
redis 哨兵原理及部署
概念
传统的Redis的主从复制模式下,一旦主节点由于故障不能提供服务,需要人工将从节点晋升为主节点,同时还要通知应用方更新主节点地址,对于很多应用场景这种故障处理的方式是无法接受的,在这种情况下Redis-Sentinel在2.8版本孕育而生。
分布式的Redis-Sentinel系统用于管理多个redis主从复制,主要任务是:
- Monitoring:监控redis主从节点、sentinel节点是否正常
- Notification:在某个被监控的redis节点出现问题时,通过配置的脚本向管理员通知
- Failover:当redis主节点挂掉时,sentinel自动从slave节点中选取合适的节点作为主节点,同时让其他节点指向该新节点进行复制;当客户端试图连接失效的主节点时,新的主从也会向客户端返回新主节点的地址,继续为业务提供服务,保证高可用。
安装部署
主从复制搭建
参数配置
|
配置文件:redis.conf Master节点: requirepass foobared repl-disable-tcp-nodelay no repl-ping-slave-period 10 repl-backlog-size 100mb repl-timeout 60 bind 0.0.0.0 Slave节点: slaveof 127.0.0.1 6380 requirepass foobared masterauth foobared replica-read-only yes replica-priority 100 |
参数解释:
|
Master节点: requirepass:auth密码 repl-disable-tcp-nodelay:用于控制是否关闭TCP_NODELAY,默认关闭 ·当关闭时,主节点产生的命令数据无论大小都会及时地发送给从节点,这样主从之间延迟会变小,但增加了网络带宽的消耗。适用于主从之间的网络环境良好的场景,如同机架或同机房部署。 ·当开启时,主节点会合并较小的TCP数据包从而节省带宽。默认发送时间间隔取决于Linux的内核,一般默认为40毫秒。这种配置节省了带宽但增大主从之间的延迟。适用于主从网络环境复杂或带宽紧张的场景,如跨机房部署。 repl-ping-slave-period:主节点默认每隔10秒对从节点发送ping命令,判断从节点的存活性和连接状态 repl-backlog-size:复制积压缓冲区最大大小 repl-timeout:如果超过repl-timeout配置的值(默认60秒),则判定从节点下线并断开复制客户端连接。即使主节点判定从节点下线后,如果从节点重新恢复,心跳检测会继续进行。
Slave节点 slaveof {masterHost} {masterPort} :主节点ip 端口 masterauth {password}:主节点认证 slave-read-only yes #从节点设置为只读 replica-priority 100 #slave的优先级,用于哨兵切换 |
状态监控
|
Master节点: 127.0.0.1:6380> INFO replication # Replication role:master #角色 connected_slaves:1 #当前有效slave数 slave0:ip=127.0.0.1,port=6381,state=online,offset=9696885,lag=1 #从节点上报的心跳信息 master_replid:b783787c8e7736baaad756a32e0a91fd406a4f03 master_replid2:fe592d0e9ec25cec0ca0cabf084610f6c639f8ec master_repl_offset:9696885 #master节点复制偏移量 second_repl_offset:660230 repl_backlog_active:1 #是否开启复制缓冲区 repl_backlog_size:1048576 #复制缓冲区大小,单位B repl_backlog_first_byte_offset:8648310 #起始偏移量,计算当前缓冲区可用范围 repl_backlog_histlen:1048576 #已保存数据的有效长度。
Slave节点: 127.0.0.1:6381> INFO replication # Replication role:slave master_host:127.0.0.1 master_port:6380 master_link_status:up master_last_io_seconds_ago:1 master_sync_in_progress:0 slave_repl_offset:9741118 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:b783787c8e7736baaad756a32e0a91fd406a4f03 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:9741118 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:8692543 repl_backlog_histlen:1048576 |
Redis-Sentinel部署
|
角色 |
IP |
Port |
备注 |
|
Master |
127.0.0.1 |
6380 |
|
|
Slave |
127.0.0.1 |
6381 |
|
|
Sentinel-1 |
127.0.0.1 |
26379 |
|
|
Sentinel-2 |
127.0.0.1 |
26380 |
|
|
Sentinel-3 |
127.0.0.1 |
26381 |
|
参数配置
|
redis-sentinel-26379.conf port 26379 daemonize yes logfile "26379.log" dir /opt/soft/redis/data sentinel monitor mymaster 127.0.0.1 6380 2 sentinel down-after-milliseconds mymaster 30000 sentinel parallel-syncs mymaster 1 sentinel failover-timeout mymaster 180000 sentinel auth-pass mymaster foobared #sentinel notification-script <master-name> <script-path> #sentinel client-reconfig-script <master-name> <script-path> |
其他节点sentinel配置除port不同其他全部一致
|
参数解释: sentinel monitor <master-name> <ip> <port> <quorum>: master-name:监控的名字(任意) ip port:master节点ip端口,不需要配置从节点信息 quorum:代表要判定主节点最终不可达所需要的票数 sentinel down-after-milliseconds <master-name> <times>: 每个Sentinel节点都要通过定期发送ping命令来判断Redis数据节点和其余Sentinel节点是否可达,如果超过了down-after-milliseconds配置的时间且没有有效的回复,则判定节点不可达,<times>(单位为毫秒) sentinel parallel-syncs <master-name> <nums>: 故障转移后每次向新的主节点发起复制操作的从节点个数 sentinel failover-timeout <master-name> <times>: 故障转移超时时间 sentinel auth-pass <master-name> <password>: master节点的密码 sentinel notification-script <master-name> <script-path>: 在故障转移期间,当一些警告级别的Sentinel事件发生(指重要事件,例如-sdown:客观下线、-odown:主观下线)时,会触发对应路径的脚本,并向脚本发送相应的事件参数 sentinel client-reconfig-script <master-name> <script-path>: 在故障转移结束后,会触发对应路径的脚本,并向脚本发送故障转移结果的相关参数。和notification-script类似 |
启动
启动方式有两种,两者本质上一样:
- 使用redis-sentinel命令:
redis-sentinel redis-sentinel-26379.conf
- 使用redis-server命令加 --sentinel参数:
redis-server redis-sentinel-26379.conf --sentinel
状态查看
|
[root@KSlave redis-5.0.9]# redis-cli -p 26379 127.0.0.1:26379> info sentinel # Sentinel sentinel_masters:1 sentinel_tilt:0 sentinel_running_scripts:0 sentinel_scripts_queue_length:0 sentinel_simulate_failure_flags:0 master0:name=mymaster,status=ok,address=127.0.0.1:6380,slaves=1,sentinels=2 |
API
|
sentinel masters 展示所有被监控的主节点状态以及相关的统计信息 sentinel get-master-addr-by-name<master name> 返回指定<master name>主节点的IP地址和端口 sentinel failover<master name> 对指定<master name>主节点进行强制故障转移(没有和其他Sentinel节点“协商”),当故障转移完成后,其他Sentinel节点按照故障转移的结果更新自身配置,这个命令在Redis Sentinel的日常运维中非常有用 sentinel ckquorum<master name> 检测当前可达的Sentinel节点总数是否达到<quorum>的个数。例如quorum=3,而当前可达的Sentinel节点个数为2个,那么将无法进行故障转移,Redis Sentinel的高可用特性也将失去 sentinel flushconfig 将Sentinel节点的配置强制刷到磁盘上,这个命令Sentinel节点自身用得比较多,对于开发和运维人员只有当外部原因(例如磁盘损坏)造成配置文件损坏或者丢失时,这个命令是很有用的。 sentinel is-master-down-by-addr <ip> <port> <current_epoch> <runid> ·ip:主节点IP。 ·port:主节点端口。 ·current_epoch:当前配置纪元。 ·runid:此参数有两种类型,不同类型决定了此API作用的不同。 当runid等于“*”时,作用是Sentinel节点直接交换对主节点下线的判定。 当runid等于当前Sentinel节点的runid时,作用是当前Sentinel节点希望目 标Sentinel节点同意自己成为领导者的请求 |
客户端连接
客户端连接的必要性
主节点挂掉了,虽然Redis Sentinel可以完成故障转移,但是客户端无法获取这个变化,那么使用Redis Sentinel的意义就不大了,所以各个语言的客户端需要对Redis Sentinel进行显式的支持。
原理逻辑
实现一个Redis Sentinel客户端的基本步骤如下:
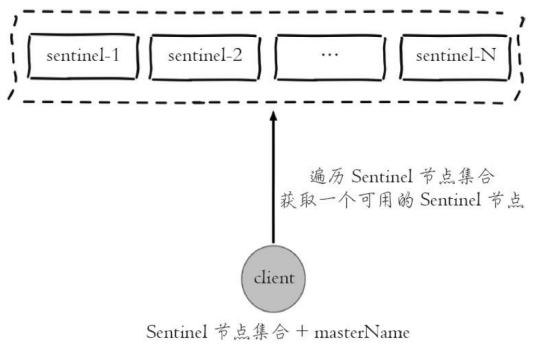
1) 遍历Sentinel节点集合获取一个可用的Sentinel节点,Sentinel节点之间可以共享数据,所以从任意一个Sentinel节点获取主节点信息都是可以的。
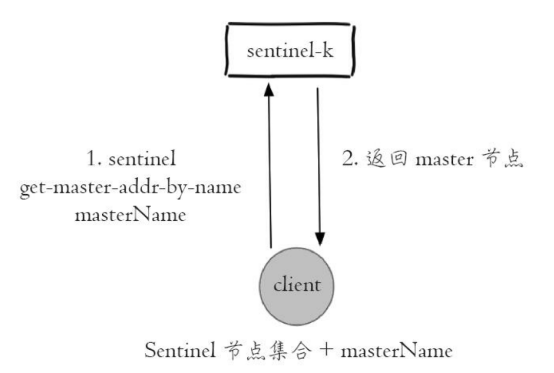
2) 通过sentinel get-master-addr-by-name master-name这个API来获取对应主节点的相关信息
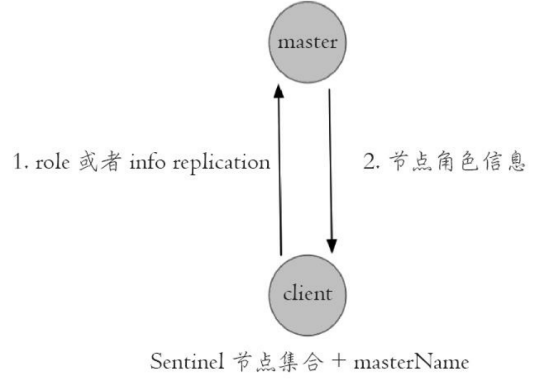
3) 验证当前获取的“主节点”是真正的主节点,这样做的目的是为了防止故障转移期间主节点的变化
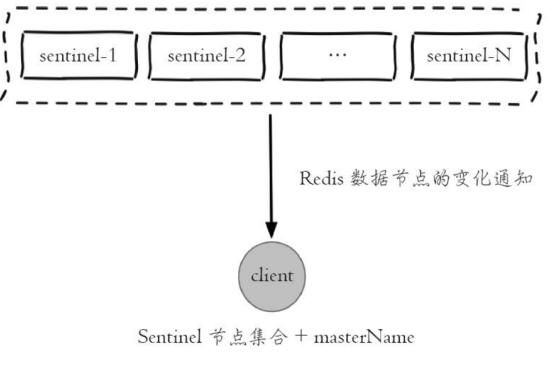
4) 保持和Sentinel节点集合的“联系”,时刻获取关于主节点的相关“信息”
Python客户端连接
|
#!/usr/bin/env python import redis from redis.sentinel import Sentinel
# 连接哨兵服务器(主机名也可以用域名) sentinel = Sentinel([('127.0.0.1', 26379),('127.0.0.1', 26380),('127.0.0.1', 26381)],socket_timeout=0.5)
# 获取主服务器地址 master = sentinel.discover_master('mymaster')
# 获取从服务器地址 slave = sentinel.discover_slaves('mymaster')
# 获取主服务器进行写入 master = sentinel.master_for('mymaster', socket_timeout=0.5, password='foobared', db=0) string1 = master.set('hello', 'world') # 输出:True
# # 获取从服务器进行读取(默认是round-roubin) slave = sentinel.slave_for('mymaster', socket_timeout=0.5, password='foobared', db=0) string1 = slave.get('hello') print(string1) |
Sentinel工作原理分析
下面介绍Redis Sentinel的基本实现原理,具体包含以下几个方面:Redis Sentinel的三个定时任务、主观下线和客观下线、Sentinel领导者选举、故障转移
三个定时任务
一套合理的监控机制是Sentinel节点判定节点不可达的重要保证,Redis
Sentinel通过三个定时监控任务完成对各个节点发现和监控:
1)每隔10秒,每个Sentinel节点会向主节点和从节点发送info命令获取最新的拓扑结构
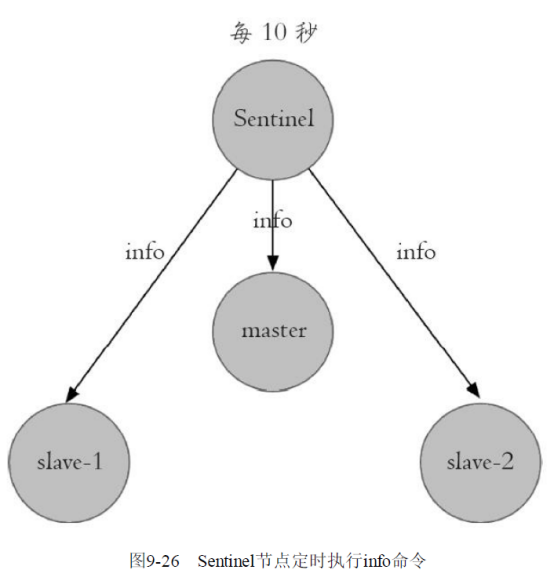
例如在master节点执行info replication指令,可以获取到slave节点的信息,这也是为什么配置sentinel的时候不需要配置slave节点信息的原因。
这个定时任务的作用具体可以表现在三个方面:
·通过向主节点执行info命令,获取从节点的信息,这也是为什么Sentinel节点不需要显式配置监控从节点。
·当有新的从节点加入时都可以立刻感知出来。
·节点不可达或者故障转移后,可以通过info命令实时更新节点拓扑信息。
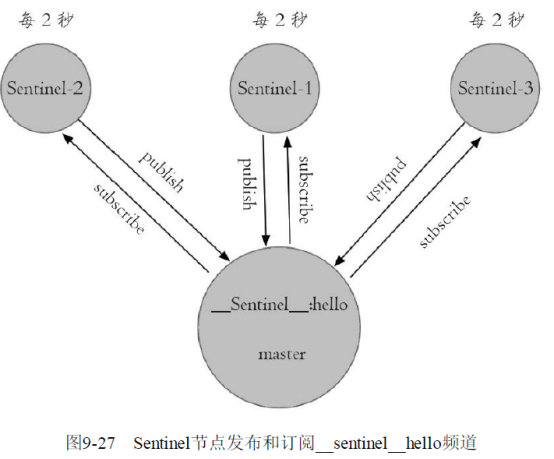
2)每隔2秒,每个Sentinel节点会向Redis数据节点的__sentinel__:hello频道上发送该Sentinel节点对于主节点的判断以及当前Sentinel节点的信息,同时每个Sentinel节点也会订阅该频道,来了解其他Sentinel节点以及它们对主节点的判断,所以这个定时任务可以完成以下两个工作:
·发现新的Sentinel节点:通过订阅主节点的__sentinel__:hello了解其他的Sentinel节点信息,如果是新加入的Sentinel节点,将该Sentinel节点信息保存起来,并与该Sentinel节点创建连接。
·Sentinel节点之间交换主节点的状态,作为后面客观下线以及领导者选举的依据。
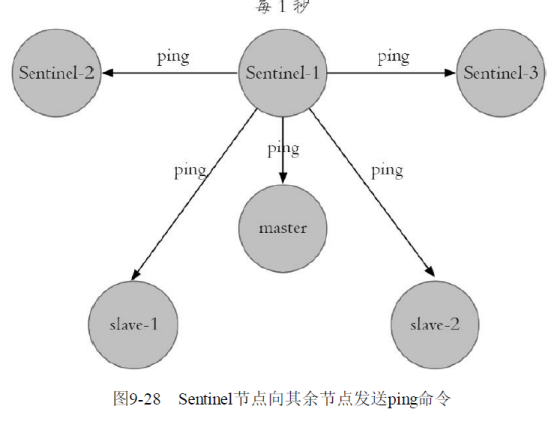
3)每隔1秒,每个Sentinel节点会向主节点、从节点、其余Sentinel节点发送一条ping命令做一次心跳检测,来确认这些节点当前是否可达。通过上面的定时任务,Sentinel节点对主节点、从节点、其余Sentinel节点都建立起连接,实现了对每个节点的监控,这个定时任务是节点失败判定的重要依据。
客观下线和主观下线
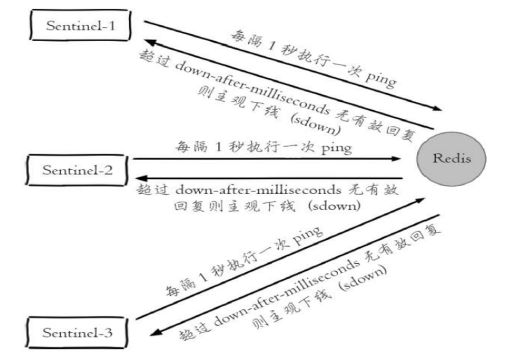
1.主观下线
每个Sentinel节点会每隔1秒对主节点、从节点、其他Sentinel节点发送ping命令做心跳检测,当这些节点超过down-after-milliseconds没有进行有效回复,Sentinel节点就会对该节点做失败判定,这个行为叫做主观下。从字面意思也可以很容易看出主观下线是当前Sentinel节点的一家之言,存在误判的可能。
2.客观下线
当Sentinel主观下线的节点是主节点时,该Sentinel节点会通过sentinel ismaster-down-by-addr命令向其他Sentinel节点询问对主节点的判断,当超过<quorum>个数,Sentinel节点认为主节点确实有问题,这时该Sentinel节点会做出客观下线的决定,这样客观下线的含义是比较明显了,也就是大部分Sentinel节点都对主节点的下线做了同意的判定,那么这个判定就是客观的
领导者Sentinel节点选举
假如Sentinel节点对于主节点已经做了客观下线,那么是不是就可以立即进行故障转移了?当然不是,实际上故障转移的工作只需要一个Sentinel节点来完成即可,所以Sentinel节点之间会做一个领导者选举的工作,选出一个Sentinel节点作为领导者进行故障转移的工作。Redis使用了Raft算法实现领导者选举,Redis Sentinel进行领导者选举的大致思路:
1)每个在线的Sentinel节点都有资格成为领导者,当它确认主节点主观下线时候,会向其他Sentinel节点发送sentinel is-master-down-by-addr命令,要求将自己设置为领导者。
2)收到命令的Sentinel节点,如果没有同意过其他Sentinel节点的sentinel is-master-down-by-addr命令,将同意该请求,否则拒绝。
3)如果该Sentinel节点发现自己的票数已经大于等于max(quorum,num(sentinels)/2+1),那么它将成为领导者。
4)如果此过程没有选举出领导者,将进入下一次选举。
故障转移
领导者选举出的Sentinel节点负责故障转移,具体步骤如下:
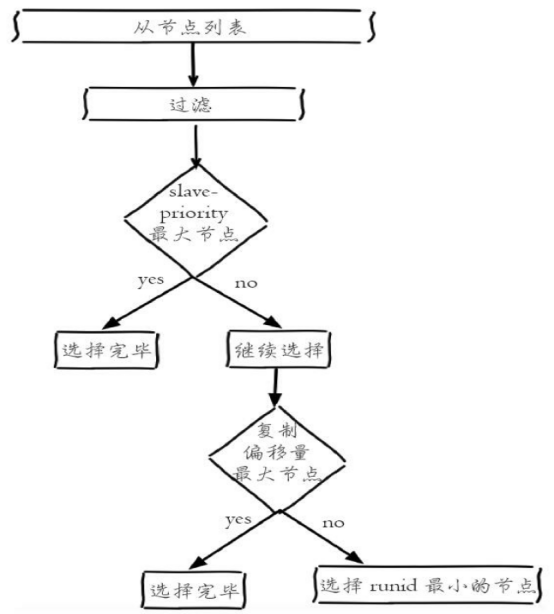
1)在从节点列表中选出一个节点作为新的主节点,选择方法如下:
a)过滤:“不健康”(主观下线、断线)、5秒内没有回复过Sentinel节点ping响应、与主节点失联超过down-after-milliseconds*10秒。
b)选择slave-priority(从节点优先级)最高的从节点列表,如果存在则返回,不存在则继续。
c)选择复制偏移量最大的从节点(复制的最完整),如果存在则返回,不存在则继续。
d)选择runid最小的从节点
2)Sentinel领导者节点会对第一步选出来的从节点执行slaveof no one命令让其成为主节点。
3)Sentinel领导者节点会向剩余的从节点发送命令,让它们成为新主节点的从节点,复制规则和parallel-syncs参数有关。
4)Sentinel节点集合会将原来的主节点更新为从节点,并保持着对其关注,当其恢复后命令它去复制新的主节点
运维提示
主从复制
master_repl_offset-offset 字节量,判断主从节点复制相差的数据量,根据这个差值判定当前复制的健康度。如果主从之间复制偏移量相差较大,则可能是网络延迟或命令阻塞等原因
根据统计指标,可算出复制积压缓冲区内的可用偏移量范围: [repl_backlog_first_byte_offset,repl_backlog_first_byte_offset+repl_backlog_histlen]
每个Redis节点启动后都会动态分配一个40位的十六进制字符串作为运行ID。运行ID的主要作用是用来唯一识别Redis节点,比如从节点保存主节点的运行ID识别自己正在复制的是哪个主节点
主节点持久化会影响性能,可能导致阻塞,应在从节点上进行持久化容灾
主节点首次同步以及主节点重启后runid会变化,从节点检测到主节点runid变化之后会干掉slave节点上的数据,重新全量复制。 此外如果repl-backlog-size(复制积压缓冲区)不足,也会导致全量复制,所以合理的大小应该根据:net_break_time:网络中断的时长, write_size_per_minute写命令数据量 可以统计高峰期主节点每秒info replication的master_repl_offset差值,保证repl_backlog_size>net_break_time*write_size_per_minute,从而避免因复制积压缓冲区不足造成的全量复制。 |
Sentinel日志说明
|
Sentinel节点发布订阅频道 |
|
|
状态 |
说明 |
|
+reset-master <instance details> |
主节点被重置 |
|
+slave <instance details> |
一个新的从节点被发现并关联 |
|
+failover-state-reconf-slaves instance details> |
故障转移进入 reconf- slaves状态 |
|
+s1ave- reconf-sent< instance detai1s> |
领导者 Sentinel节点命令其他从节点复制新的主节点 |
|
+slave-reconf-inprog <instance details> |
从节点正在重新配置主节点的 slave,但是同步过程尚未完成 |
|
+s1ave- reconf-done< instance details> |
其余从节点完成了和新主节点的同步 |
|
+sentinel <instance details> |
一个新的 sentinel节点被发现并关联 |
|
+sdown <instance details> |
添加对某个节点被主观下线 |
|
-sdown <instance details> |
撤销对某个节点被主观下线 |
|
+adown <instance details> |
添加对某个节点被客观下线 |
|
-adown <instance details> |
撤销对某个节点被客观下线 |
|
+new-epoch < instance details> |
当前纪元被更新 |
|
+try-failover < instance details> |
故障转移开始 |
|
+elected-leader <instance details> |
选出了故障转移的 Sentinel节点 |
|
+failover- state- select-save <instance details> |
故障转移进入 select-s1ave状态(寻找合适的从节点) |
|
no-good-slave <instance details> |
没有找到适合的从节点 |
|
selected-slave <instance details> |
找到了适合的从节点 |
|
failover- sta te-send- slaves-none <instance details> |
故障转移进入 failover- state-send- slaves-oone状态(对找到的从节点执行s1 ageof no one) |
|
failover-end-for-timeout <instance details> |
故障转移由于超时而终止 |
|
failover-end <instance details> |
故障转移顺利完成 |
|
switch-master <master name><oldip><oldport> <newip><newport> |
更新主节点信息,这个是许多客户端重点关注的 |
<instance details>格式如下:
|
<instance-type> <name> <ip> <port> @ <master-name> <master-ip> <master-port> |
指定特定Slave作为新master节点
将其他从节点的slavepriority配置为0,然后在任意sentinel节点执行sentinel failover;但是需要注意failover后,将slave-priority调回原值。
|
#非新master节点 CONFIG SET replica-priority 0 #任意sentinel节点 redis-cli-6 -p 26379 sentinel failover mymaster |
Sentinel的数量
Sentinel的领导者选举机制为:max(quorum,num(sentinels)/2+1),因此建议最小为3个

 浙公网安备 33010602011771号
浙公网安备 33010602011771号