《手把手教你》系列技巧篇(十一)-java+ selenium自动化测试-元素定位大法之By tag name(详细教程)
1.简介
按宏哥计划,本文继续介绍WebDriver关于元素定位大法,这篇介绍By ClassName。看到ID,NAME这些方法的讲解,小伙伴们和童鞋们应该知道,要做好Web自动化测试,最好是需要了解一些前端的基本知识。有了前端知识,做元素定位会很轻松,同样写网络爬虫也很有帮助,话题扯远了,回到Selenium自动化测试。tagName是DOM结构的一部分,其中页面上的每个元素都是通过输入标签,按钮标签或锚定标签等标签定义的。每个标签都具有多个属性,例如ID,名称,值类等。就其他定位符而言在Selenium中,我们使用了标签的这些属性值来定位元素。 对于Selenium中的tagName定位器,我们将仅使用标签名称来标识元素。
何时在Selenium中使用此tagName定位符? 好吧,在没有属性值(如ID,类或名称)并且倾向于定位元素的情况下,您可能不得不依靠在Selenium中使用tagName定位器。 例如,如果您希望从表中检索数据,则可以使用< td >标记或< tr >标记检索数据。
同样,在希望验证链接数量并验证它们是否正常工作的情况下,您可以选择通过anchor标签定位所有此类链接。
请注意:在一个简单的基本场景中,仅通过标签定位元素,这可能会导致识别大量值并可能导致问题。 在这种情况下,Selenium将选择或定位与您端提供的标签匹配的第一个标签。 因此,如果要定位单个元素,请不要在Selenium中使用tagName定位器。
2.常用定位方法(8种)
(1)id
(2)name
(3)class name
(4)tag name(今天讲解)
(5)link text
(6)partial link text
(7)xpath
(8)css selector
3.自动测试实战
跟随宏哥的脚步,有了前边两篇的经验,想必这个应该很简单的了吧!宏哥这里就不赘述了,没有前菜直接上正菜。
3.1当前标签没有重复值
当前标签没有重复值,所有可以直接用find_element***定位元素,和前边讲述的都差不多。宏哥这里以博客园为例,获取博客园的title。
3.1.1主要步骤
1、打开浏览器
2、通过tagname进行查找元素,findelement返回的数值没有重复的,那就是一个。
3.1.2代码设计
通过主要步骤把代码都设计好了,宏哥只需要将其串起来,调试脚本即可。如下图所示:

3.1.3参考代码
package lessons; import java.util.concurrent.TimeUnit; import org.openqa.selenium.By; import org.openqa.selenium.Keys; import org.openqa.selenium.WebDriver; import org.openqa.selenium.WebElement; import org.openqa.selenium.chrome.ChromeDriver; import org.openqa.selenium.firefox.FirefoxDriver; /** * @author 北京-宏哥 * * 2021年7月28日 */ public class ByTagName { public static void main(String[] args) throws Exception { // System.setProperty("webdriver.gecko.driver", ".\\Tools\\chromedriver.exe"); //指定驱动路径 // // WebDriver driver = new ChromeDriver (); System.setProperty("webdriver.gecko.driver", ".\\Tools\\geckodriver.exe"); WebDriver driver = new FirefoxDriver(); driver.manage().window().maximize(); driver.manage().timeouts().implicitlyWait(5, TimeUnit.SECONDS); driver.get("https://www.cnblogs.com/"); Thread.sleep (5000); WebElement ww = driver.findElement(By.tagName("title")); System.out.println(ww.getText()); driver.close(); } }
3.1.4运行代码
1.运行代码,右键Run AS->java Application,控制台输出,如下图所示:
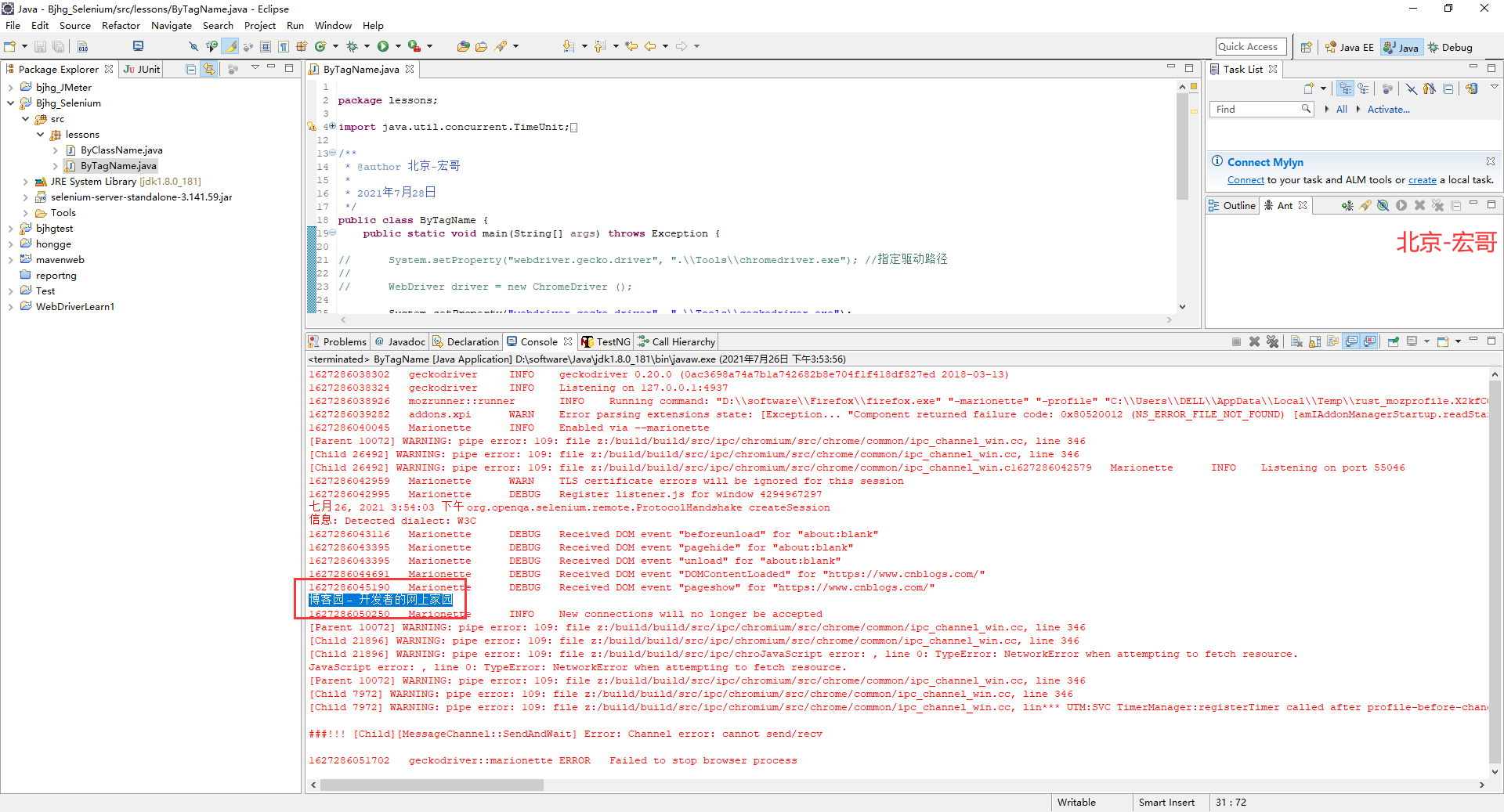
2.运行代码后电脑端的浏览器的动作,如下小视频所示:
3.2当前标签没有重复值
当前标签存在重复则在运行的时候会找不到元素,此时需要使用find_elements***。通过tagName来搜索元素的时候,会返回多个元素. 因此需要使用findElements()。宏哥这里以博客园为例,获取博客园的发布首页文章的信息。在此示例中,我将展示何时要标识表中的行数,因为在运行时此信息可以是动态的,因此,我们需要事先评估行数,然后检索或验证信息。
3.1.1主要步骤
1、打开浏览器
2、通过tagname进行查找元素,findelements返回的数值可能是多个,因此放在list中,此时list中的元素类型是webelement。
3.1.2代码设计
通过主要步骤把代码都设计好了,宏哥只需要将其串起来,调试脚本即可。如下图所示:
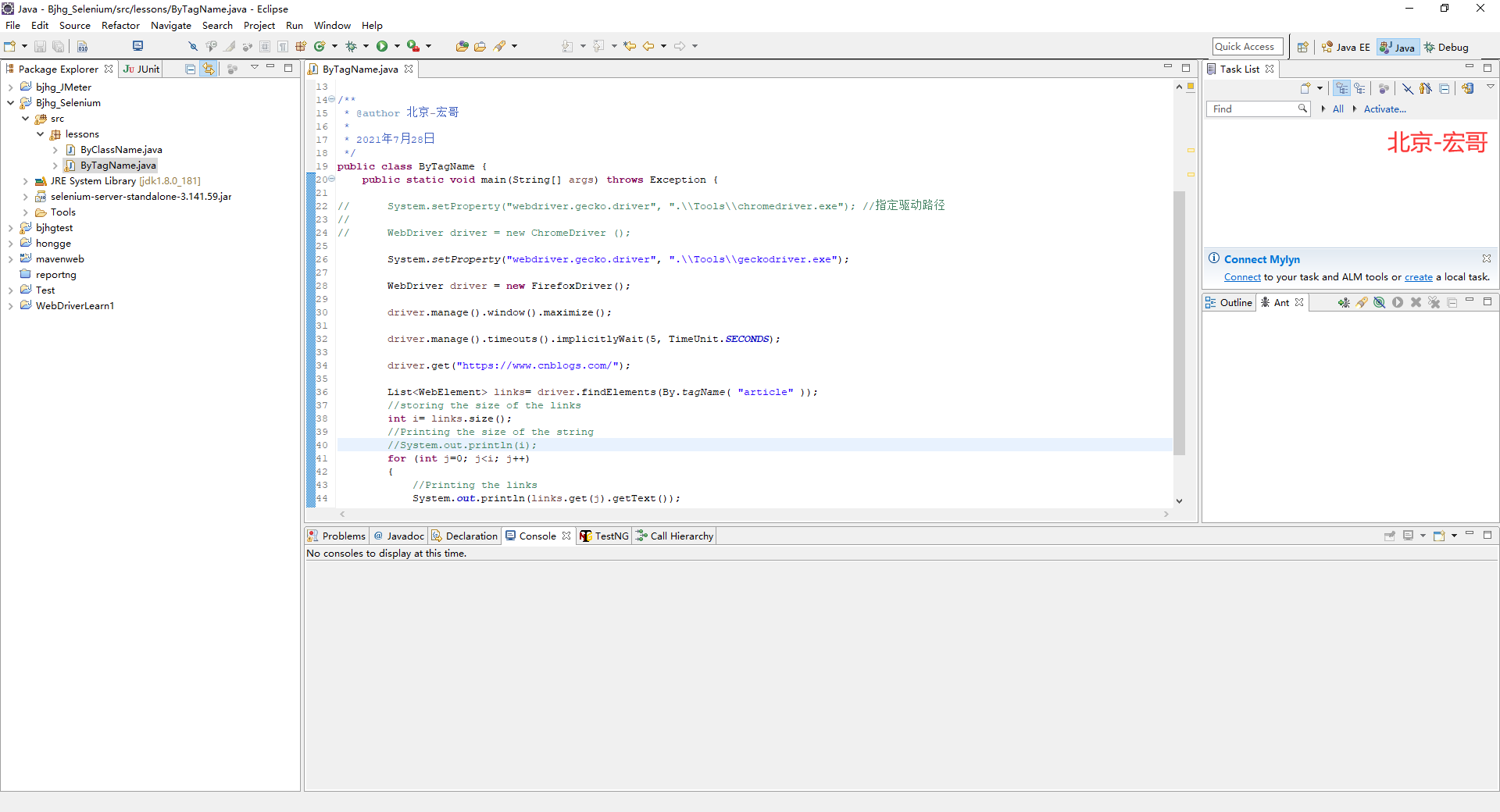
3.1.3参考代码
package lessons; import java.util.List; import java.util.concurrent.TimeUnit; import org.openqa.selenium.By; import org.openqa.selenium.Keys; import org.openqa.selenium.WebDriver; import org.openqa.selenium.WebElement; import org.openqa.selenium.chrome.ChromeDriver; import org.openqa.selenium.firefox.FirefoxDriver; /** * @author 北京-宏哥 * * 2021年7月28日 */ public class ByTagName { public static void main(String[] args) throws Exception { // System.setProperty("webdriver.gecko.driver", ".\\Tools\\chromedriver.exe"); //指定驱动路径 // // WebDriver driver = new ChromeDriver (); System.setProperty("webdriver.gecko.driver", ".\\Tools\\geckodriver.exe"); WebDriver driver = new FirefoxDriver(); driver.manage().window().maximize(); driver.manage().timeouts().implicitlyWait(5, TimeUnit.SECONDS); driver.get("https://www.cnblogs.com/"); List<WebElement> links= driver.findElements(By.tagName( "article" )); //storing the size of the links int i= links.size(); //Printing the size of the string //System.out.println(i); for (int j=0; j<i; j++) { //Printing the links System.out.println(links.get(j).getText()); } driver.close(); } }
3.1.4运行代码
1.运行代码,右键Run AS->java Application,控制台输出,如下图所示:

2.运行代码后电脑端的浏览器的动作,如下小视频所示:
4.小结
好了,今天到这里通过name定位就介绍完了,其实很简单,在使用tagname进行定位的时候,由于一个页面中含有的tagname数目不定,可能是0,1或者是多个,因此这时候就不能用findelement方法了,此时需要使用findelemnets。
5.拓展
1.tag name即标签名称,如:a、input、button、img等
- 目标
查找页面中的a标签
- 实现
element1 = driver. find_element_by_tag_name(“a”)
element2 = driver. find_element(by=”tag name”, value=”a”)
- 说明
当前标签没有重复值,所有可以直接用find_element***定位元素,如果name存在重复则在运行的时候会找不到元素,此时需要使用find_elements***,假设a存在重复值,则定位方式如下:
element3 = driver.find_elements_by_class_name(“a”) element4 = driver.find_elements(by=”class name”, value=”a”)
2.通过tagName来搜索元素的时候,会返回多个元素. 因此需要使用findElements()
WebDriver driver = new FirefoxDriver(); driver.get("http://www.cnblogs.com"); List<WebElement> buttons = driver.findElements(By.tagName("div")); System.out.println("Button:" + buttons.size());
注意: 如果使用tagName, 要注意很多HTML元素的tagName是相同的,
比如单选框,复选框, 文本框,密码框.这些元素标签都是input. 此时单靠tagName无法精确获取我们想要的元素, 还需要结合type属性,才能过滤出我们要的元素
WebDriver driver = new FirefoxDriver(); driver.get("http://www.cnblogs.com"); List<WebElement> buttons = driver.findElements(By.tagName("input")); for (WebElement webElement : buttons) { if (webElement.getAttribute("type").equals("text")) { System.out.println("input text is :" + webElement.getText()); } }
感谢您花时间阅读此篇文章,如果您觉得这篇文章你学到了东西也是为了犒劳下博主的码字不易不妨打赏一下吧,让博主能喝上一杯咖啡,在此谢过了!
如果您觉得阅读本文对您有帮助,请点一下左下角 “推荐” 按钮,您的 将是我最大的写作动力!另外您也可以选择 【 关注我 】 ,可以很方便找到我!
本文版权归作者和博客园共有,来源网址: https://www.cnblogs.com/du-hong 欢迎各位转载,但是未经作者本人同意,转载文章之后必须在文章页面明显位置给出作者和原文连接,否则保留追究法律责任的权利!
公众号(关注宏哥) 微信群(扫码进群) 客服微信




 浙公网安备 33010602011771号
浙公网安备 33010602011771号