语义分割常用的评价指标
语义分割中最常用的有3个指标。为了便于解释,首先需要介绍混淆矩阵,如下所示:
|
混淆矩阵 |
真实值 |
||
|
Positive |
Negative |
||
|
预测值
|
Positive |
True Positive(TP)真阳性 |
False Positive(FP)假阳性 |
|
Negative |
False Negative(FN)假阴性 |
True Negative(TN)真阴性 |
|
首先假定数据集中有k+1类(0...k),0通常表示背景。
使用Pii表示原本为i类同时预测为i类,即真阳性(TP)和真阴性(TN)。
Pij表示原本为i类被预测为j类,即假阳性(FP)和假阴性(FN)。
如果第i类为正类,当i!=j时,那么Pii表示TP,Pjj表示TN,Pij表示FP,Pji表示FN。
1) Pixel Accuracy,像素精度是标记正确的像素占总像素的百分比。公式如下:
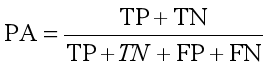
2) Recall,召回率是预测值为1且真实值也为1的样本在真实值为1的所有样本中所占的比例。公式如下:
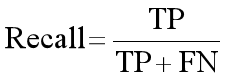
3) Mean IoU(mean intersection over union),均交并比在语义分割中作为标准度量一直被人使用。IoU公式如下:
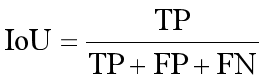
Mean IoU是在所有类别的IoU上取平均值。其公式如下:

在经典的论文《Fully Convolutional Networks for Semantic Segmentation》也有相关的指标定义,但是大体上与上述定义相同。
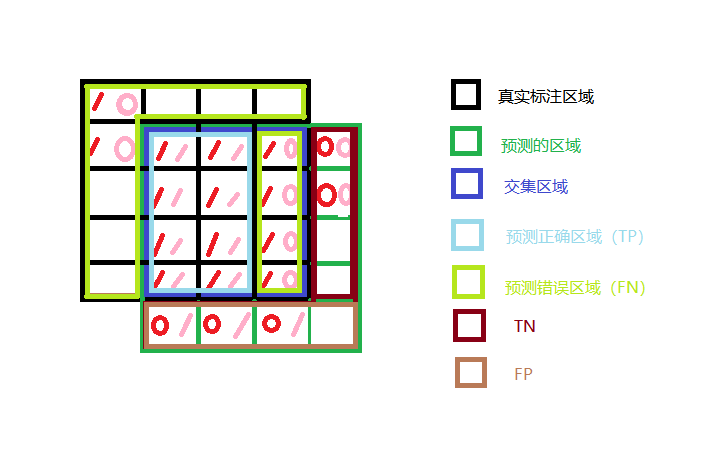
对一张需要预测的图来讲,图中有背景(0)和2类标签(1、2),共计46 + 34 + 20 = 100个像素点数。如下图所示:
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 2 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 2 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 2 |
| 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 2 | 2 |
| 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 2 | 2 |
| 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 2 | 2 |
| 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 2 | 2 |
| 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 2 | 2 |
| 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 2 | 2 |
| 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 2 | 2 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 2 |
| 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 2 | 2 |
| 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 2 | 2 |
| 0 | 1 | 1 | 1 | 1 | 1 | 0 | 2 | 2 | 2 |
| 0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 2 | 2 |
| 0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 2 | 2 |
| 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 2 |
| 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 2 |
如上所示,第一幅图为GT所标注出来的真实类别情况,第二幅图为预测的类别情况。
则首先计算混淆函数:
|
混淆矩阵 |
真实值(46、34、20) |
|||
|
类别0 |
类别1 |
类别2 |
||
|
预测值 |
类别0 |
40 |
4 |
6 |
|
类别1 |
5 |
30 |
0 |
|
|
类别2 |
1 |
0 |
14 |
|
求法:
对角线上的值 / 对角线所在行、列其它值之和 + 对角线值
则:
类别0的IoU:40 /(40 + 4 + 6 + 5 + 1) = 0.714
类别1的IoU:30 /(5 + 30 + 0 + 4 + 0) = 0.769
类别2的IoU:14 /(1 + 0 + 14 + 6 + 0) = 0.667
Mean IoU:(1 / 3)*(0.714 + 0.769 + 0.667 ) = 0.717

 浙公网安备 33010602011771号
浙公网安备 33010602011771号