
Object-oriented_第一单元总结
本博客为面向对象课程第一单元的三次作业总结。
引言
第一单元的OO课程,致力于培养形成面向对象思想,达到高鲁棒性、清晰的层次结构。课程的三次作业形成迭代关系,以多项式求导为主题。具体地,第一次作业为简单多项式求导,涵盖幂函数因子与常数因子求导需求;第二次作业增加三角函数因子、可嵌套的表达式因子求导需求;第三次作业增加输入数据格式的判断、三角函数因子嵌套求导需求。最重要的是,第一单元作业使我面向对象的思维、解决问题的能力得到有效提升。
整篇共分为四个部分:
-
基于度量的程序结构分析
-
程序的bug分析
-
重构经历总结
-
心得体会
本文篇幅较长,展现了三次作业的设计思路、实现过程与心得体会,涵盖了笔者对面向对象课程第一单元作业思考的结晶,希望能为大家带来启发。
一、基于度量的程序结构分析
0. 面向对象的度量指标
主要度量指标分为基本复杂度、模块设计复杂度和圈复杂度。以下进行详细解释:
-
基本复杂度
ev(G):描述程序非结构化程度。ev(G)高的程序难以模块化和维护。非结构化:难以结构化的部分。此部分中,程序的质量较低,代码维护难度较大。
-
模块设计复杂度
iv(G):描述模块判定结构,即调用关系,体现为耦合度。iv(G)高的程序难以维护与复用。 -
圈复杂度
v(G):描述模块判定结构的复杂程度,体现为独立路径的条数。v(G)高的程序同样难于测试和维护,代码质量低。
三种度量指标中,模块设计复杂度iv(G)往往远小于圈复杂度。其中,高的圈复杂度与程序存在错误具有很大关系。
此外,度量指标还包含以下三种复杂度。
-
OCavg:平均操作复杂度;
-
OCmax:最大操作复杂度;
-
WMC: 加权方法复杂度。
1. 第一次作业
作业思路
-
由于不要求格式判断,在正式解析之前,对输入进行预处理:
-
替换空格
-
合并符号
-
-
正式处理部分:
-
采用正则表达式进行判断,使用
ArrayList链表存放因子; -
在多项式类中设计求导方法,对
ArrayList中的元素进行求导; -
合并同类项,进行输出。
-
重要类/接口分析
-
Main类:
-
处理输入;
-
解析项加入链表;
-
合并输出。
-
-
Poly类:
-
解析项的输出方式;
-
实现求导功能。
-
代码可视化与数据统计的程序度量
-
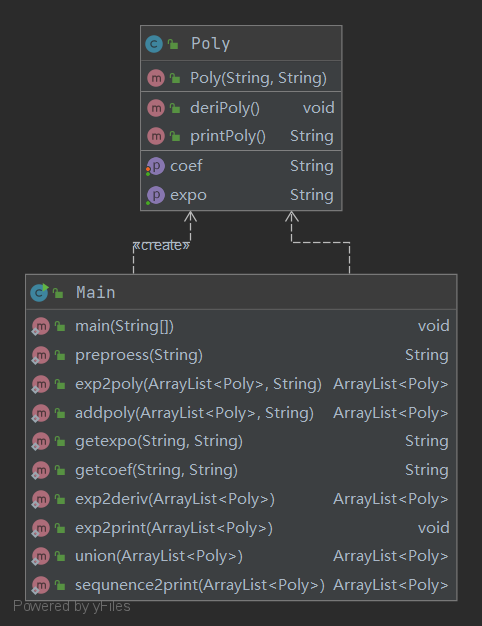
程序UML类图
第一次作业中,我一共创建了2个类。通过类图可以发现,本次作业未引入工厂模式,导致大量方法堆叠在Main函数中,无法拥有一个可扩展的层次结构。尝试从面相过程的编程思想转变为面相对象的编程思想,但实现起来并未完全面相对象,这也是第一次作业的不足之处,以及与以往编程方式不同的提升之处。
-
代码规模分析

分析来看,主函数中容纳了大部分代码量,这种情况由于未使用工厂模式导致,并不是一个良好的解决方式,但这在后续作业中得以解决。
-
类复杂度分析
| class | OCavg | OCmax | WMC |
|---|---|---|---|
| Main | 3.2 | 6.0 | 32.0 |
| Poly | 3.5 | 16.0 | 21.0 |
| Total | 53.0 | ||
| Average | 3.3 | 11.0 | 26.5 |
分析来看,大多数操作被集中于Poly类中,而基于面向对象的编程的合理方式是使用工厂模式,将处理方法置于工厂类当中,对象类中进行处理的高操作复杂度不是良好的程序结构,也正体现了这种模式的不足之处以及可待改进之处。
-
方法复杂度分析
| method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Poly.setCoef(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Poly.printPoly() | 24.0 | 16.0 | 12.0 | 16.0 |
| Poly.Poly(String,String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Poly.getExpo() | 0.0 | 1.0 | 1.0 | 1.0 |
| Poly.getCoef() | 0.0 | 1.0 | 1.0 | 1.0 |
| Poly.deriPoly() | 0.0 | 1.0 | 1.0 | 1.0 |
| Main.union(ArrayList) | 8.0 | 2.0 | 4.0 | 5.0 |
| Main.sequnence2print(ArrayList) | 3.0 | 3.0 | 3.0 | 3.0 |
| Main.preproess(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Main.main(String[]) | 0.0 | 1.0 | 1.0 | 1.0 |
| Main.getexpo(String,String) | 9.0 | 1.0 | 7.0 | 7.0 |
| Main.getcoef(String,String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Main.exp2print(ArrayList) | 6.0 | 2.0 | 5.0 | 5.0 |
| Main.exp2poly(ArrayList,String) | 8.0 | 1.0 | 6.0 | 6.0 |
| Main.exp2deriv(ArrayList) | 1.0 | 1.0 | 2.0 | 2.0 |
| Main.addpoly(ArrayList,String) | 10.0 | 1.0 | 6.0 | 7.0 |
| Total | 69.0 | 35.0 | 53.0 | 59.0 |
| Average | 4.3 | 2.1 | 3.3 | 3.6 |
分析来看,整体的复杂程度和耦合程度较低,但例如Poly.printPoly()方法由于处理不当导致ev(G)等超标。经分析, 原因是在项的输出中需要考虑大量指数为1与系数为1等的省略情况,含有较多的 if-else 分支,这也正是这类问题的共性所在。由于第一次作业将这些因子放在同一类处理,也是使这种情况被放大的原因。
优缺点分析
-
优点分析
-
采用容器存储,处理层次化
-
化简功能较为完善
-
-
缺点分析
-
未使用工厂模式,项目结构失衡
-
面向对象的思维方式、程序的可扩展性有待提升
-
评测结果
第一次作业在强测与互测阶段没有被找出bug,找出了同房间内的一个bug,将会在bug分析中详述。
2. 第二次作业
作业思路
本次作业有两种主要思路:
-
基于容器建立项类,在项中添加多个容器属性。
-
优缺点分析
-
优点:符合计算依从思想,实现对表达式进行化简(合并同类项)更加容易。
-
缺点:求导复杂。
-
-
-
基于数据结构建立表达式树,将各类因子继承于父类
Factor,并将父类引用作为树结点,进行链式求导(对树进行遍历)。-
优缺点分析
-
优点:符合数据依从思想,实现因子管理更加容易。
-
缺点:化简复杂。
-
-
正如教程所言,面对优化应优先考虑正确性,因此,我采用更加保证求导正确性的表达式树方法进行处理,将项与因子分别建立类,使用二叉树进行结构构造。处理思路如下:
-
基于表达式的加减符号,提取出各个项。
-
基于项中因子的结构,例如
a*x**b,实现从项到Factor的拆分。 -
在拆分过程中,对各
Factor进行分类,在该父类下纳入如三角函数因子等多个子类。 -
在子类中进行因子求导。
-
对树进行遍历,将求导结果进行最终输出。
-
-
具体地,构建表达式树采用向上的方式,即汇聚本深度下的子树,形成自身的新树,对上一深度依次进行处理:
-
对于表达式,首先读入表达式,将每一项在工厂中拆分表达式返回的树根节点使用运算符
+连接,形成一个新的表达式树。 -
对于项,根据表达式形成的项,将每一项在工厂中拆分项返回的树根节点使用运算符
*连接,形成一个新的表达式树。 -
对于因子,根据项形成的因子,将每一项在工厂中使正则表达式匹配因子类型,形成
Factor树。
-
-
将本次使用的表达式树方法继续深入来看,对于每一个类,即抽象为树节点,内部主要涵盖求导与输出两种主要方法:
-
求导:对以本结点作为根的子树求导,返回的一个求导后的根节点。
-
输出:对以本结点作为根的子树输出,返回的一个字符串。
-
重要类/接口分析
-
输入处理:
Factory, Main-
Factory类:工厂类,完成输入处理,包括表达式的拆分与项的拆分 -
Main类:主函数,完成输入预处理,如符号替换
-
-
表达式树:
Derivebrackets, Parameter, Power, Term, Trigle-
Derivebrackets类:存放嵌套类,包括求导、输出功能 -
Parameter类:存放常数类,包括求导、输出功能 -
Power类:存放幂函数类,包括求导、输出功能 -
Trigle类:存放三角函数类,包括求导、输出功能
-
-
求导化简:
Derivemult, Derivemult1, Derivemult2, Deriveplus, Superior-
Derivemult类:实现乘法求导 -
Deriveplus类:实现加法求导 -
Superior类:化简表达式
-
代码可视化与数据统计的程序度量
-
程序UML类图
在第二次作业在我一共创建了
12个类,这主要被划分为3个部分。

-
代码规模分析
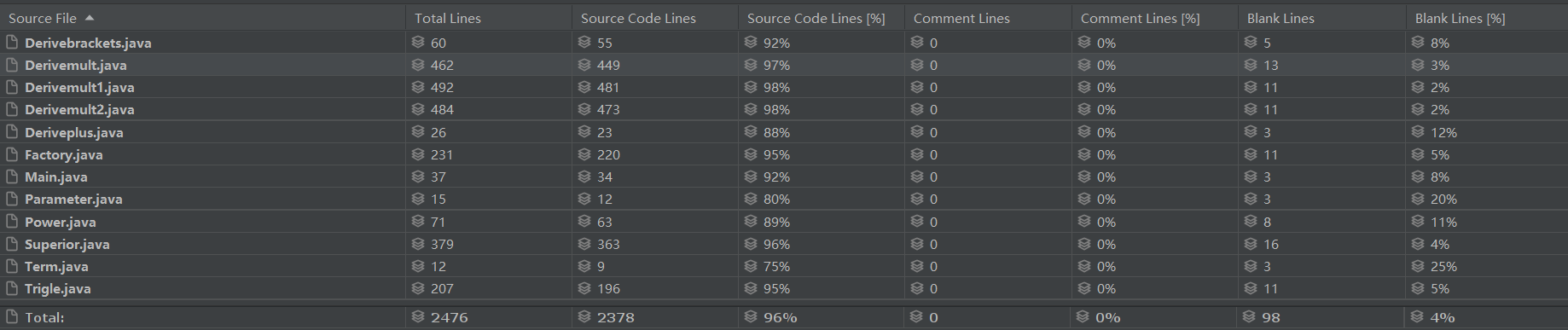
分析来看,由于采用了工厂模式,主函数内代码规模得以改善,然而,由于大量的if-else操作,导致求导部分代码规模量巨大,实际上,这是不好的设计架构与未完善的面向对象方式所造成,我在第三次作业中改善了这一点。
-
类的复杂度分析
| class | OCavg | OCmax | WMC |
|---|---|---|---|
| Derivebrackets | 4.7 | 11.0 | 19.0 |
| Derivemult | 12.1 | 15.0 | 134.0 |
| Derivemult1 | 13.1 | 15.0 | 145.0 |
| Derivemult2 | 12.5 | 15.0 | 138.0 |
| Deriveplus | 2.5 | 4.0 | 5.0 |
| Factory | 6.6 | 16.0 | 66.0 |
| Main | 2.5 | 3.0 | 5.0 |
| Parameter | 1.0 | 1.0 | 3.0 |
| Power | 3.0 | 12.0 | 18.0 |
| Superior | 7.13 | 22.0 | 107.0 |
| Term | 1.0 | 1.0 | 2.0 |
| Trigle | 6.4 | 13.0 | 64.0 |
| Total | 706.0 | ||
| Average | 8.1 | 10.6 | 58.8 |
分析来看,设计到求导的Derivemult类中存在很大复杂度,这是由于未将求导设计为接口,导致结构化不强。同时内部使用了大量的if-else语句,造成了很大的复杂度,但本次引入了工厂模式,对于简化操作与可扩展性有所帮助。
-
方法的复杂度分析
由于方法数目较多,
Method Metrics生成表格过长,故只展示总体情况与出现红色的条目。
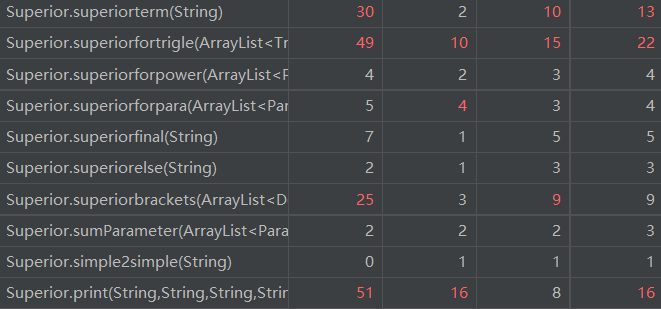
分析来看,整体的复杂程度和耦合程度集中于程序的化简部分,这造成了一定的资源浪费。而复杂的化简流程也造成了一定错误的产生,损失了面向对象过程的带来的优越性,但可扩展性较第一次作业得以增强。出于第二次作业的复杂,我在第三次作业进行了简化。
优缺点分析
-
优点分析
-
采用工厂模式,结构较为清晰
-
可扩展性得以提升
-
-
缺点分析
-
存储操作未处理好
-
部分嵌套处理混乱
-
评测结果
第二次作业由于优化过度造成了强测中的2个bug,互测阶段也被找出了4个bug,找出了同房间内存在的7个bug。
3. 第三次作业
作业思路
本次作业基于第二次作业进行迭代改进,优化工厂模式,进行增量开发。主要修改了以下内容:
-
求导方式;
-
化简方式;
-
增加了格式检查;
-
三角函数
sin和cos的属性与解析方式; -
实现了三角函数的嵌套求导。
对于格式判断,使用大正则表达式会导致爆栈出错,是不可取的操作。
因此,我采用了递归的方式,通过利用#替代嵌套,将#纳入符合的格式要求,实现格式检查。
比如(3*x+2)*cos(x):
在我使用的方法中,即可将它转换为#*cos(x),对其进行项的格式检查即可,深层嵌套通过递归以此类推。其他具体思路与第二次作业大体相同。
重要类/接口分析
-
格式判断和输入处理:
Factory, Main-
Factory类:工厂类,完成输入处理,包括表达式的拆分与项的拆分,实现格式判断 -
Main类:主函数,完成输入预处理,如符号替换
-
-
表达式树:
Expression, poly, Factor, Constant, Power, Tricos, Trisin, Brackets-
Expression类:存放表达式,形成表达式树,包括求导、输出功能 -
poly类:存放项类,构成项结点,包括求导、输出功能 -
Factor类:存放因子类,构成因子结点,包括求导、输出功能 -
Constant类:存放常数类,构成常数结点,包括求导、输出功能 -
Power类:存放幂函数类,构成幂函数结点,包括求导、输出功能 -
Tricos类:存放三角函数类,构成三角函数结点,包括求导、输出功能 -
Trisin类:存放三角函数类,构成三角函数结点,包括求导、输出功能 -
Brackets类:存放嵌套类,构成嵌套结点,包括求导、输出功能
-
-
求导化简:
Factory-
Factory类:处理工厂,包括解析表达式,以及化简功能
-
代码可视化与数据统计的程序度量
-
程序UML类图
在第二次作业中我一共创建了共包含10个类,这主要被划分为3个部分。
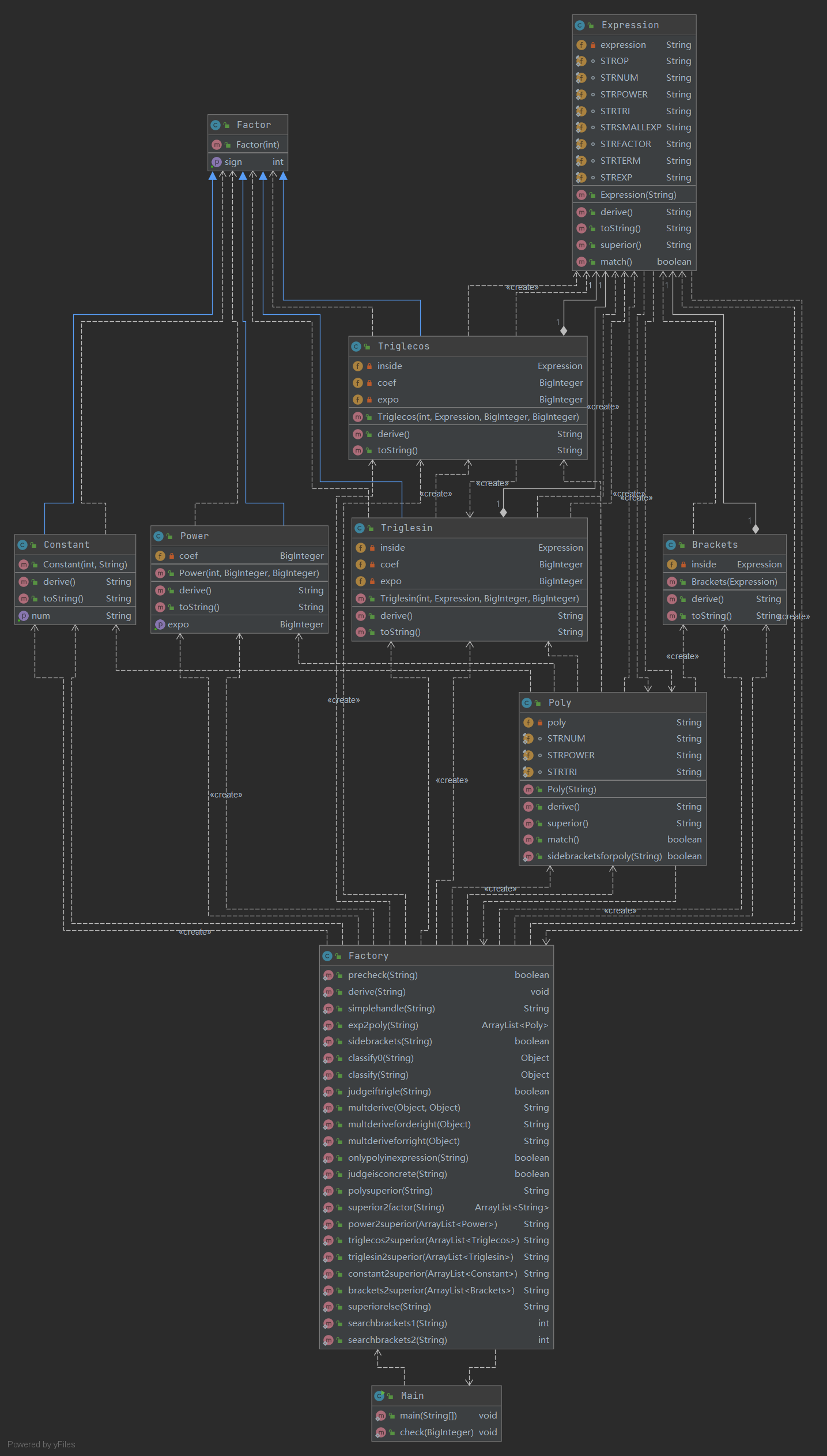
-
代码规模分析
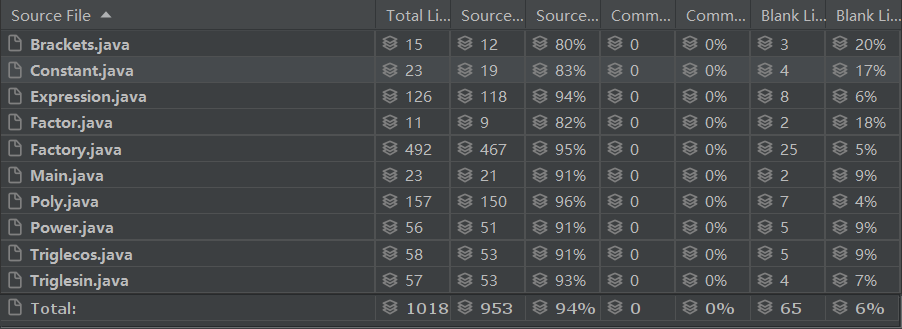
分析来看,由于以面向对象的方法作为指导,进行了良好架构的设计与优化,本次作业代码规模比上次大大减少,同时除了工厂需要进行大量处理操作之外,其他类的规模合理,没有臃肿庞大的类。
-
类的复杂度分析
| class | OCavg | OCmax | WMC |
|---|---|---|---|
| Brackets | 1.0 | 1.0 | 3.0 |
| Constant | 1.25 | 2.0 | 5.0 |
| Expression | 5.2 | 15.0 | 26.0 |
| Factor | 1.0 | 1.0 | 2.0 |
| Factory | 5.86 | 16.0 | 135.0 |
| Main | 2.0 | 2.0 | 4.0 |
| Poly | 8.8 | 17.0 | 44.0 |
| Power | 3.75 | 8.0 | 15.0 |
| Triglecos | 4.66 | 8.0 | 14.0 |
| Triglesin | 4.66 | 8.0 | 14.0 |
| Total | 262.0 | ||
| Average | 4.85 | 7.8 | 26.2 |
分析来看,在本次作业架构的设计上,我使用了很好的面向对象的处理方式,将主要对象分为Expression, Poly, Factor
-
方法的复杂度分析
| method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Triglesin.Triglesin(int,Expression,BigInteger,BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| Triglesin.toString() | 12.0 | 2.0 | 7.0 | 8.0 |
| Triglesin.derive() | 4.0 | 2.0 | 2.0 | 5.0 |
| Triglecos.Triglecos(int,Expression,BigInteger,BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| Triglecos.toString() | 12.0 | 2.0 | 7.0 | 8.0 |
| Triglecos.derive() | 4.0 | 2.0 | 2.0 | 5.0 |
| Power.toString() | 12.0 | 2.0 | 5.0 | 8.0 |
| Power.Power(int,BigInteger,BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| Power.getExpo() | 0.0 | 1.0 | 1.0 | 1.0 |
| Power.derive() | 4.0 | 2.0 | 2.0 | 5.0 |
| Poly.superior() | 0.0 | 1.0 | 1.0 | 1.0 |
| Poly.sidebracketsforpoly(String) | 18.0 | 7.0 | 8.0 | 13.0 |
| Poly.Poly(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Poly.match() | 34.0 | 12.0 | 17.0 | 20.0 |
| Poly.derive() | 37.0 | 15.0 | 19.0 | 20.0 |
| Main.main(String[]) | 1.0 | 2.0 | 2.0 | 2.0 |
| Main.check(BigInteger) | 2.0 | 1.0 | 3.0 | 3.0 |
| Factory.triglesin2superior(ArrayList) | 2.0 | 2.0 | 2.0 | 3.0 |
| Factory.triglecos2superior(ArrayList) | 2.0 | 2.0 | 2.0 | 3.0 |
| Factory.superiorelse(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Factory.superior2factor(String) | 8.0 | 1.0 | 6.0 | 6.0 |
| Factory.simplehandle(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Factory.sidebrackets(String) | 12.0 | 5.0 | 6.0 | 10.0 |
| Factory.searchbrackets2(String) | 3.0 | 3.0 | 2.0 | 3.0 |
| Factory.searchbrackets1(String) | 3.0 | 3.0 | 2.0 | 3.0 |
| Factory.precheck(String) | 3.0 | 3.0 | 2.0 | 3.0 |
| Factory.power2superior(ArrayList) | 2.0 | 2.0 | 2.0 | 3.0 |
| Factory.polysuperior(String) | 15.0 | 5.0 | 11.0 | 13.0 |
| Factory.onlypolyinexpression(String) | 13.0 | 4.0 | 7.0 | 10.0 |
| Factory.multderiveforright(Object) | 5.0 | 5.0 | 5.0 | 5.0 |
| Factory.multderiveforderight(Object) | 5.0 | 5.0 | 5.0 | 5.0 |
| Factory.multderive(Object,Object) | 16.0 | 4.0 | 7.0 | 15.0 |
| Factory.judgeisconcrete(String) | 7.0 | 3.0 | 4.0 | 6.0 |
| Factory.judgeiftrigle(String) | 13.0 | 6.0 | 8.0 | 11.0 |
| Factory.exp2poly(String) | 13.0 | 1.0 | 8.0 | 10.0 |
| Factory.derive(String) | 1.0 | 1.0 | 2.0 | 2.0 |
| Factory.constant2superior(ArrayList) | 2.0 | 2.0 | 2.0 | 3.0 |
| Factory.classify0(String) | 35.0 | 13.0 | 17.0 | 19.0 |
| Factory.classify(String) | 35.0 | 13.0 | 17.0 | 19.0 |
| Factory.brackets2superior(ArrayList) | 12.0 | 2.0 | 4.0 | 7.0 |
| Factor.getSign() | 0.0 | 1.0 | 1.0 | 1.0 |
| Factor.Factor(int) | 0.0 | 1.0 | 1.0 | 1.0 |
| Expression.toString() | 2.0 | 2.0 | 1.0 | 2.0 |
| Expression.superior() | 7.0 | 1.0 | 6.0 | 6.0 |
| Expression.match() | 37.0 | 11.0 | 15.0 | 19.0 |
| Expression.Expression(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Expression.derive() | 1.0 | 1.0 | 2.0 | 2.0 |
| Constant.toString() | 1.0 | 2.0 | 1.0 | 2.0 |
| Constant.getNum() | 0.0 | 1.0 | 1.0 | 1.0 |
| Constant.derive() | 0.0 | 1.0 | 1.0 | 1.0 |
| Constant.Constant(int,String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Brackets.toString() | 0.0 | 1.0 | 1.0 | 1.0 |
| Brackets.derive() | 0.0 | 1.0 | 1.0 | 1.0 |
| Brackets.Brackets(Expression) | 0.0 | 1.0 | 1.0 | 1.0 |
| Total | 395.0 | 168.0 | 237.0 | 304.0 |
| Average | 7.31 | 3.11 | 4.3 | 5.6 |
分析来看,主要的复杂度出现在对于格式检查的处理上,由于我将格式检查和多项式求导分成了不相关的两个模块,造成了部分的重复,使得格式检查中复杂度增大。而对于多项式的计算部分,我使用了面向对象的方式进行处理与分析,复杂度相比第二次作业改进许多,这是我认为我做的比较好的地方。
优缺点分析
-
优点分析
-
采用工厂模式,结构清晰
-
可扩展性良好
-
面向对象思维方式,可靠性改善
-
-
缺点分析
-
化简操作有待提升
-
评测结果
第三次作业中由于对面向对象思想的良好吸收与运用,在强测中没有出现bug,由于在格式检查中的一个小笔误,造成了互测中被测出了1次bug。同房间内实现较好,没有测出他人的bug。
二、程序的bug分析
自身程序bug
1. 第一次作业
强测与互测均没有出现bug。
2. 第二次作业
强测出现了两个bug,其一是由于内部处理不好的递归调用,位于求导类,造成了程序超时,分析后发现,内部过多的tostring()语句是造成它的主要原因。具体改进是,应该将其首先存入一个变量之中,而后调用变量即可,因为多次调用tostring()语句实际上是在调用类中的某个函数,将函数重新运行一遍,而变量即可解决这一问题。
对于另一个的bug,是由于化简造成,位于工厂类的化简方法中。我误将项中因子的化简合并的*号当做+号,将第一次作业中合并同类项的代码直接复制使用,造成了这一错误的出现。
我对此的感想是,未来代码的模块即使与在之前的作业中实现过,也应该再次认真地敲一遍,而不是直接复制粘贴。
互测中被hack的bug也是同样造成的,修复了以上2个bug的主要问题后,强测、互测均通过。
-
代码行和圈复杂度的差异
出现bug方法的代码如下:
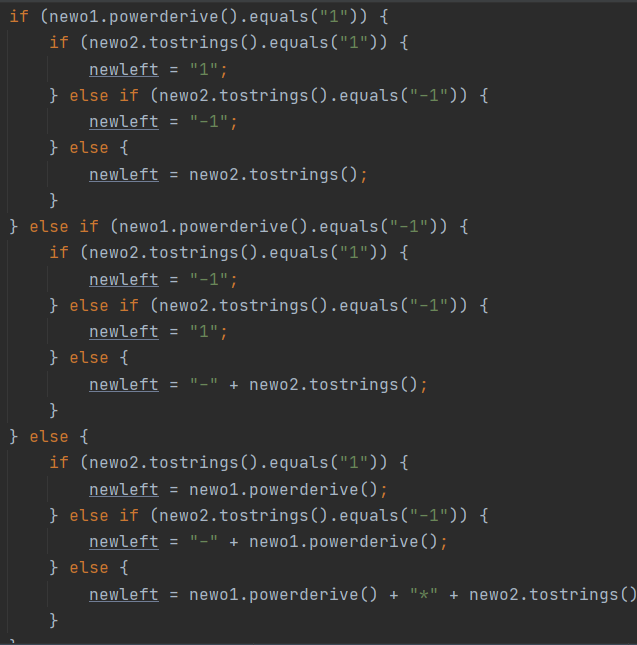
如上所述,大量使用toString()导致了错误,这也导致如上所示的代码行大大增多(由前文代码规模也可见)。同时,根据前文圈复杂度的列举,可以发现该模块(求导模块)的圈复杂度也相比其他未出现bug的方法模块要高许多。
3. 第三次作业
强测中没有出现bug。在互测中bug存在于如下的笔误之中:
for(i=str.length-1; i>=0; i++) {
...
}
由于惯性思维,错把i--写成i++,导致了程序出现了bug。
-
代码行和圈复杂度的差异
由于该bug的特殊性,没有对代码行与圈复杂度造成影响。
综上所述,也说明了无论对于多么好的设计,如果实现的细节没有到位,那么仍会导致同样的结果。因此,我对此的感想是以后应该更加细致,注意程序的细节之处。
他人程序bug
1. 第一次作业
互测中我测出了他人一个bug。原因是其未对计算结果为0的情况进行考虑。
例如输入:
x-x
其没有任何输出,正确的处理方式是对于结果为0时,即容器中不存在内容,应该输出0。
2. 第二次作业
在第二次作业中,我利用评测机与手动构建边缘样例,测试出了他人8个bug。
这些bug主要是由于内部嵌套的处理不足,而导致超时造成。可能出现错误的方式也与我相同,即多次调用了同一个toString()。这导致如下面对如下的测试用例,代码无法运行完毕。
x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x*x
(((((((((((((((((x)))))))))))))))))
此外,对于0的处理也是很大的问题。
例如,应该在结果为:
(0)
的时候输出(0),但其错误地输出了(),即缺少对于括号内元素的判断,这也是应该注意的地方。
3. 第三次作业
本次作业互测中没有发现bug。
发现bug的策略
本次我采取的测试策略:测评机黑箱测试 + 手动构建边缘测试样例。
-
测评机黑箱测试
实现自动测试的主要内容分为:
-
求导
-
化简
-
比较
具体而言,首先对测试用例进行分类。例如常数、三角函数、嵌套类,再利用正则表达式生成字符串,进行针对性构造。由于数据长度的限制,生成数据时,应该生成长度直到小于等于50。此后,再利用
python sympy库中的diff等函数实现比较。基于测评机的黑箱测试可以针对正确性进行测试。然而这难以覆盖格式判断以及超时造成的错误。因此,被需要引入手动构建的边缘测试样例。在实际操作中,也证明了此种方法在本次作业中寻找bug更加有效。
-
-
手动构建边缘测试样例
手动构建边缘样例的方式主要涵盖以下三种:
-
极端数据
-
自己测试时出现的bug的数据
-
阅读代码寻找薄弱点
其具体说明如下:
-
极端数据
手动构建用例更具有针对性,尤其是极端数据,它能够覆盖到边缘的错误。
-
自己测试时出现的bug的数据
由于许多bug在同学之间存在共性,所以对于使用自己测试时出现的bug的数据来测试别人,成功率相对而言比较高。
-
阅读代码
阅读代码不但能找到他人代码的薄弱之处,也能让我们面向对象的良好设计代码加以学习,进而改进自己的代码。这部分正是结合被测程序的代码设计结构。
但由于阅读代码比较耗时,我们应该有针对性地阅读。例如重点阅读面向过程的代码,对于求导、化简、递归、格式判断是本次作业主要的出错点。例如当对方代码处理递归非常复杂时,可能出现超时现象,应构造相应的极端数据进行针对性hack,例如:
(((((((((((((((x))))))))))))))) -
三、重构经历总结
第三次作业重构
重构过程
本单元主要在第三次作业开发时重构了解析的递归调用方式和面向对象的类的存储方式。
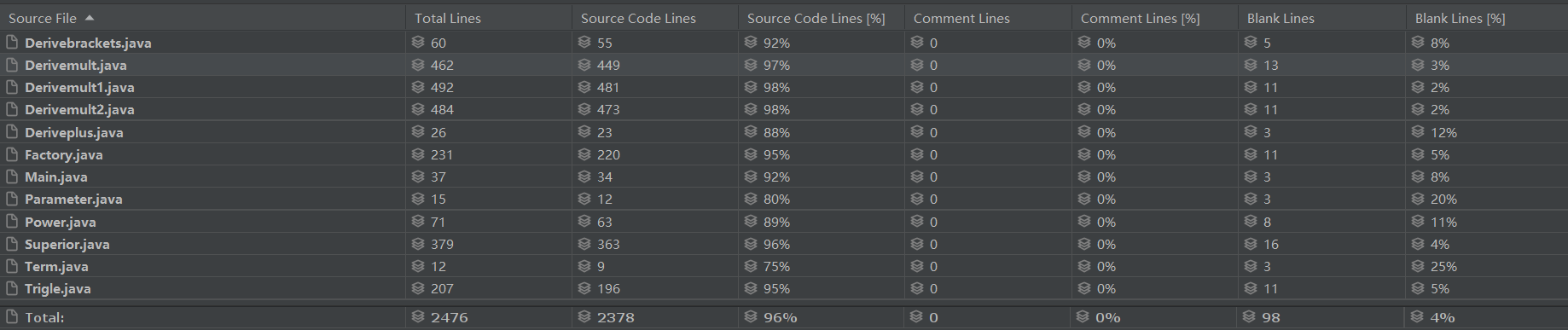
由于第一次作业较为简单,未涉及需要进行递归的复杂表达式求导,或面向对象上许多类的存储方式,因此不需要太多改动。第二次作业由于表达式嵌套的引入,以及三角函数的构成,在第一次简单架构的基础上进行一些删改,即完成了第二次的构建,但正因如此,可扩展性无法保证,如下图所示是重构前的度量数据:
在第三次作业的过程中,由于三角函数内也支持嵌套,因此便开展了重构过程。
在整个重构过程的开始,收到课程的启发以及研讨课的收获,我先进行的是对对象的类的构建。以递归下降为指导,我定义了Expresssion, Poly和Factor三大类,作为表达式、项、因子这三种对象,基于此,我使用继承的关系,在Factor的基础上继承了三角函数、常数、嵌套等子类。基于此,结合工厂模式,我开展了代码的正式编写。
在编写过程中,我以工厂模式作为指导,依托高内聚低耦合的思路对表达式开展递归下降的解析,一些关于判断或解析的主要函数我已经前两次填写完成,因此书写代码的时间并不长。最后实现的时候,整个代码的性能、框架、复杂度、正确性都得到了极大的改善,以下是重构后的度量数据:
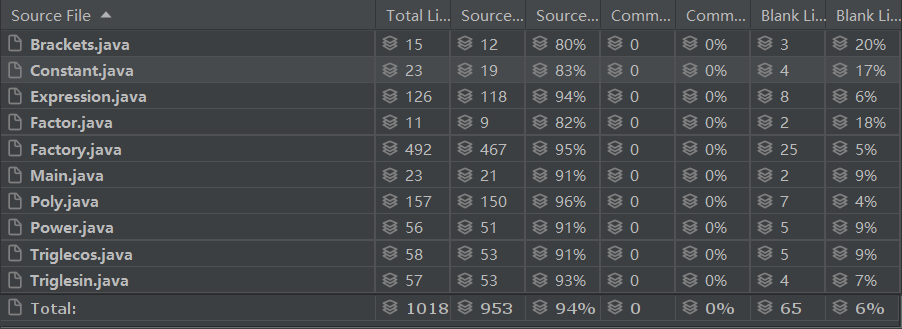
最后,在此基础上我添加了格式判断模块,便完成了第三次作业的重构工作,由上述度量数据的对比可知,程序结构形成了较大改善,重构前代码长度为2476,重构后代码长度为1018,即仅用不到重构前不到一半的代码长度便实现了可靠性更高的功能。
经验总结
-
重构的过程中,我书写代码时的感受或心情与以往不同。这是因为经过重构后代码非常具有结构化,思路非常清晰。因此,给我的感受是一定要先依托面向对象的思路来设计架构,而后进行代码填写。
-
完成代码时,尤其是具有后续迭代的任务,应该考虑后续的工作,初期不要认为只满足当下的要求即可,实际上去重构的时间会远大于自己初期便设计好一个可扩展性的架构的时间。
-
针对本次重构,我对字符串的解析中递归下降法收获颇丰,这可能有助于未来编译原理的学习。因此,在未开始编写代码时,往往对于方法的思考或者查找,将大于自己随心所欲的想法的效果,应该通过更多途径去寻找任务良好的解决方案。
四、心得体会
本单元作业基于表达式求导,从第一次简单的幂函数迭代到最后的嵌套,整体的开发、迭代、重构、测试过程真的是我收获颇丰,我真切体会到从多个角度令我具有了很大的进步。我将此总结为如下四个方面:
-
技术层面,通过本次作业我掌握了面向对象的思想,能够依托工厂模式,基于继承、接口等面向对象编程的基础知识,来层次化与低耦合实现项目的正确性以及可扩展性。同时,我掌握了更加工程化的方法完成项目, 本次作业设计了对于开发、拓展、测试、debug的各个环节,使我对工程开发有所了解。这将更有助于我在未来工作方面的项目开发,是我一次很有收获的体会。
-
理论层面,我具有了更深层次对
java语言的掌握,checkstyle的纳入使我理解了工程代码规范。同时,本次作业以解析表达式为出发点使我了解到如何基于递归下降来解析数据。 -
能力层面,本次作业增强了我项目开发的工程实现能力,例如程序的测试能力,debug能力等,使我熟悉了如何利用
python库进行比对与测试,提升了我的项目测试能力。同时,我在讨论区的积极参与,也提升了我的团队合作能力,在我对别人启发的时候我也受到了帮助。 -
意志层面,这三次作业的练习磨炼了我的意志力,限时的作业强大了我的意志,使我能够更加专心的书写代码。在强测与互测中,我的心理抗压能力也得到了很大提升,具有更加良好的心理素质,来面对未来更加复杂的开发环境。
总之,在面向对象的学习过程中,永不气馁、勇于尝试就会学习到更多的知识,在未来的三个单元中,我也会更加努力,基于过去总结的经验,迎接未来新的挑战。做好每一天的事,相信美好的事情即将发生。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号