1.大数据概述
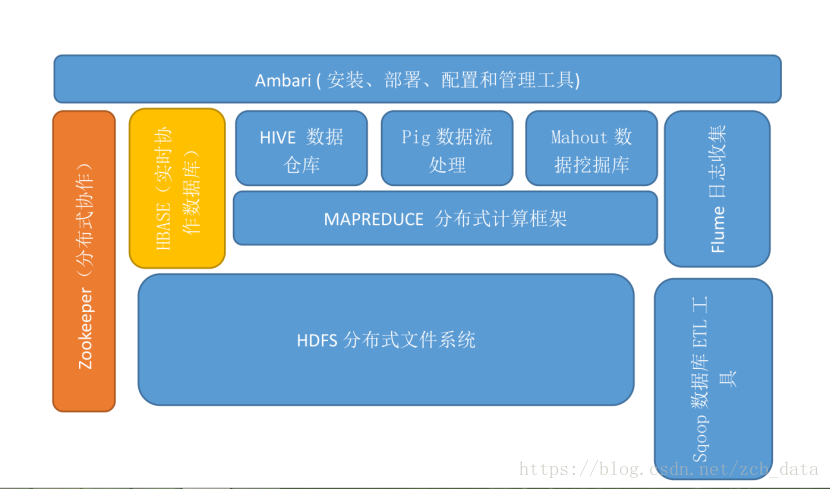
1.列举Hadoop生态的各个组件及其功能、以及各个组件之间的相互关系,以图呈现并加以文字描述。
组件名 功能及作用 优势 局限 应用场景 相关功能组件
HDFS 分布式文件系统。存储是大数据技术的基础 (1)高吞吐量访问; (2)高容错性; (3)容量扩充 (1)不适合低延迟数据访问; (2)不适合存储大量小文件; (3)不支持多用户写入及任意修改文件(只能执行追加操作,写操作只能在文件末位完成) 可处理超大文件,可运行于廉价的商用机器集群。 hadoop文件系统包含local(支持有客户端校验和的本地文件系统)、har(构建在其他文件系统上进行归档文件的文件系统,在hadoop主要被用来减少namenode的内存使用)、kfs(cloudstroe前身是Kosmos文件系统,是类似于HDFS和Google的GFS的文件系统)、ftp(由FTP服务器支持的文件系统)
Mapreduce 计算模型 (1)被多台主机同事处理,速度快; (2)擅长处理少量大数据; (3)容错性,节点故障导致失败作业时,mapreduce计算框架会自动将作业安排到健康的节点 (1)不适合大量小数据; (2)过于底层化,编程复杂; (3)JobTracker单点瓶颈,JobTracker负责作业的分发、管理和调度,任务量多会造成其内存和网络带宽的快速消耗,最终使其成为集群的单点瓶颈; (4)Task分配容易不均; (5)作业延迟高(TaskTracker汇报资源和运行情况,JobTracker根据其汇报情况分配作业等过程); (6)编程框架不够灵活; (7)Map池和Reduce池区分降低了资源利用率; 日志分析、海量数据排序、在海量数据中查找特定模式等 可用hive简化操作,完成简单任务
Yarn 改善MapReduce的缺陷 (1)分散了JobTracker任务,提高了集群的扩展性和可用性; (2)扩大了MapReduce编程人员范围; (3)在资管管理器故障时,可快速重启恢复状态; (4)不再区分Map池和Reduce池,提高了资源利用率;
Hive 数据仓库 (1)易操作; (2)能处理不变的大规模数据级上的批量任务; (3)可扩展性(可自动适应机器数目和数据量的动态变化); (4)可延展性(结合mapreduce和用户定义的函数库); (5)良好的容错性; (6)低约束的数据输入格式 (1)不提供数据排序和查询功能; (2)不提供在线事务处理; (3)不提供实时查询; (4)执行延迟
Hbase 数据仓库 数据库,存储松散型数据。向下提供存储,向上提供运算。 (1)海量存储; (2)列式存储; (3)极易扩展(基于RegionServer上层处理能力的扩展和基于HDFS存储的扩展); (4)高并发; (5)稀疏,列数据为空时,不会占用存储空间。 (1)对多表关联查询支持不足; (2)不支持sql,开发难度加大 查询简单、不涉及复杂关联的场景,如海量流水数据、交易记录、数据库历史数据
Pig 数据分析平台,侧重数据查询和分析,而不是对数据进行修改和删除等。需要把真正的查询转换成相应的MapReduce作业 (1)处理海量数据的速度快 (2)相较mapreduce,使用Pig Latin编写程序时,不需关心程序如何更好地在hadoop云平台上运行,因为这些都有pig系统自行分配。 (3)在资管管理器故障时,可快速重启恢复状态; (4)不再区分Map池和Reduce池,提高了资源利用率; 处理系统内日志文件、处理大型数据库文件、处理特定web数据 可看做简化mapreduce的高级语言
Zookeeper 协调服务 (1)高吞吐量 (2)低延迟 (3)高可靠 (4)有序性,每一次更新操作都有一个全局版本号 控制集群中的数据,如管理hadoop集群中的NameNode、Hbase中的Mster Election、Server见的状态同步
Avro 基于二进制数据传输高性能的中间件。数据序列化系统,可以将数据结构或对象转化成便于存储或传输的格式,以节约数据存储空间和网络传输贷款。适用于远程或本地大批量数据交互。 (1)模式和数据在一起,反序列化时写入的模式和独处的模式都是已知的; (2)多语言支持; (3)可有效减少大规模存储较小的数据文件的数据量; (4)丰富的数据结构类型 hadoop的RPC
Chukwa 数据收集系统,帮助hadoop用户清晰了解系统运行的状态,分析作业运行的状态及HDFS的文件存储状态 Scribe存储在中央存储系统(NFS)、Kafka、Flume。看到一篇对于日志系统讲的比较清晰的,也做了分类比较,再次引用给大家。
2.对比Hadoop与Spark的优缺点。
spark的计算模式也属于MapReduce,但不限于Map与Reduce操作,还提供多种数据集操作类型,编程模型比HadoopMapReduce更灵活
spark提供内存计算,可将中间结果放到内存中,对于迭代运算效率更高,MapReduce 中计算结果需要落地,保存到磁盘上,这样势必会影响整体速度
speak基于,要优于HadoopMapReduce的迭代执行机制DAG的任务调度执行机制,减少了迭代过程中数据的落地,提高了处理效率
Spark 更加通用。mapreduce 只提供了 Map 和 Reduce 两种操作,Spark 提供的数据集操作类型有很多,大致分为:Transformations 和 Actions 两大类。Transformations包括 Map、Filter、FlatMap、Sample、GroupByKey、ReduceByKey、Union、Join、Cogroup、MapValues、Sort 等多种操作类型,同时还提供 Count, Actions 包括 Collect、Reduce、Lookup 和 Save 等操作
3.如何实现Hadoop与Spark的统一部署?
由于Hadoop MapReduce、HBase、Storm和Spark等,都可以运行在资源管理框架YARN之上,因此,可以在YARN之上进行统一部署
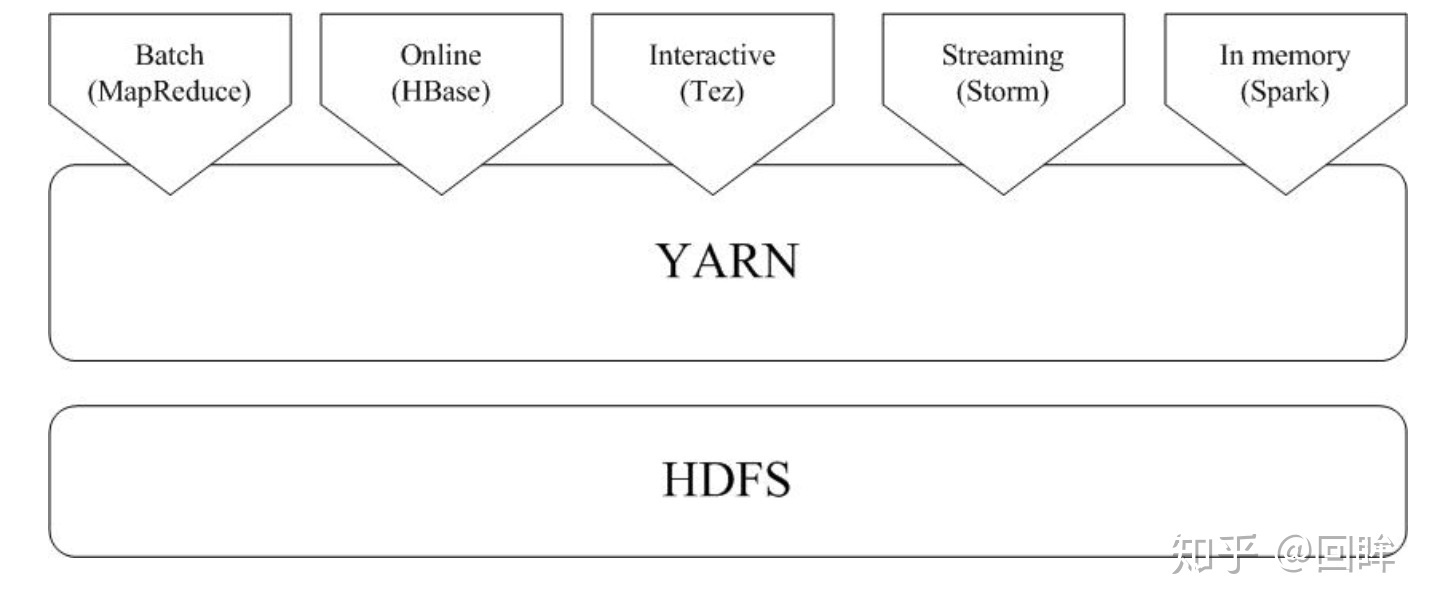
不同计算框架运行在YARN的好处
计算资源按需伸缩;
不用负载应用混搭,集群利用率高;
共享底层存储,避免数据跨集群迁移。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号