数据采集工具Flume Scoop DataX
八、数据采集
Flume
1.Flume工作机制是什么
- Flume 用于从大量不同的源有效的收集、聚合、移动大量日志数据进行集中式存储。
- Flume 的核心是 Agent,Agent 中包括 Source、Channel 和 Sink。Agent 是最小的独立运行单位。在 Agent 中数据流向为 Source>Channel>Sink。
- Source 负责收集数据,传递给 Channel。支持多种收集方式,比如 Avro、Thrift、Spooling Directory、Taildir、Kafka、HTTP 等。其中 Taildir Source:观察指定的文件,并在监测到添加的每个文件的新行后几乎实时的尾随它们;Spooling Directory Source:监测配置的目录下新增的文件,并将文件中的数据读取出来。需要注意两点,拷贝到 spool 目录下的文件不可以再打开编辑,并且 spool 目录下不可包含相应的子目录。
- Channel 作为数据通道,接受 Source 的数据并储存,传递给 Sink。Channel 中的数据会在被 Sink 消费前一直保存,等 Sink 成功把数据发送到下一跳 Channel 或最终目的地后才会删除缓存的数据。支持多种类型的 Channel,包括 Memory、JDBC、Kafka、File 等。其中Memory Channel 可以实现高速的吞吐,但是无法保证数据的完整性;File Channel 是一个持久化的隧道,它持久化所有的事件,并将其存储到磁盘中。
- Sink 消费 Channel 中的数据,传递到下一跳 Channel 或最终目的地,完成后将数据从Channel 中移除。支持多种类型的 Sink,包括 HDFS、Hive、Hbase、Kafka 等。Sink 在设置存储数据的时候,可以向文件系统、数据库、hadoop 存数据;在日志数据比较少时,可以将数据存储在文件系统中,并且设定一定的时间间隔保存数据。在日志数据较多时,可以将相应的日志数据存储到 Hadoop 中,便于日后进行相应的数据分析。
- Flume 支持多个 Agent 相连,形成多极 Agent。此时上一级 Sink 和下一集 Source 都必须使用 Avro 协议。使用多级 Flume 可以实现日志的聚合,第一层 Agent 接收日志,第二层Agent 统一处理。
- Flume 还支持将一个流从一个 Source 扇出到多个 Channel。有两种模式的扇出,复制和复用。在复制流程中,事件被发送到所有配置的通道。在复用的情况下,事件仅发送到合格信道的子集。
2. Flume组成、Put事务、Take事务
-
taildir source
- 断点续传、多目录
- 哪个flume版本产生的?
- Apache1.7、CDH1.6
- 没有断点续传功能时怎么做的?
- 自定义
- taildir挂了怎么办
- 不会丢数据:断点续传
- 怎么处理重复数据
- 不处理
- 生产环境下通常不处理,因为会影响传输效率
- 处理
- 自身:在taildirsource里面增加自定义事务
- 找兄弟:下一级处理(hive dwd sparkstreaming flink布隆)、去重手段(groupby、开窗取窗口第一条、redis)
- 不处理
- taildir source 是否支持递归遍历文件夹读取文件?
- 不支持
- 自定义:递归遍历文件夹 +读取文件
-
file channel、memory channel、kafka channel
-
file channel
- 数据存储于磁盘,优势:可靠性高;劣势:传输速度低
- 默认容量:100万event
- FileChannel可以通过配置dataDirs指向多个路径,每个路径对应不同的硬盘,增大Flume吞吐量
-
memory channel
- 数据存储于内存,优势:传输速度快;劣势:可靠性差
- 默认容量:100个event
-
kafka channel
- 数据存储于Kafka,基于磁盘,优势:可靠性高
- 传输速度:kafka channel > memory channel+kafka sink 原因省去了sink
-
生产环境如何选择
- 如果下一级是kafka,优先选择kafka channel
- 如果是金融、对钱要求准确的公司,选择file channel
- 如果就是普通的日志,通常可以选择memory channel
-
-
HDFS sink
- 设置时间1小时、大小128m、event个数(0禁止)
- hdfs.rollInterval=3600,hdfs.rollSize=134217728,hdfs.rollCount =0
-
事务
- Source到Channel是Put事务
- Channel到Sink是Take事务
3. Flume采集数据会丢失吗?
- 如果是FileChannel不会,Channel存储可以存储在File中,数据传输自身有事务。如果是MemoryChannel有可能丢。
Sqoop
1. Sqoop参数
--connect \
--username \
--password \
--target-dir \
--delete-target-dir \
--num-mappers \
--fields-terminated-by \
--query "$2" ' and $CONDITIONS;'
2. Sqoop的工作原理是什么
- hadoop 生态圈上的数据传输工具。 可以将关系型数据库的数据导入非结构化的 hdfs、hive 或者 bbase 中,也可以将 hdfs 中的数据导出到关系型数据库或者文本文件中。 使用的是 mr 程序来执行任务,使用 jdbc 和关系型数据库进行交互。
- import 原理:通过指定的分隔符进行数据切分,将分片传入各个 map 中,在 map 任务中在每行数据进行写入处理没有 reduce。
- export 原理:根据要操作的表名生成一个 java 类,并读取其元数据信息和分隔符对非结构化的数据进行匹配,多个 map 作业同时执行写入关系型数据库
3. Sqoop导入导出Null存储的一致性问题
- Hive中的Null在底层是以“\N”来存储,而MySQL中的Null在底层就是Null,为了保证数据两端的一致性。在导出数据时采用--input-null-string和--input-null-non-string两个参数。导入数据时采用--null-string和--null-non-string。
4. Sqoop数据导出一致性问题
5. Sqoop底层运行的任务是什么
- 只有Map阶段,没有Reduce阶段的任务。默认是4个MapTask。
6. Sqoop一天导入多少数据
- 100万日活=>10万订单,1人10条,每天1g左右业务数据
- Sqoop每天将1G的数据量导入到数仓。
7. Sqoop数据导出的时候一次执行多长时间
- 每天晚上00:30开始执行,Sqoop任务一般情况40 -50分钟的都有。取决于数据量(11:11,6:18等活动在1个小时左右)。
8. Sqoop数据导出Parquet
Ads层数据用Sqoop往MySql中导入数据的时候,如果用了orc(Parquet)不能导入,需转化成text格式
- 创建临时表,把Parquet中表数据导入到临时表,把临时表导出到目标表用于可视化
- Sqoop里面有参数,可以直接把Parquet转换为text
- ads层建表的时候就不要建Parquet表
DataX
1. 简单介绍一下DataX
- DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。(这是一个单机多任务的ETL工具)
2. DataX架构
DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
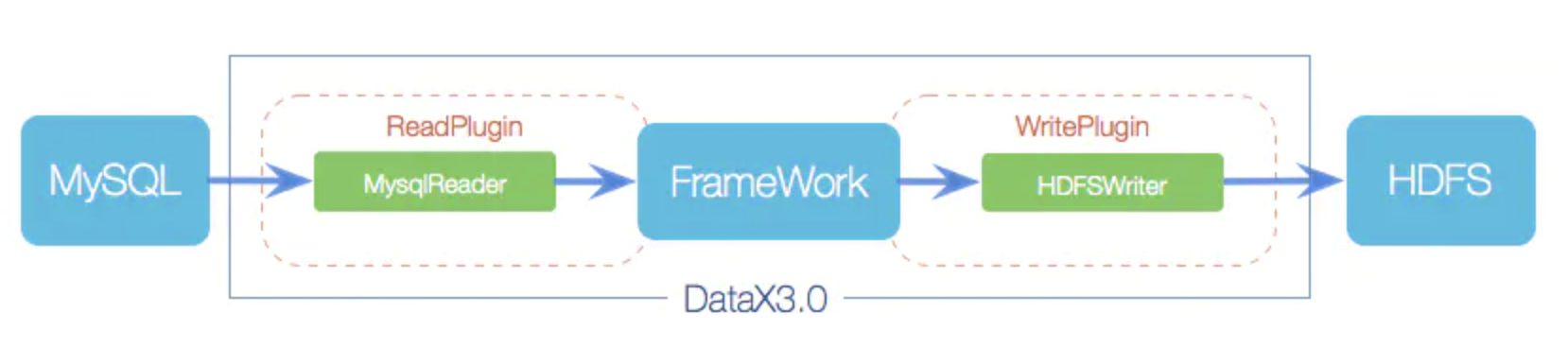
- Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
3. DataX运行流程
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
4. DataX的使用
基于官网提供的JSON格式配置文件模版,选择对应的读写插件,根据实际情况修改相关配置,最后使用dataX命令提交运行即可
5. 数据采集流程和同步场景

总结
1. Flume
Flume 是一个分布式、可靠和可伸缩的系统,用于高效地从不同的数据源收集、聚合和传输大量数据到 Hadoop 系统中。它主要用于处理大数据环境中的日志数据流。
- 核心组件:
- Source:数据的入口点,例如从日志文件、网络流等来源接收数据。
- Channel:在 Source 和 Sink 之间传递数据的缓冲区,Flume 提供了多种类型的 Channel,比如 Memory Channel 和 File Channel。
- Sink:数据的出口点,数据会被写入到目标存储系统中,例如 HDFS、HBase 等。
- 使用场景:主要用于日志数据的收集和传输。
2. Sqoop
Sqoop 是一个用于在 Hadoop 和关系型数据库之间高效传输数据的工具。它主要用于将数据从关系数据库导入到 Hadoop 中,或者将数据从 Hadoop 中导出到关系数据库中。
- 主要功能:
- Import:将关系数据库中的数据导入到 Hadoop 的 HDFS、Hive 或 HBase 中。
- Export:将 Hadoop 中的数据导出到关系数据库。
- 使用场景:适用于数据迁移、数据同步和数据备份等任务。
3. DataX
DataX 是阿里巴巴开源的一个数据同步工具,支持各种数据源之间的数据同步,包括关系型数据库、NoSQL 数据库、大数据存储等。它支持多种数据源的读取和写入操作,提供了灵活的数据同步解决方案。
- 主要功能:
- Reader:数据源读取组件,支持多种数据源。
- Writer:数据写入组件,支持多种数据存储系统。
- Job:数据同步任务的配置和执行。
- 使用场景:广泛应用于数据迁移、数据同步、数据集成等场景,支持多种数据源和数据目标。
希望这些信息能帮助你复习数据库知识!如果有更具体的问题或需要更详细的解释,随时告诉我。
介绍下各自的用法
1. Flume
Flume 的使用包括配置其组件来完成数据流的收集、聚合和传输。以下是一个简单的 Flume 配置示例,用于将日志文件传输到 HDFS:
配置文件(flume.conf)示例:
properties复制代码# 定义一个 agent agent.sources = source agent.channels = channel agent.sinks = sink # 配置 source agent.sources.source.type = spool agent.sources.source.spooldir = /var/log/myapp agent.sources.source.fileHeader = true # 配置 channel agent.channels.channel.type = memory agent.channels.channel.capacity = 1000 agent.channels.channel.transactionCapacity = 100 # 配置 sink agent.sinks.sink.type = hdfs agent.sinks.sink.hdfs.path = /user/hadoop/logs agent.sinks.sink.hdfs.fileType = DataStream # 将 source 连接到 channel agent.sources.source.channels = channel # 将 channel 连接到 sink agent.sinks.sink.channel = channel步骤:
- 定义 Source:指定数据的来源,例如从本地文件系统中读取。
- 定义 Channel:设置数据在 Source 和 Sink 之间的缓冲机制。
- 定义 Sink:配置数据的目标位置,例如 HDFS。
- 启动 Flume:使用命令
flume-ng agent -c conf -f flume.conf -n agent启动 Flume agent。2. Sqoop
Sqoop 的使用涉及到导入和导出数据。下面是导入和导出的基本命令示例:
导入数据到 HDFS:
bash复制代码sqoop import \ --connect jdbc:mysql://localhost/mydatabase \ --username myuser \ --password mypassword \ --table mytable \ --target-dir /user/hadoop/mytable \ --split-by id导出数据到 MySQL:
bash复制代码sqoop export \ --connect jdbc:mysql://localhost/mydatabase \ --username myuser \ --password mypassword \ --table mytable \ --export-dir /user/hadoop/mytable \ --input-fields-terminated-by ','步骤:
- 导入:通过
--connect参数指定数据库连接,--table参数指定要导入的表,--target-dir参数指定 HDFS 中的数据存储目录。- 导出:通过
--connect参数指定数据库连接,--table参数指定要导出的表,--export-dir参数指定 HDFS 中的数据来源目录。3. DataX
DataX 的使用包括配置任务的 JSON 文件,定义数据源和目标数据存储。以下是一个简单的 DataX 配置示例,用于将数据从 MySQL 导入到 HDFS:
配置文件(job.json)示例:
json复制代码{ "job": { "content": [ { "reader": { "name": "mysqlreader", "parameter": { "username": "myuser", "password": "mypassword", "column": ["id", "name", "value"], "splitPk": "id", "connection": [ { "table": ["mytable"], "jdbcUrl": ["jdbc:mysql://localhost/mydatabase"] } ] } }, "writer": { "name": "hdfswriter", "parameter": { "defaultFS": "hdfs://localhost:9000", "fileType": "text", "path": "/user/hadoop/mytable", "column": ["id", "name", "value"] } } } ], "setting": { "speed": { "channel": 1 } } } }步骤:
- 配置 Reader:设置数据源(例如 MySQL)的连接信息和要读取的表。
- 配置 Writer:设置数据目标(例如 HDFS)的存储路径和格式。
- 运行任务:使用命令
datax.py job.json执行 DataX 任务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号