c# 基础爬虫
在工作中尝尝会用到爬虫,所谓的爬虫就是爬取网站的资源 ,这里只是一些基础的爬虫提供大家参考 若有写的不好的地方 指出来改正下 大家共同进步
所谓的爬虫就是模拟用户请求某个地址获取信息
C# 中 爬虫使用的是类是HttpWebRequest与WebRequest 两者的区别 前者是可以带cookie 后者一般用于下载 ,后者类似于网页浏览无历史记录
有一些网站有设置证书和安全协议,因此在请求时需要添加证书和安全协议
1、设置了HttpWebRequest 请求


1 public static HttpWebRequest GetHttpRequest() 2 { 3 var urlobj = new Uri("");//请求ur 4 HttpWebRequest request = WebRequest.CreateHttp(urlobj); 5 //验证服务器证书 6 ServicePointManager.ServerCertificateValidationCallback = new System.Net.Security.RemoteCertificateValidationCallback(CheckValidationResult); 7 //安全协议 8 ServicePointManager.SecurityProtocol = SecurityProtocolType.Tls; 9 request.Method = ""; 10 request.Accept =""; 11 request.AllowAutoRedirect =""; 12 request.Host = http.Host; 13 request.ContentType = ""; 14 request.UserAgent = ""; 15 request.Referer = ""; 16 //代理 17 WebProxy proxyObject = new WebProxy("ip地址","端口号");// 18 proxyObject.Credentials = new NetworkCredential("用户名","密码"); 19 request.Proxy = proxyObject; 20 //若使用代理 切记 request.Headers.Add("LP-Https:1") 21 request.Headers.Add(""); 22 //添加cookie 23 request.CookieContainer = new CookieContainer(); 24 request.CookieContainer.Add(urlobj, http.Cookie); 25 //添加参数 切记这个是用于post请求方式 26 byte[] byteArray = System.Text.Encoding.UTF8.GetBytes(http.Parmas.ToString()); 27 request.ContentLength = byteArray.Length; 28 request.GetRequestStream().Write(byteArray, 0, byteArray.Length); 29 return request; 30 } 31 public static bool CheckValidationResult(object sender, X509Certificate certificate, X509Chain chain, SslPolicyErrors errors) 32 { 33 return true; 34 }
以博客园为例 查看某文章,这些是请求参数
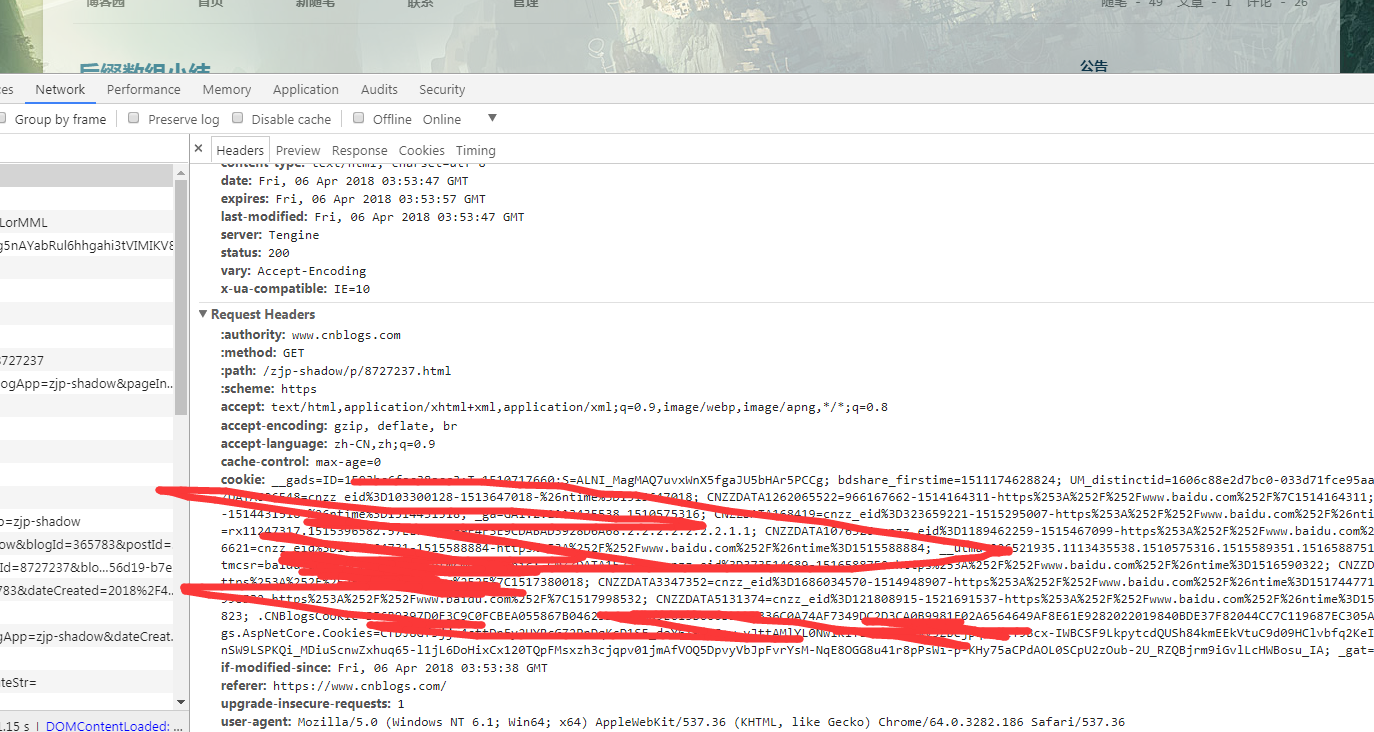
2、获取响应 用到HttpWebResponse
1 public static string GetResponseStr(HttpWebRequest request ) 2 { 3 var responseStr = string.Empty; 4 HttpWebResponse response = null; 5 response = request.GetResponse() as HttpWebResponse; 6 var stream = response.GetResponseStream(); 7 StreamReader streamRead = null; 8 if (//要判断下是否是压缩文件流) 9 { 10 streamRead = new StreamReader(new GZipStream(stream, CompressionMode.Decompress), Encoding.UTF8); 11 } 12 else 13 { 14 streamRead = new StreamReader(stream, Encoding.UTF8); 15 } 16 responseStr = streamRead.ReadToEnd(); 17 return responseStr; 18 }
1 public static MemoryStream GetResponseStream(HttpWebRequest reques) 2 { 3 MemoryStream ms = null; 4 HttpWebResponse response = null; 5 response = request.GetResponse() as HttpWebResponse; 6 var stream = response.GetResponseStream(); 7 ms = new MemoryStream(); 8 byte[] bArr = new byte[1024]; 9 int size; 10 while ((size = stream.Read(bArr, 0, bArr.Length)) > 0) 11 { 12 ms.Write(bArr, 0, size); 13 } 14 return ms; 15 }
前者返回了是html文本 后者返回的是文件流
这个是返回的文本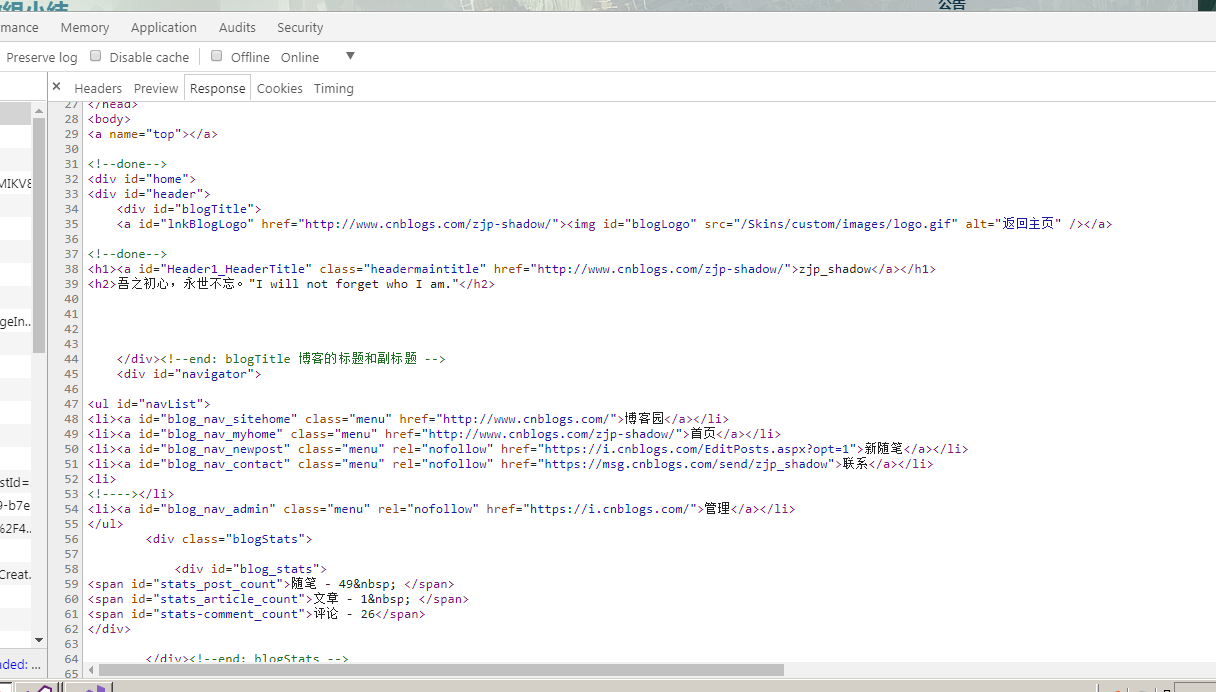

 浙公网安备 33010602011771号
浙公网安备 33010602011771号