大数据回顾:Scala、Spark
9、Scala、Spark
Scala
1.Scala是什么
Scala是一种多范式的编程语言,其设计的初衷是要集成面向对象编程和函数式编程的各种特性。Scala运行于Java平台(Java虚拟机),并兼容现有的Java程序。
函数式编程:函数式编程就是在解决问题时,将问题分解成一个一个的步骤,将每个步骤进行封装(函数),通过调用这些封装好的步骤,解决问题。
例如:请求->用户名、密码->连接JDBC->读取数据库
Scala语言是一个完全函数式编程语言。万物皆函数。0函数的本质:函数可以当做一个值进行传递
2.Scala中隐式转换
谈一谈scala中的隐式转换
1.scala中的隐式转换本质上就是将一个类型转换成另一个类型去使用另一个类型中的功能
2.scala中的隐式转换分为三种:隐式转换函数、隐式转换类、隐式转换变量
3、隐式转换函数在使用隐式转换函数返回值类型功能时,可以自动将参数的类型转换成返回值类型进行使用
4、隐式转换类,可以自动的将构造方法的参数类型转成类的类型,将来可以直接使用构造方法中的类型调用类中的方法
5、隐式转换变量,配合函数中定义的隐式转换参数使用,将来调用函数的时候,可以不用传入隐式转换参数的值,自动使用对应类型的隐式转换变量,当然也可以手动传入具体的值给隐式转换参数
3.集合
-
scala 中的集合: List 元素有序,且可以发生重复、长度固定 Set 元素无序,且唯一,长度固定 Map 元素是键值对的形式,键是唯一的 Tuple 元组,长度是固定的,每个元素的数据类型可以不一样 -
可变集合和不可变集合(mutable下面的都是可变集合)
-
常用方法:
map:依次取出元素,进行后面函数逻辑,有返回值,返回新的集合
flatmap:在flatMap中,我们会传入一个函数,该函数对每个输入都会返回一个集合(而不是一个元素),然后,flatMap把生成的多个集合“拍扁”成为一个集合。
filter:所有数据中取出符合条件的元素
take:返回值是一个Iterator对象,它包含了取出的前n个元素。
last:最后一个元素
head:第一个元素
4.什么是函数柯里化
1、本身是一个数学界的一个名词,本意是原来一次传递多个参数,现在被改成了可以分开传递的形式,这种做法叫做柯里化
2、在scala中体现柯里化,指的是函数的返回值也是一个函数,将来调用时参数可以分开传递。
3、提高了程序的灵活性和代码复用性
4、在scala中也可以通过偏函数实现参数分开传递的功能
5.模式匹配
模式匹配:
可以匹配基本数据类型,字符串,枚举,样例类,类型
* 语法:
* 表达式 match {
* case 值|[变量名:类型]|元组|数组|对象=>
* 匹配成功执行的语句
* case xxx=>
* xxx
* _ xxx=>
* xxx
* }
*
* 模式匹配中,如果没有对应的匹配,那么就报错!!!
var i: Int = 100
i match {
case 20 => println("该值是20")
case 50 => println("该值是50")
// case 100=>println("该值是100")
case _ => println("其他值")
}
Spark
1.spark是什么
Spark是一种快速、通用、可扩展的大数据分析引擎,基于内存计算的大数据并行计算框架。
2.RDD的五大特性
- RDD由很多partition构成,有多少partition就对应有多少task
- 算子实际上是作用在每一个分区上,
- RDD之间有依赖关系,宽依赖和窄依赖,用于切分Stage
- Spark默认是hash分区,ByKey类的算子只能作用在kv格式的rdd上
- Spark为task的计算提供了最佳的计算位置,移动计算而不是移动数据
3.Spark常用算子
- map
- flatMap
- filter
- Union
- join
- groupBy
- groupByKey
- reudceByKey
- sortByKey
- foreach
- foreachPaetition
- saveAsTextFile
4.reduceByKey和groupByKey的区别
- reduceByKey会在map端做预聚合,可以减少shuffle过程中传输的数据量,提高执行效率,groupByKey不能做预聚合
- 在某些业务场景reduceByKey没办法实现,需要使用groupByKey
- 尽量使用reduceByKey代替groupByKey
5.Spark缓存

- 缓存级别选择
Spark 的存储级别的选择,核心问题是在内存使用率和 CPU 效率之间进行权衡。建议按下面的过程进行存储级别的选择
-
如果使用 MEMORY_ONLY 存储在内存中的 RDD / DataFrame 没有发生溢出,那么就选择默认的存储级别。默认存储级别可以最大程度的提高 CPU 的效率,可以使在 RDD / DataFrame 上的操作以最快的速度运行。
-
如果内存不能全部存储 RDD / DataFrame ,那么使用 MEMORY_ONLY_SER,并挑选一个快速序列化库将对象序列化,以节省内存空间。使用这种存储级别,计算速度仍然很快。
-
除了在计算该数据集的代价特别高,或者在需要过滤大量数据的情况下,尽量不要将溢出的数据存储到磁盘。因为,重新计算这个数据分区的耗时与从磁盘读取这些数据的耗时差不多。
-
如果想快速还原故障,建议使用多副本存储级别 MEMORY_ONLY_2 / MEMORY_ONLY_SER_2 。所有的存储级别都通过重新计算丢失的数据的方式,提供了完全容错机制。但是多副本级别在发生数据丢失时,不需要重新计算对应的数据库,可以让任务继续运行。
6. Spark部署方式
- Local::运行在一台机器上,测试使用。
- Standalone:构建一个基于Mster+Slaves的资源调度集群,Spark任务提交给Master运行。是Spark自身的一个调度系统。
- Yarn: Spark客户端直接连接Yarn,不需要额外构建Spark集群。有yarn-client和yarn-cluster两种模式,主要区别在于:Driver程序的运行节点。yarn-clientDriver在本地启动,在本地可以看到详细日志,如果在本地启动太多Spark任务会导致本地网卡流量剧增,不适合上线使用
- Mesos:国内大环境比较少用。
7. Spark任务调度和资源调度流程
- Yarn-client模式
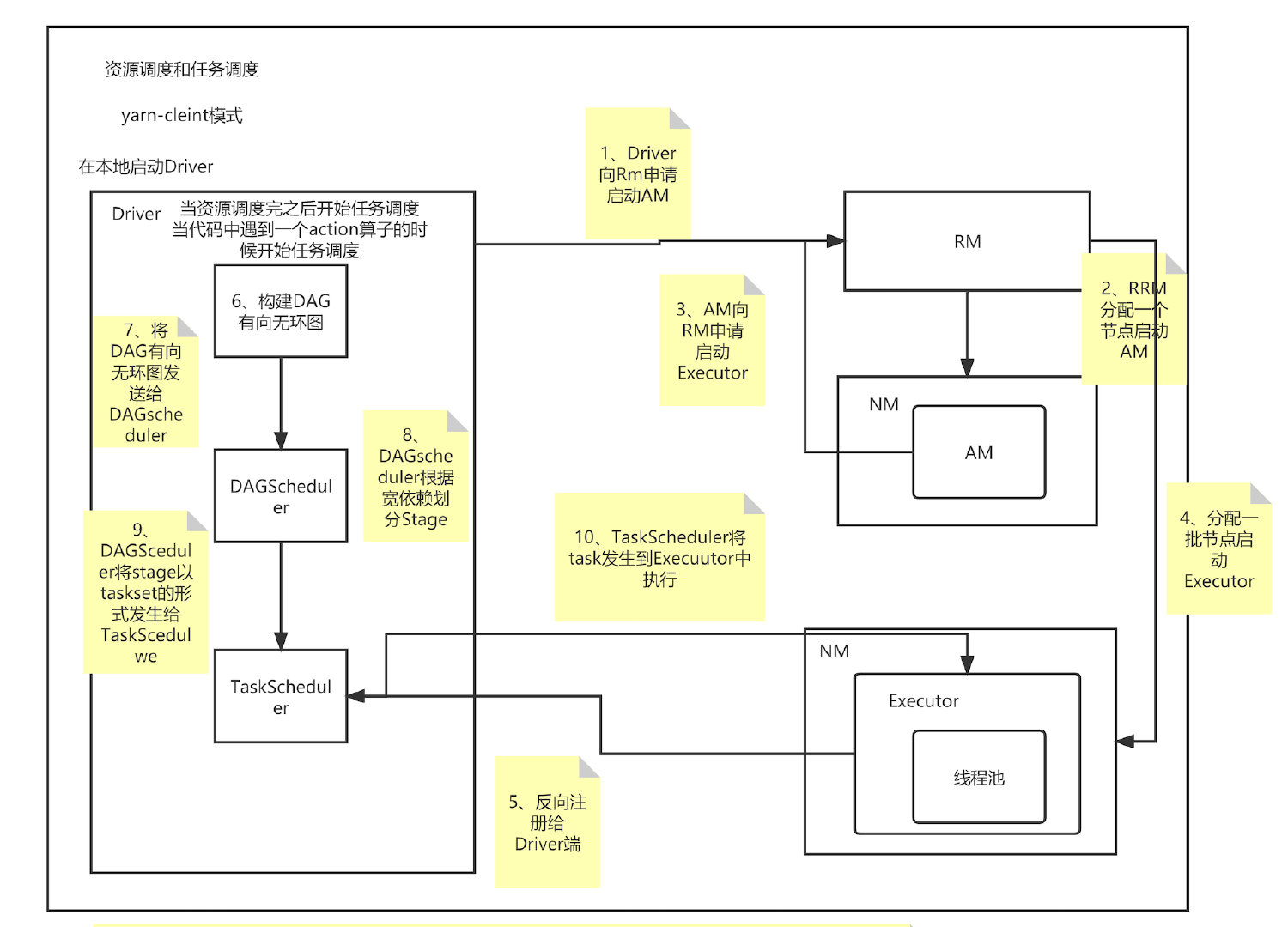
- 重试机制:如果task执行失败taskscheduler会重试3次,如果还失败,DAGscheduler会重试4次
如果是因为shuffle过程中文件找不到的异常,taskscheduler不负责重试task,而是由DAGscheduler重试上一个stage - 推测执行:如果有的task执行很慢,taskscheduler会在发生一个一摸一样的task到其它节点中执行,让多个task竟争,谁先执行完成以谁的结果为准
8. Repartition和Coalesce区别
-
关系:两者都是用来改变RDD的partition数量的,repartition底层调用的就是coalesce方法:coalesce(numPartitions, shuffle = true)
-
区别:repartition一定会发生shuffle,coalesce根据传入的参数来判断是否发生shuffle,一般情况下增大rdd的partition数量使用repartition(增大partition数量一定会产生shuffle),减少partition数量时使用coalesce
9.cache和checkpoint区别
- 都是做RDD持久化的
- cache:内存,不会截断血缘关系,cache 机制是每计算出一个要 cache 的 partition 就直接将其 cache 到内存了。cache一般用于会被重复使用的(但不能太大)RDD。
- checkpoint:磁盘,截断血缘关系,checkpoint 没有使用这种第一次计算得到就存储的方法,而是等到 job 结束后另外启动专门的 job 去完成 checkpoint 。也就是说需要 checkpoint 的 RDD 会被计算两次。因此,在使用 rdd.checkpoint() 的时候,建议加上 rdd.cache(),这样第二次运行的 job 就不用再去计算该 rdd 了,直接读取 cache 写磁盘。checkpoing适用于运算时间很长或运算量太大才能得到的 RDD,或是依赖其他RDD很多的RDD。
10.广播变量和累加器
-
累加器(accumulator)是Spark中提供的一种分布式的变量机制,其原理是将每个副本变量的最终值传回 Driver,由 Driver 聚合后得到最终值,并更新原始变量。累加器的一个常见用途是在调试时对作业执行过程中的事件进行计数。
-
广播变量:允许开发者将一个只读变量(Driver端)缓存到每个节点(Executor)上,而不是每个任务传递一个副本。用来高效分发较大的对象。
-
共享变量出现的原因:
- 通常在向 Spark 传递函数时,比如使用 map() 函数或者用 filter() 传条件时,可以使用驱动器程序中定义的变量,但是集群中运行的每个任务都会得到这些变量的一份新的副本,更新这些副本的值也不会影响Driver中的对应变量。
- Spark的两个共享变量,累加器与广播变量,分别为结果聚合与广播这两种常见的通信模式突破了这一限制。
11. 当Spark涉及到数据库的操作时,如何减少Spark运行中的数据库连接数
- 使用foreachPartition代替foreach,在foreachPartition内获取数据库的连接
12. 简述SparkSQL中RDD、DataFrame、DataSet三者的区别与联系?
-
RDD
优点:
- 编译时类型安全
- 编译时就能检查出类型错误
- 面向对象的编程风格
- 直接通过类名点的方式来操作数据
缺点:
- 序列化和反序列化的性能开销
- 无论是集群间的通信, 还是IO操作都需要对对象的结构和数据进行序列化和反序列化。
- GC的性能开销,频繁的创建和销毁对象, 势必会增加GC
-
DataFrame
优点:
- DataFrame引入了schema和off-heap
- schema : DataFrame每一行的数据, 结构都是一样的,这个结构就存储在schema中。 Spark通过schema就能够读懂数据, 因此在通信和IO时就只需要序列化和反序列化数据, 而结构的部分就可以省略了。
- off-heap : 意味着JVM堆以外的内存, 这些内存直接受操作系统管理(而不是JVM)。Spark能够以二进制的形式序列化数据(不包括结构)到off-heap中, 当要操作数据时,就直接操作off-heap内存。由于Spark理解schema,所以知道该如何操作。
- 通过schema和off-heap,不再受JVM的限制,也就不再收GC的困扰了,DataFrame解决了RDD的缺点。
缺点:
1.DataFrame解决了RDD的缺点,但是却丢了RDD的优点。DataFrame不是类型安全的,API也不是面向对象风格的。
-
DataSet
- DataSet结合了RDD和DataFrame的优点,并带来的一个新的概念Encoder。
- 当序列化数据时,Encoder产生字节码与off-heap进行交互,能够达到按需访问数据的效果,而不用反序列化整个对象。Spark还没有提供自定义Encoder的API,但是未来会加入。
-
相互转换

13. Spark Sql默认并行度
- 参数spark.sql.shuffle.partitions 决定 默认并行度200
14. Spark优化
-
代码优化
- 避免创建重复的RDD
- 尽可能复用同一个RDD
- 对多次使用的RDD进行持久化
- 默认情况下,性能最高的当然是MEMORY_ONLY
- 如果使用MEMORY_ONLY级别时发生了内存溢出,那么建议尝试使用 MEMORY_ONLY_SER级
- 使用高性能的算子
- 使用reduceByKey/aggregateByKey替代groupByKey
- 使用foreachPartitions替代foreach Action算子
- 使用filter之后进行coalesce操作
- 广播大变量
- 会遇到需要在算子函数中使用外部变量的场景(尤其是大变量,比如 100M以上的大集合),那么此时就应该使用Spark的广播(Broadcast)功能来提 升性能
- 使用Kryo优化序列化性能
- 将reduce jon 转化成map join
- Spark sql 中实现方式 /*+broadcast(a) */
- RDD中将小表广播
-
参数优化
1. --num-executors 50 \ executor的数量
2. --executor-cores 2 \ executor的核数
3. --executor-memory 4G \ executor的内存
4. --driver-memory 2G \ driver的内存
5. --conf spark.sql.shuffle.partitions=200 \ spark sql shuffle之后的分区数
6. --conf spark.storage.memoryFraction=0.6 \ 用于缓存的内存占比
7. --conf spark.shuffle.memoryFraction=0.2 \ 用于shuffle的内存占比
8. --conf spark.locality.wait=10 \ task在executor中执行之前的等待时间,默认3秒
9. --conf spark.yarn.executor.memoryOverhead=2048 \ 堆外内存
10. --conf spark.network.timeout=120s \ spark网络连接的超时时间
15. Spark数据倾斜
-
Spark中的数据倾斜,表现主要有下面几种:
数据倾斜产生的原因:1、数据分布不均,2,同时产生了shuffle
- Executor lost,OOM,Shuffle过程出错;
- lDriver OOM;
- 单个Executor执行时间特别久,整体任务卡在某个阶段不能结束;
- 正常运行的任务突然失败
- 数据倾斜优化
- 使用Hive ETL预处理数据
- 适用场景:导致数据倾斜的是Hive表。如果该Hive表中的数据本身很不均匀(比如某个key对应了100万数据,其他key才对应了10条数据),而且业务场景需要频繁使用Spark对Hive表执行某个分析操作,那么比较适合使用这种技术方案。
- 实现思路:此时可以评估一下,是否可以通过Hive来进行数据预处理(即通过Hive ETL预先对数据按照key进行聚合,或者是预先和其他表进行join),然后在Spark作业中针对的数据源就不是原来的Hive表了,而是预处理后的Hive表。此时由于数据已经预先进行过聚合或join操作了,那么在Spark作业中也就不需要使用原先的shuffle类算子执行这类操作了。
- 方案实现原理:这种方案从根源上解决了数据倾斜,因为彻底避免了在Spark中执行shuffle类算子,那么肯定就不会有数据倾斜的问题了。但是这里也要提醒一下大家,这种方式属于治标不治本。因为毕竟数据本身就存在分布不均匀的问题,所以Hive ETL中进行group by或者join等shuffle操作时,还是会出现数据倾斜,导致Hive ETL的速度很慢。我们只是把数据倾斜的发生提前到了Hive ETL中,避免Spark程序发生数据倾斜而已。
- 方案优缺点:
- 优点:实现起来简单便捷,效果还非常好,完全规避掉了数据倾斜,Spark作业的性能会大幅度提升。
- 缺点:治标不治本,Hive ETL中还是会发生数据倾斜。
- 方案实践经验:在一些Java系统与Spark结合使用的项目中,会出现Java代码频繁调用Spark作业的场景,而且对Spark作业的执行性能要求很高,就比较适合使用这种方案。将数据倾斜提前到上游的Hive ETL,每天仅执行一次,只有那一次是比较慢的,而之后每次Java调用Spark作业时,执行速度都会很快,能够提供更好的用户体验。
- 项目实践经验:在美团·点评的交互式用户行为分析系统中使用了这种方案,该系统主要是允许用户通过Java Web系统提交数据分析统计任务,后端通过Java提交Spark作业进行数据分析统计。要求Spark作业速度必须要快,尽量在10分钟以内,否则速度太慢,用户体验会很差。所以我们将有些Spark作业的shuffle操作提前到了Hive ETL中,从而让Spark直接使用预处理的Hive中间表,尽可能地减少Spark的shuffle操作,大幅度提升了性能,将部分作业的性能提升了6倍以上。
- 过滤少数导致倾斜的key
- 方案适用场景:如果发现导致倾斜的key就少数几个,而且对计算本身的影响并不大的话,那么很适合使用这种方案。比如99%的key就对应10条数据,但是只有一个key对应了100万数据,从而导致了数据倾斜。
- 方案实现思路:如果我们判断那少数几个数据量特别多的key,对作业的执行和计算结果不是特别重要的话,那么干脆就直接过滤掉那少数几个key。比如,在Spark SQL中可以使用where子句过滤掉这些key或者在Spark Core中对RDD执行filter算子过滤掉这些key。如果需要每次作业执行时,动态判定哪些key的数据量最多然后再进行过滤,那么可以使用sample算子对RDD进行采样,然后计算出每个key的数量,取数据量最多的key过滤掉即可。
- 方案实现原理:将导致数据倾斜的key给过滤掉之后,这些key就不会参与计算了,自然不可能产生数据倾斜。
- 方案优缺点:
- 优点:实现简单,而且效果也很好,可以完全规避掉数据倾斜。
- 缺点:适用场景不多,大多数情况下,导致倾斜的key还是很多的,并不是只有少数几个。
- 方案实践经验:在项目中我们也采用过这种方案解决数据倾斜。有一次发现某一天Spark作业在运行的时候突然OOM了,追查之后发现,是Hive表中的某一个key在那天数据异常,导致数据量暴增。因此就采取每次执行前先进行采样,计算出样本中数据量最大的几个key之后,直接在程序中将那些key给过滤掉。
- 提高shuffle操作的并行度
- 方案适用场景:如果我们必须要对数据倾斜迎难而上,那么建议优先使用这种方案,因为这是处理数据倾斜最简单的一种方案。
- 方案实现思路:在对RDD执行shuffle算子时,给shuffle算子传入一个参数,比如reduceByKey(1000),该参数就设置了这个shuffle算子执行时shuffle read task的数量,即spark.sql.shuffle.partitions,该参数代表了shuffle read task的并行度,默认是200,对于很多场景来说都有点过小。
- 方案实现原理:增加shuffle read task的数量,可以让原本分配给一个task的多个key分配给多个task,从而让每个task处理比原来更少的数据。举例来说,如果原本有5个key,每个key对应10条数据,这5个key都是分配给一个task的,那么这个task就要处理50条数据。而增加了shuffle read task以后,每个task就分配到一个key,即每个task就处理10条数据,那么自然每个task的执行时间都会变短了。
- 方案优缺点:
- 优点:实现起来比较简单,可以有效缓解和减轻数据倾斜的影响。
- 缺点:只是缓解了数据倾斜而已,没有彻底根除问题,根据实践经验来看,其效果有限。
- 方案实践经验:该方案通常无法彻底解决数据倾斜,因为如果出现一些极端情况,比如某个key对应的数据量有100万,那么无论你的task数量增加到多少,这个对应着100万数据的key肯定还是会分配到一个task中去处理,因此注定还是会发生数据倾斜的。所以这种方案只能说是在发现数据倾斜时尝试使用的第一种手段,尝试去用最简单的方法缓解数据倾斜而已,或者是和其他方案结合起来使用。
- 双重聚合 (局部聚合+全局聚合)
- 方案适用场景:对RDD执行reduceByKey等聚合类shuffle算子或者在Spark SQL中使用group by语句进行分组聚合时,比较适用这种方案。
- 方案实现思路:这个方案的核心实现思路就是进行两阶段聚合:第一次是局部聚合,先给每个key都打上一个随机数,比如10以内的随机数,此时原先一样的key就变成不一样的了,比如(hello, 1) (hello, 1) (hello, 1) (hello, 1),就会变成(1_hello, 1) (1_hello, 1) (2_hello, 1) (2_hello, 1)。接着对打上随机数后的数据,执行reduceByKey等聚合操作,进行局部聚合,那么局部聚合结果,就会变成了(1_hello, 2) (2_hello, 2)。然后将各个key的前缀给去掉,就会变成(hello,2)(hello,2),再次进行全局聚合操作,就可以得到最终结果了,比如(hello, 4)。
- 方案实现原理:将原本相同的key通过附加随机前缀的方式,变成多个不同的key,就可以让原本被一个task处理的数据分散到多个task上去做局部聚合,进而解决单个task处理数据量过多的问题。接着去除掉随机前缀,再次进行全局聚合,就可以得到最终的结果。具体原理见下图。
- 方案优缺点:
- 优点:对于聚合类的shuffle操作导致的数据倾斜,效果是非常不错的。通常都可以解决掉数据倾斜,或者至少是大幅度缓解数据倾斜,将Spark作业的性能提升数倍以上。
- 缺点:仅仅适用于聚合类的shuffle操作,适用范围相对较窄。如果是join类的shuffle操作,还得用其他的解决方案。
- 将reduce join转为map join
- 方案适用场景:在对RDD使用join类操作,或者是在Spark SQL中使用join语句时,而且join操作中的一个RDD或表的数据量比较小(比如几百M或者一两G),比较适用此方案。
- 方案实现思路:不使用join算子进行连接操作,而使用Broadcast变量与map类算子实现join操作,进而完全规避掉shuffle类的操作,彻底避免数据倾斜的发生和出现。将较小RDD中的数据直接通过collect算子拉取到Driver端的内存中来,然后对其创建一个Broadcast变量,广播给其他Executor节点;接着对另外一个RDD执行map类算子,在算子函数内,从Broadcast变量中获取较小RDD的全量数据,与当前RDD的每一条数据按照连接key进行比对,如果连接key相同的话,那么就将两个RDD的数据用你需要的方式连接起来。
- 方案实现原理:普通的join是会走shuffle过程的,而一旦shuffle,就相当于会将相同key的数据拉取到一个shuffle read task中再进行join,此时就是reduce join。但是如果一个RDD是比较小的,则可以采用广播小RDD全量数据+map算子来实现与join同样的效果,也就是map join,此时就不会发生shuffle操作,也就不会发生数据倾斜。具体原理如下图所示。
- 方案优缺点:
- 优点:对join操作导致的数据倾斜,效果非常好,因为根本就不会发生shuffle,也就根本不会发生数据倾斜。
- 缺点:适用场景较少,因为这个方案只适用于一个大表和一个小表的情况。毕竟我们需要将小表进行广播,此时会比较消耗内存资源,driver和每个Executor内存中都会驻留一份小RDD的全量数据。如果我们广播出去的RDD数据比较大,比如10G以上,那么就可能发生内存溢出了。因此并不适合两个都是大表的情况。
- 采样倾斜key并分拆join操作
- 方案适用场景:两个RDD/Hive表进行join的时候,如果数据量都比较大,无法采用“解决方案五”,那么此时可以看一下两个RDD/Hive表中的key分布情况。如果出现数据倾斜,是因为其中某一个RDD/Hive表中的少数几个key的数据量过大,而另一个RDD/Hive表中的所有key都分布比较均匀,那么采用这个解决方案是比较合适的。
- 方案实现思路:对包含少数几个数据量过大的key的那个RDD,通过sample算子采样出一份样本来,然后统计一下每个key的数量,计算出来数据量最大的是哪几个key。然后将这几个key对应的数据从原来的RDD中拆分出来,形成一个单独的RDD,并给每个key都打上n以内的随机数作为前缀;而不会导致倾斜的大部分key形成另外一个RDD。接着将需要join的另一个RDD,也过滤出来那几个倾斜key对应的数据并形成一个单独的RDD,将每条数据膨胀成n条数据,这n条数据都按顺序附加一个0~n的前缀;不会导致倾斜的大部分key也形成另外一个RDD。再将附加了随机前缀的独立RDD与另一个膨胀n倍的独立RDD进行join,此时就可以将原先相同的key打散成n份,分散到多个task中去进行join了。而另外两个普通的RDD就照常join即可。最后将两次join的结果使用union算子合并起来即可,就是最终的join结果。
- 方案实现原理:对于join导致的数据倾斜,如果只是某几个key导致了倾斜,可以将少数几个key分拆成独立RDD,并附加随机前缀打散成n份去进行join,此时这几个key对应的数据就不会集中在少数几个task上,而是分散到多个task进行join了。具体原理见下图。
- 方案优缺点:
- 优点:对于join导致的数据倾斜,如果只是某几个key导致了倾斜,采用该方式可以用最有效的方式打散key进行join。而且只需要针对少数倾斜key对应的数据进行扩容n倍,不需要对全量数据进行扩容。避免了占用过多内存。
- 缺点:如果导致倾斜的key特别多的话,比如成千上万个key都导致数据倾斜,那么这种方式也不适合。
- 使用随机前缀和扩容RDD进行join
- 方案实现思路:该方案的实现思路基本和“解决方案六”类似,首先查看RDD/Hive表中的数据分布情况,找到那个造成数据倾斜的RDD/Hive表,比如有多个key都对应了超过1万条数据。然后将该RDD的每条数据都打上一个n以内的随机前缀。同时对另外一个正常的RDD进行扩容,将每条数据都扩容成n条数据,扩容出来的每条数据都依次打上一个0~n的前缀。最后将两个处理后的RDD进行join即可。
- 使用Hive ETL预处理数据
15. Spark Streaming背压机制
- 把spark.streaming.backpressure.enabled 参数设置为ture,开启背压机制后Spark Streaming会根据延迟动态去kafka消费数据,上限由spark.streaming.kafka.maxRatePerPartition参数控制,所以两个参数一般会一起使用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号