
PG优化实战系列-从22s到20ms全纪录
最近现场开发抛回一个性能问题,有个简单SQL查询很慢,需要家里DBA进行优化。
表T1
| rksj | area_id | 其他字段 |
| 时间字段 | 区域ID |
表情况:
当前总量7000万,日数据量800万,后期保存两周,无分区。
对应查询SQL:
select 字段1,字段2,字段3.... from T1 where rksj>1608134400 and area_id in (select unnest(area_childs_id) from t2 where area_id=1111);
对应执行计划如下:
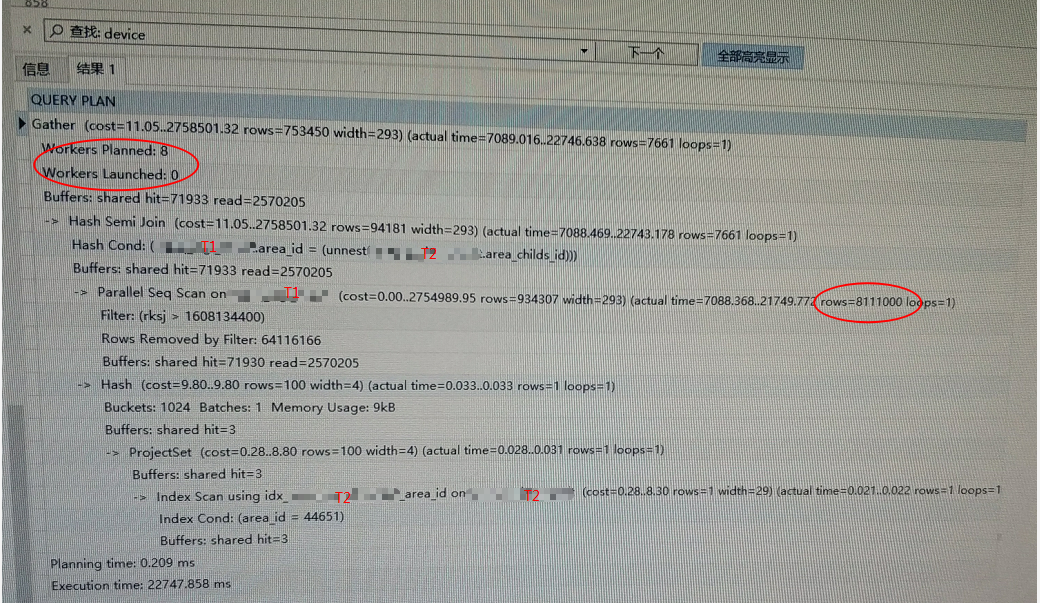
可以看到在过滤性这么差的情况下T1表选择对rksj进行全表扫描,还有磁盘读,过滤800万。T2表利用索引过滤一条,和T1表用in进行条件过滤SQL没啥问题,问题出在并行全表扫描。

从上图 T1表索引可以看到,存在rksj单列和area_id、rksj多列索引。
尝试调试参数:
set enable_seqscan=0; select 字段1,字段2,字段3.... from T1 where rksj>1608134400 and area_id in (select unnest(area_childs_id) from t2 where area_id=1111);
对应执行计划:
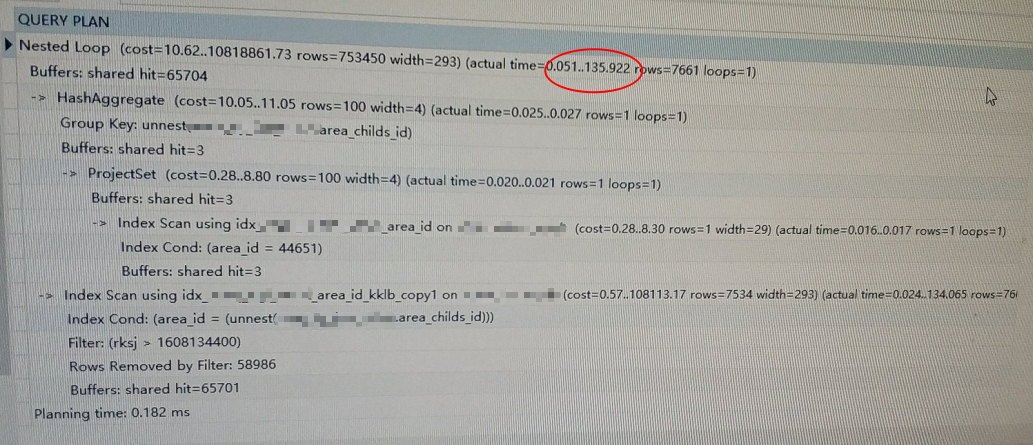
可以看到T1走了area_id的索引之后,速度有大幅度提升;更优的索引方式应该是area_id+rksj的组合索引。那为啥执行计划选择走并行全表扫描而不是走索引呢?
问题排查:
从第一个执行计划可以看到走了并行,询问现场得知这个是新装环境,之前在现场排查的时候遇到过配置文件被修改的情况;
show parallel_setup_cost; --0 默认值1000 show parallel_tuple_cost; --0 默认值0.1 show enable_bitmapscan; --off 默认值on #好家伙这三个参数又变成这个了,看来安装包存在很大问题(查看安装包,证实确实存在问题) show random_page_cost;--1(此参数存在争议,现场用的是STAT做的raid5,理论上不应该是4,应该设置成2或者3,但是很多现场设置成4是不走索引的,故而被改成了1;但是在该现场优化过程中遇到过因为此参数导致走顺序扫描快的sql走了索引导致速度反而慢)
关于这个参数:建议单盘STAT设置成4,SSD设置成1,STAT盘做的raid5设置成2或3
将前三个参数改成默认值,重启PG
set enable_seqscan=1; select 字段1,字段2,字段3.... from T1 where rksj>1608134400 and area_id in (select unnest(area_childs_id) from t2 where area_id=1111);
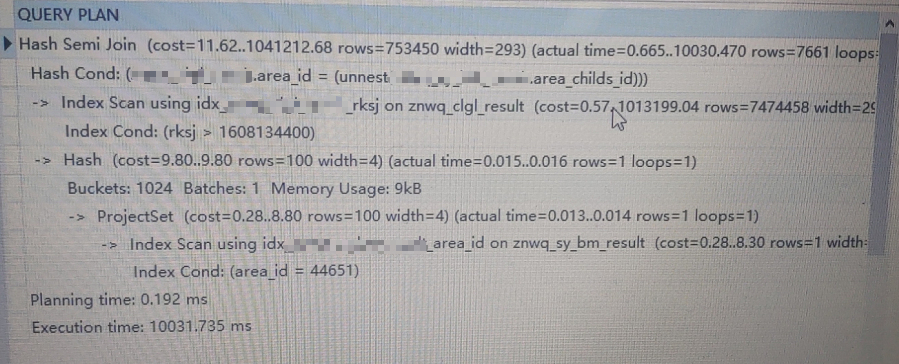
从上面的执行计划可以看到PG还是固执的选择了走rksj的数据,前面我们知道这个表每天800万数据量,而业务的SQL全是取一天的数据;
set enable_seqscan=1; select 字段1,字段2,字段3.... from T1 where rksj>1608134400 and area_id in (select unnest(area_childs_id) from t2 where area_id=1111) limit 100;
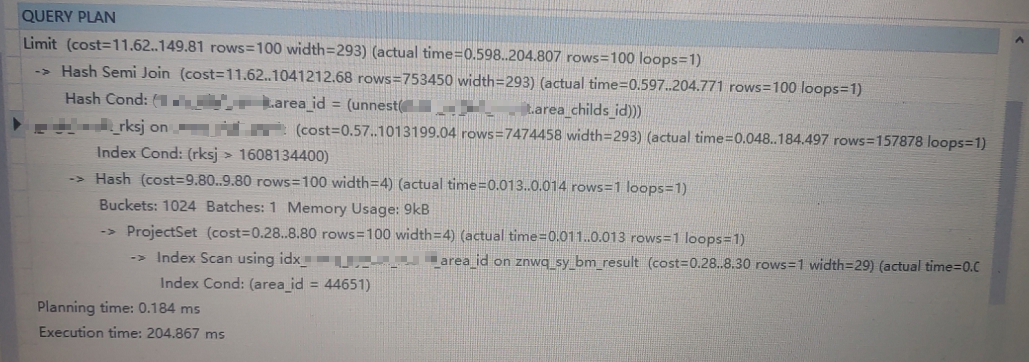
从执行计划可以看到在加了分页情况下,取前100条耗时204ms;很容易理解为什么加了limit会变快(简单说就是扫描满足返回100行的数据就够了),但是并未解决根本原因,分页约到后面越慢;
那通过以上分析,基本上问题定位是:1、参数设置有问题;2、执行计划错误的选择了索引;3、表结构设计存在问题;4、SQL未加limit分页
问题解决:
1、修改会默认参数
2、确认此索引只用在过滤当天整天的SQL上,无意义可以删掉rksj单列索引(如果此索引有别的用途,不能删除,可使用pg_hint_plan强制走指定索引)
3、改造成分区表,分区规则:按天分区;减少非必要数据的扫描。
4、实际代码中都加了的,但是依旧要强调必须要分页,关于分页到后面速度越慢,可以看另外一篇博客《PG_SQL优化》--SQL后面添加limit
实际效果(未改造成分区表,未加limit分页效果):
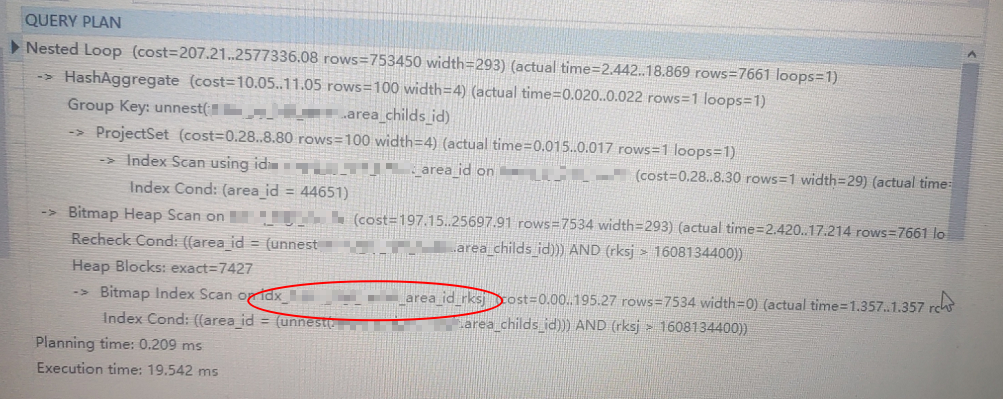
速度直接从22s优化到了20ms

 浙公网安备 33010602011771号
浙公网安备 33010602011771号