MongoDB
uri = 'mongodb://user:pass@39.108.29.203:27017/database'
client = MongoClient(uri)

保存图片(二进制)
from pymongo import MongoClient
from gridfs import *
import os
#链接mongodb
client=MongoClient('localhost',27017)
#取得对应的collection
db=client.image
#本地硬盘上的图片目录
dirs = 'H:\PYTHON-DUJUN\day999-spider\db\mongodb'
#列出目录下的所有图片
files = os.listdir(dirs)
#遍历图片目录集合
for file in files:
#图片的全路径
filesname = dirs + '\\' + file
#分割,为了存储图片文件的格式和名称
f = file.split('.')
#类似于创建文件
datatmp = open(filesname, 'rb')
#创建写入流
imgput = GridFS(db)
#将数据写入,文件类型和名称通过前面的分割得到
insertimg=imgput.put(datatmp,content_type=f[1],filename=f[0])
datatmp.close()
print("保存成功")
提取图片(二进制)
from pymongo import MongoClient
from gridfs import *
client=MongoClient('localhost',27017)
db=client.image
#给予girdfs模块来写出,其中collection为上一步生成的,我不知道怎么该名称。实际上是由fs.flies和fs.chunks组成
gridFS = GridFS(db, collection="fs")
count=0
for grid_out in gridFS.find():
count+=1
print(count)
data = grid_out.read() # 获取图片数据
outf = open('%s.png' %count,'wb')#创建文件
outf.write(data) # 存储图片
print('ok')
outf.close()
https://www.cnblogs.com/zhangxinqi/p/9242687.html

自建一个json格式的数据


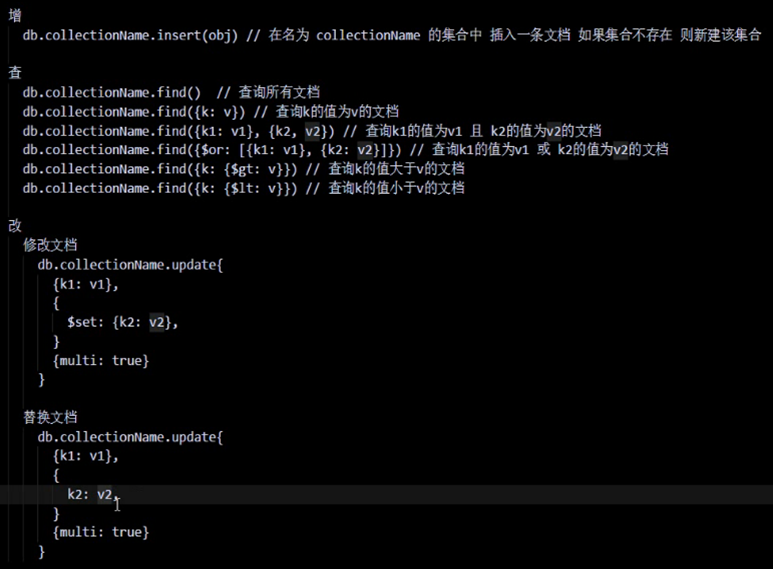


mongodb curd
https://www.imooc.com/article/21772
那为什么要用mongo来存呢?
首先、数据关系复杂,没有表连接,结构化弱。
然后、利用mongo全文索引查找方便
最好、数据不重要,记录的日志数据库。意外丢失风险可以接受。
说了这么多,接下来幕客先给大家说说对mongo的CURD,如下:
一、安装mongo的支持
sudo /opt/python2.7.13/bin/pip install pymongo
二、简单操作
1) 数据库实例创建
In [1]: import pymongo
In [2]: pymongo.MongoClient('192.168.8.237',27017)
Out[2]: MongoClient(host=['192.168.8.237:27017'], document_class=dict, tz_aware=False, connect=True)
In [3]: mgc = pymongo.MongoClient('192.168.8.237',27017)2)插入数据
In [4]: db = mgc['iops']
In [10]: col.insert_one(content)
Out[10]: <pymongo.results.InsertOneResult at 0x104907e60>3)数据查找,确认插入成功
> db.logrecord.find()
{ "_id" : ObjectId("5a27b65dfa121a84df126d8c"), "status" : "success", "stepid" : 2, "stepinfo" : "ok! finished", "taskid" : 23432 }4)直接通过python的对象获取内容
In [12]: col.find_one()
Out[12]:
{u'_id': ObjectId('5a27b65dfa121a84df126d8c'),
u'status': u'success',
u'stepid': 2,
u'stepinfo': u'ok! finished',
u'taskid': 23432}(5) 通过查询条件查询
查询成功的内容
In [13]: col.find_one({'status':'success'})
Out[13]:
{u'_id': ObjectId('5a27b65dfa121a84df126d8c'),
u'status': u'success',
u'stepid': 2,
u'stepinfo': u'ok! finished',
u'taskid': 23432}(6) 更新数据
col.update_one({"stepid":2},{"$set":{"stepid":3}})(7) 获取所有的集合
相当于show tables获取集合操作
In [11]: db.collection_names()
Out[11]: [u'opts', u'logrecord']mongo常用命令
show dbs //显示数据库
use theDb //进入某DB
show collections //显示该DB下所有表
创建表
db.createCollection("myColl") //建立myColl表
搜出collection中的数据
db.myColl.find(); 查找myColl表中的所有记录
db.myColl.find().limit(10) 查找myColl表中的10条记录
清空collection表中的所有数据
db.myColl.remove({}) 清空myColl表中的所有数据
删除表
db.myColl.drop()删除此表
统计数据
db.myColl.count() //统计myColl表记录数
使用$in operator 修改多条Doc:
db.inventory.update(
{ tags: { $in: ["appliances", "school"] } },
{ $set: { sale:true } }
)
更多方法是用命令
db.mycoll.help()
获取第一条/最早添加的数据
这个小伙伴们应该指定,如果是nodejs的api中之间使用user.findOne()就能找到,但是直接在mongo使用是不行滴:
但是我们可以这样做:
db.users.find({}).limit(1)
取出所有的再限制只取一条:
这样就成功取出了第一条。
获取最后一条/最晚添加的数据
这个似乎也没有直接可以使用的api接口哦。
所以我们想起来每一个文档都有一个ObjectId,而这个ObjectId是有带时间性质的哦,我们可以先按_id进行倒序排列,再取第一条,就OK了:
db.users.find({}).sort({_id:-1}.limit(1)
这样就成功取出了最后一条,
接着再验证试试:
可以发现最新插入的被取出来了,OK,没有问题。
导入 导出表数据
apt-get update
apt-get upgrade
apt-get install lrzsz
mongoexport --host localhost --port 27017 --collection schedules --db crawlab_test --out schedules.json
mongoimport --host localhost --port 27017 --collection schedules --db crawlab_test --file /opt/schedules.json

 浙公网安备 33010602011771号
浙公网安备 33010602011771号