

批量计算和流式计算
一、数据集类型
现实世界中,所有的数据都是以流式的形态产生的,不管是哪里产生的数据,在产生的过程中都是一条条地生成,最后经过了存储和转换处理,形成了各种类型的数据集。如下图所示,根据现实的数据产生方式和数据产生是否含有边界(具有起始点和终止点)角度,将数据分为两种类型的数据集,一种是有界数据集,另外一种是无界数据集。
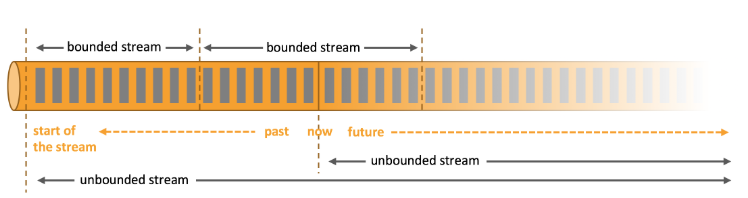
- 有界数据集
有界数据集具有时间边界,在处理过程中数据一定会在某个时间范围内起始和结束,有可能是一分钟,也有可能是一天内的交易数据。对有界数据集的数据处理方式被称为批计算(Batch Processing),例如将数据从RDBMS或文件系统等系统中读取出来,然后在分布式系统内处理,最后再将处理结果写入存储介质中,整个过程就被称为批处理过程。而针对批数据处理,目前业界比较流行的分布式批处理框架有Apache Hadoop和Apache Spark等。 - 无界数据集
对于无界数据集,数据从开始生成就一直持续不断地产生新的数据,因此数据是没有边界的,例如服务器的日志、传感器信号数据等。和批量数据处理方式对应,对无界数据集的数据处理方式被称为流式数据处理,简称为流处理(Streaming Process)。可以看出,流式数据处理过程实现复杂度会更高,因为需要考虑处理过程中数据的顺序错乱,以及系统容错等方面的问题,因此流处理需要借助专门的流数据处理技术。目前业界的Apache Storm、Spark Streaming、Apache Flink等分布式计算引擎都能不同程度地支持处理流式数据。 - 统一数据处理
有界数据集和无界数据集只是一个相对的概念,主要根据时间的范围而定,可以认为一段时间内的无界数据集其实就是有界数据集,同时有界数据也可以通过一些方法转换为无界数据。例如系统一年的订单交易数据,其本质上应该是有界的数据集,可是当我们把它一条一条按照产生的顺序发送到流式系统,通过流式系统对数据进行处理,在这种情况下可以认为数据是相对无界的。对于无界数据也可以拆分成有界数据进行处理,例如将系统产生的数据接入到存储系统,按照年或月进行切割,切分成不同时间长度的有界数据集,然后就可以通过批处理方式对数据进行处理。从以上分析我们可以得出结论:有界数据和无界数据其实是可以相互转换的。有了这样的理论基础,对于不同的数据类型,业界也提出了不同的能够统一数据处理的计算框架。
目前在业界比较熟知的开源大数据处理框架中,能够同时支持流式计算和批量计算,比较典型的代表分别为Apache Spark和Apache Flink两套框架。其中Spark通过批处理模式来统一处理不同类型的数据集,对于流数据是将数据按照批次切分成微批(有界数据集)来进行处理。Flink则从另外一个角度出发,通过流处理模式来统一处理不同类型的数据集。Flink用比较符合数据产生的规律方式处理流式数据,对于有界数据可以转换成无界数据统一进行流式,最终将批处理和流处理统一在一套流式引擎中,这样用户就可以使用一套引擎进行批计算和流计算的任务。
前面已经提到用户可能需要通过将多种计算框架并行使用来解决不同类型的数据处理,例如用户可能使用Flink作为流计算的引擎,使用Spark或者MapReduce作为批计算的引擎,这样不仅增加了系统的复杂度,也增加了用户学习和运维的成本。而Flink作为一套新兴的分布式计算引擎,能够在统一平台中很好地处理流式任务和批量任务,同时使用流计算模式更符合数据产生的规律,相信Flink会在未来成为众多大数据处理引擎的一颗明星。
二、实时计算、离线计算、流式计算和批量计算分别是什么?有什么区别?
大数据的计算模式主要分为批量计算(batch computing)、流式计算(stream computing)、交互计算(interactive computing)、图计算(graph computing)等。其中,流式计算和批量计算是两种主要的大数据计算模式,分别适用于不同的大数据应用场景。
流数据(或数据流)是指在时间分布和数量上无限的一系列动态数据集合体,数据的价值随着时间的流逝而降低,因此必须实时计算给出秒级响应。流式计算,顾名思义,就是对数据流进行处理,是实时计算。批量计算则统一收集数据,存储到数据库中,然后对数据进行批量处理的数据计算方式。主要体现在以下几个方面:
1、数据时效性不同:流式计算实时、低延迟, 批量计算非实时、高延迟。
2、数据特征不同:流式计算的数据一般是动态的、没有边界的,而批处理的数据一般则是静态数据。
3、应用场景不同:流式计算应用在实时场景,时效性要求比较高的场景,如实时推荐、业务监控...批量计算一般说批处理,应用在实时性要求不高、离线计算的场景下,数据分析、离线报表等。
4、运行方式不同,流式计算的任务持续进行的,批量计算的任务则一次性完成。
流式处理可以用于两种不同场景: 事件流和持续计算。
1、事件流
事件流具能够持续产生大量的数据,这类数据最早出现与传统的银行和股票交易领域,也在互联网监控、无线通信网等领域出现、需要以近实时的方式对更新数据流进行复杂分析如趋势分析、预测、监控等。简单来说,事件流采用的是查询保持静态,语句是固定的,数据不断变化的方式。
2、持续计算
比如对于大型网站的流式数据:网站的访问PV/UV、用户访问了什么内容、搜索了什么内容等,实时的数据计算和分析可以动态实时地刷新用户访问数据,展示网站实时流量的变化情况,分析每天各小时的流量和用户分布情况;
比如金融行业,毫秒级延迟的需求至关重要。一些需要实时处理数据的场景也可以应用Storm,比如根据用户行为产生的日志文件进行实时分析,对用户进行商品的实时推荐等。
五、流式计算的价值
通过大数据处理我们获取了数据的价值,但是数据的价值是恒定不变的吗?显然不是,一些数据在事情发生后不久就有了更高的价值,而且这种价值会随着时间的推移而迅速减少。流处理的关键优势在于它能够更快地提供洞察力,通常在毫秒到秒之间。
流式计算的价值在于业务方可在更短的时间内挖掘业务数据中的价值,并将这种低延迟转化为竞争优势。比方说,在使用流式计算的推荐引擎中,用户的行为偏好可以在更短的时间内反映在推荐模型中,推荐模型能够以更低的延迟捕捉用户的行为偏好以提供更精准、及时的推荐。
流式计算能做到这一点的原因在于,传统的批量计算需要进行数据积累,在积累到一定量的数据后再进行批量处理;而流式计算能做到数据随到随处理,有效降低了处理延时。
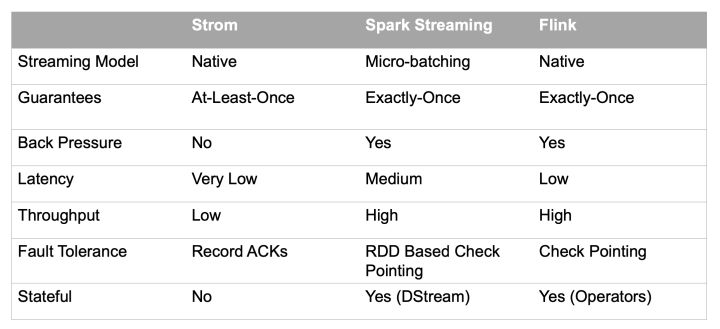
目前主流的流式计算框架有Storm、Spark Streaming、Flink三种,其基本原理如下:
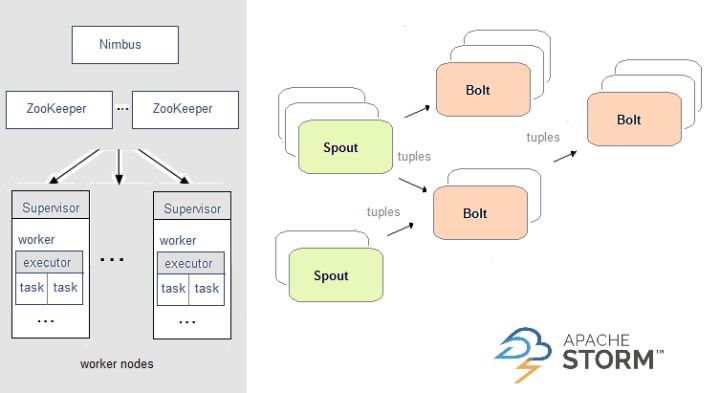
Apache Storm
在Storm中,需要先设计一个实时计算结构,我们称之为拓扑(topology)。之后,这个拓扑结构会被提交给集群,其中主节点(master node)负责给工作节点(worker node)分配代码,工作节点负责执行代码。在一个拓扑结构中,包含spout和bolt两种角色。数据在spouts之间传递,这些spouts将数据流以tuple元组的形式发送;而bolt则负责转换数据流。
Apache Spark
Spark Streaming,即核心Spark API的扩展,不像Storm那样一次处理一个数据流。相反,它在处理数据流之前,会按照时间间隔对数据流进行分段切分。Spark针对连续数据流的抽象,我们称为DStream(Discretized Stream)。 DStream是小批处理的RDD(弹性分布式数据集), RDD则是分布式数据集,可以通过任意函数和滑动数据窗口(窗口计算)进行转换,实现并行操作。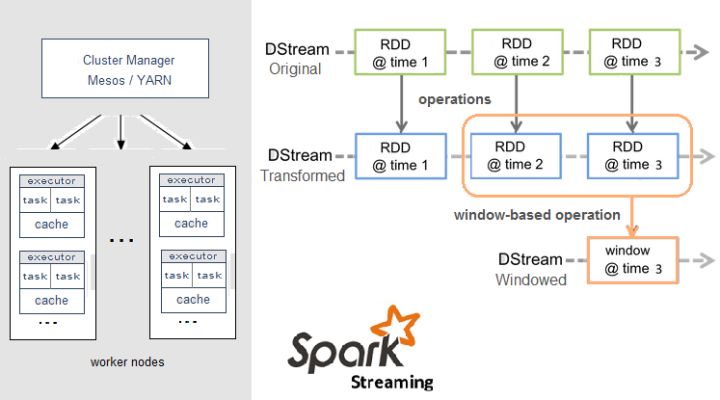
Apache Flink
针对流数据+批数据的计算框架。把批数据看作流数据的一种特例,延迟性较低(毫秒级),且能够保证消息传输不丢失不重复。
Flink创造性地统一了流处理和批处理,作为流处理看待时输入数据流是无界的,而批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。Flink程序由Stream和Transformation这两个基本构建块组成,其中Stream是一个中间结果数据,而Transformation是一个操作,它对一个或多个输入Stream进行计算处理,输出一个或多个结果Stream。
这三种计算框架的对比如下:
原文链接:https://blog.csdn.net/Jack__iT/java/article/details/103266486

 浙公网安备 33010602011771号
浙公网安备 33010602011771号