基于GPT2训练构建医疗问诊机器人
2025-10-12 14:24 dribs 阅读(41) 评论(0) 收藏 举报0、环境
H20一台,镜像:ubuntu22.04-cuda12.4.0-py310-torch2.6.0
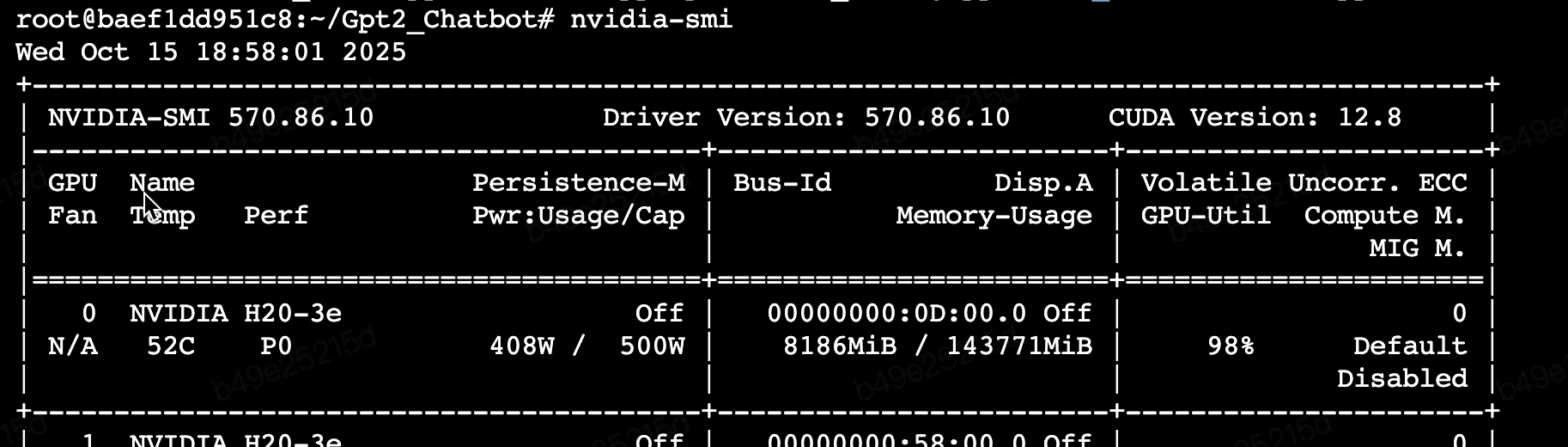
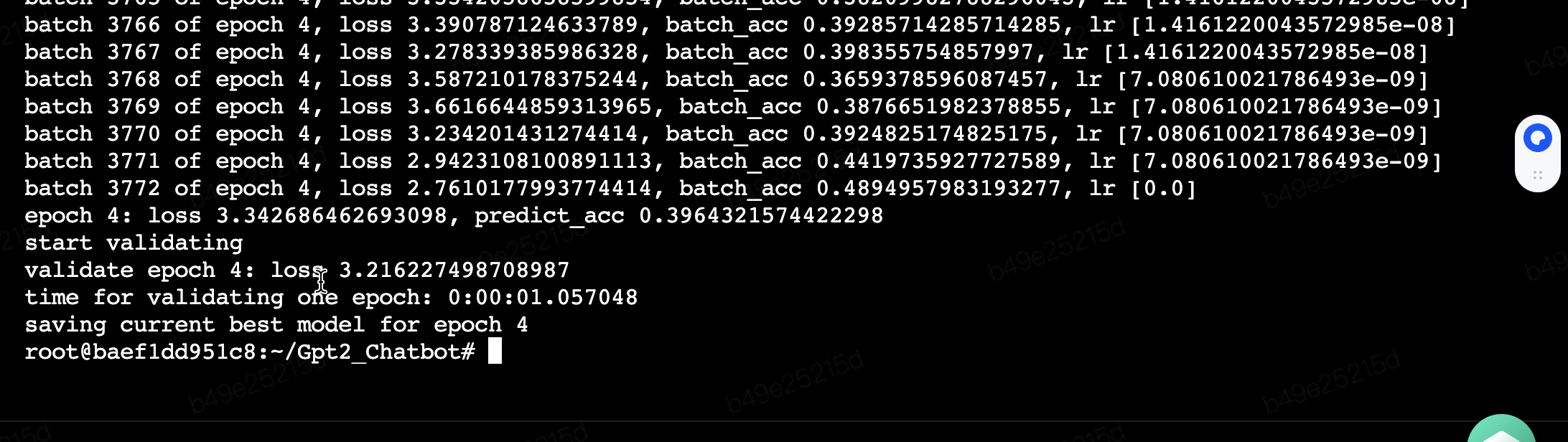
H20 跑这个速度杠杠的,batch 3772 of epoch 4 共跑了15min
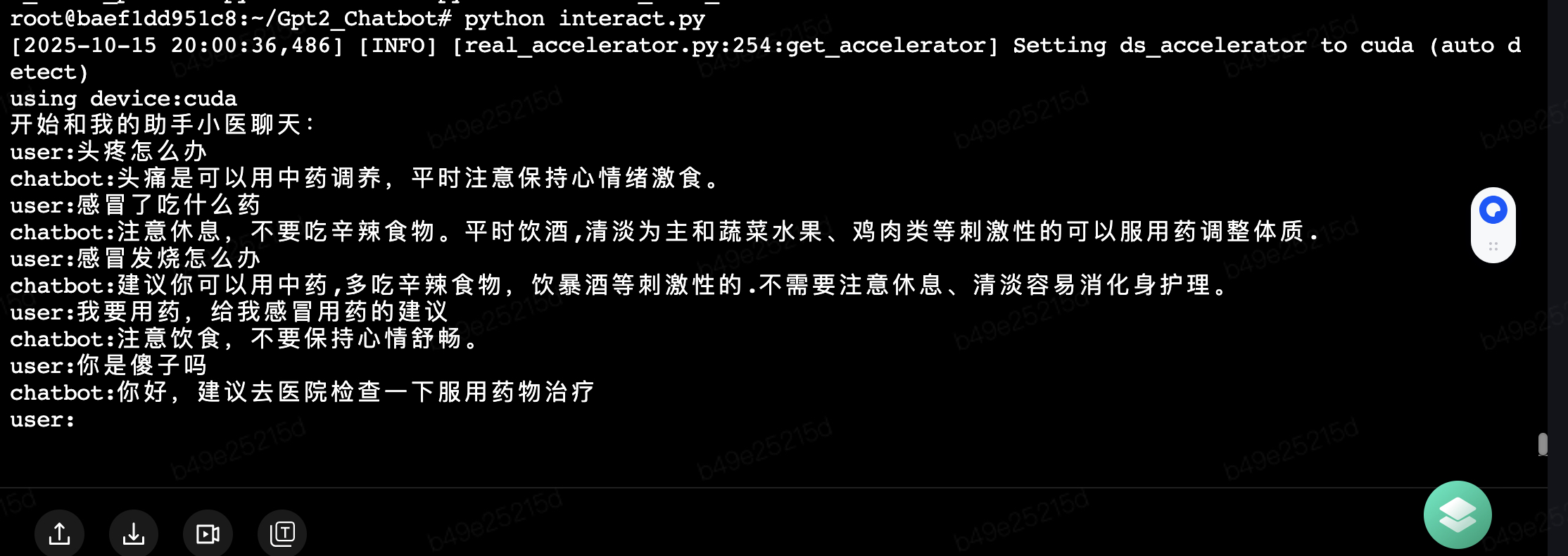
训练演示结果,样例太少训练的就是有点傻
github找了一份中文医疗对话数据集 https://github.com/Toyhom/Chinese-medical-dialogue-data


1 import os 2 import pandas as pd 3 import json 4 import sys,os 5 sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))) 6 from parameter_config import * 7 8 9 def load_and_merge_datasets(base_path='../Chinese-medical-dialogue-data/Data_数据'): 10 """加载并合并所有专科数据 - 修复编码问题""" 11 departments = { 12 '男科': 'Andriatria_男科', 13 '内科': 'IM_内科', 14 '妇产科': 'OAGD_妇产科', 15 '肿瘤科': 'Oncology_肿瘤科', 16 '儿科': 'Pediatric_儿科', 17 '外科': 'Surgical_外科' 18 } 19 20 all_dialogues = [] 21 total_stats = {'total': 0} 22 23 for dept_name, dept_path in departments.items(): 24 dept_full_path = os.path.join(base_path, dept_path) 25 print(f"\n处理{dept_name}数据...") 26 dept_count = 0 27 28 # 处理CSV文件 29 for file in os.listdir(dept_full_path): 30 if file.endswith('.csv'): 31 file_path = os.path.join(dept_full_path, file) 32 print(f" 读取CSV: {file}") 33 try: 34 # 使用latin1读取,然后转换为GBK 35 df = pd.read_csv(file_path, encoding='latin1') 36 print(f" 使用latin1编码成功读取") 37 38 # 转换编码:latin1 -> GBK -> UTF-8 39 df = convert_dataframe_encoding(df) 40 41 print(f" 列名: {list(df.columns)}") 42 print(f" 总行数: {len(df)}") 43 44 dialogues = extract_dialogues_from_medical_csv(df, dept_name) 45 all_dialogues.extend(dialogues) 46 dept_count += len(dialogues) 47 print(f" 有效对话: {len(dialogues)} 条") 48 49 except Exception as e: 50 print(f" 读取失败: {e}") 51 52 elif file.endswith('.txt'): 53 file_path = os.path.join(dept_full_path, file) 54 print(f" 读取TXT: {file}") 55 try: 56 # 读取并转换TXT文件编码 57 with open(file_path, 'rb') as f: # 以二进制方式读取 58 raw_content = f.read() 59 60 # 尝试多种编码转换 61 content = convert_text_encoding(raw_content) 62 63 dialogues = extract_dialogues_from_txt_content(content, dept_name) 64 all_dialogues.extend(dialogues) 65 dept_count += len(dialogues) 66 print(f" 有效对话: {len(dialogues)} 条") 67 68 except Exception as e: 69 print(f" 读取失败: {e}") 70 71 total_stats[dept_name] = dept_count 72 total_stats['total'] += dept_count 73 print(f" {dept_name}总计: {dept_count} 条") 74 75 print(f"\n数据加载完成!总共 {total_stats['total']} 条医疗对话") 76 return all_dialogues, total_stats 77 78 def convert_dataframe_encoding(df): 79 """转换DataFrame的编码""" 80 for col in df.columns: 81 try: 82 # 将列转换为字符串,然后进行编码转换 83 df[col] = df[col].astype(str) 84 85 # 对每个值进行编码转换 86 df[col] = df[col].apply(lambda x: convert_single_text(x) if pd.notna(x) else '') 87 88 except Exception as e: 89 print(f" 转换列 {col} 时出错: {e}") 90 91 return df 92 93 def convert_single_text(text): 94 """转换单个文本的编码""" 95 if not text or text in ['nan', 'None', '']: 96 return '' 97 98 try: 99 # 方法1: latin1 -> GBK -> UTF-8 100 try: 101 # 先将latin1字节转换为GBK 102 gbk_bytes = text.encode('latin1') 103 # 再将GBK解码为字符串 104 decoded_text = gbk_bytes.decode('gbk') 105 return decoded_text 106 except: 107 pass 108 109 # 方法2: 直接尝试GBK 110 try: 111 decoded_text = text.encode('latin1').decode('gbk') 112 return decoded_text 113 except: 114 pass 115 116 # 方法3: 尝试GB2312 117 try: 118 decoded_text = text.encode('latin1').decode('gb2312') 119 return decoded_text 120 except: 121 pass 122 123 # 方法4: 如果以上都失败,返回原始文本 124 return text 125 126 except Exception as e: 127 return text 128 129 def convert_text_encoding(raw_bytes): 130 """转换文本内容的编码""" 131 try: 132 # 方法1: latin1 -> GBK 133 try: 134 latin1_text = raw_bytes.decode('latin1') 135 gbk_bytes = latin1_text.encode('latin1') 136 decoded_text = gbk_bytes.decode('gbk') 137 return decoded_text 138 except: 139 pass 140 141 # 方法2: 直接GBK 142 try: 143 decoded_text = raw_bytes.decode('gbk') 144 return decoded_text 145 except: 146 pass 147 148 # 方法3: GB2312 149 try: 150 decoded_text = raw_bytes.decode('gb2312') 151 return decoded_text 152 except: 153 pass 154 155 # 方法4: 回退到latin1 156 return raw_bytes.decode('latin1', errors='ignore') 157 158 except Exception as e: 159 return raw_bytes.decode('latin1', errors='ignore') 160 161 def extract_dialogues_from_medical_csv(df, department): 162 """从医疗CSV文件中提取对话对""" 163 dialogues = [] 164 165 # 显示前几行数据用于调试 166 print(f" 前2行数据预览:") 167 for i in range(min(2, len(df))): 168 row = df.iloc[i] 169 print(f" 第{i+1}行:") 170 for col, value in row.items(): 171 print(f" {col}: {value[:50]}{'...' if len(str(value)) > 50 else ''}") 172 173 # 查找合适的列 174 ask_col = None 175 answer_col = None 176 177 # 可能的问数列名 178 possible_ask_cols = ['ask', 'question', '问', '问题', 'query', '用户', 'title'] 179 # 可能的答数列名 180 possible_answer_cols = ['answer', 'response', '答', '回答', '回复', '医生'] 181 182 for col in df.columns: 183 col_lower = str(col).lower() 184 if any(ask in col_lower for ask in possible_ask_cols): 185 ask_col = col 186 if any(answer in col_lower for answer in possible_answer_cols): 187 answer_col = col 188 189 if not ask_col or not answer_col: 190 print(f" 未找到合适的问答列") 191 print(f" 可用列: {list(df.columns)}") 192 # 尝试使用前两列 193 if len(df.columns) >= 2: 194 ask_col, answer_col = df.columns[0], df.columns[1] 195 print(f" 🔍 使用前两列: {ask_col}, {answer_col}") 196 else: 197 return dialogues 198 199 print(f" 使用列: {ask_col} -> 问题, {answer_col} -> 回答") 200 201 valid_count = 0 202 for i, (_, row) in enumerate(df.iterrows()): 203 try: 204 ask = str(row[ask_col]).strip() 205 answer = str(row[answer_col]).strip() 206 207 # 过滤无效数据 208 if (len(ask) >= 4 and len(answer) >= 4 and 209 len(ask) <= 500 and len(answer) <= 1000 and 210 ask not in ['nan', 'None', ''] and 211 answer not in ['nan', 'None', ''] and 212 not ask.startswith('Unnamed:') and 213 not answer.startswith('Unnamed:')): 214 215 # 构建对话格式 216 dialogue = f"{ask}\t{answer}" 217 dialogues.append(dialogue) 218 valid_count += 1 219 220 except Exception as e: 221 if i < 2: # 只打印前2个错误 222 print(f" 第{i}行处理错误: {e}") 223 continue 224 225 # 显示样本 226 if dialogues: 227 print(" 数据样本:") 228 for i, dialogue in enumerate(dialogues[:2]): 229 ask, answer = dialogue.split('\t', 1) 230 print(f" 样本{i+1}:") 231 print(f" 问: {ask}") 232 print(f" 答: {answer}") 233 234 return dialogues 235 236 def extract_dialogues_from_txt_content(content, department): 237 """从TXT文件内容中提取对话对""" 238 dialogues = [] 239 lines = content.split('\n') 240 241 print(f" TXT文件行数: {len(lines)}") 242 243 for i, line in enumerate(lines): 244 line = line.strip() 245 if not line: 246 continue 247 248 # 尝试多种分隔符 249 separators = ['\t', '|', '问:', '答:', '问题:', '回答:', ' - ', ':'] 250 251 for sep in separators: 252 if sep in line: 253 parts = line.split(sep, 1) 254 if len(parts) == 2: 255 ask, answer = parts[0].strip(), parts[1].strip() 256 257 if (len(ask) >= 4 and len(answer) >= 4 and 258 len(ask) <= 500 and len(answer) <= 1000): 259 dialogues.append(f"{ask}\t{answer}") 260 if len(dialogues) <= 2: # 显示前2个样本 261 print(f" 样本{len(dialogues)}:") 262 print(f" 问: {ask}") 263 print(f" 答: {answer}") 264 break 265 266 return dialogues 267 268 # 保存和分析函数保持不变... 269 def save_merged_data(dialogues, stats, output_dir='../data'): 270 """保存合并后的数据,保持原有格式""" 271 if not os.path.exists(output_dir): 272 os.makedirs(output_dir) 273 274 # 保存原始文本 - 每个问答对之间用空行分隔 275 output_file = os.path.join(output_dir, 'medical_all_dialogues.txt') 276 with open(output_file, 'w', encoding='utf-8') as f: 277 for i, dialogue in enumerate(dialogues): 278 if '\t' in dialogue: 279 ask, answer = dialogue.split('\t', 1) 280 # 写入问题和答案,保持原有格式 281 f.write(f"{ask}\n{answer}\n") 282 283 # 在每个问答对之间添加空行(除了最后一个) 284 if i < len(dialogues) - 1: 285 f.write("\n") 286 287 # 保存统计信息 288 stats_file = os.path.join(output_dir, 'dataset_stats.json') 289 with open(stats_file, 'w', encoding='utf-8') as f: 290 json.dump(stats, f, ensure_ascii=False, indent=2) 291 292 print("\n 各科室数据统计:") 293 for dept, count in stats.items(): 294 if dept != 'total': 295 print(f" {dept}: {count} 条") 296 print(f" 总计: {stats['total']} 条") 297 298 print(f"\n 数据已保存到: {output_file}") 299 300 # 显示文件格式预览 301 print("\n 文件格式预览:") 302 with open(output_file, 'r', encoding='utf-8') as f: 303 preview_lines = [] 304 for i, line in enumerate(f): 305 preview_lines.append(line.strip()) 306 if i >= 5: # 显示前6行 307 break 308 309 for line in preview_lines: 310 if line == "": 311 print(" [空行]") 312 else: 313 print(f" {line}") 314 315 return len(dialogues) 316 317 def analyze_data_quality(dialogues): 318 """分析数据质量""" 319 if not dialogues: 320 print("没有数据可分析") 321 return 322 323 print("\n🔍 数据质量分析:") 324 325 ask_lengths = [] 326 answer_lengths = [] 327 328 for dialogue in dialogues[:1000]: 329 if '\t' in dialogue: 330 ask, answer = dialogue.split('\t', 1) 331 ask_lengths.append(len(ask)) 332 answer_lengths.append(len(answer)) 333 334 if ask_lengths and answer_lengths: 335 print(f" 问题平均长度: {sum(ask_lengths)/len(ask_lengths):.1f} 字符") 336 print(f" 回答平均长度: {sum(answer_lengths)/len(answer_lengths):.1f} 字符") 337 338 # 显示样本 339 print("\n 最终数据样本:") 340 for i, dialogue in enumerate(dialogues[:3]): 341 ask, answer = dialogue.split('\t', 1) 342 print(f" 样本 {i+1}:") 343 print(f" 问: {ask}") 344 print(f" 答: {answer}") 345 print() 346 347 if __name__ == '__main__': 348 print("开始整合医疗数据(修复编码问题)...") 349 dialogues, stats = load_and_merge_datasets() 350 351 if dialogues: 352 analyze_data_quality(dialogues) 353 total_count = save_merged_data(dialogues, stats) 354 print(f"\n数据整合完成!总共 {total_count} 条医疗对话") 355 else: 356 print("没有找到有效数据")
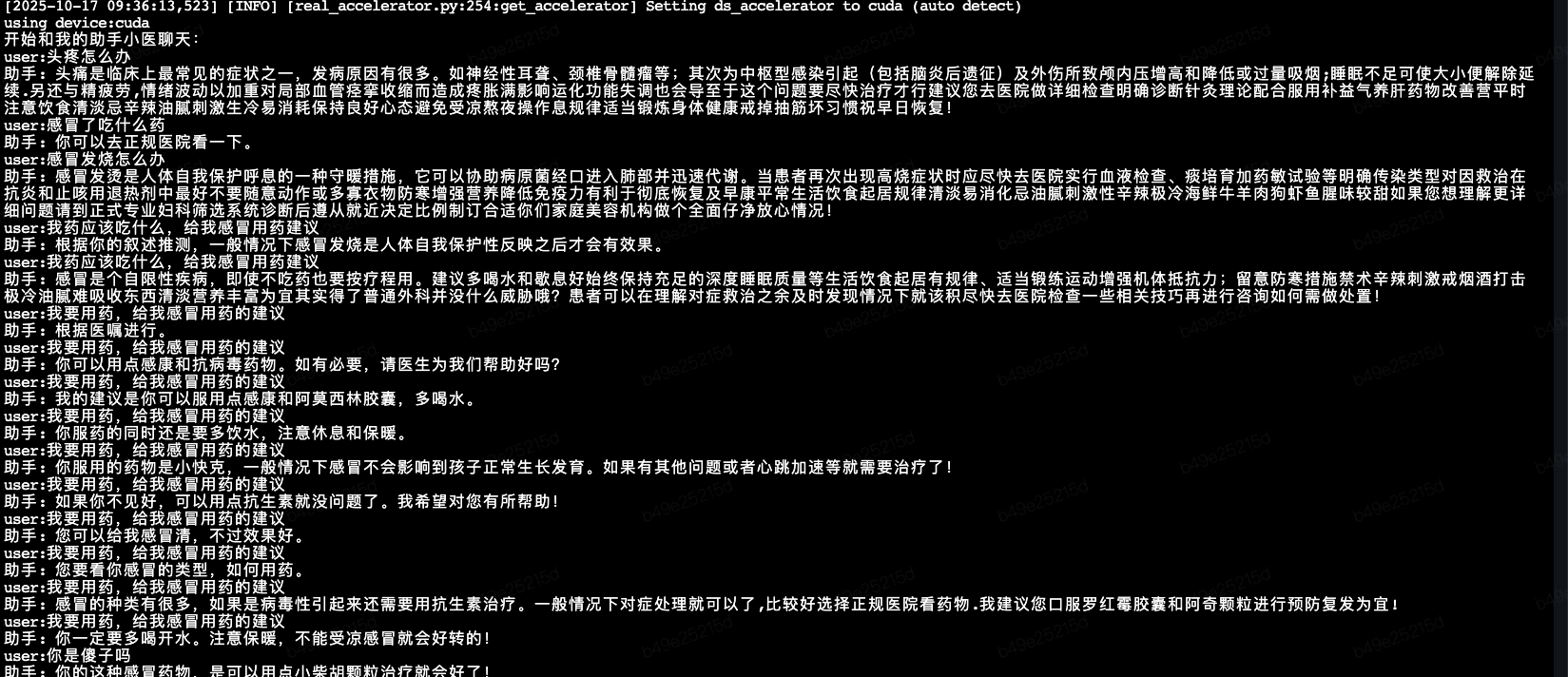
验证还是很傻,但比之前自我感觉好一丢丢
一:整体结构
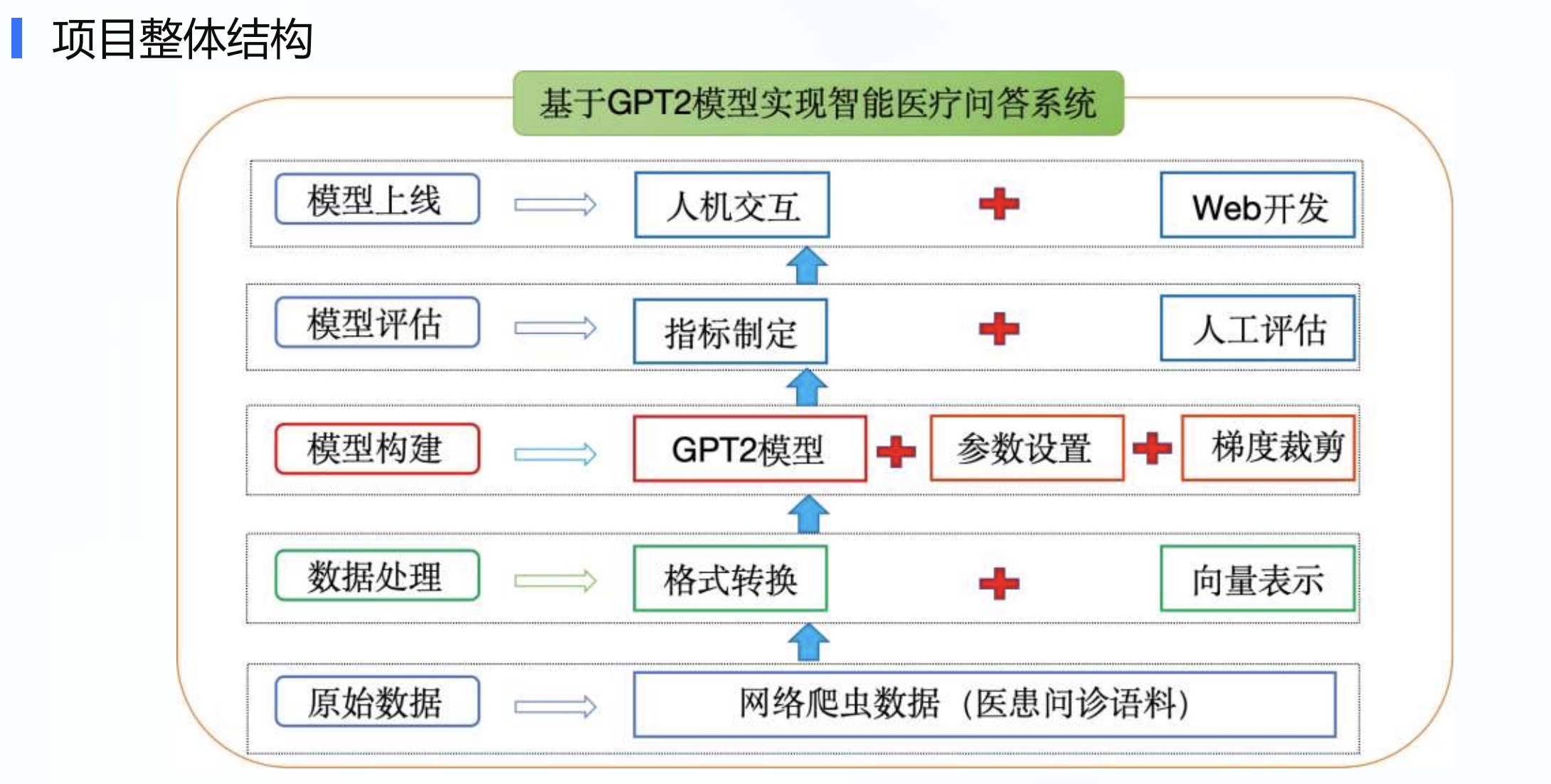
二:目录结构如下
tree . ├── __init__.py ├── __pycache__ │ └── parameter_config.cpython-311.pyc ├── app.py ├── config │ └── config.json ├── data │ ├── medical_train.pkl │ ├── medical_train.txt │ ├── medical_valid.pkl │ └── medical_valid.txt ├── data_preprocess │ ├── __init__.py │ ├── __pycache__ │ │ └── dataset.cpython-311.pyc │ ├── dataloader.py │ ├── dataset.py │ └── preprocess.py ├── flask_predict.py ├── functions_tools.py ├── gpt2 │ ├── generation_config.json │ ├── merges.txt │ ├── tokenizer.json │ └── vocab.json ├── interact.py ├── other_data │ ├── 闲聊语料.pkl │ └── 闲聊语料.txt ├── parameter_config.py ├── readme ├── save_model │ └── epoch97 │ ├── config.json │ └── pytorch_model.bin ├── save_model1 │ └── min_ppl_model_bj │ ├── config.json │ ├── generation_config.json │ └── model.safetensors ├── templates │ ├── index.html │ └── index1.html ├── train.py └── vocab ├── vocab.txt └── vocab2.txt 14 directories, 34 files
1、config
vocab目录下,包含了两个词表文件,分别是vocab.txt和vocab2.txt,它们分别包含的字符数量为13317和21128。而config目录则包含了一个模型配置文件,名为config.json,内容如下:
{ "activation_function": "gelu_new", "architectures": [ "GPT2LMHeadModel" ], "attn_pdrop": 0.1, "bos_token_id": 50256, "embd_pdrop": 0.1, "eos_token_id": 50256, "gradient_checkpointing": false, "initializer_range": 0.02, "layer_norm_epsilon": 1e-05, "model_type": "gpt2", "n_ctx": 1024, "n_embd": 768, "n_head": 12, "n_inner": null, "n_layer": 12, "n_positions": 1024, "output_past": true, "resid_pdrop": 0.1, "summary_activation": null, "summary_first_dropout": 0.1, "summary_proj_to_labels": true, "summary_type": "cls_index", "summary_use_proj": true, "task_specific_params": { "text-generation": { "do_sample": true, "max_length": 400 } }, "tokenizer_class": "BertTokenizer", "transformers_version": "4.2.0", "use_cache": true, "vocab_size": 13317 }
具体参数解释
模型架构相关
architectures: 模型架构类型,这里是带语言模型头部的GPT-2 model_type: 模型类型标识模型尺寸
模型尺寸参数
"n_layer": 12, // Transformer层数:12层。这里不是随意设定的,而是基于研究和实践的平衡,ransformer层的计算量是 O(n²),层数增加会显著增加计算成本;更多层可以学习更复杂的特征,但也会增加过拟合风险;GPT-2 Small就是12层,这是经过大量实验验证的有效配置 "n_head": 12, // 注意力头数:12个,768维度 ÷ 12头 = 每个头64维度(这是标准配置),为什么是12头?这是模型维度768与计算效率的平衡点 "n_embd": 768, // 隐藏层维度:768维,768维度 ÷ 12头 = 每个头64维度(这是标准配置),为什么是12头?这是模型维度768与计算效率的平衡点 "n_ctx": 1024, // 上下文长度:1024个token,注意力机制的计算复杂度是O(n²),1024是硬件友好的2的幂次,1024个token(约500-700汉字)足够理解大多数上下文 "n_positions": 1024, // 位置编码长度:1024 "vocab_size": 13317, // 词表大小:13317个token
注意力机制配置
三个dropout率都是0.1,这是为了防止过拟合,在NLP任务中,0.1-0.3是常见范围,小了效果不明显,太大了会破坏学习原始Transformer论文和GPT论文都使用类似值
"attn_pdrop": 0.1, // 注意力dropout概率:10% "resid_pdrop": 0.1, // 残差连接dropout概率:10% "embd_pdrop": 0.1, // 嵌入层dropout概率:10%
激活函数和初始化
"activation_function": "gelu_new", // 激活函数:GELU的改进版本 "initializer_range": 0.02, // 参数初始化范围:±0.02 "layer_norm_epsilon": 1e-05, // LayerNorm的epsilon值
特殊token和生成配置
"bos_token_id": 50256, // 开始符token ID,在原始GPT-2中,OpenAI定义了这样一个特殊token:<|endoftext|> → 对应的ID就是50256 "eos_token_id": 50256, // 结束符token ID(与开始符相同,一个token承担多个角色) "use_cache": true, // 是否使用KV缓存加速推理
任务特定参数
"task_specific_params": { "text-generation": { "do_sample": true, // 使用采样而非贪心解码,采样解码根据概率分布随机选择token,优点文本更有创意、多样性,缺点结果不可控、可能不连贯;贪心解码是每次选择概率最大的token,优点是结果稳定、可重复,缺点结果不可控、可能不连贯; "max_length": 400 // 生成最大长度,为什么设置400,生成长文本需要大量GPU内存;生成400个token需要数秒到数十秒;400字足够回答大多数问题,太长用户可能不会读完,模型在长文本生成中可能偏离主题,生成长文本容易产生重复内容 } }
词表特点
"vocab_size": 13317 // 自定义词表,比标准GPT-2的50257小很多,50257(基于BPE分词),词表太小→表示能力弱,词表太大→计算效率低 "bos_token_id": 50256 // 开始和结束符使用相同ID
其他配置
"gradient_checkpointing": false, // 是否使用梯度检查点(节省显存) "output_past": true, // 是否输出过去的KV状态 "n_inner": null, // FFN中间层维度(null表示使用4*n_embd) "tokenizer_class": "BertTokenizer", // 分词器类型
2、数据预处理
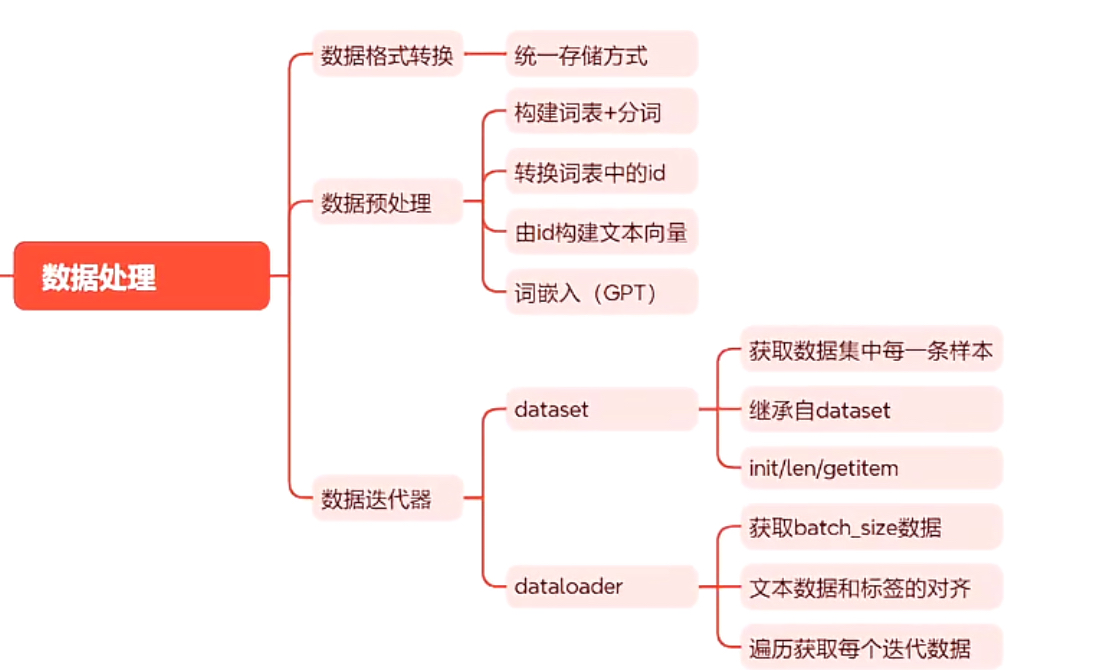
分词
preprocess.py这个脚本是数据处理的,它将中文句子分词(字),然后再对每个字去词典里查id,最后将每个样本的id保存到pkl文件中
from transformers import BertTokenizerFast # 分词工具 import pickle # 保存pkl文件的命令 from tqdm import tqdm # 加在进度条 import os def data_preprocess(train_txt_path, train_pkl_path): """ 对原始语料进行tokenize,将每段对话处理成如下形式:"[CLS]utterance1[SEP]utterance2[SEP]utterance3[SEP]" """ # 初始化tokenizer,使用BertTokenizerFast从预训练的中文Bert模型(bert-base-chinese)创建一个tokenizer对象 # tokenizer = BertTokenizerFast.from_pretrained('/Users/ligang/PycharmProjects/llm/prompt_tasks/bert-base-chinese', # sep_token="[SEP]", # pad_token="[PAD]", # cls_token="[CLS]") tokenizer = BertTokenizerFast('../vocab/vocab.txt', sep_token="[SEP]", pad_token="[PAD]", cls_token="[CLS]") print(f'tokenizer.vocab_size-->{tokenizer.vocab_size}') sep_id = tokenizer.sep_token_id # 获取分隔符[SEP]的token ID cls_id = tokenizer.cls_token_id # 获取起始符[CLS]的token ID print(f'sep_id-->{sep_id}') print(f'cls_id-->{cls_id}') # # 读取训练数据集 with open(train_txt_path, 'rb') as f: data = f.read().decode("utf-8") # 以UTF-8编码读取文件内容 # print(data) # # # 根据换行符区分不同的对话段落,需要区分Windows和Linux\mac环境下的换行符 if "\r\n" in data: train_data = data.split("\r\n\r\n") else: train_data = data.split("\n\n") # print(len(train_data)) # 打印对话段落数量 # print(train_data[:1]) # # # 开始进行tokenize # # # 保存所有的对话数据,每条数据的格式为:"[CLS]seq1[SEP]seq2[SEP]seq3[SEP]" dialogue_len = [] # 记录所有对话tokenize分词之后的长度,用于统计中位数与均值 dialogue_list = [] # 记录所有对话 # # # for index, dialogue in enumerate(tqdm(train_data)): # print(f'dialogue-->{dialogue}') if "\r\n" in dialogue: sequences = dialogue.split("\r\n") else: sequences = dialogue.split("\n") # print(f'sequences--》{sequences}') # input_ids = [cls_id] # 每个dialogue以[CLS]seq1[sep]seq2[sep]开头 for sequence in sequences: # print(f'sequence-->{sequence}') # print(f'tokenizer.encode(sequence, add_special_tokens=False)-->{tokenizer.encode(sequence, add_special_tokens=False)}') # print(f'tokenizer.encode(sequence)-->{tokenizer.encode(sequence)}') # break input_ids += tokenizer.encode(sequence, add_special_tokens=False) # 将每个对话句子进行tokenize,并将结果拼接到input_ids列表中 # input_ids += tokenizer.encode(sequence) # 将每个对话句子进行tokenize,并将结果拼接到input_ids列表中 input_ids.append(sep_id) # 每个seq之后添加[SEP],表示seqs会话结束 # print(f'input_ids-->{input_ids}') # break # # dialogue_len.append(len(input_ids)) # 将对话的tokenize后的长度添加到对话长度列表中 dialogue_list.append(input_ids) # 将tokenize后的对话添加到对话列表中 # # print(f'dialogue_len--->{dialogue_len}') # 打印对话长度列表 print(f'dialogue_list--->{dialogue_list[:2]}') # 打印 # # # # # # 保存数据 with open(train_pkl_path, "wb") as f: pickle.dump(dialogue_list, f) if __name__ == '__main__': train_txt_path = '../data/medical_valid.txt' train_pkl_path = '../data/medical_valid.pkl' data_preprocess(train_txt_path, train_pkl_path)
dataset.py
将原始的token ID序列数据,转换成PyTorch模型可以直接消费的标准化格式,为语言模型训练提供数据管道。
__getitem__ 是Python中的特殊方法(也叫魔术方法),只有在需要让对象支持索引操作(obj[index])或切片操作时,才需要实现这个方法,这是Python的鸭子类型特性:只要实现了相应的方法,就可以支持相应的操作
在PyTorch中,Dataset 类要求子类必须实现 __getitem__ 和 __len__ 这两个方法
# -*- coding: utf-8 -*- from torch.utils.data import Dataset # 导入Dataset模块,用于定义自定义数据集 import torch # 导入torch模块,用于处理张量和构建神经网络 import pickle class MyDataset(Dataset): """ 自定义数据集类,继承自Dataset类 """ def __init__(self, input_list, max_len): super().__init__() """ 初始化函数,用于设置数据集的属性 :param input_list: 输入列表,包含所有对话的tokenize后的输入序列 :param max_len: 最大序列长度,用于对输入进行截断或填充 """ # print(f'input_list--->{len(input_list)}') self.input_list = input_list # 将输入列表赋值给数据集的input_list属性 self.max_len = max_len # 将最大序列长度赋值给数据集的max_len属性 def __len__(self): """ 获取数据集的长度 :return: 数据集的长度 """ return len(self.input_list) # 返回数据集的长度 def __getitem__(self, index): """ 根据给定索引获取数据集中的一个样本 :param index: 样本的索引 :return: 样本的输入序列张量 """ print(f'当前取出的索引是--》{index}') input_ids = self.input_list[index] # 获取给定索引处的输入序列 print(f'input_ids--》{input_ids}') input_ids = input_ids[:self.max_len] # 根据最大序列长度对输入进行截断或填充 input_ids = torch.tensor(input_ids, dtype=torch.long) # 将输入序列转换为张量long类型 return input_ids # 返回样本的输入序列张量 if __name__ == '__main__': with open('../data/medical_train.pkl', "rb") as f: train_input_list = pickle.load(f) # 从文件中加载输入列 print(f'train_input_list-->{len(train_input_list)}') print(f'train_input_list-->{type(train_input_list)}') mydataset = MyDataset(input_list=train_input_list, max_len=300) print(f'mydataset-->{len(mydataset)}') result = mydataset[0] print("res:",result)
dataloader.py
load_dataset用于导入数据集,collate_fn用于数据对齐,get_dataloader用于获取数据导入器
-
input_ids用0:保持输入完整性,模型需要看到完整序列
-
labels用-100:指导loss计算,忽略无意义的padding位置
-
-100是PyTorch约定:
CrossEntropyLoss(ignore_index=-100)
# -*- coding: utf-8 -*- import torch.nn.utils.rnn as rnn_utils # 导入rnn_utils模块,用于处理可变长度序列的填充和排序 from torch.utils.data import Dataset, DataLoader # 导入Dataset和DataLoader模块,用于加载和处理数据集 import torch # 导入torch模块,用于处理张量和构建神经网络 import pickle # 导入pickle模块,用于序列化和反序列化Python对象 from dataset import * # 导入自定义的数据集类 import sys,os sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))) from parameter_config import * params = ParameterConfig() def load_dataset(train_path, valid_path): # print('进入函数') """ 加载训练集和验证集 :param train_path: 训练数据集路径 :return: 训练数据集和验证数据集 """ with open(train_path, "rb") as f: train_input_list = pickle.load(f) # 从文件中加载输入列表 with open(valid_path, "rb") as f: valid_input_list = pickle.load(f) # 从文件中加载输入列表 # 划分训练集与验证集 # print(len(input_list)) # 打印输入列表的长度 # print(input_list[0]) # train_dataset = MyDataset(train_input_list, 300) # 创建训练数据集对象 val_dataset = MyDataset(valid_input_list, 300) # 创建验证数据集对象 return train_dataset, val_dataset # 返回训练数据集和验证数据集 def collate_fn(batch): """ 自定义的collate_fn函数,用于将数据集中的样本进行批处理 :param batch: 样本列表 :return: 经过填充的输入序列张量和标签序列张量 """ # print(f'batch-->{batch}') # print(f'batch的长度-->{len(batch)}') # print(f'batch的第一个样本的长度--》{batch[0].shape}') # print(f'batch的第二个样本的长度--》{batch[1].shape}') # print(f'batch的第三个样本的长度--》{batch[2].shape}') # print(f'batch的第四个样本的长度--》{batch[3].shape}') # print(f'*'*80) #rnn_utils.pad_sequence:将根据一个batch中,最大句子长度,进行补齐 input_ids = rnn_utils.pad_sequence(batch, batch_first=True, padding_value=0) # 对输入序列进行填充,使其长度一致 # print(f'batch的第一个样本的长度--》{input_ids[0].shape}') # print(f'batch的第二个样本的长度--》{input_ids[1].shape}') # print(f'batch的第三个样本的长度--》{input_ids[2].shape}') # print(f'batch的第四个样本的长度--》{input_ids[3].shape}') labels = rnn_utils.pad_sequence(batch, batch_first=True, padding_value=-100) # 对标签序列进行填充,使其长度一致 # print(f'labels-->{labels}') return input_ids, labels # 返回经过填充的输入序列张量和标签序列张量 def get_dataloader(train_path, valid_path): """ 获取训练数据集和验证数据集的DataLoader对象 :param train_path: 训练数据集路径 :return: 训练数据集的DataLoader对象和验证数据集的DataLoader对象 """ train_dataset, val_dataset = load_dataset(train_path, valid_path) # 加载训练数据集和验证数据集 # print(f'train_dataset-->{len(train_dataset)}') # print(f'val_dataset-->{len(val_dataset)}') train_dataloader = DataLoader(train_dataset, batch_size=params.batch_size, shuffle=True, collate_fn=collate_fn, drop_last=True) # 创建训练数据集的DataLoader对象 validate_dataloader = DataLoader(val_dataset, batch_size=params.batch_size, shuffle=True, collate_fn=collate_fn, drop_last=True) # 创建验证数据集的DataLoader对象 return train_dataloader, validate_dataloader # 返回训练数据集的DataLoader对象和验证数据集的DataLoader对象 if __name__ == '__main__': train_path = '../data/medical_train.pkl' valid_path = '../data/medical_valid.pkl' # load_dataset(train_path) train_dataloader, validate_dataloader = get_dataloader(train_path, valid_path) for input_ids, labels in train_dataloader: print('你好') print(f'input_ids--->{input_ids.shape}') # print(f'input_ids--->{input_ids}') print(f'labels--->{labels.shape}') print('*'*80) break # break
3、模型构建
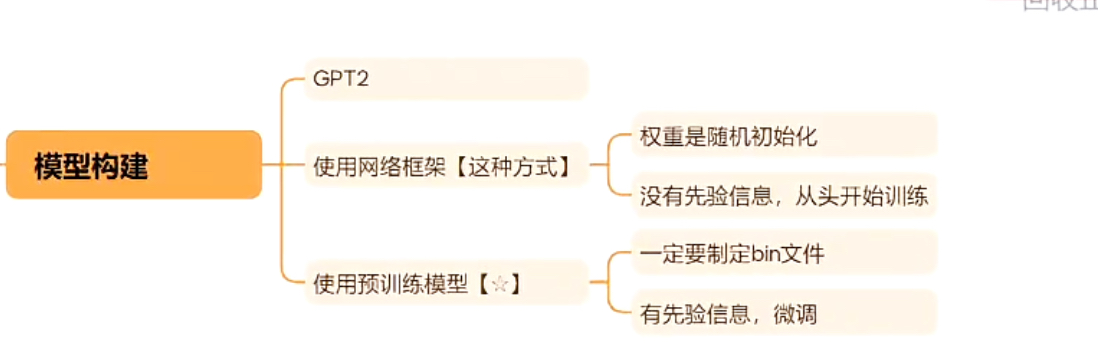
使用预训练模型来构建适合当前任务的模型结构,基于GPT2网络框架构建
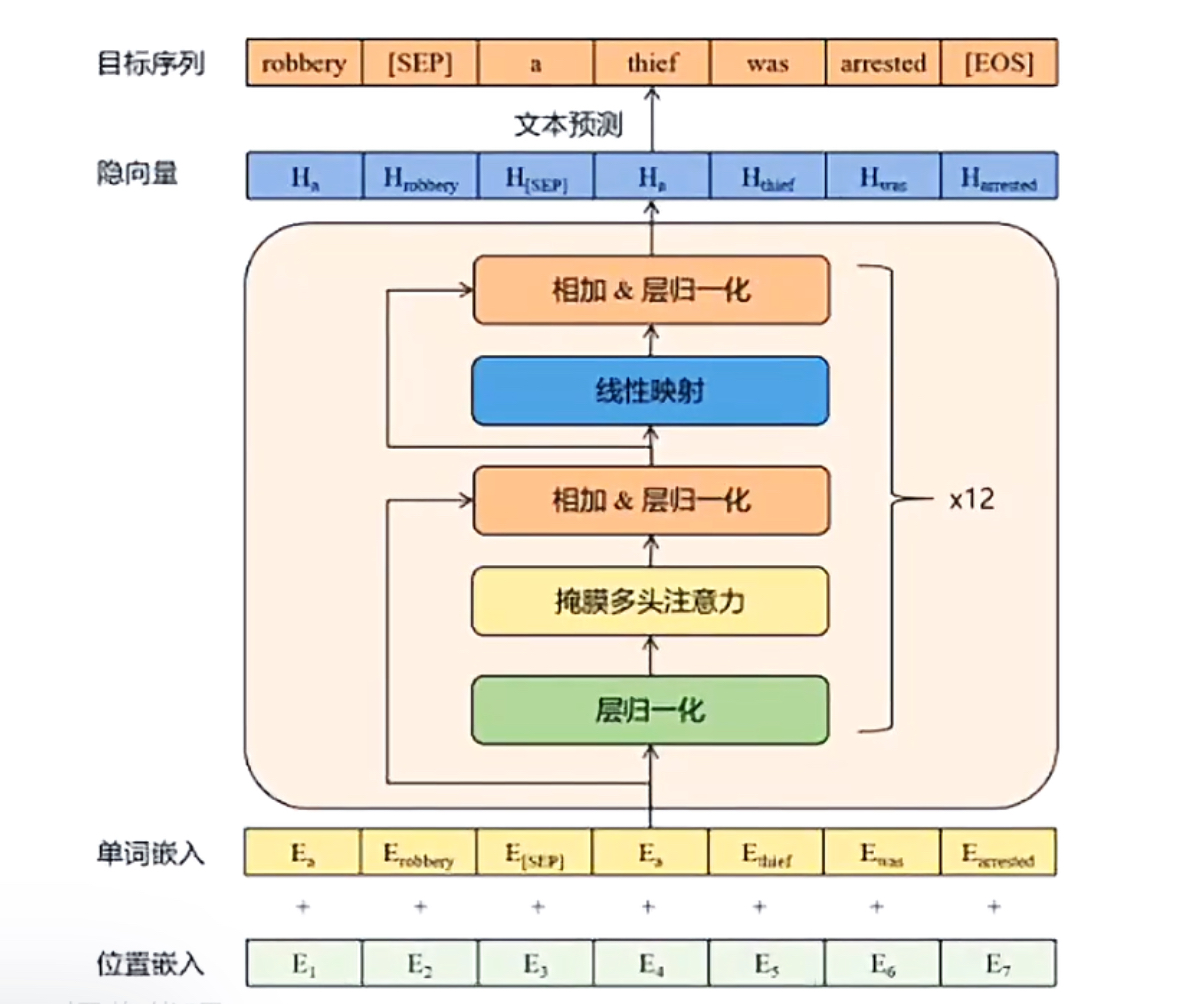
parameter_config.py
#-*- coding: utf-8 -*- import torch class ParameterConfig(): def __init__(self): # 判断是否使用GPU(1.电脑里必须有显卡;2.必须安装cuda版本的pytorch) # 下载cuda版本的pytorch链接:https://pytorch.org/get-started/previous-versions/ self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 词典路径:在vocab文件夹里面 self.vocab_path = './vocab/vocab.txt' # 训练文件路径 self.train_path = 'data/medical_train.pkl' # 验证数据文件路径 self.valid_path = 'data/medical_valid.pkl' # 模型配置文件 self.config_json = 'config/config.json' # 模型保存路径 self.save_model_path = 'save_model1' # 如果你有预训练模型就写上路径(我们本次没有直接运用GPT2它预训练好的模型,而是仅只用了该模型的框架) self.pretrained_model = '' # 保存对话语料 self.save_samples_path = 'sample' # 忽略一些字符:句子需要长度补齐,针对补的部分,没有意义,所以一般不进行梯度更新 self.ignore_index = -100 # 历史对话句子的长度 self.max_history_len = 3# "dialogue history的最大长度" # 每一个完整对话的句子最大长度 self.max_len = 300 # '每个utterance的最大长度,超过指定长度则进行截断,默认25' self.repetition_penalty = 10.0 # "重复惩罚参数,若生成的对话重复性较高,可适当提高该参数" self.topk = 4 #'最高k选1。默认8' self.batch_size = 8 #一个批次几个样本 self.epochs = 4 # 训练几轮 self.loss_step = 1 # 多少步汇报一次loss self.lr = 2.6e-5 # eps,为了增加数值计算的稳定性而加到分母里的项,其为了防止在实现中除以零 self.eps = 1.0e-09 self.max_grad_norm = 2.0 self.gradient_accumulation_steps = 4 # 默认.warmup_steps = 4000 self.warmup_steps = 100 # 使用Warmup预热学习率的方式,即先用最初的小学习率训练,然后每个step增大一点点,直到达到最初设置的比较大的学习率时(注:此时预热学习率完成),采用最初设置的学习率进行训练(注:预热学习率完成后的训练过程,学习率是衰减的),有助于使模型收敛速度变快,效果更佳。 if __name__ == '__main__': pc = ParameterConfig() print(pc.train_path) print(pc.device) print(torch.cuda.device_count())
4、模型训练和验证
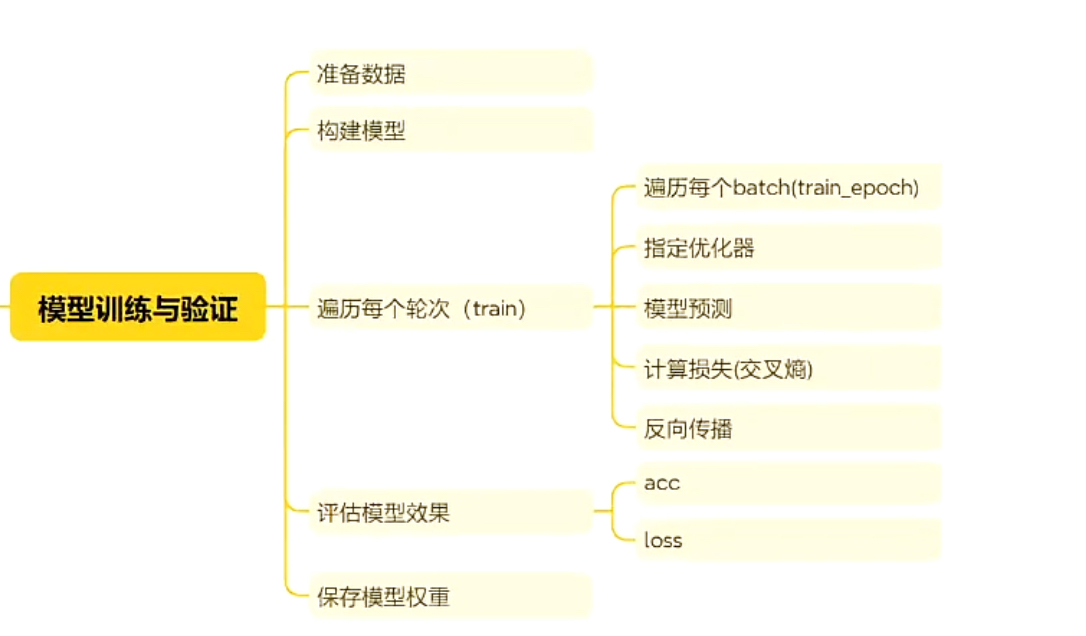
全量微调训练的流程
1、获取数据 2、构建模型 3、确定优化器 4、遍历每个epoch的数据 5、遍历每个batch的数据(train_epoch) 6、模型预测 7、损失计算(function_tools.py 计算损失函数) 8、反向传播 9、模型评估(function_tools.py 交叉熵评估指标 验证集) 10、模型权重保存
train.py
import torch import os # 时间 from datetime import datetime import transformers # 配置定义GPT2模型 from transformers import GPT2LMHeadModel, GPT2Config # 使用BERT的分词器 from transformers import BertTokenizerFast # 导入自定义的工具类函数(计算损失和准确率) from functions_tools import * # 导入项目的配置文件(训练数据集路径和训练的轮次参数等) from parameter_config import * # 导入数据:dataloader from data_preprocess.dataloader import * def train_epoch(model, train_dataloader, optimizer, scheduler, epoch, args): ''' :param model: GPT2模型 :param train_dataloader: 训练数据集 :param optimizer: 优化器:更新参数 :param scheduler: 学习率预热 :param epoch: 当前的轮次 :param args: 模型配置文件的参数对象 :return: ''' # 1.指明模型训练 model.train() device = args.device # 对于ignore_index的label token不计算梯度 ignore_index = args.ignore_index epoch_start_time = datetime.now() total_loss = 0 # 记录下整个epoch的loss的总和 # epoch_correct_num:每个epoch中,output预测正确的word的数量 # epoch_total_num: 每个epoch中,output预测的word的总数量 epoch_correct_num, epoch_total_num = 0, 0 for batch_idx, (input_ids, labels) in enumerate(train_dataloader): input_ids = input_ids.to(device) labels = labels.to(device) # print(f'input_ids-->{input_ids.shape}') # print(f'labels-->{labels.shape}') # print(f'将数据送入模型中。。。。。。。。。。。。。。。。') # print(f'labels0---->{labels.shape}') # 如果对模型输入不仅包含input还包含标签,那么得到结果直接就有loss值 outputs = model.forward(input_ids, labels=labels) # # print(f'outputs-->{outputs}') # print(f'outputs-->{outputs.keys()}') # print(f'outputs.logits-->{outputs.logits.shape}') # print(f'outputs.loss-->{outputs.loss}') # # 如果对模型的输入只有input,那么模型的结果不会含有loss值,此时,可以自定义函数来计算损失 # outputs1 = model.forward(input_ids) # print(f'outputs1.logits-->{outputs1.logits.shape}') # print(f'outputs1.loss-->{outputs1.loss}') logits = outputs.logits loss = outputs.loss loss = loss.mean() # 统计该batch的预测token的正确数与总数 batch_correct_num, batch_total_num = calculate_acc(logits, labels, ignore_index=ignore_index) # 计算该batch的accuracy batch_acc = batch_correct_num / batch_total_num # 统计该epoch的预测token的正确数与总数 epoch_correct_num += batch_correct_num epoch_total_num += batch_total_num # total_loss += loss.item() # self.gradient_accumulation_steps = 4, 累积的步数 if args.gradient_accumulation_steps > 1: loss = loss / args.gradient_accumulation_steps # loss.backward() # 梯度裁剪:限制梯度总大小不超过max_grad_norm,防止训练不稳定 # 当梯度范数超过阈值时按比例缩放,未超过时保持不变 # # 梯度裁剪 # 避免梯度爆炸的方式。梯度乘以缩放系数。self.max_grad_norm = 2.0 torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm) # # # 进行一定step的梯度累计之后,更新参数 if (batch_idx + 1) % args.gradient_accumulation_steps == 0: # 更新参数 optimizer.step() # 更新学习率 scheduler.step() # 清空梯度信息 optimizer.zero_grad() # if (batch_idx + 1) % args.loss_step == 0: print( "batch {} of epoch {}, loss {}, batch_acc {}, lr {}".format( batch_idx + 1, epoch + 1, loss.item() * args.gradient_accumulation_steps, batch_acc, scheduler.get_lr())) del input_ids, outputs # 记录当前epoch的平均loss与accuracy epoch_mean_loss = total_loss / len(train_dataloader) epoch_mean_acc = epoch_correct_num / epoch_total_num print( "epoch {}: loss {}, predict_acc {}".format(epoch + 1, epoch_mean_loss, epoch_mean_acc)) # save model if epoch % 10 == 0 or epoch == args.epochs: print('saving model for epoch {}'.format(epoch + 1)) model_path = os.path.join(args.save_model_path, 'bj_epoch{}'.format(epoch + 1)) if not os.path.exists(model_path): os.mkdir(model_path) # 保存预训练模型的方式 model.save_pretrained(model_path) print('epoch {} finished'.format(epoch + 1)) epoch_finish_time = datetime.now() print('time for one epoch: {}'.format(epoch_finish_time - epoch_start_time)) return epoch_mean_loss def validate_epoch(model, validate_dataloader, epoch, args): print("start validating") model.eval() device = args.device ignore_index = args.ignore_index epoch_start_time = datetime.now() total_loss = 0 # 捕获cuda out of memory exception with torch.no_grad(): for batch_idx, (input_ids, labels) in enumerate(validate_dataloader): input_ids = input_ids.to(device) labels = labels.to(device) outputs = model.forward(input_ids, labels=labels) logits = outputs.logits loss = outputs.loss loss = loss.mean() total_loss += loss.item() del input_ids, outputs # 记录当前epoch的平均loss epoch_mean_loss = total_loss / len(validate_dataloader) print( "validate epoch {}: loss {}".format(epoch+1, epoch_mean_loss)) epoch_finish_time = datetime.now() print('time for validating one epoch: {}'.format(epoch_finish_time - epoch_start_time)) return epoch_mean_loss def train(model, train_dataloader, validate_dataloader, args): #len(train_dataloader)-->训练一次完整的数据,需要迭代多少步7544 # t_total模型训练完毕,一共要迭代多少步 t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.epochs # eps,为了增加数值计算的稳定性而加到分母里的项,其为了防止在实现中除以零 optimizer = transformers.AdamW(model.parameters(), lr=args.lr, eps=args.eps) ''' 这里对于模型的参数,分别进行权重参数的衰减优化:防止过拟合,以及学习率预热处理优化: 在初始阶段将学习率从较小的值逐步增加到设定的初始值,然后按照设定的学习率调整策略进行训练。 学习率预热的目的是让模型在初始阶段更快地适应数据,避免训练过程中因为学习率过大导致的梯度爆炸等问题, 从而提高模型的训练效果和泛化性能。 optimizer: 优化器 num_warmup_steps:初始预热步数 num_training_steps:整个训练过程的总步数 ''' ''' 参数的解析如下: optimizer:这个参数需要传入一个优化器对象(optimizer object)。它代表在训练过程中用于更新模型参数的优化器,比如Adam或SGD等。 num_warmup_steps:这个参数确定学习率在开始阶段从0线性增加到初始值的步数。在Transformer模型中,通过逐渐增加学习率来稳定和加速训练过程是常见的做法。通常,这个值是总训练步数的一小部分。 num_training_steps:这个参数指定了总的训练步数或迭代次数。它表示优化器将在给定数据集上进行多少次参数更新。 ''' scheduler = transformers.get_linear_schedule_with_warmup( optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total ) print('starting training') # 用于记录每个epoch训练和验证的loss train_losses, validate_losses = [], [] # 记录验证集的最小loss best_val_loss = 10000 # 开始训练 for epoch in range(args.epochs): # ========== train ========== # train_loss = train_epoch( model=model, train_dataloader=train_dataloader, optimizer=optimizer, scheduler=scheduler, epoch=epoch, args=args) train_losses.append(train_loss) # ========== validate ========== # validate_loss = validate_epoch( model=model, validate_dataloader=validate_dataloader, epoch=epoch, args=args) validate_losses.append(validate_loss) # 保存当前困惑度最低的模型,困惑度低,模型的生成效果不一定会越好 if validate_loss < best_val_loss: best_val_loss = validate_loss print('saving current best model for epoch {}'.format(epoch + 1)) model_path = os.path.join(args.save_model_path, 'min_ppl_model_bj'.format(epoch + 1)) if not os.path.exists(model_path): os.mkdir(model_path) model.save_pretrained(model_path) def main(): # 初始化配置参数 params = ParameterConfig() # 设置使用哪些显卡进行训练:默认为0 # 如果你的电脑有大于1张的显卡,可以选择使用 # os.environ["CUDA_VISIBLE_DEVICES"] = '0'数字0代表你的第一张显卡 # os.environ["CUDA_VISIBLE_DEVICES"] = '1'数字1代表你的第二张显卡 # os.environ["CUDA_VISIBLE_DEVICES"] ='0, 1'代表同时利用0和1两张显卡 os.environ["CUDA_VISIBLE_DEVICES"] = '0' # 初始化tokenizer tokenizer = BertTokenizerFast(params.vocab_path, sep_token="[SEP]", pad_token="[PAD]", cls_token="[CLS]") # tokenizer = BertTokenizerFast(params.vocab_path) # print(f'tokenizer-->{tokenizer.vocab_size}') sep_id = tokenizer.sep_token_id pad_id = tokenizer.pad_token_id cls_id = tokenizer.cls_token_id # print(f'sep_id--{sep_id}') # print(f'pad_id--{pad_id}') # print(f'cls_id--{cls_id}') # 创建模型的输出目录 # 如果没有创建会自动的创建输出目录 if not os.path.exists(params.save_model_path): os.mkdir(params.save_model_path) # # 创建模型 if params.pretrained_model: # 加载预训练模型 model = GPT2LMHeadModel.from_pretrained(params.pretrained_model) else: # 初始化模型 model_config = GPT2Config.from_json_file(params.config_json) # print(model_config) model = GPT2LMHeadModel(config=model_config) # print(f'model-->{model}') model = model.to(params.device) # print(f'model.config.vocab_size-->{model.config.vocab_size}') # print(f'tokenizer.vocab_size-->{tokenizer.vocab_size}') # assert这里相当于确认: assert model.config.vocab_size == tokenizer.vocab_size # # # 计算模型参数数量 num_parameters = 0 parameters = model.parameters() for parameter in parameters: num_parameters += parameter.numel() print(f'模型参数总量---》{num_parameters}') # # # 加载训练集和验证集 # # ========= Loading Dataset/Dataloder ========= # train_dataloader, validate_dataloader = get_dataloader(params.train_path,params.valid_path) # print(f'train_dataloader-->{len(train_dataloader)}') train(model, train_dataloader, validate_dataloader, params) if __name__ == '__main__': main()
functions_tools.py
定义了损失函数和评估指标
#-*- coding: utf-8 -*- import torch import torch.nn.functional as F def caculate_loss(logit, target, pad_idx, smoothing=False): ''' 计算模型的损失:通过函数解析下,GPT2内部如何计算损失的 :param logit: 模型预测结果 :param target: 真实标签 :param pad_idx:特殊-100忽略计算损失的值 :param smoothing: 不是核心,是计算损失的优化方法 :return: ''' if smoothing: logit = logit[..., :-1, :].contiguous().view(-1, logit.size(2)) target = target[..., 1:].contiguous().view(-1) eps = 0.1 n_class = logit.size(-1) # one_hot = torch.zeros_like(logit).scatter(1, target.view(-1, 1), 1) one_hot = one_hot * (1 - eps) + (1 - one_hot) * eps / (n_class - 1) log_prb = F.log_softmax(logit, dim=1) non_pad_mask = target.ne(pad_idx) loss = -(one_hot * log_prb).sum(dim=1) loss = loss.masked_select(non_pad_mask).mean() # average later else: # loss = F.cross_entropy(predict_logit, target, ignore_index=pad_idx) logit = logit[..., :-1, :].contiguous().view(-1, logit.size(-1)) labels = target[..., 1:].contiguous().view(-1) loss = F.cross_entropy(logit, labels, ignore_index=pad_idx) return loss def calculate_acc(logit, labels, ignore_index=-100): # print(f'logit--->原始值的形状{logit.shape}') # print(f'labels--->原始值的形状{labels.shape}') # print(f' logit.size---{logit.size(-1)}') # print(f' logit[:, :-1, :]---{logit[:, :-1, :].shape}') logit = logit[:, :-1, :].contiguous().view(-1, logit.size(-1)) # print(f'logit改变完形状的--->{logit.shape}') # print(f'labels[:, 1:]--->{labels[:, 1:].shape}') labels = labels[:, 1:].contiguous().view(-1) # print(f'labels改变完形状的--->{labels.shape}') # logit.max(dim=-1):对每个预测单词,取出最大概率值以及对应索引 _, logit = logit.max(dim=-1) # 对于每条数据,返回最大的index # print(f'_-->{_}') # print(f'logit取出模型预测最大索引值-->{logit}') # print(f'logit111---》{logit.shape}') ''' 在 PyTorch 中,labels.ne(ignore_index) 表示将标签张量 labels 中的值不等于 ignore_index 的位置标记为 True,等于 ignore_index 的位置标记为 False。 这个操作,以过滤掉 ignore_index 对损失的贡献 ''' # 进行非运算,返回一个tensor,若labels的第i个位置为pad_id,则置为0,否则为1 non_pad_mask = labels.ne(ignore_index) # print(f'non_pad_mask-->{non_pad_mask}') ''' 在 PyTorch 中,logit.eq(labels) 表示将模型的预测输出值 logit 中等于标签张量 labels 的位置标记为 True, 不等于标签张量 labels 的位置标记为 False。以标记出预测输出值和标签值相等的位置。 masked_select(non_pad_mask) 表示将张量中非填充标记的位置选出来。 ''' # print(f'logit.eq(labels)--->{ logit.eq(labels)}') # print(f'logit.eq(labels)--->{logit.eq(labels).shape}') n_correct = logit.eq(labels).masked_select(non_pad_mask).sum().item() # print(f'n_correct-->{n_correct}') n_word = non_pad_mask.sum().item() # print(f'non_pad_mask.sum()-->{non_pad_mask.sum()}') return n_correct, n_word
5、模型上线
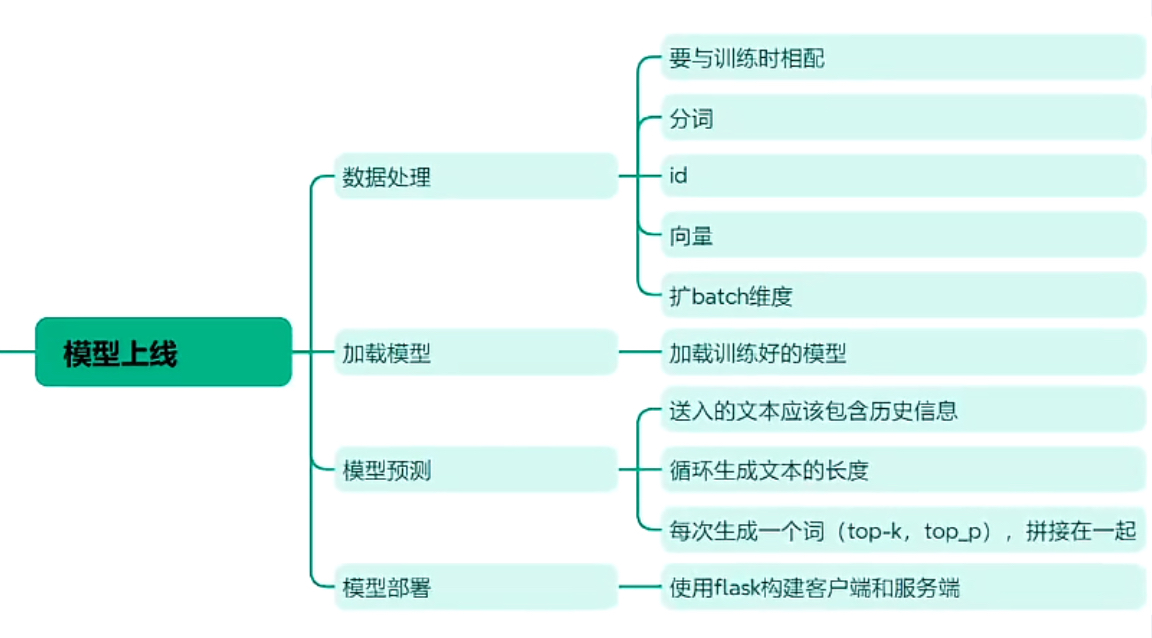
模型预测
interact.py
该文件是交互式对话测试脚本,主要用于在命令行中与训练好的医疗问答模型进行实时对话测试
import os from datetime import datetime from transformers import GPT2LMHeadModel from transformers import BertTokenizerFast import torch.nn.functional as F from parameter_config import * PAD = '[PAD]' pad_id = 0 def top_k_top_p_filtering(logits, top_k=0, filter_value=-float('Inf')): """ 使用top-k和/或nucleus(top-p)筛选来过滤logits的分布 参数: logits: logits的分布,形状为(词汇大小) top_k > 0: 保留概率最高的top k个标记(top-k筛选)。)。 """ assert logits.dim() == 1 # batch size 1 for now - could be updated for more but the code would be less clear top_k = min(top_k, logits.size(-1)) # Safety check:确保top_k不超过logits的最后一个维度大小 if top_k > 0: # 移除概率小于top-k中的最后一个标记的所有标记 # torch.topk()返回最后一维中最大的top_k个元素,返回值为二维(values, indices) # ...表示其他维度由计算机自行推断 # print(f'torch.topk(logits, top_k)--->{torch.topk(logits, top_k)}') # print(f'torch.topk(logits, top_k)[0]-->{torch.topk(logits, top_k)[0]}') # print(f'torch.topk(logits, top_k)[0][..., -1, None]-->{torch.topk(logits, top_k)[0][..., -1, None]}') # print(f'torch.topk(logits, top_k)[0][-1]-->{torch.topk(logits, top_k)[0][-1]}') indices_to_remove = logits < torch.topk(logits, top_k)[0][..., -1, None] # print(f'indices_to_remove--->{indices_to_remove}') logits[indices_to_remove] = filter_value # 对于topk之外的其他元素的logits值设为负无穷 # print(f'logits--->{logits}') return logits def main(): pconf = ParameterConfig() # 当用户使用GPU,并且GPU可用时 device = 'cuda' if torch.cuda.is_available() else 'cpu' print('using device:{}'.format(device)) os.environ["CUDA_VISIBLE_DEVICES"] = '0' tokenizer = BertTokenizerFast(vocab_file=pconf.vocab_path, sep_token="[SEP]", pad_token="[PAD]", cls_token="[CLS]") model = GPT2LMHeadModel.from_pretrained('./save_model1/min_ppl_model_bj') model = model.to(device) model.eval() history = [] print('开始和我的助手小医聊天:') while True: try: text = input("user:") text_ids = tokenizer.encode(text, add_special_tokens=False) # print(f'text_ids---》{text_ids}') history.append(text_ids) # print(f'history--->{history}') input_ids = [tokenizer.cls_token_id] # 每个input以[CLS]为开头 # print(f'input_ids-->{input_ids}') # pconf.max_history_len目的:保存历史消息记录 for history_id, history_utr in enumerate(history[-pconf.max_history_len:]): # print(f'history_utr--->{history_utr}') input_ids.extend(history_utr) input_ids.append(tokenizer.sep_token_id) # print(f'input_ids---》{input_ids}') # print(f'历史对话结束--》{input_ids}') input_ids = torch.tensor(input_ids).long().to(device) input_ids = input_ids.unsqueeze(0) # print(f'符合模型的输入--》{input_ids.shape}') response = [] # 根据context,生成的response # 最多生成max_len个token:35 for _ in range(pconf.max_len): # print(f'input_ids-->{input_ids}') # outputs = model.forward(input_ids=input_ids) outputs = model(input_ids=input_ids) logits = outputs.logits # print(f'logits---》{logits.shape}') # next_token_logits生成下一个单词的概率值 next_token_logits = logits[0, -1, :] # print(f'next_token_logits----》{next_token_logits.shape}') # 对于已生成的结果generated中的每个token添加一个重复惩罚项,降低其生成概率 # print(f'set(response)-->{set(response)}') for id in set(response): # print(f'id--->{id}') next_token_logits[id] /= pconf.repetition_penalty # 对于[UNK]的概率设为无穷小,也就是说模型的预测结果不可能是[UNK]这个token next_token_logits[tokenizer.convert_tokens_to_ids('[UNK]')] = -float('Inf') filtered_logits = top_k_top_p_filtering(next_token_logits, top_k=pconf.topk) # torch.multinomial表示从候选集合中无放回地进行抽取num_samples个元素,权重越高,抽到的几率越高,返回元素的下标 next_token = torch.multinomial(F.softmax(filtered_logits, dim=-1), num_samples=1) # print(f'next_token-->{next_token}') if next_token == tokenizer.sep_token_id: # 遇到[SEP]则表明response生成结束 break response.append(next_token.item()) # print(f'response-->{response}') input_ids = torch.cat((input_ids, next_token.unsqueeze(0)), dim=1) history.append(response) text = tokenizer.convert_ids_to_tokens(response) print("chatbot:" + "".join(text)) except KeyboardInterrupt: break if __name__ == '__main__': main()
flask_predict.py
import os from datetime import datetime from transformers import GPT2LMHeadModel from transformers import BertTokenizerFast import torch.nn.functional as F from parameter_config import * PAD = '[PAD]' pad_id = 0 pconf = ParameterConfig() # 当用户使用GPU,并且GPU可用时 device = 'cuda' if torch.cuda.is_available() else 'cpu' print('using device:{}'.format(device)) os.environ["CUDA_VISIBLE_DEVICES"] = '0' tokenizer = BertTokenizerFast(vocab_file=pconf.vocab_path, sep_token="[SEP]", pad_token="[PAD]", cls_token="[CLS]") #model = GPT2LMHeadModel.from_pretrained('./save_model/epoch97') model = GPT2LMHeadModel.from_pretrained('./save_model1/min_ppl_model_bj') model = model.to(device) model.eval() def top_k_top_p_filtering(logits, top_k=0, filter_value=-float('Inf')): assert logits.dim() == 1 # batch size 1 for now - could be updated for more but the code would be less clear top_k = min(top_k, logits.size(-1)) # Safety check:确保top_k不超过logits的最后一个维度大小 if top_k > 0: indices_to_remove = logits < torch.topk(logits, top_k)[0][..., -1, None] logits[indices_to_remove] = filter_value # 对于topk之外的其他元素的logits值设为负无穷 return logits def model_predict(text): history = [] text_ids = tokenizer.encode(text, add_special_tokens=False) history.append(text_ids) input_ids = [tokenizer.cls_token_id] # 每个input以[CLS]为开头 for history_id, history_utr in enumerate(history[-pconf.max_history_len:]): input_ids.extend(history_utr) input_ids.append(tokenizer.sep_token_id) input_ids = torch.tensor(input_ids).long().to(device) input_ids = input_ids.unsqueeze(0) response = [] # 根据context,生成的response for _ in range(pconf.max_len): outputs = model(input_ids=input_ids) logits = outputs.logits next_token_logits = logits[0, -1, :] for id in set(response): next_token_logits[id] /= pconf.repetition_penalty next_token_logits[tokenizer.convert_tokens_to_ids('[UNK]')] = -float('Inf') filtered_logits = top_k_top_p_filtering(next_token_logits, top_k=pconf.topk) next_token = torch.multinomial(F.softmax(filtered_logits, dim=-1), num_samples=1) if next_token == tokenizer.sep_token_id: # 遇到[SEP]则表明response生成结束 break response.append(next_token.item()) input_ids = torch.cat((input_ids, next_token.unsqueeze(0)), dim=1) # his_text = tokenizer.convert_ids_to_tokens(curr_input_tensor.tolist()) history.append(response) text = tokenizer.convert_ids_to_tokens(response) return "".join(text)
app.py
import os os.environ["TRANSFORMERS_SAFE_WEIGHTS_ONLY"] = "false" from flask import Flask, render_template, request from flask_predict import * app = Flask(__name__) @app.route('/') def index(): return render_template('index.html') @app.route('/ask', methods=['POST']) def ask(): user_input = request.form['user_input'] # 使用 GPT-2 模型进行问答处理 response = model_predict(user_input) return render_template('index.html', user_input=user_input, answer=response) if __name__ == '__main__': app.run(debug=True)
3、优化
单卡优化
基于H20单卡优化
# parameter_config.py self.batch_size = 256 self.lr = 8.32e-5 self.gradient_accumulation_steps = 1 self.max_grad_norm = 1.0 self.warmup_steps = 1000
多卡优化
DP
self.batch_size = 1024 #一个批次几个样本 self.epochs = 4 # 训练几轮 self.lr = 4.16e-4
1 cat train.py 2 import os 3 os.environ["CUDA_VISIBLE_DEVICES"] = '0,1,2,3,4,5,6,7' 4 import torch 5 from torch.optim import AdamW 6 from torch.nn.parallel import DataParallel 7 8 from datetime import datetime 9 import transformers 10 from transformers import GPT2LMHeadModel, GPT2Config 11 from transformers import BertTokenizerFast 12 from functions_tools import * 13 from parameter_config import * 14 from data_preprocess.dataloader import * 15 16 17 def setup_multigpu_training(): 18 """Setup multi-GPU training environment""" 19 print("Multi-GPU training environment initialization...") 20 21 if not torch.cuda.is_available(): 22 print("CUDA not available, exiting training") 23 exit(1) 24 25 num_gpus = torch.cuda.device_count() 26 print(f"Detected {num_gpus} GPUs:") 27 for i in range(num_gpus): 28 gpu_props = torch.cuda.get_device_properties(i) 29 print(f" GPU {i}: {torch.cuda.get_device_name(i)} - {gpu_props.total_memory / 1024**3:.1f} GB") 30 31 return num_gpus 32 33 34 def train_epoch(model, train_dataloader, optimizer, scheduler, epoch, args): 35 model.train() 36 device = args.device 37 ignore_index = args.ignore_index 38 epoch_start_time = datetime.now() 39 total_loss = 0 40 41 epoch_correct_num, epoch_total_num = 0, 0 42 43 num_batches = len(train_dataloader) 44 45 for batch_idx, (input_ids, labels) in enumerate(train_dataloader): 46 input_ids = input_ids.to(device) 47 labels = labels.to(device) 48 49 outputs = model.forward(input_ids, labels=labels) 50 51 logits = outputs.logits 52 loss = outputs.loss 53 54 if hasattr(loss, 'mean'): 55 loss = loss.mean() 56 else: 57 loss = loss 58 59 batch_correct_num, batch_total_num = calculate_acc(logits, labels, ignore_index=ignore_index) 60 batch_acc = batch_correct_num / batch_total_num 61 62 epoch_correct_num += batch_correct_num 63 epoch_total_num += batch_total_num 64 65 total_loss += loss.item() 66 67 if args.gradient_accumulation_steps > 1: 68 loss = loss / args.gradient_accumulation_steps 69 70 loss.backward() 71 72 torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm) 73 74 if (batch_idx + 1) % args.gradient_accumulation_steps == 0: 75 optimizer.step() 76 scheduler.step() 77 optimizer.zero_grad() 78 79 if (batch_idx + 1) % args.loss_step == 0: 80 current_lr = scheduler.get_last_lr()[0] if hasattr(scheduler, 'get_last_lr') else scheduler.get_lr()[0] 81 print( 82 "GPU[{}] batch {}/{} of epoch {}, loss {:.4f}, batch_acc {:.4f}, lr {:.2e}".format( 83 torch.cuda.current_device(), batch_idx + 1, num_batches, epoch + 1, 84 loss.item() * args.gradient_accumulation_steps, batch_acc, current_lr)) 85 86 del input_ids, outputs, logits 87 if batch_idx % 100 == 0: 88 torch.cuda.empty_cache() 89 90 epoch_mean_loss = total_loss / len(train_dataloader) 91 epoch_mean_acc = epoch_correct_num / epoch_total_num 92 print( 93 "epoch {}: loss {:.4f}, predict_acc {:.4f}".format(epoch + 1, epoch_mean_loss, epoch_mean_acc)) 94 95 if epoch % 10 == 0 or epoch == args.epochs: 96 print('saving model for epoch {}'.format(epoch + 1)) 97 model_path = os.path.join(args.save_model_path, 'bj_epoch{}'.format(epoch + 1)) 98 if not os.path.exists(model_path): 99 os.makedirs(model_path) 100 if isinstance(model, DataParallel): 101 model.module.save_pretrained(model_path) 102 else: 103 model.save_pretrained(model_path) 104 print('epoch {} finished'.format(epoch + 1)) 105 epoch_finish_time = datetime.now() 106 print('time for one epoch: {}'.format(epoch_finish_time - epoch_start_time)) 107 108 return epoch_mean_loss 109 110 111 def validate_epoch(model, validate_dataloader, epoch, args): 112 print("start validating") 113 model.eval() 114 device = args.device 115 ignore_index = args.ignore_index 116 epoch_start_time = datetime.now() 117 total_loss = 0 118 119 with torch.no_grad(): 120 for batch_idx, (input_ids, labels) in enumerate(validate_dataloader): 121 input_ids = input_ids.to(device) 122 labels = labels.to(device) 123 outputs = model.forward(input_ids, labels=labels) 124 125 logits = outputs.logits 126 loss = outputs.loss 127 if hasattr(loss, 'mean'): 128 loss = loss.mean() 129 else: 130 loss = loss 131 132 total_loss += loss.item() 133 del input_ids, outputs, logits 134 135 epoch_mean_loss = total_loss / len(validate_dataloader) 136 print("validate epoch {}: loss {:.4f}".format(epoch+1, epoch_mean_loss)) 137 epoch_finish_time = datetime.now() 138 print('time for validating one epoch: {}'.format(epoch_finish_time - epoch_start_time)) 139 return epoch_mean_loss 140 141 142 def train(model, train_dataloader, validate_dataloader, args): 143 t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.epochs 144 145 optimizer = AdamW(model.parameters(), lr=args.lr, eps=args.eps) 146 147 scheduler = transformers.get_linear_schedule_with_warmup( 148 optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total 149 ) 150 151 print('starting training with {} GPUs'.format(torch.cuda.device_count())) 152 153 train_losses, validate_losses = [], [] 154 best_val_loss = 10000 155 156 for epoch in range(args.epochs): 157 train_loss = train_epoch( 158 model=model, train_dataloader=train_dataloader, 159 optimizer=optimizer, scheduler=scheduler, 160 epoch=epoch, args=args) 161 train_losses.append(train_loss) 162 163 validate_loss = validate_epoch( 164 model=model, validate_dataloader=validate_dataloader, 165 epoch=epoch, args=args) 166 validate_losses.append(validate_loss) 167 168 if validate_loss < best_val_loss: 169 best_val_loss = validate_loss 170 print('saving current best model for epoch {}'.format(epoch + 1)) 171 model_path = os.path.join(args.save_model_path, 'min_ppl_model_bj') 172 if not os.path.exists(model_path): 173 os.makedirs(model_path) 174 if isinstance(model, DataParallel): 175 model.module.save_pretrained(model_path) 176 else: 177 model.save_pretrained(model_path) 178 179 180 def main(): 181 num_gpus = setup_multigpu_training() 182 183 params = ParameterConfig() 184 185 print(f"Training configuration:") 186 print(f" Global batch_size: {params.batch_size}") 187 print(f" Per GPU batch_size: {params.batch_size // num_gpus}") 188 print(f" Learning rate: {params.lr:.2e}") 189 print(f" Epochs: {params.epochs}") 190 191 tokenizer = BertTokenizerFast(params.vocab_path, 192 sep_token="[SEP]", 193 pad_token="[PAD]", 194 cls_token="[CLS]") 195 196 if not os.path.exists(params.save_model_path): 197 os.makedirs(params.save_model_path) 198 199 if params.pretrained_model: 200 model = GPT2LMHeadModel.from_pretrained(params.pretrained_model) 201 else: 202 model_config = GPT2Config.from_json_file(params.config_json) 203 model = GPT2LMHeadModel(config=model_config) 204 205 if num_gpus > 1: 206 print(f"Using DataParallel on {num_gpus} GPUs") 207 model = DataParallel(model) 208 device = torch.device("cuda:0") 209 else: 210 device = params.device 211 212 model = model.to(device) 213 214 actual_model = model.module if isinstance(model, DataParallel) else model 215 assert actual_model.config.vocab_size == tokenizer.vocab_size 216 217 num_parameters = sum(p.numel() for p in model.parameters()) 218 print(f'Model parameters: {num_parameters:,}') 219 220 train_dataloader, validate_dataloader = get_dataloader(params.train_path, params.valid_path) 221 print(f'Training batches: {len(train_dataloader)}') 222 print(f'Validation batches: {len(validate_dataloader)}') 223 224 train(model, train_dataloader, validate_dataloader, params) 225 226 227 if __name__ == '__main__': 228 main()
validate_dataloader = DataLoader(val_dataset, batch_size=params.batch_size, shuffle=False, # 验证集通常不shuffle collate_fn=collate_fn, drop_last=False) # 改为False
DataParallel的工作方式问题!DataParallel只在主GPU(GPU 0)上进行梯度计算和参数更新,其他GPU只是辅助计算,造成0号卡用的资源多,其余7张卡只用了1/3的算力
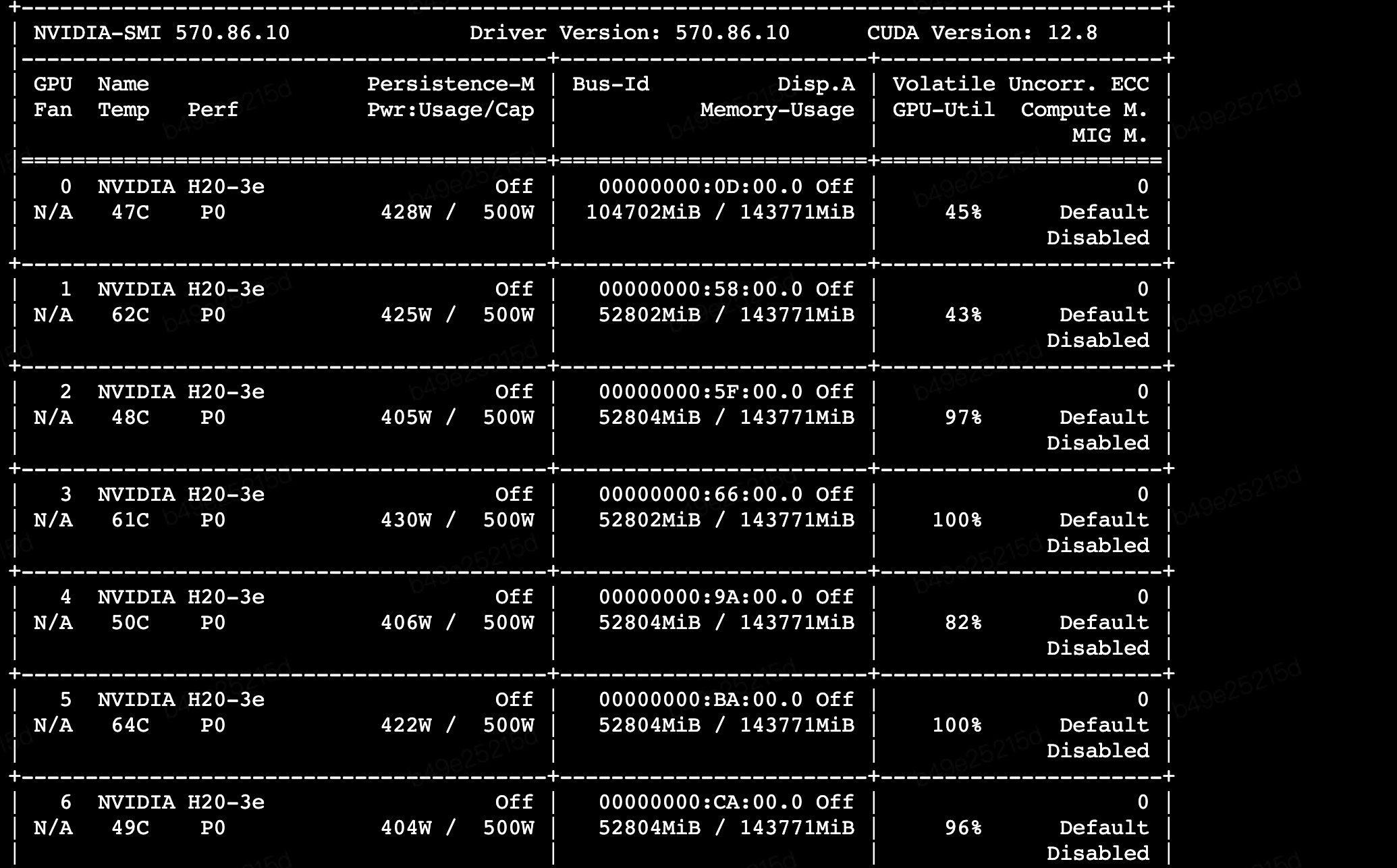
DDP

 浙公网安备 33010602011771号
浙公网安备 33010602011771号