c# 爬虫-HtmlAgilityPack
在使用爬虫获取自己想要的信息,通常是需要解析下html
最常用的方式是用时正则表达式,这里要介绍的是HtmlAgilityPack ,可以在nuget中引用



1 HtmlDocument doc = new HtmlDocument(); 2 doc.LoadHtml("");//html 文本 3 HtmlNodeCollection hrefList = doc.DocumentNode.SelectNodes("")//这里是元素的xpath 获取的是集合 4 5 HtmlNode node=doc.DocumentNode.SelectSingleNode("")//获取的是 单个元素
获取元素的内容
node.InnerText.Trim()
node.InnerHtml
node.OuterHtml
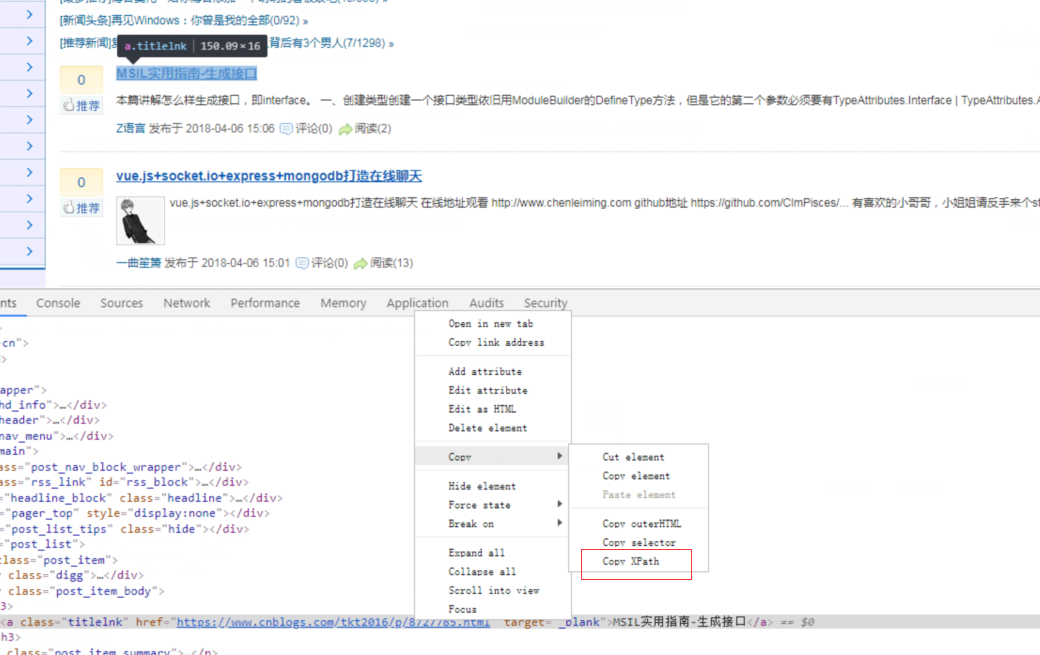
元素xpath的获取

 浙公网安备 33010602011771号
浙公网安备 33010602011771号