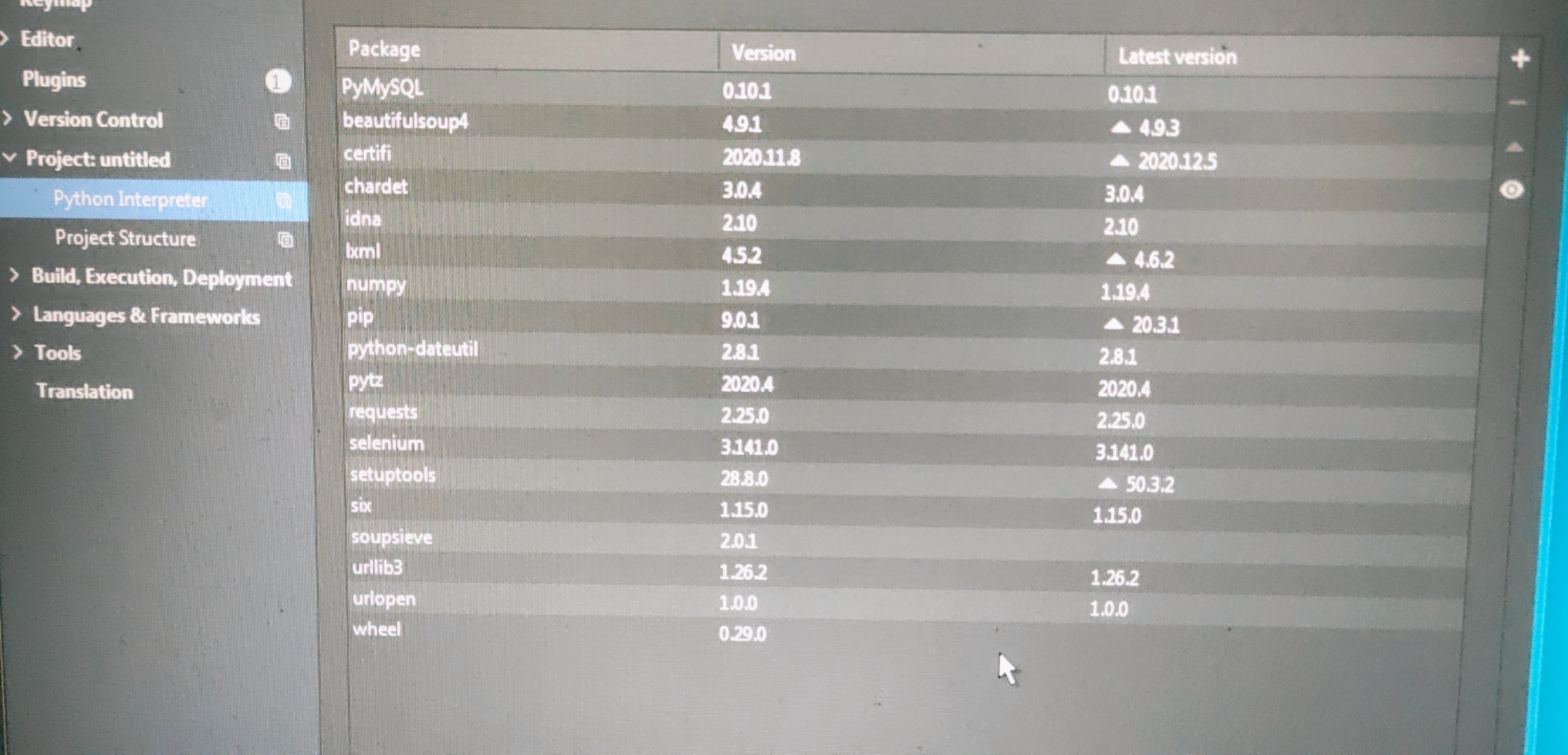
导入python包时,导入失败以及port=443报错
在导入python包时出现下载失败以及443报错:
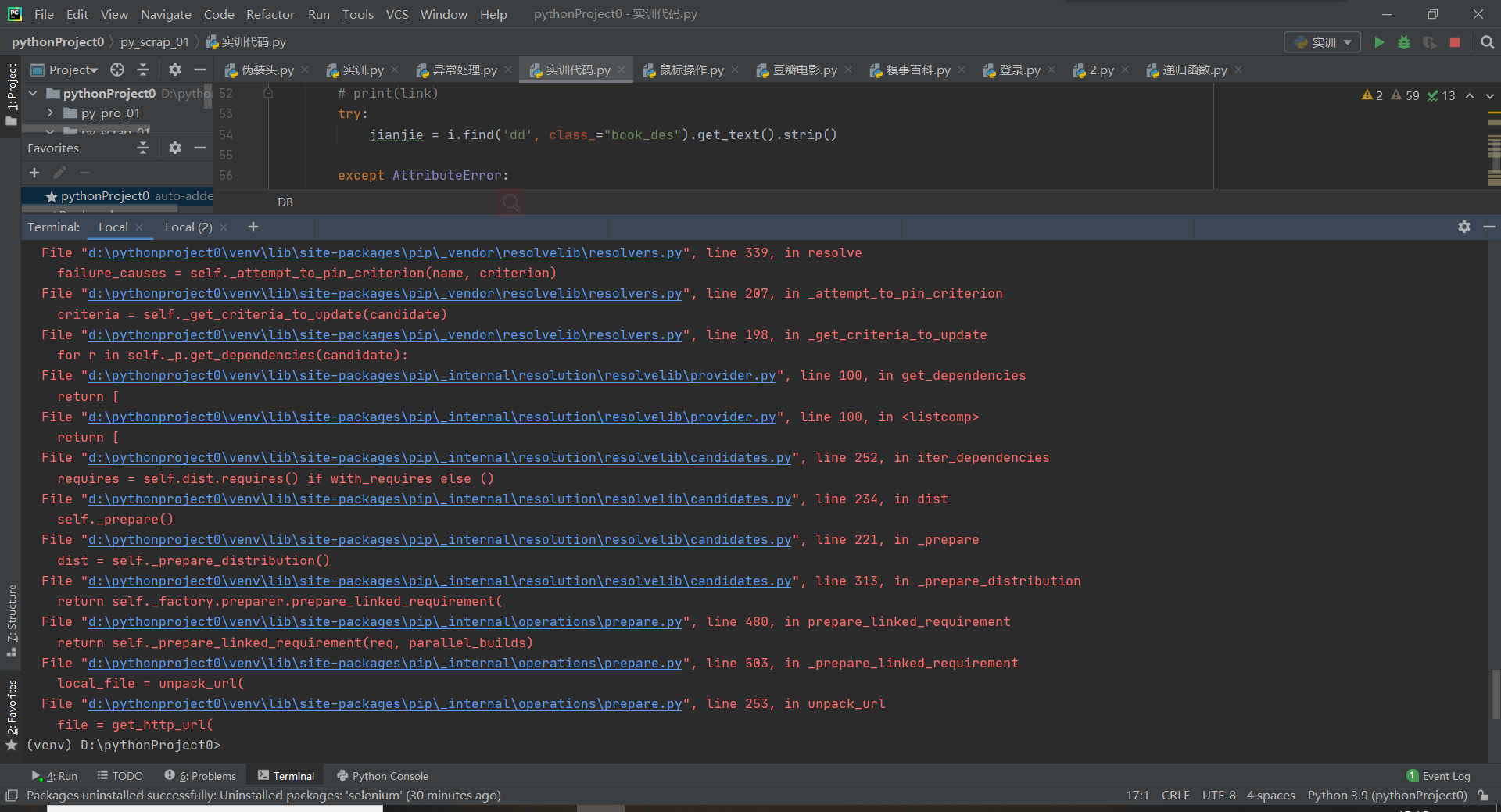
443报错:
问题是与服务器连接后服务器端传输速率过慢 或 个人网络连接下载速度不给力
解决方法:
1.更换网络
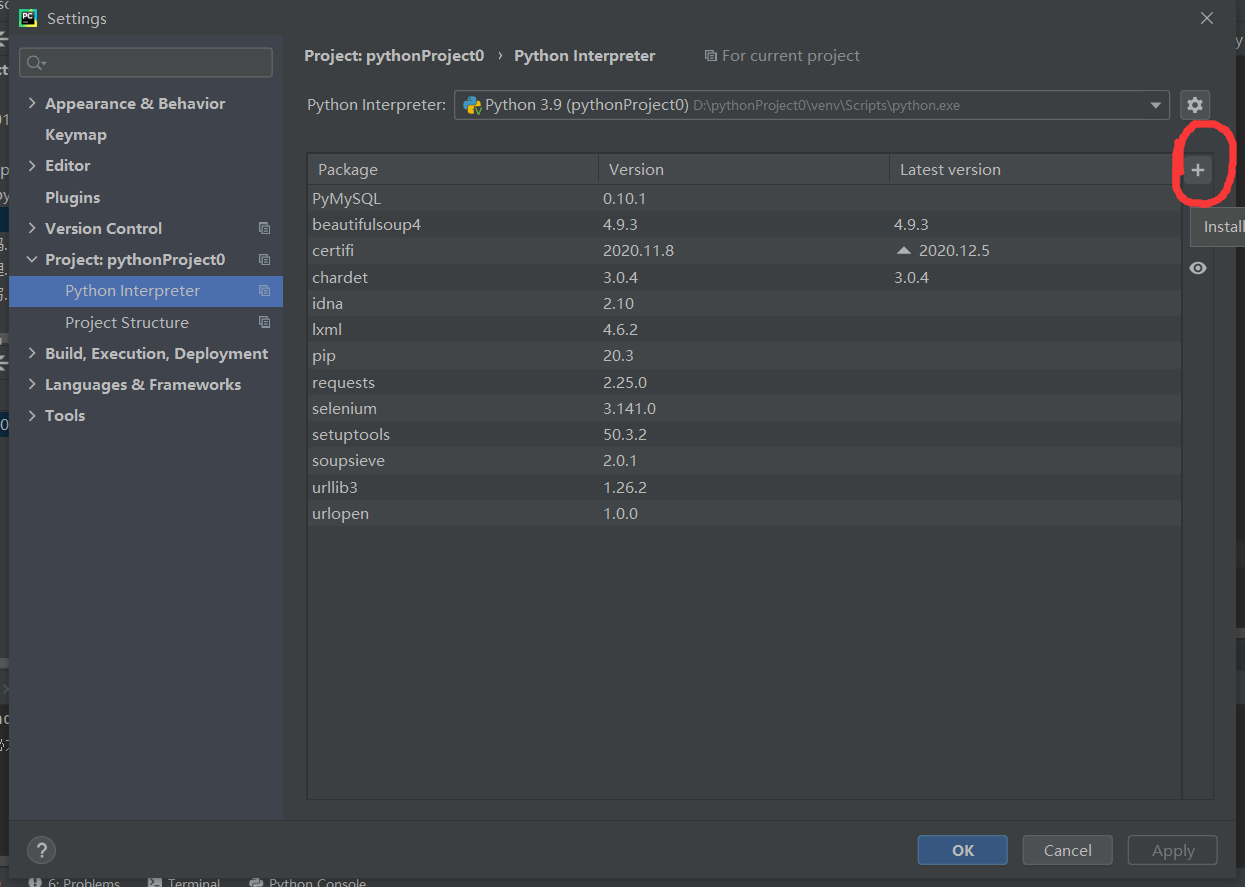
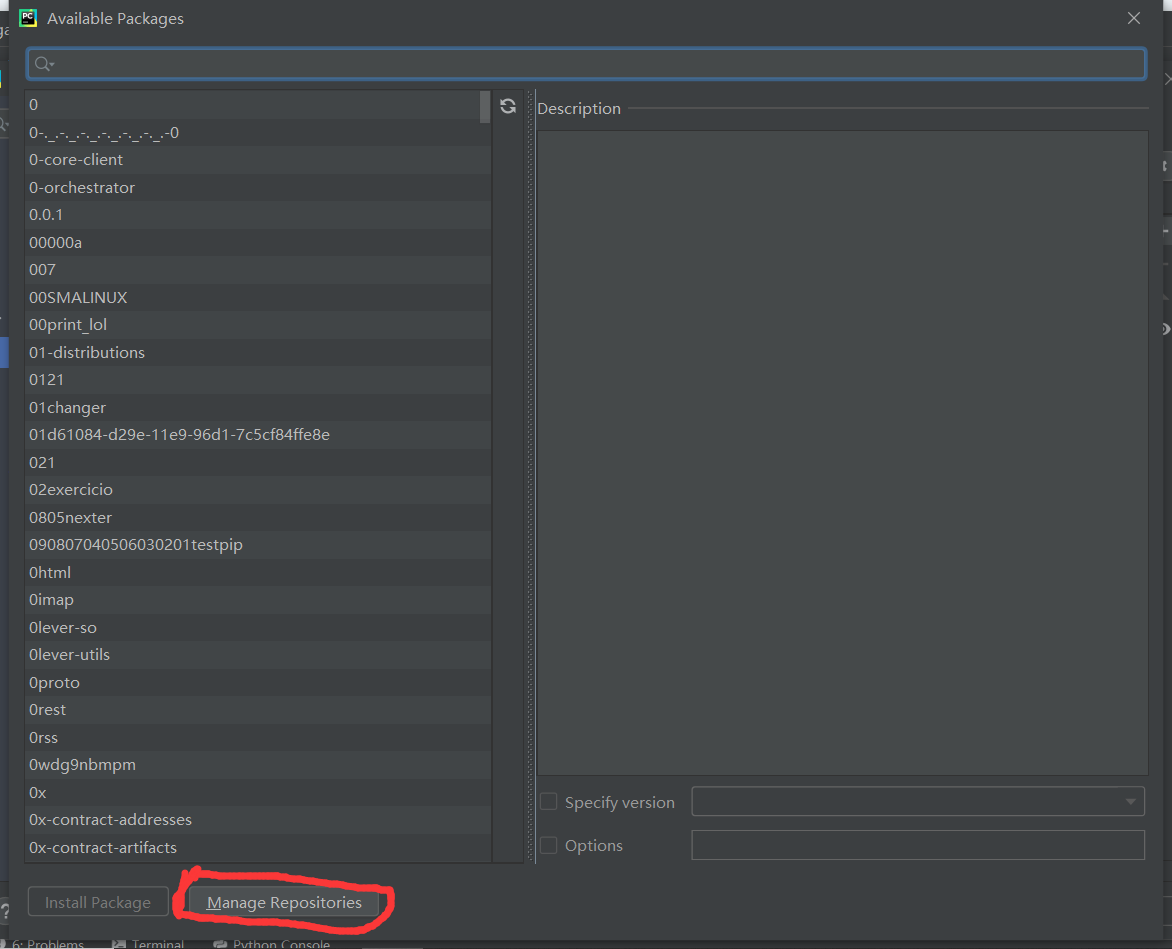
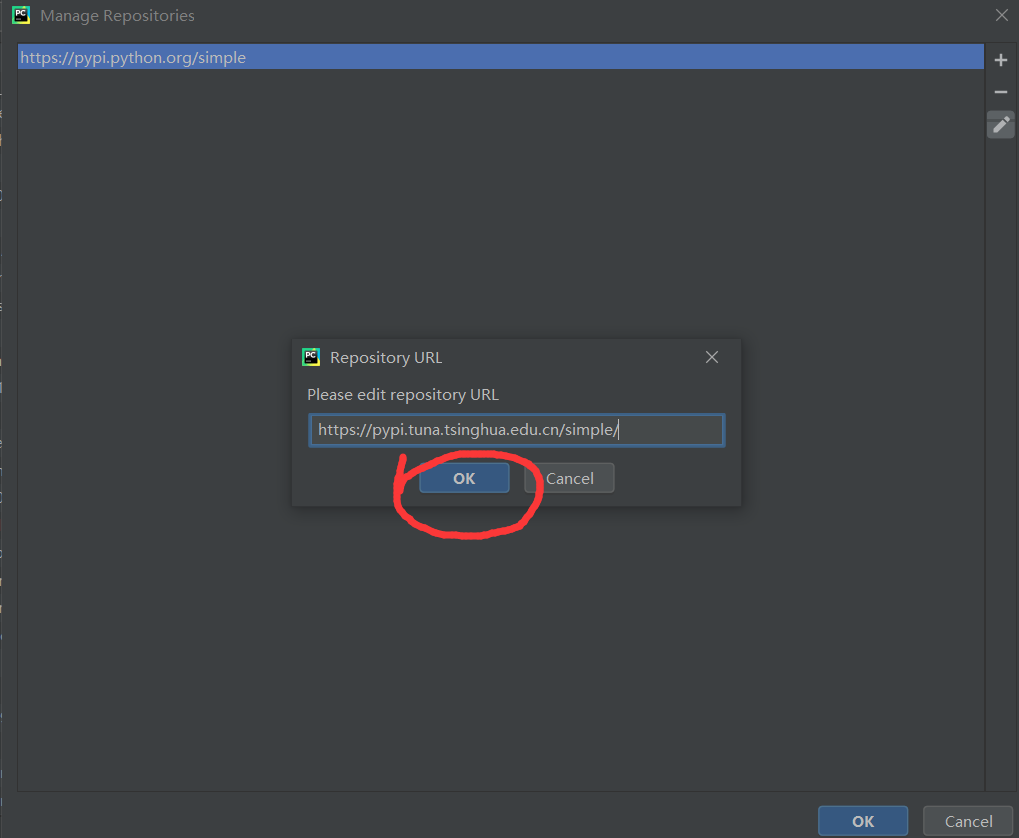
2.改用国内映像为:
清华:https://pypi.tuna.tsinghua.edu.cn/simple/ (推荐)
阿里云:https://mirrors.aliyun.com/pypi/simple/
豆瓣:https://pypi.douban.com/simple/
默认:https://pypi.python.org/simple


---------------------------------------------------------------------分隔符---------------------------------------------------------------------
参考学习爬取小说内容并下载的代码:
爬取网址:
http://www.shuquge.com/txt/8659/2324753.html
参考网址:
http://www.manongjc.com/detail/13-rkktrjtmgjgiuwg.html
代码:
import requests
import parsel
# 模拟浏览器发送请求
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'
}
def download_one_chapter(target_url):
# 需要请求的网址
# target_url = 'http://www.shuquge.com/txt/8659/2324753.html'
# response 服务返回的内容 对象
# pycharm ctrl+鼠标左键
response = requests.get(target_url, headers=headers)
# 解码 万能解码
response.encoding = response.apparent_encoding
# 文字方法 获取网页文字内容
# print(response.text)
# 字符串
html = response.text
"""从网页源代码里面拿到信息"""
# 使用parsel 把字符串变成对象
sel = parsel.Selector(html)
# scrapy
# extract 提取标签的内容
# 伪类选择器(选择属性) css选择器(选择标签)
# 提取第一个内容
title = sel.css('.content h1::text').extract_first()
# 提取所有的内容
contents = sel.css('#content::text').extract()
print(title)
print(contents)
""" 数据清除 清除空白字符串 """
# contents1 = []
# for content in contents:
# # 去除两端空白字符
# # 字符串的操作 列表的操作
# contents1.append(content.strip())
#
# print(contents1)
# 列表推导式
contents1 = [content.strip() for content in contents]
print(contents1)
# 把列表编程字符串
text = '\n'.join(contents1)
print(text)
"""保存小说内容"""
# open 操作文件(写入、读取)
file = open(title + '.txt', mode='w', encoding='utf-8')
# 只能写入字符串
file.write(title)
file.write(text)
# 关闭文件
file.close()
# 传入一本小说的目录
def get_book_links(book_url):
response = requests.get(book_url)
response.encoding = response.apparent_encoding
html = response.text
sel = parsel.Selector(html)
links = sel.css('dd a::attr(href)').extract()
return links
# 下载一本小说
def get_one_book(book_url):
links = get_book_links(book_url)
for link in links:
print('http://www.shuquge.com/txt/8659/' + link)
download_one_chapter('http://www.shuquge.com/txt/8659/' + link)
if __name__ == '__main__':
# target_url = 'http://www.shuquge.com/txt/8659/2324754.html'
# # 关键词参数与位置参数
# download_one_chapter(target_url=target_url)
# 下载别的小说 直接换url
book_url = 'http://www.shuquge.com/txt/8659/index.html'
get_one_book(book_url)
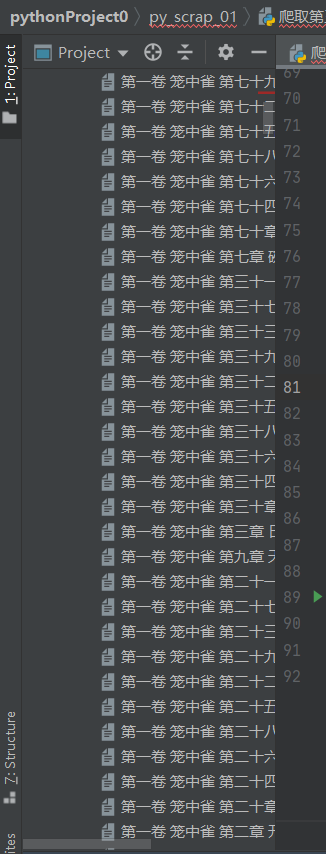
运行结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号