
ds第三章学习记录
一.
栈 :LIFO top base
队列:FIFO front rear
二.
顺序栈新类型定义
typedef struct
{
SElemType data[MAXSIZE];
int top;
int size;
}Stack; //用静态数组
初始化---------> top=0 size
push---------> *s.top++=e
pop--------->e=s.data[--s.top]
typedef struct
{
SElemType *base;
SElemType *top;
int size;
}Stack; //指针 动态性强
初始化---------> 分配数组空间 top=base size
push---------> s.data[s.top++]=e
pop--------->e=*--S.top
//注意isEmpty isFull
队列
·假溢出 模运算
三.
链栈--------->链表

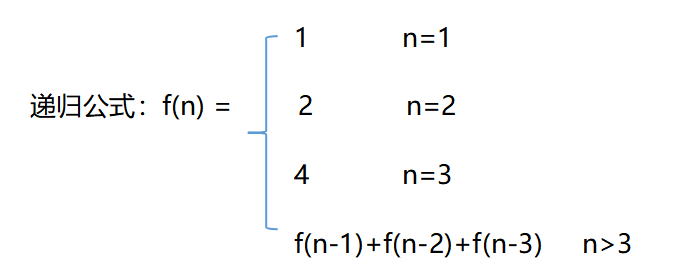
自底向上 和 自顶向下
底:小规模问题(终止条件)
顶:大规模问题(原问题)
自底向上的求解方法:由最小规模问题逐步向上求解,直至求出原问题的解。

总结:自底向上的求解过程,其实就是一个填表的过程!
顺序存储 用它的下标来表示自变量?
自顶向下的求解方法:从原问题出发,分解出规模减小了的子问题,直至终止条件,然后由终止条件的结果进行回推,求出原问题的值。
自顶向下的求解方法就是真正正的一个递归求解的方法
使用递归的过程来求解问题 避免重复计算:数组的这种特性 作为一个辅助的数据结构帮助解决问题 (备忘录的读写速度
数组的什么特性呢?随机存取 根据数组的下标 迅速往这个下标里面的元素写入和读取
通常把自底向上求解的编程方法称为迭代,把自顶向下的编程方法称为递归。
其实你实现这个迭代。在我们的编程的这个结构里面,是用什么结构来实现迭代? 循环
两者比较:递归编程简单,只需要关注本层逻辑。
实递归来写代码 代码会比较简单,而且可读性比较强。
特点:只需要关注本层逻辑
递归有可能出现重复子问题的情况!
五.

六.
小组讨论代码
1输入编号和积分时 因为是编号升序 从上一条编码的下一个位置开始遍历 减少时间
2给出姓名来查找时 可以两头一起开始往中间靠 这样时间能减半!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号