Object-oriented_第三单元总结
本博客为面向对象课程第三单元的作业总结。
引言
第三单元的OO课程,致力于培养JML规格思想,达到根据规格进行开发、熟练理解JML的需求。在本单元中,实现JML规格的方式,是以开展规格化设计的形式,即通过具有严密逻辑的规格,而非模糊的自然语言描述来实现具体代码。
课程的三次作业,以社交网络为主题,通过阅读规格需求进行开发,形成迭代关系。
本篇博客行文思路总结如下:
-
-
基于JML规格的测试策略
-
容器选择和使用经验
-
性能问题分析
-
架构设计分析
-
单元感想
1 实现规格采取实现和设计策略
规格实现
综合三次作业中,我采用了如下规格的实现方式,共分为以下三个流程,包含六个步骤:
事前准备
-
阅读规格,了解所有函数功能,具有对整体意义、过程的把握。
随着作业的迭代,例如求平均数与方差、最短路径等功能逐渐增多,加之代码本身较为庞大,因此最开始时,需要对规格的限制、代码所要实现的功能进行整体感知,为后续领会、撰写代码作良好准备。实践来看,这不但提升了正确性,对实现的可靠性也有所保障。
-
通过阅读,考虑时间、内存的限制来选用合适的容器,例如
ArrayList和Hashmap,详细选择过程将会在后文进行介绍。
正式编写
-
实现异常类、计数类、Person类等耦合度较低的简单类规格。
由于代码中类的交互相对复杂,考虑到正确性与可靠性及方便后续理解,先对简单类进行填写,在保证代码基础功能的同时,对某一个体类中的方法具有感知。例如,实现了Person类后,对于Network这种复杂类中出现的Person中的方法便能够更好地理解。这样,从JML简短的类下手更降低了复杂的交互。
-
基于简单类方法的基础上,按照流程整体根据JML编写代码,注意关注于比较复杂的函数,例如
send_message, delete_cold_emoji等。
整体完善
-
进行充分的测试,保证程序正确性,以及符合JML规格。详细过程将会在后文进行介绍。
-
开展性能优化。
在性能优化中,需要对取决于数据结构的方法进行优化,例如
query_block_sum,query_circle等。
规格设计
在实现的过程中,由于测试是白盒测试,在经过完善的测试再进行性能优化时,容易出现因为优化而造成正确性失衡的情况。所以,要把握二者之间的平衡,不能顾此失彼。
因此,为了使得测试更加有效,最好的情况是,在开发时采用正交化的开发模式,即设计与实现相分离,实现与测试相分离。此外,感知代码整体的同时关注细节,这样的设计会达到事半功倍的效果。
规格迭代
由于作业迭代进行,因此,在每次实现之前, 为了进行良好的迭代,对代码规格的新增内容具有良好的感知,可以使用VScode的diff命令来辨析规格的前后差别,避免先入为主的思想造成的规格疏忽。
2 基于JML规格的测试策略
在基于规格的测试中,我们应该基于七个性质:一致性、顺序性、区间性、依赖性、存在性、基数性和时间性来开展测试。具体地,我在本单元作业中综合使用了以下五步测试方法:
基于JUnit测试
JUnit是白盒测试,是针对Java语言最小程序的单元测试框架,表现为对方法进行测试,它可以给出成功与否的判断,并生成测试报告。
JUnit的主要思想是:基于测试底层小规模、独立的功能,来对这些独立的行为功能建立信息,确保其与期望一致,进而来搭起整个系统的结构,保证测试的系统稳固。
JUnit的优势:
-
能够实现自行编写代码对指定的方法进行自动测试,更有助于bug的定位;
-
能将大的系统进行分解到小的结构,有助于测试的便捷与高效
JUnit的缺陷:
由于代码自行编写,因此无法确保情况的覆盖性,测试强度无法保证。
基于OpenJML测试
OpenJML是JML规格的完整性检查,其测试对象主要是最基本的功能,包括类型、变量等检查方式。
自动数据生成器
这里我基于python生成了自动数据生成器,根据数据生成器来生成大批量数据,这对一些大批量数据带来的正确性挑战与性能挑战更容易检测出来,因此其负责大规模数据的测试,其他边缘用例通过手动检查即可完成。
同时,使用该方法必要的一环是进行结果检查,通常是基于构造的对拍器,由于对拍过程中无法保证正确性,因此需要先使用JUnit与手动测试开展基本的测试,然后通过与同学之间结果的对拍,来确保该种测试方式的有效。
阅读代码
本次作业通过阅读代码进行测试的难度相对前两单元作业而言相对下降,这正是由于规格化带来的好处,使得代码正确性和实现的差异并不会过大,更易于开发者的相互理解。
在个人的测试中,我会首先选择阅读代码,人工判断基本逻辑上的正确性,而后开始进行其他测试操作。在互测过程中,我在数据自动测试之余,也会查看他人代码寻找bug,例如是否使用了易于超时的容器,方法中边缘用例处理的正确性是否得到保障等。
手动构造样例随机测试
这种方式对于边缘用例正确性与对超时测试较为有效。例如,将一个人的关系网络增加到最大,或者通过询问自环的关系等边缘情况判断正确性。然而,由于该方法覆盖性较低,因此相对而言仍有缺陷。
3 容器选择和使用经验
在本单元中,我选择了HashMap、ArrayList和PriorityQueue这三种容器:
HashMap
选择原因
-
HashMap无法使用普通的for进行循环遍历,但它查询、访问、删除性能很高,达到O(1),不会引发本次作业的超时问题
-
将key与value一一对应,且由于本次作业中无需解决索引冲突的操作,非常适用于Person、message等Id唯一的情况。
使用经验
本次作业中,HashMap被我广泛使用,例如在各种Person类的队列,例如acquaintance。同时,在本次作业中大多只对单独一个元素进行操作的地方,例如Person、Group、Message的增、删、查等,我都使用了HashMap进行了存储。

ArrayList
选择原因
-
ArrayList的遍历元素和访问元素的效率良好,适用于在一些对于性能不作过多要求的地方。
-
具有比较形象的队列结构。
-
具有天然的顺序性,这是HashMap不具备的,因此操作相对比较便捷。
使用经验
使用过程中,针对于本次作业,我将其用于了收到的信息message的列表中。这是因为ArrayList对于性能要求不高的地方使用起来比较直观与便捷,同时能够很好地控制插入的顺序,例如,在规格中我们要求将新收取的消息插入到队列的首部,同时按序输出。此外,它更具有形象的数组结构。

此外,经测试发现,ArrayList无法保证本次规格下的性能,因此,在其他部分我没有使用ArrayList,而是使用HashMap进行进一步的操作。
PriorityQueue
选择原因
针对于最短路径问题,使用PriorityQueue能减小堆优化的Dijsktra算法复杂度。出于性能优化的问题,我在本次作业中采用了PriorityQueue,用于存储节点,根据节点距离为优先级进行去除。
使用经验
对于java中的优先级队列PriorityQueue是二叉小顶堆,在堆优化的Dijskra算法中,使用方式如下:
-
remove():获取并删除队首元素,失败时抛出异常。
-
poll():获取并删除队首元素,失败时返回null。
-
element():获取但不删除堆顶即队首元素,失败时抛出异常
-
peek():获取但不删除堆顶即队首元素,失败时返回null。
在算法中的具体使用代码如下:
priorityQueue.add(nodeset.get(beginId));
while (!priorityQueue.isEmpty()) {
Node temp = priorityQueue.poll();
······
for (Node node : nodeArrayList) {
······
if (distance.get(nodeid) > (distance.get(tempId) + dis)) {
······
priorityQueue.add(node);
}
}
}
4 性能问题分析
本次作业中,主要涉及性能问题或采用的性能算法有如下几种,我通过如下的方式对性能问题进行了避免:
最短路径——堆优化的Dijkstra
处理最短路径问题,使用的算法往往是Dijkstra算法。一般地,标准Dijkstra算法复杂度为O(n2),该复杂度来源于因为每次操作后都要寻找与当前距离最小的元素作为下一个最短路径中的节点。
在本单元作业中,使用堆优化的Dijkstra算法,就能很好地对该问题进行优化,其优化后的复杂度是O(nlogn)。
其中,用数组存放节点的复杂度是O(n),而使用Java中内部的PriorityQueue<T>,由于PriorityQueue内部采用堆来维护节点之间的大小,使得能够直接找到最小,复杂度为O(logn),有效降低算法复杂度,使得性能得以提升。
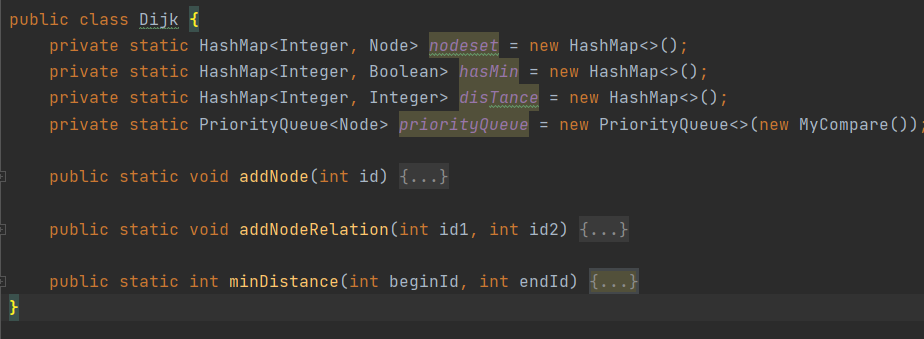
在本单元中,我为算法的实现单独建立了一个Dijk类,在节点的增添的同时做好初始矩阵、距离等的处理过程。
连通性与最大连通子图——并查集
在第九次作业中,isCircle方法与queryBlockSum方法容易出现超时问题,其复杂度分别为O(n^2)与O(n^3)。
在isCircle的方法中,可以使用并查集的数据结构,并将与压缩路径的优化算法相结合,其将性质相同的元素划分为同一个集合,来实现不相交集合中的分组问题,易于实现元素的查询与合并等操作,能够使得操作复杂度降低到O(logn)。
此外,对于BlockSum的算法,采用如下算法:
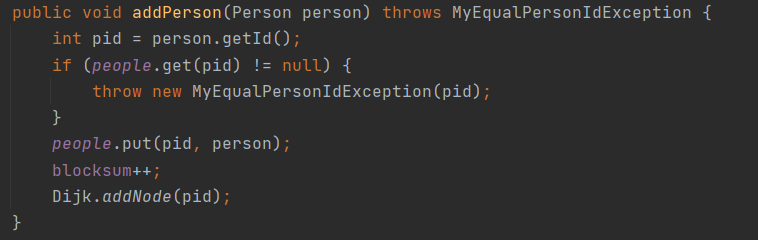
-
初始化变量blockSum,增添人时blockSum++;
-
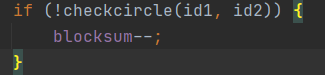
addRelation时判断二人是否相连同,若不连同则blockSum--
通过该种方式,有效降低了算法的复杂度。
群体属性计算——变量维护
本单元作业中,对于群体属性进行了大量的访问,例如年龄平均数与年龄方差、群体社交值等。
如果按照规格中给出的描述编写代码,需要多次对图进行遍历而计算。我通过使用变量维护的方法: 即随着每次对网络的变动而变动相关参数,对于访问群体属性时,只需直接返回某一参数值,即可实现方法,这样使得复杂度大大降低。
具体而言,在增删的过程中时间复杂度为O(n),而查询的过程中时间复杂度为O(1)。
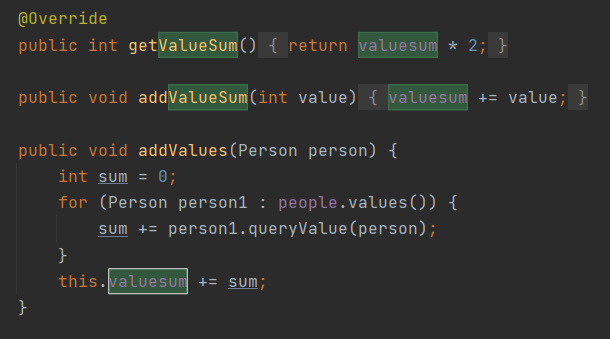
例如,访问群体社交值属性的getValueSum方法,根据缓存的方法设置了valuesum变量,通过每次在addRelation时直接增添valuesum,而不是在访问方法时才进行遍历计算,实现了这种机制,最后只需返回valuesum的参数即可。
而对于年龄平均数、方差的简化计算,通过维护年龄和与年龄和的平方这两个参数,最终利用公式计算出所需的结果即可实现,同时需要注意取整问题,有些计算公式并不支持取整的最终结果。
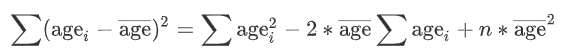
5 架构设计分析
架构设计
对于架构设计,由于规格的特性,对于本单元作业中大家统一的相同类,按照规格的描述实现即可,自己的设计部分不多,因为这些类的设计与方法的实现在规格中已完善的比较全面,以下对这些类进行简要说明。
-
Person类:是相对底层的类,是人的描述;
-
Group类:在Person基础上,对一部分的Person统一进行管理;
-
Message类:进一步,在人和群体的基础上出现了消息类,在第十一次作业中,引入了具体的三个继承的消息来实现对应不同的功能;
-
NetWork类:负责对社交网路进行整体的规划,包括增、删、查、计算、维护等功能;
通过 UML 图描述如下。
UML 图

异常类策略
对于异常类的管理与维护,我额外增加了异常计数类Counter,管理异常总次数的计数,其余10个异常类管理各自异常的计数,并调用Counter获取总次数进行输出即可。
图模型构建与维护策略
对于图模型的构建与维护是本次单元作业保障性能方面的重点,在图模型的构建与维护中,我主要使用了两个新建的类,即Node类与Dijk类,将图结构独立出来,采用邻接表的方式完成了图模型的构建与维护:
-
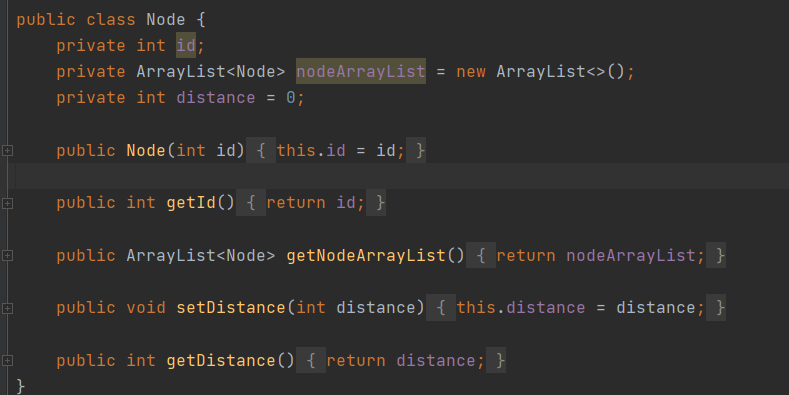
Node:负责图模型中邻接表的构建,当新增Person时,同时新增Node,作为邻接表中的一个节点。
![]()
-
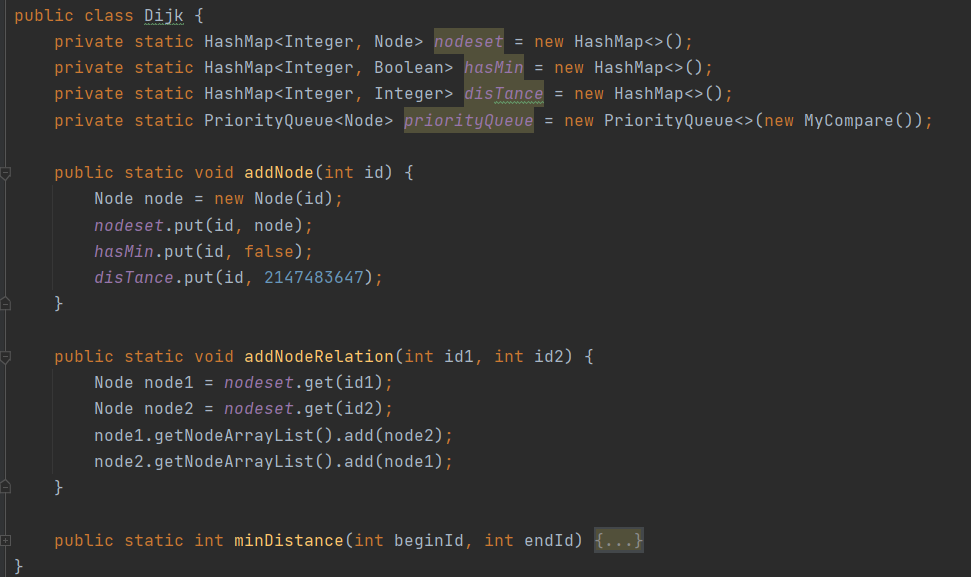
Dijk:图模型的关键。包含两个方法,即addNode与addRelation,用于为图模型新增节点与边。同时,对于每一次在NetWork中Person与Relation的新增,Dijk类也起到维护作用,对图模型中点与边的结构进行实时更新。
![]()
此外,对于这两个类而言,是基于Person与Network底层维护的基础,即Person通过对人的增减,利用Hashmap等将抽象的图结构进行维护,而Dijk和Node是将这个抽象的图具象起来,使得具有较清晰的层次结构。这也有利于例如最短路径等算法的理解与程序代码的维护。
6 单元感想
本单元总体难度相对不大,主要任务基于弄清JML的基本语法,对规格进行更好地掌握。
相对来说,本单元相比前两单元作业并未遇到太多困难,但在本单元中我也学到了许多新的内容和有帮助的知识,例如JUnit单元测试、容器选择策略、图的算法等。同时,我对规格有了更加熟练的认识,理解了规格以及JUnit测试带来的可靠性与便捷性。
在作业的完成过程中,我的总体工作量偏重于以下三点:
-
规格的理解;
-
算法性能的改进;
-
测试的过程
而针对本单元测试的过程,我更深入体会到了性能与正确性之间的平衡关系,正确性是首要的前提,才能保证性能的优化。同时,我也能更好地掌握这种平衡关系,这将对我以后的开发工作非常有帮助。
总之,面向对象第三单元的学习内容使我收获很多,我相信从学习的内容中认真体会,一定会有更深入的认识与理解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号