitorenter
monitorenter
......
monitorexit
monitorexit
monitorexit
monitorexit
monitorexit
回顾之前讲的加锁就是将_count 由 0 设置为1,将_owner指向自己,这里的_owner指向加锁的线程。
(1)所以再次重入加锁执行monitorenter指令的时候,发现有人加锁了,同时检查_owner加锁的线程是不是自己的,如果是自己加锁的,只需要将_count 次数加1即可。
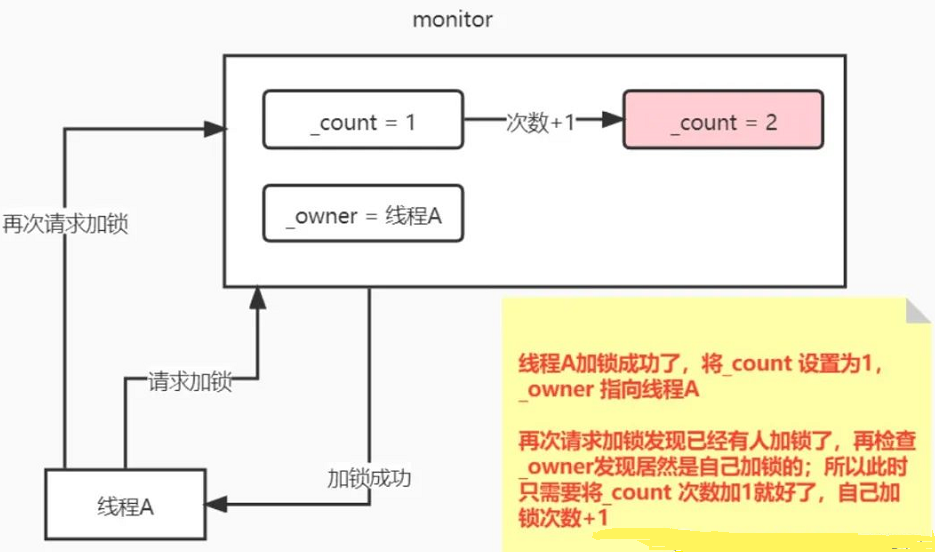
(2)同样,在释放锁的时候执行monitorexit指令,首先将_count进行减1,当_count 减少到0的时候表示自己释放了锁,然后将_owner 指向null。
所以,根据上诉锁重入的方式,代码进入了5次synchronized 相当于执行了5次monitorenter加锁,最后_count = 5。当5次monitorexit执行完了之后,_count = 0即释放了锁。
4.2、synchronized锁消除
锁消除,这个也很简单,就是在不存在锁竞争的地方使用了synchronized,jvm会自动帮你优化掉,比如说下面的这段代码:
public void business() { // lock对象方法内部创建,线程私有的,根本不会引起竞争 Object lock = new Object(); synchronized(lock) { i++; j++; // 其它业务操作 } }
上面的这段代码,由于lock对象是线程私有的,多个线程不会共享;像这种情况多线程之间没有竞争,就没必要使用锁了,就有可能被JVM优化成以下的代码:
public void business() { i++; j++; // 其它业务操作 }
示例2:
public void add(String str1,String str2){ StringBuffer sb = new StringBuffer(); sb.append(str1).append(str2); }
我们都知道 StringBuffer 是线程安全的,因为它的关键方法都是被 synchronized 修饰过的,但我们看上面这段代码,我们会发现,sb 这个引用只会在 add 方法中使用,不可能被其它线程引用(因为是局部变量,栈私有),因此 sb 是不可能共享的资源,JVM 会自动消除 StringBuffer 对象内部的锁。
这就是我理解的锁消除,只有一个线程会用到,不会引起多个线程竞争的;相当于就自己用,没必要加锁了。
4.3、synchronized锁升级
synchronized为什么要设计成可升级的锁呢?我理解的就是希望能尽量花费最小的代价能达到目的。是这个理由没错;但是你知道synchronized在什么锁的情况下花费什么代价吗?以及每次升级之后花费了什么代价吗?说这个之前,我先给你看一下前两章都讲解过Mark Word的图,我们再来回顾一下:

之前我们说过,Mark Word是一个32bit/64位的数据结构,最后两位表示的是锁标志位,当Mark Word的锁标志位不同的时候,代表Mark Word 中记录的数据不一样。
(1)比如锁模式标志位是,也就是最后两位是01的时候,表示处于无锁模式或者偏向锁模式。
- 无锁:如果此时偏向锁标志,倒数第3位,是0,即最后3位是001,表示当前处于无锁模式,此时Mark Word就常规记录对象hashcode、GC年龄信息。
- 偏向锁:倒数第3位是1,即Mark word最后3位是101,则表示当前处于偏向锁模式,那么Mark Word就记录者获取了偏向锁的线程ID、对象的GC年龄。
(2)轻量级锁:当锁模式标志位是00的时候,表示当前处于轻量级锁模式,此时会生成一个轻量级的锁记录,存放在获取锁的线程栈空间中,Mark Word此时就存储者这个锁记录的地址。
Mark Word存储的地址在哪个线程的栈空间中,就表示哪个线程获取到了轻量级锁。
(3)重量级锁:当锁模式标志位是10的时候,表示当前处于重量级锁模式,此时加锁就不是Mark Word的责任了,需要找monitor锁监视器,这个上一章我们已经讲解monitor加锁的原理了。
此时Mark Word就记录了一下monitor的地址,然后有线程找Mark Word的时候,Mark Word就把monitor地址给它,告诉线程自个根据这个地址找monitor进行加锁。
4.4、synchronized偏向锁
如果上表格所示,当有线程第一次进入synchronized的同步代码块之内,发现:
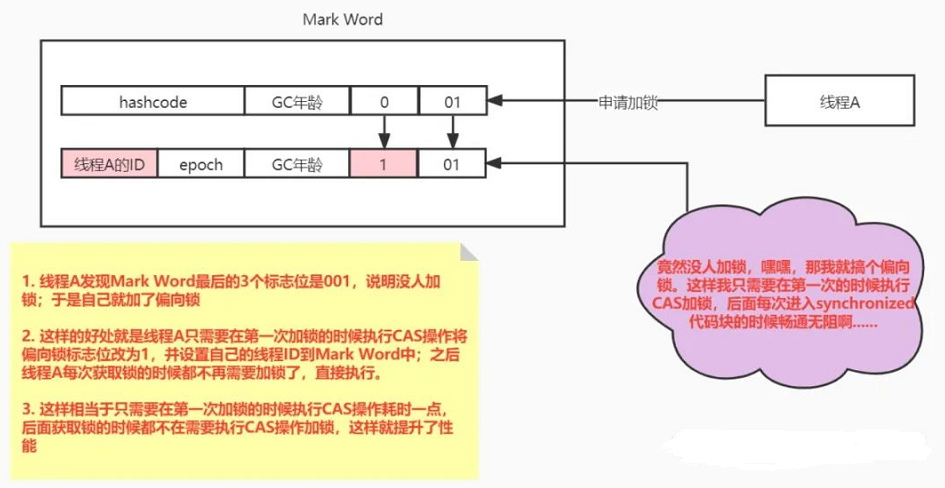
Mark Word的最后三位是001,表示当前无锁状态,说明锁的这时候竞争不激烈啊。
于是选择代价最小的方式,加了个偏向锁,只在第一次获取偏向锁的时候执行CAS操作(将自己的线程Id通过CAS操作设置到Mark Word中),同时将偏向锁标志位改为1。
后面如果自己再获取锁的时候,每次检查一下发现自己之前加了偏向锁,就直接执行代码,就不需要再次加锁了。
加了偏向锁的人确实是个自私的人,这家伙用完了锁之后,自己加锁时候修改过的Mark Word信息都不会再改回来了,也就是它不会主动释放锁。
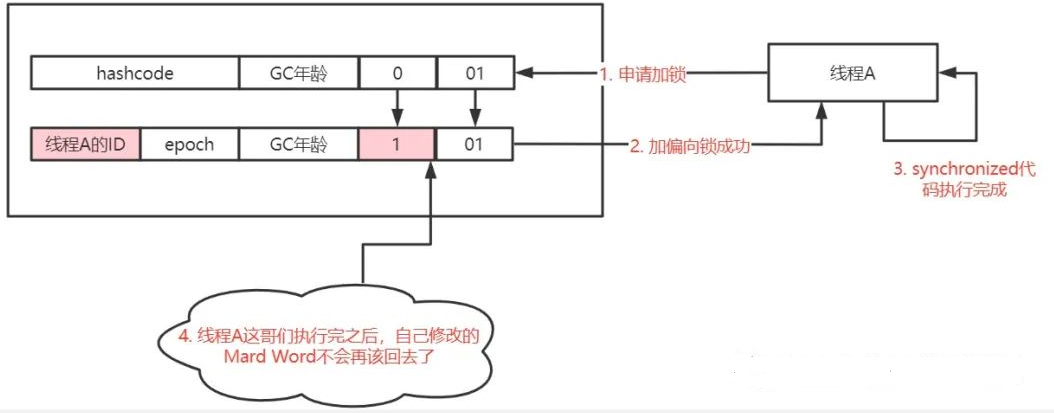
线程A不释放锁,如果它用完了,别人这个时候需要进入synchronized代码块怎么办?你说的这个问题啊,其实JVM的设计者也考虑到了,这就涉及到一个重偏向的问题。
4.5、偏向锁之重偏向
线程B去申请加锁,发现是线程A加了偏向锁;这时候回去判断一下线程A是否存活,如果线程A挂了,就可以重新偏向了,重偏向也就是将自己的线程ID设置到Mark Word中。
如果线程A没挂,但是synchronized代码块执行完了,这个时候也可以重新偏向了,将偏向标识指向自己,轮到我了,哈哈。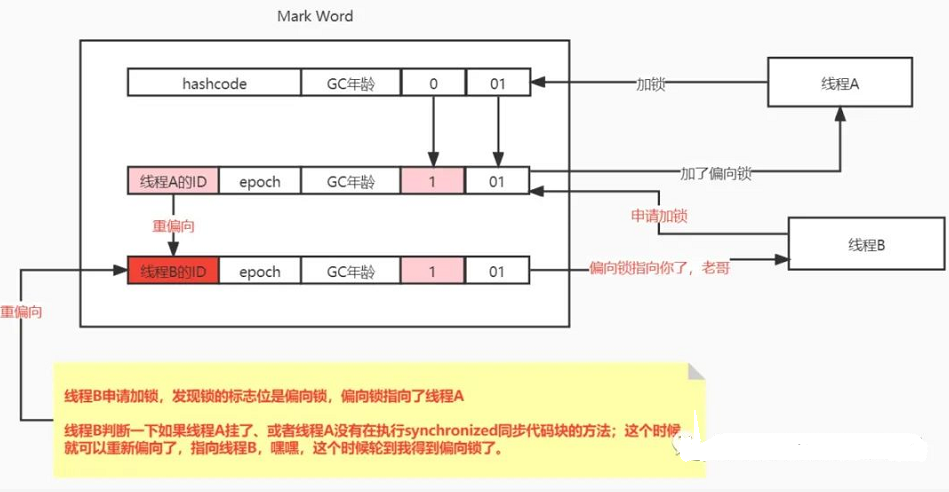
线程A用完了这家伙不把Mark Word标识改回来;没关系啊,线程B判断线程A没在synchronized同步代码块了,就执行重新偏向了。我还有个问题,就是如果线程B在申请获取锁的时候,线程A这哥们还没执行完synchronized同步代码块怎么办?这个时候就有锁的竞争了,这就需要将锁升级一下了,线程B就会把锁升级为轻量级锁。
4.5.2、偏向锁为什么要升级为轻量级锁?
// 代码块1 synchronized(this){ // 业务代码1 } // 代码块2 synchronized(this){ // 业务代码2 } // 代码块3 synchronized(this){ // 业务代码3 } // 代码块4 synchronized(this){ // 业务代码4 }
假如这个时候有线程A、B、C、D四个线程,线程A先加了偏向锁。之前讲过偏向锁只是在第一次获取锁的时候加锁,后面都是直接操作的不需要加锁。
这个时候其它几个线程B、C、D想要加锁,如果线程A连续执行上面4个代码块,那么其他线程看到线程A都在执行synchronized同步代码块,没完没了了,想重偏向都不行。
这个时候就需要等线程A执行完4个synchronized代码块之后才能获取锁啊,哈哈,别的线程都只能看线程A一个人自己在那表演了,这样代码就变成串行执行了。
多个线程竞争锁的时候为什么要升级明白了吧?下面我们进入锁升级的第一个级别,轻量级锁,讲之前,先回顾之前将的一个知识点:
4.6、轻量级锁
轻量级锁模式下,加锁之前会创建一个锁记录,然后将Mark Word中的数据备份到锁记录中(Mark Word存储hashcode、GC年龄等很重要数据,不能丢失了),以便后续恢复Mark Word使用。
这个锁记录放在加锁线程的虚拟机栈中,加锁的过程就是将Mark Word 前面的30位指向锁记录地址。所以mark word的这个地址指向哪个线程的虚拟机栈中,就说明哪个线程获取了轻量级锁。
就好比下面的图,线程A获取了轻量级锁,锁记录存在线程A的虚拟机栈中,然后Mark Word的前面30位存储锁记录的地址。

了解了轻量级加锁的原理之后,我们继续,来讲讲偏向锁升级为轻量级锁的过程:
(1)首先线程A持有偏向锁,然后正在执行synchronized块中的代码
(2)这个时候线程B来竞争锁,发现有人加了偏向锁并且正在执行synchronized块中的代码,为了避免上述说的线程A一直持有锁不释放的情况,需要对锁进行升级,升级为轻量级锁
(3)先将线程A暂停,为线程A创建一个锁记录Lock Record,将Mark Word的数据复制到锁记录中;然后将锁记录放入线程A的虚拟机栈中
(4)然后将Mark Word中的前30位指向线程A中锁记录的地址,将线程A唤醒,线程A就知道自己持有了轻量级锁
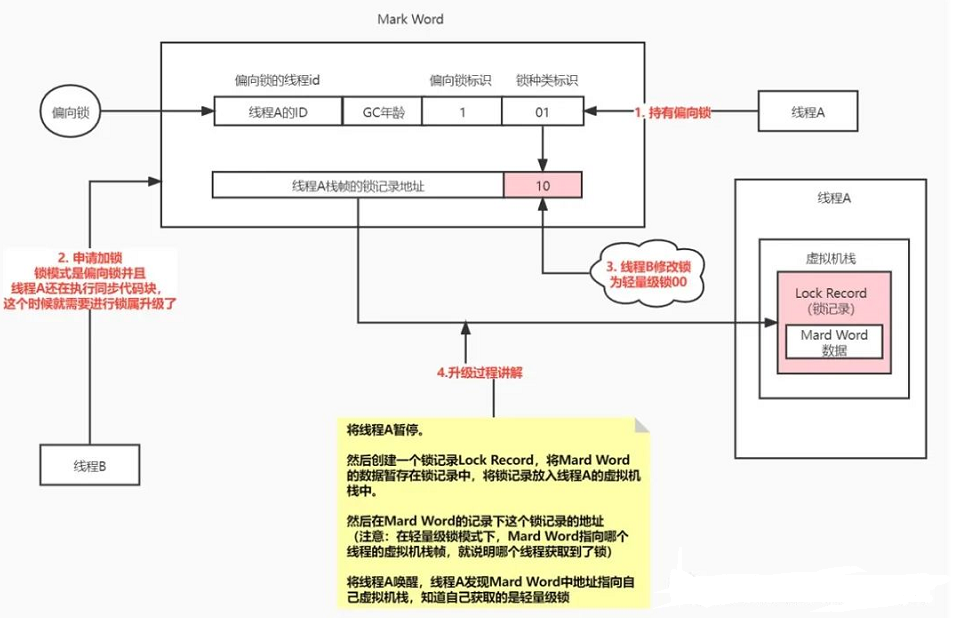
4.6.2、在轻量级锁模式下,多线程是怎么竞争锁和释放锁的?
(1)线程A和线程B同时竞争锁,在轻量级锁模式下,都会创建Lock Record锁记录放入自己的栈帧中
(2)同时执行CAS操作,将Mark Word前30位设置为自己锁记录的地址,谁设置成功了,锁就获取到锁
上面讲了加锁的过程,轻量级锁的释放很简单,就将自己的Lock Record中的Mark Word备份的数据恢复回去即可,恢复的时候执行的是CAS操作将Mark Word数据恢复成加锁前的样子。
4.7、重量级锁的自旋
在轻量级锁模式下获取锁失败的线程应该会怎么样?获取锁失败的线程应该会再去尝试吧?或者直接沉睡等待别人释放锁的时候将它唤醒?
两种其实都有可能,但是你觉得哪种花销会更小一点?
线程沉睡花费代价更大吧,这涉及到上下文切换,操作系统层次涉及到用户态转内核态,是一个非常重的操作。
既然线程沉睡和唤醒代价这么大,所以肯定是不会让线程轻易就沉睡的;
比如说线程沉睡再唤醒最少需要3000ms的时间,如果某个线程只使用锁150ms的时间就释放了,如果直接采用沉睡方式的话,这个时候synchronized的性能就太差了。
所以啊JVM的设计者,设计了一种方案,获取锁失败之后的线程自己先原地等一段时间,然后再去重试获取锁,这种方式就叫做自旋。但是JVM怎么知道要等多久呢,加入持有锁的那个人一直不释放锁,其他人要一直自旋等待,然后不断重复尝试吗?这样不是非常消耗CPU的资源的吗?
这里自旋多少次是有一个限制的,之前我们讲解monitor的底层原理的时候就讲解过了,如果忘记的话可以回去重新看一下。monitor有一个_spinFreq参数表示最大自旋的次数,_spinClock参数表示自旋的间隔时间。所以自旋最多会重试_spinFreq次。
每次失败之后等_spinClock的时间过后再去重试,如果尝试_spinFreq次之后都没有成功,那没辙了,只能沉睡了。
自旋其实是非常消耗CPU资源的,自旋期间相当于CPU啥也不干,就在那等着的。为了避免自旋时间太长,所以JVM就规定了默认最多自旋10次,10次还获取不到锁,那就直接将线程挂起了,线程就会直接阻塞等待了,这个时候性能就差了。
4.8、锁粗化 lock coarsening
public String test(String str){
int i = 0;
StringBuffer sb = new StringBuffer():
while(i < 100){
sb.append(str);
i++;
}
return sb.toString():
}
JVM 会检测到这样一连串的操作都对同一个对象加锁(while 循环内 100 次执行 append,没有锁粗化的就要进行 100 次加锁/解锁),此时 JVM 就会将加锁的范围粗化到这一连串的操作的外部(比如 while 虚幻体外),使得这一连串操作只需要加一次锁即可。
参考:https://mp.weixin.qq.com/s/jOd9tcqG8qnuoATZo8gFAw

 浙公网安备 33010602011771号
浙公网安备 33010602011771号