MySQL online DDL
1.1 Online DDL语法
online DDL是在mysql5.6版本后加入的特性,语法:
加列
alter table 表名 add column 列名 数据类型,ALGORITHM 算法;
例如:
alter table t3 add column name1 varchar(16),ALGORITHM INPLACE/COPY/DEFAULT;
可以不指定算法:
alter table t3 add column name1 varchar(16);
加索引:
alter table 表名 add index 索引名(列名),ALGORITHM INPLACE;
例如:
alter table t3 add index idx_name(name1) , ALGORITHM INPLACE/COPY/DEFAULT;
可以不指定算法:
alter table t3 add index idx_name(name1);
注:copy是offline的。 默认情况下不需要指定算法,系统会自主选择 。
1.2 online DDL(copy)
1.2.1 copy
alter table sbtest1 add column c varchar(122), ALGORITHM=COPY;
1.2.2 copy方式三个阶段
准备阶段->执行阶段->提交阶段
1.2.2.1 准备阶段(prepare阶段)
1.对元数据进行添加共享锁(MDL-S)[Meta Data Lock Share],读取原表结构。(不能进行DDL,不阻塞DML,但是过程很短)
2.S锁升级为X锁(共享锁升级为排他锁),此时阻塞DDL、DML。
3.创建和原表一致的临时表。server层会执行类似create table的语句来创建一个和表结构一致的临时表,在引擎层也会生成frm和ibd文件。
1.2.2.2 执行阶段 (run)
4.修改新创建的临时表的表结构。
5.临时表的表结构修改完成之后,server层copy原来表数到到临时表中(阻塞DML,阻塞的时间取决于拷贝的速度)表一旦过大,受拷贝数据到临时表的影响。
6.server层替换两个表(重命名临时表及文件),修改原来的文件,然后然后将临时文件名修改成原文件名。
7.删除原表所有数据。
1.2.2.3 提交阶段 (commit)
8.commit,释放所有锁。
1.2.3 注意
1.从开始,一直到执行结束,都是上锁(MDL-X)的,阻塞所有的DDL和修改类的DML,大多数情况下SELECT操作不会被阻塞。
2.此类操作不是online DDL,在执行整个DDL阶段(执行阶段)都是阻塞业务的。
1.3 online DDL(inplace)
1.3.1 执行原理
三阶段:准备阶段 -> 执行阶段 -> 提交阶段
inplace原理:整个过程都是阻塞其他DDL (inplace 5.6开始支持,把执行流程下推到了引擎层执行),如图:
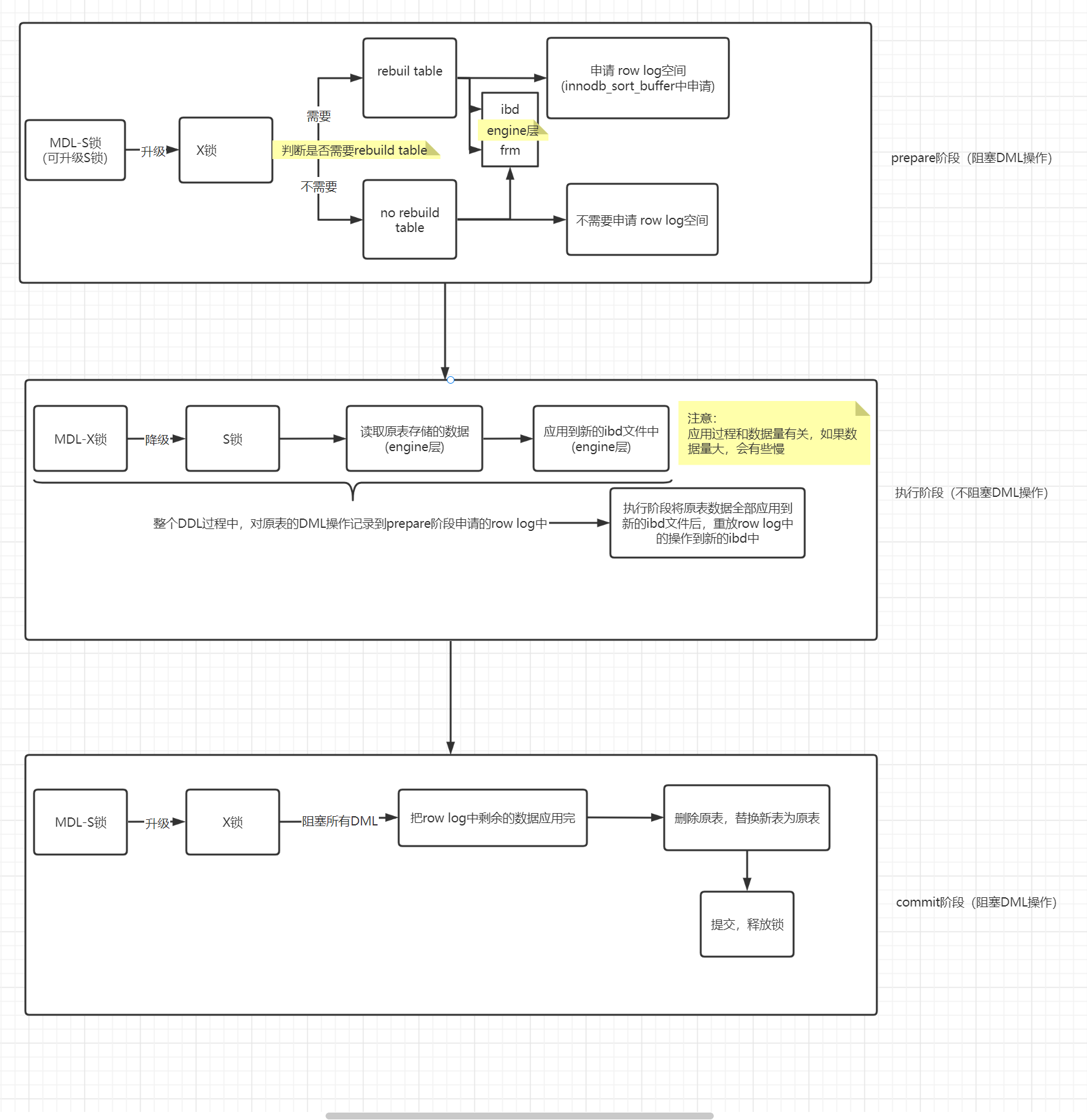
1.3.2 inplace三阶段
1.3.2.1 准备阶段(prepare阶段)
准备阶段阻塞DML
0.在进入prepare阶段前对元数据持有可升级的S锁(MDL-S锁),在此阶段不允许DML, 不允许部分ddl,例如:drop操作。
1.在预备阶段MDL-S锁会升级为X锁(排他锁),在此时会判断,操作是否需要rebuild table。
2.判断是需要rebuild table还是no rebuild table,判断完之后进行下一步,如果需要rebuild table,则申请row log空间。
row log作用:记录online DDL执行阶段,对原表数据做的DML操作的。(row log由innodb_sort_buffer_size决定)。
如果需要rebuild table,则需要在engine层生成原表的转储文件(比如:ibd,frm文件,DDL阶段执行)。
如果是no reduild table,则要在engine层则只需要生成frm文件(比如加索引就是no rebuild table,只需要生成frm,DDL阶段执行。
1.3.2.2 执行阶段 (run)
DDL执行阶段不阻塞DML 。
3.执行阶段 会把X锁降级为S锁,该阶段不阻塞dml操作 ,这个阶段被称为online阶段,例如在加列过程中可能时间比较长,在这期间大部分时间是不阻塞DML操作
4.MDL-X锁降级为MDL-S锁,将原表存储的数据读取到prepare阶段创建的ibd文件中(engine层完成,直接分析数据页,内部结构,将原表的数据记录逐行取出后进行处理,且会执行ddl修改表结构,并应用到新的ibd文件中)
1.3.2.3 提交阶段
commit阶段阻塞DML
5.提交阶段engine层应用row log中的操作到新的ibd文件中直到最后一个,系统会自动判断进行截断,避免源源不断的DML操作。
6.此时MDL-S锁再此升级到MDL-X锁(拒绝所的DML),然后把row log中剩余的数据应用完。
7.删除原表,替换新表为原表( 最后将临时文件替换为原文件,清理老文件)。
8.最后提交。
1.4 一些疑问
1.4.1.Online DDL会不会锁表?
用户角度看online ddl,在执行ddl期间,不阻塞DML操作。
管理员角度看online ddl
准备阶段 持有X锁 ->阻塞DML
执行阶段 降级为S锁 ->不阻塞DML
提交阶段 升级为X锁 ->阻塞DML
1.4.2支持 INPLACE 算法的 DDL 一定是 Online 的吗?
不一定,从三个阶段看:copy和inplace(第一、第三阶段对用户来说就不是online的,第二阶段对用户来讲是online的)。
COPY 算法执行的 DDL肯定不是 Online 的。
INPLACE 算法执行的 DDL 不一定是 Online 的。
1.4.3 online ddl需不需要额外的磁盘空间?
对于engine层需要创建ibd转储文件的操作,是需要额外的存储空间,所以操作的时长,是受到数据量的影响,但不会阻塞业务
1.4.4 copy方式和inplace方式的区别?
copy是在server层,inlpace是在engine层。
1.4.5 如何判断是rebuild table还是no rebuild table?
可以观察ddl执行时间和快慢,以一张大表为例:
方法1:如果是rebuild table方式,在执行阶段会很慢。
方法2:可以观察数据目录下是否生成文件如:#sql_xxx.ibd/frm(主要是ibd文件)且会持续增大
1.4.6 如何判断是否online DDL?
mysql> alter table sbtest1 modify column c varchar(121);
Query OK, 5000 rows affected (0.28 sec) # 如果不是0 rows 则是offline DDL
mysql> alter table sbtest1 modify column c varchar(122);
Query OK, 0 rows affected (0.00 sec) # 如果是0 rows affected 则是online DDL
Records: 0 Duplicates: 0 Warnings: 0
1.5 小结
1.加索引DDL,受一定原表数据的影响,加列会DDL受原表数据影响。
2.称直为inplace是因为不涉及到server层的操作,而且直接在engine层直接做inplace转换。
3.在prepare阶段和commit阶段少量时间加锁,其中在执行DDL阶段是online的,所以在ddl阶段不管执行了多长时间,对原有业务的DML操作不会有影响,不阻塞,在负载、IO上可能会有点影响 。
4.inplace中,不需要通过server层的create语句重建表,但是依然需要在engine层,生成ibd转储文件,所以需要做此步骤的操作(如:加列),依然需要额外的存储空间。可以理解为,之所以称inplace,其实是将操作下推到engine层去执行。
5.更多online DDL,请查看:https://dev.mysql.com/doc/refman/5.6/en/innodb-online-ddl-operations.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号