


etcd
二、etcd介绍
2.1 etcd发展背景与相关竞品介绍
2013年CoreOS创业团队在构建一款开源,轻量级的操作系统ContainerLinux时,为了应对用户服务多副本之间协调的问题,自研开发的一款用于配置共享和服务发现的高可用KV分布式存储组件——ETCD。
下面我们也针对Zookeeper和Consul两个选型做了一下对比:· ZooKeeper
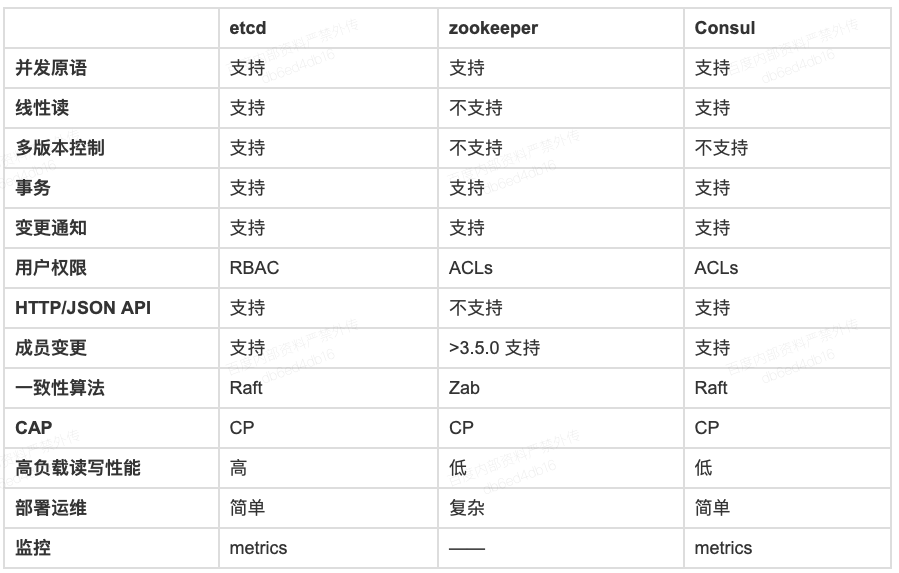
ZooKeeper从高可用性,数据一致性,功能这三个方面而言是完全符合需求的,但CoreOS还是坚持自研etcd的原因总结有以下两点:1. ZooKeeper不支持通过API安全地变更成员,需要人工修改节点配置并重启进程.如果操作有误,有可能导致脑裂等线上故障,同时CoreOS对适配云环境,集群规模的平滑调整,运行时配置的在线变更都是有期望目标的,这方面ZooKeeper的维护成本比较高。2. 高负载读写性能,ZooKeeper在大规模的实例连接情况下性能表现并不佳。
etcd名字是由“/etc”文件夹和”d”分布式系统组成。“/etc”文件夹是用来存储单系统配置数据的,而“etcd”用于存储大规模分布式系统的配置数据,etcd集群可提供高稳定性,高可靠性,高伸缩性和高性能的分布式KV存储服务。etcd是基于复制状态机实现的,由Raft一致性模块,日志模块,基于boltdb持久化存储的状态机组成,可应用于分布式系统的配置管理,服务发现,分布式一致性等等。
ZooKeeper与etcd一样,可解决分布式系统一致性和元数据存储等问题,但是etcd相较于ZooKeeper有以下几点优势:1. 动态集群成员关系重新配置2. 高负载下稳定的读写能力3. 多版本并发控制数据模型4. 可靠的键监控5. Lease(租约)原语将连接和会话分离6. 分布式锁保证API安全性7. ZooKeeper使用自己的RPC协议,使用受限;而etcd客户端协议是基于gRPC的,可支持多种语言。 · ConsulConsul与etcd解决的是不同的问题,etcd用于分布式一致性KV存储,而Consul侧重于端到端的服务发现,它提供了内置的健康检查,失败检测和DNS服务等等,另外Consul通过RESTfulHTTPAPIs提供KV存储能力.但是当KV使用量达到百万级时,会出现高延迟和内存压力等问题。
一致性算法方面,etcd、Consul基于Raft算法实现数据复制,ZooKeeper则是基于Zab算法实现。Raft算法由Leader选举,日志同步,安全性组成,而Zab协议则由Leader选举、发现、同步、广播组成。分布式CAP方面,etcd、Consul和ZooKeeper都是CP系统,发生网络分区时,无法写入新数据。
下表是针对三者的关键能力做了一下对比分析:
2.2 etcd核心技术介绍
基于Raft协议实现数据高可用和强一致性
早期数据存储服务引入多副本复制技术方案来解决单点问题,但是无论是主从复制还是去中性化复制,都存在一定的缺陷。主从复制运维困难,且一致性与可用性难以兼顾;去中心化复制,存在各种写入冲突问题需要业务处理。而分布式一致性算法,正是解决多副本复制存在问题的关键。分布式一致性算法,又称为共识算法,最早是基于复制状态机背景下提出来的。Paxos作为第一个共识算法,过于复杂,不容易理解,难以在工程上落地。斯坦福大学的Diego提出的Raft算法,通过将问题拆解为三个子问题,易于理解,降低了工程落地难度。这三个子问题是:Leader选举,日志复制,安全性。
Leader选举
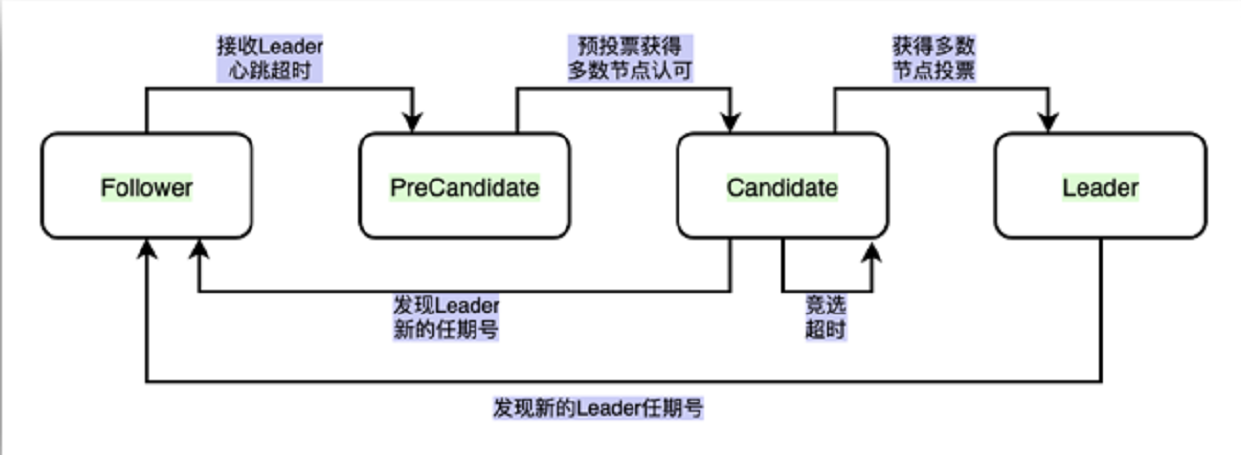
etcd(版本3.4+)中Raft协议定义集群节点有4种状态:Leader、Follower、Candidate、PreCandidate。
正常情况下,Leader节点会按照心跳间隔时间,定时广播心跳消息给Follower节点,以维持Leader身份。Follower收到后回复心跳应答包消息给Leader。Leader都会带有一个任期号(term),任期表示从一次选举开始,赢得选举的节点在该任期内担当Leader。任期号单调递增,在Raft算法中充当逻辑时钟,用于比较各个节点数据新旧,识别过期Leader等等。
当Leader节点异常时,Follower节点会接收Leader的心跳消息超时,当超时时间大于竞选超时时间后,会进入PreCandidate状态,不自增任期号,仅发起预投票(民意调查,防止由于节点数据远远落后于其他节点而发起无效选举),获得大多数节点认可后,进入Candidate状态.进入Candidate状态的节点,会等待一个随机时间,然后发起选举流程,自增任期号,投票给自己,并向其他节点发送竞选投票信息。
当节点B收到节点A竞选消息后,有2种情况:1. 节点B判断节点A的数据至少和自己一样新,节点A任期号大于节点B任期号,并且节点B未投票给其他候选者,即可投票给节点A,节点A获得集群大多数节点支持,可成为新Leader。2. 如果节点B也发起了选举,并投票给自己,那么它将拒绝投票给节点A。此时若没有节点可以得到大多数投票支持,则只能等待竞选超时,开启新一轮选举。
日志复制
Raft日志结构如下图所示:
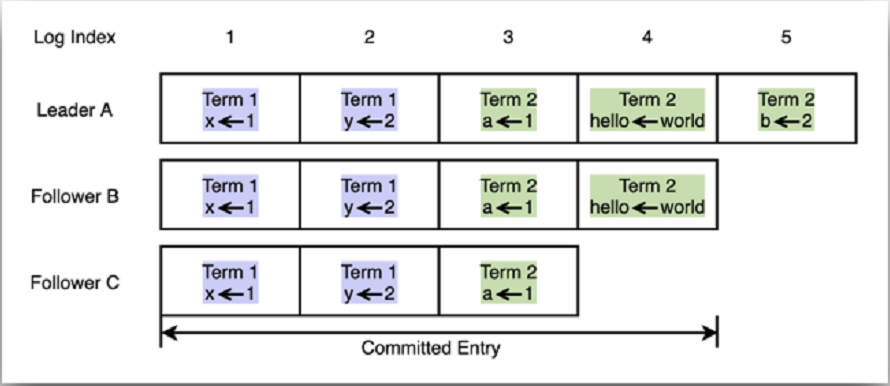
Raft日志由有序索引的一个个条目组成,每个日志条目包含了任期号和提案内容.Leader通过维护两个字段来追踪各个Follower的进度信息.一个是NextIndex,表示Leader发送给该Follower节点的下一个日志条目索引;另一个是MatchIndex,表示该Follower节点已复制的最大日志条目索引。
本文以Client提交“hello=world”提案,至接收到响应的整个流程为例,简单介绍etcd日志复制流程:1. 当Leader接收到Client提交的提案信息后,生成日志条目,同时遍历各个Follower的日志进度,生成对各个Follower追加日志的RPC消息;2. 通过网络模块将追加日志的RPC消息广播给各个Follower;3. Follower接收到追加日志消息并持久化之后,回复Leader已复制最大日志条目索引,即MatchIndex;4. Leader接收到Follower应答后,更新对应Follower的MatchIndex;5. Leader根据各个Follower提交的MatchIndex信息,计算出日志条目已提交索引位置,该位置代表日志条目被一半以上节点持久化;6. Leader通过心跳告知各个Follower已提交日志索引位置;7. 当Client的提案,被标识为已提交后,Leader回复Client该提案通过。通过以上流程,Leader同步日志条目给各个Follower,保证etcd集群的数据一致性。
安全性
etcd通过给选举和日志复制增加了一系列规则,来保证Raft算法的安全性。选举规则:1. 一个任期号,只能有一个Leader被选举,Leader选举需要集群一半以上节点支持;2. 节点收到选举投票时,如果候选者最新日志条目的任期号小于自己,拒绝投票,任期号相同但是日志比自己短,同样拒绝投票。日志复制规则:1. Leader完全特性,如果某个日志条目在某个任期号中已被提交,则这个日志条目必然出现在更大任期号的所有Leader中;2. 只附加原则,Leader只能追加日志条目,不能删除已持久化的日志条目;3. 日志匹配特性,Leader发送日志追加信息时,会带上前一个日志条目的索引位置(用P表示)和任期号,Follower接收到Leader的日志追加信息后,会校验索引位置P的任期号与Leader是否一致,一致才能追加。
boltdb存储技术
ectd的另一个核心技术是boltdb存储,提供高效的b+树的检索能力,同时支持事务操作,他是支撑etcd高性能读写的关键能力之一。boltdb的实现参见了LMDB(LightningMemory-MappedDatabase)设计思路,基于高效快速的内存映射数据库方案.基于B+树的结构设计。数据文件设计上bolt使用一个单独的内存映射的文件,实现一个写入时拷贝的B+树,这能让读取更快。而且,BoltDB的载入时间很快,特别是在从crash恢复的时候,因为它不需要去通过读log(其实它压根也没有)去找到上次成功的事务,它仅仅从两个B+树的根节点读取ID。
文件存储设计
由于采用了单文件映射存储,所以bolt对文件按指定长度进行分块处理,每块存储不同的内容类型。默认使用4096字节的长度进行分块。每一块的开头有单独的pageid(int64)标识。
文件块的类型有以下几种:
|
类型 |
Flag标识 |
个数 |
长度 |
说明 |
|
meta |
0x04 |
2 |
80字节。其余为空 |
元数据信息。包含存储B+树root buck位置,可用块的数量freelist,当前最大块的offset等。分为metaA与metaB, 用来控制进行中的事务与已完成的事务(写事务只有一个进行中). 根据meta中的txid的值的大小来判断当前生效的是哪个meta。(txid会根据事务操作递增) |
|
freelist |
0x10 |
1或多个 Overflow引用 |
变长 |
Freelist用于管理当前可用的pageid列表。由Meta元数据信息中的freelist字段来定位所在的pageid位置。 |
|
【data】bucket |
0x01 |
1或多个 Overflow引用 |
变长 |
存储bucket名称数据,bucket名称也是采用B+树结构存储。根root bucket的pageid由meat的root字段指定 |
|
【data】branch |
0x01 |
1或多个 Overflow引用 |
变长 |
存储分支数据内容。分支数据结构中只有key信息,没有value信息。指向的都是下一级节点的pageid信息 |
|
【data】leaf |
0x02 |
1或多个 Overflow引用 |
变长 |
存储叶子数据内容。 |
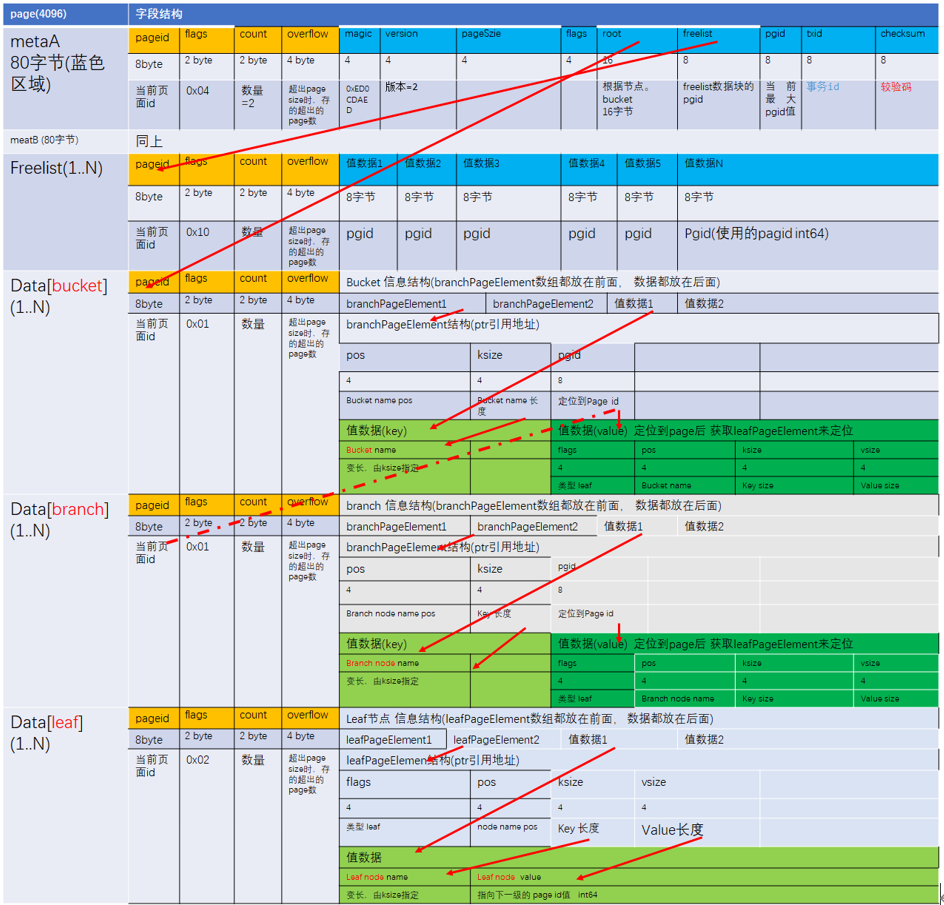
数据文件全景结构
说明:
- metapage固定在page0与page1位置
- Pagesize大小固定在4096字节
- bolt的文件写入采用了本地序(小端序)的模式,比如16进制0x0827(2087)写入的内容为2708000000000000
单文件方案的优势就是不需要做文件的合并删除等操作,只需要在原文件上追加扩展长度就可以了。
查询设计
boltdb提供了非常高效的查询能力,可以先看一下它的对象设计:
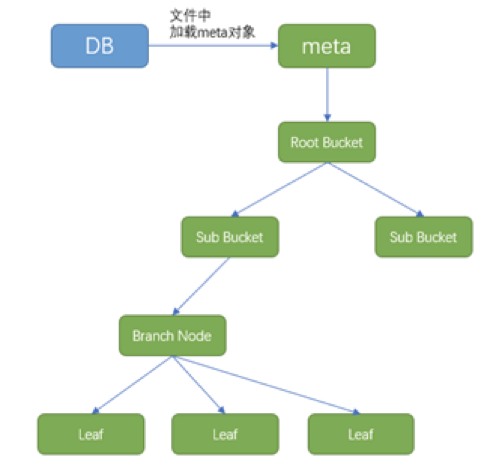
从对象设计上,boltdb在加载时,会先loadmeta数据进内存,然后根据bucket,来定位数据块所在的位置,然后再根据key的值,来定位branchnode的位置,然后定位到叶子值节点。 我们以查询为例,来讲解一下,下面是一个基本的查询示例代码:
tx, err := db.Begin(true) // 开启事务 if err != nil { return } b := tx.Bucket([]byte("MyBucket")) // 根据名称查询bucket v := b.Get([]byte("answer20")) // 根据key进行查询 fmt.Println(string(v)) tx.Commit()
对应上面的代码,下面的序列图,可以更详细的了解一次查询的操作流程:
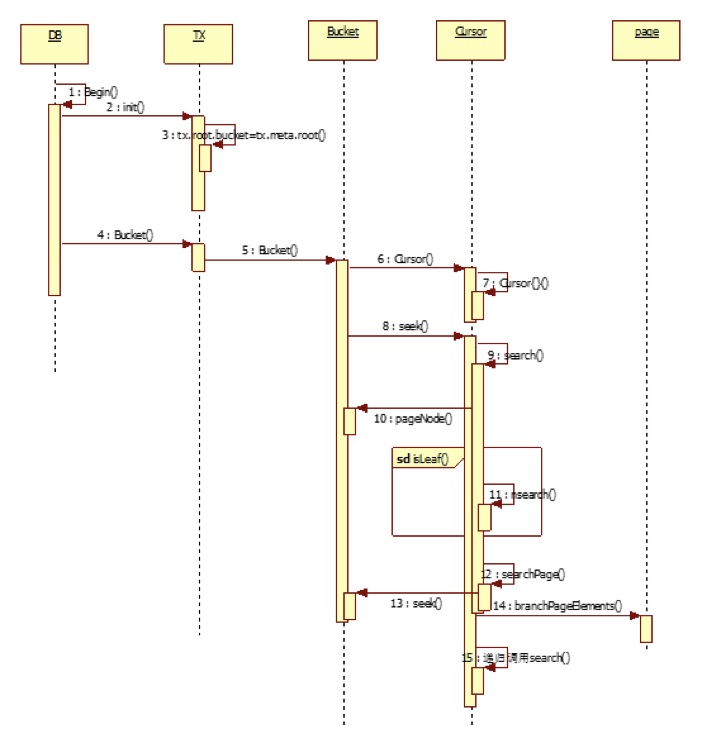
上面最关键的代码就是search方法,下面是主要的代码片断,已添加了注释说明方便阅读。
func (c *Cursor) search(key []byte, pgid pgid) { p, n := c.bucket.pageNode(pgid) if p != nil && (p.flags&(branchPageFlag|leafPageFlag)) == 0 { panic(fmt.Sprintf("invalid page type: %d: %x", p.id, p.flags)) } // 把当前查询节点(page,node)压入栈 e := elemRef{page: p, node: n} c.stack = append(c.stack, e) // If we're on a leaf page/node then find the specific node. if e.isLeaf() { c.nsearch(key) return } // if node cached seach by node's inodes field if n != nil { c.searchNode(key, n) return } // recursively to load branch page and call search child node again c.searchPage(key, p) }
https://mp.weixin.qq.com/s/1VmMZlMEv-In9QKYeYOjiA

 浙公网安备 33010602011771号
浙公网安备 33010602011771号