
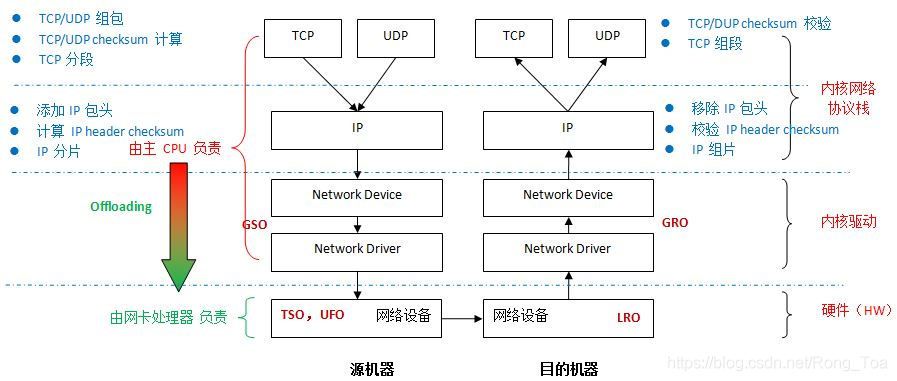
内核gso
概念
TSO(TCP Segmentation Offload): 是一种利用网卡来对大数据包进行自动分段,降低CPU负载的技术。 其主要是延迟分段
GSO(Generic Segmentation Offload): GSO是协议栈是否推迟分段,在发送到网卡之前判断网卡是否支持TSO,如果网卡支持TSO则让网卡分段,否则协议栈分完段再交给驱动。 如果TSO开启,GSO会自动开启
- GSO开启, TSO开启: 协议栈推迟分段,并直接传递大数据包到网卡,让网卡自动分段
- GSO开启, TSO关闭: 协议栈推迟分段,在最后发送到网卡前才执行分段
- GSO关闭, TSO开启: 同GSO开启, TSO开启
- GSO关闭, TSO关闭: 不推迟分段,在tcp_sendmsg中直接发送MSS大小的数据包
开启GSO/TSO
- 驱动程序在注册网卡设备的时候默认开启GSO: NETIF_F_GSO
- 驱动程序会根据网卡硬件是否支持来设置TSO: NETIF_F_TSO
- 可以通过ethtool -K来开关GSO/TSO
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
#define NETIF_F_SOFT_FEATURES (NETIF_F_GSO | NETIF_F_GRO)
int register_netdevice(struct net_device *dev)
{
...
/* Transfer changeable features to wanted_features and enable
* software offloads (GSO and GRO).
*/
dev->hw_features |= NETIF_F_SOFT_FEATURES;
dev->features |= NETIF_F_SOFT_FEATURES; //默认开启GRO/GSO
dev->wanted_features = dev->features & dev->hw_features;
...
}
static int ixgbe_probe(struct pci_dev *pdev, const struct pci_device_id *ent)
{
...
netdev->features = NETIF_F_SG |
NETIF_F_TSO |
NETIF_F_TSO6 |
NETIF_F_RXHASH |
NETIF_F_RXCSUM |
NETIF_F_HW_CSUM;
register_netdev(netdev);
...
}
|
TSO与GSO的重要区别
1, TSO只有第一个分片有TCP头和IP头,接着的分段只有IP头。意味着第一个分段丢失,所有分段得重传。
2, GSO在分段时会调用TCP或UDP的回调函数(udp4_ufo_fragment)为每个分段都加上IP头,l4header,由于分段是通过mss设置的(mss由发送端设置),所以长度仍然可能超过mtu值,所以在IP层还得再分片(代码位于dev_hard_start_xmit)。
是否推迟分段
从上面我们知道GSO/TSO是否开启是保存在dev->features中,而设备和路由关联,当我们查询到路由后就可以把配置保存在sock中
比如在tcp_v4_connect和tcp_v4_syn_recv_sock都会调用sk_setup_caps来设置GSO/TSO配置
需要注意的是,只要开启了GSO,即使硬件不支持TSO,也会设置NETIF_F_TSO,使得sk_can_gso(sk)在GSO开启或者TSO开启的时候都返回true
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
#define NETIF_F_ALL_TSO (NETIF_F_TSO | NETIF_F_TSO6 | \
NETIF_F_TSO_ECN | NETIF_F_TSO_MANGLEID)
/* List of features with software fallbacks. */
#define NETIF_F_GSO_SOFTWARE (NETIF_F_ALL_TSO | NETIF_F_UFO | \
NETIF_F_GSO_SCTP)
void sk_setup_caps(struct sock *sk, struct dst_entry *dst)
{
u32 max_segs = 1;
sk_dst_set(sk, dst);
sk->sk_route_caps = dst->dev->features;
if (sk->sk_route_caps & NETIF_F_GSO) //软件GSO,默认开启
sk->sk_route_caps |= NETIF_F_GSO_SOFTWARE; //开启延时gso延时选项,包括NETIF_F_TSO
sk->sk_route_caps &= ~sk->sk_route_nocaps;
if (sk_can_gso(sk)) { //开启tso,对于tcpv4, 设置了NETIF_F_TSO
if (dst->header_len) {
sk->sk_route_caps &= ~NETIF_F_GSO_MASK;
} else {
sk->sk_route_caps |= NETIF_F_SG | NETIF_F_HW_CSUM; // 开启gso后,设置sg和校验
sk->sk_gso_max_size = dst->dev->gso_max_size; //GSO_MAX_SIZE=65536
max_segs = max_t(u32, dst->dev->gso_max_segs, 1); //GSO_MAX_SEGS=65535
}
}
sk->sk_gso_max_segs = max_segs;
}
//判断GSO或TSO是否开启
static inline bool sk_can_gso(const struct sock *sk)
{
return net_gso_ok(sk->sk_route_caps, sk->sk_gso_type); //SKB_GSO_TCPV4
}
//对于tcp4, 判断NETIF_F_TSO是否被设置, 即使硬件不支持TSO,开启GSO的情况下也会被设置
static inline bool net_gso_ok(netdev_features_t features, int gso_type)
{
netdev_features_t feature = (netdev_features_t)gso_type << NETIF_F_GSO_SHIFT;
/* check flags correspondence */
BUILD_BUG_ON(SKB_GSO_TCPV4 != (NETIF_F_TSO >> NETIF_F_GSO_SHIFT));
BUILD_BUG_ON(SKB_GSO_UDP != (NETIF_F_UFO >> NETIF_F_GSO_SHIFT));
return (features & feature) == feature;
}
|
vxlan gso
[root@bogon ~]# ethtool -k vxlan0 | grep generic-segmentation-offload generic-segmentation-offload: on [root@bogon ~]# ethtool -k vxlan0 Features for vxlan0: rx-checksumming: on tx-checksumming: on tx-checksum-ipv4: off [fixed] tx-checksum-ip-generic: on tx-checksum-ipv6: off [fixed] tx-checksum-fcoe-crc: off [fixed] tx-checksum-sctp: off [fixed] scatter-gather: on tx-scatter-gather: on tx-scatter-gather-fraglist: off [fixed] tcp-segmentation-offload: on tx-tcp-segmentation: on tx-tcp-ecn-segmentation: on tx-tcp-mangleid-segmentation: on tx-tcp6-segmentation: on udp-fragmentation-offload: off generic-segmentation-offload: on generic-receive-offload: on large-receive-offload: off [fixed] rx-vlan-offload: off [fixed] tx-vlan-offload: off [fixed] ntuple-filters: off [fixed] receive-hashing: off [fixed] highdma: off [fixed] rx-vlan-filter: off [fixed] vlan-challenged: off [fixed] tx-lockless: on [fixed] netns-local: off [fixed] tx-gso-robust: off [fixed] tx-fcoe-segmentation: off [fixed] tx-gre-segmentation: off [fixed] tx-gre-csum-segmentation: off [fixed] tx-ipxip4-segmentation: off [fixed] tx-ipxip6-segmentation: off [fixed] tx-udp_tnl-segmentation: off [fixed] tx-udp_tnl-csum-segmentation: off [fixed] tx-gso-partial: off [fixed] tx-sctp-segmentation: on tx-esp-segmentation: off [fixed] fcoe-mtu: off [fixed] tx-nocache-copy: off loopback: off [fixed] rx-fcs: off [fixed] rx-all: off [fixed] tx-vlan-stag-hw-insert: off [fixed] rx-vlan-stag-hw-parse: off [fixed] rx-vlan-stag-filter: off [fixed] l2-fwd-offload: off [fixed] hw-tc-offload: off [fixed] esp-hw-offload: off [fixed] esp-tx-csum-hw-offload: off [fixed] rx-udp_tunnel-port-offload: off [fixed]
ip -d link show vxlan0 24: vxlan0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 16:0b:a0:7a:e0:b0 brd ff:ff:ff:ff:ff:ff promiscuity 0 vxlan id 42 srcport 0 0 dstport 8472 ageing 300 udpcsum noudp6zerocsumtx noudp6zerocsumrx addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535 [root@bogon ~]#
tcpdump vxlan接口没有vxlan header
节点1 ip netns exec host1 ping 9.9.9.1 [root@evpn2 test]# tcpdump -i vxlan100 -eennvv tcpdump: listening on vxlan100, link-type EN10MB (Ethernet), capture size 262144 bytes 11:53:45.567149 00:00:01:02:03:04 > 00:00:01:02:03:05, ethertype IPv4 (0x0800), length 98: (tos 0x0, ttl 63, id 1418, offset 0, flags [DF], proto ICMP (1), length 84) 2.2.2.2 > 9.9.9.1: ICMP echo request, id 16024, seq 1, length 64 11:53:45.567212 00:00:01:02:03:05 > 00:00:01:02:03:04, ethertype IPv4 (0x0800), length 98: (tos 0x0, ttl 63, id 57044, offset 0, flags [none], proto ICMP (1), length 84) 9.9.9.1 > 2.2.2.2: ICMP echo reply, id 16024, seq 1, length 64 11:53:46.635278 00:00:01:02:03:04 > 00:00:01:02:03:05, ethertype IPv4 (0x0800), length 98: (tos 0x0, ttl 63, id 1457, offset 0, flags [DF], proto ICMP (1), length 84) 2.2.2.2 > 9.9.9.1: ICMP echo request, id 16024, seq 2, length 64 11:53:46.635344 00:00:01:02:03:05 > 00:00:01:02:03:04, ethertype IPv4 (0x0800), length 98: (tos 0x0, ttl 63, id 57086, offset 0, flags [none], proto ICMP (1), length 84) 9.9.9.1 > 2.2.2.2: ICMP echo reply, id 16024, seq 2, length 64 11:53:47.675200 00:00:01:02:03:04 > 00:00:01:02:03:05, ethertype IPv4 (0x0800), length 98: (tos 0x0, ttl 63, id 1561, offset 0, flags [DF], proto ICMP (1), length 84) 2.2.2.2 > 9.9.9.1: ICMP echo request, id 16024, seq 3, length 64 11:53:47.675262 00:00:01:02:03:05 > 00:00:01:02:03:04, ethertype IPv4 (0x0800), length 98: (tos 0x0, ttl 63, id 57130, offset 0, flags [none], proto ICMP (1), length 84) 9.9.9.1 > 2.2.2.2: ICMP echo reply, id 16024, seq 3, length 64 11:53:48.715193 00:00:01:02:03:04 > 00:00:01:02:03:05, ethertype IPv4 (0x0800), length 98: (tos 0x0, ttl 63, id 1662, offset 0, flags [DF], proto ICMP (1), length 84) 2.2.2.2 > 9.9.9.1: ICMP echo request, id 16024, seq 4, length 64 11:53:48.715258 00:00:01:02:03:05 > 00:00:01:02:03:04, ethertype IPv4 (0x0800), length 98: (tos 0x0, ttl 63, id 57203, offset 0, flags [none], proto ICMP (1), length 84) 9.9.9.1 > 2.2.2.2: ICMP echo reply, id 16024, seq 4, length 64 11:53:49.715707 00:00:01:02:03:04 > 00:00:01:02:03:05, ethertype IPv4 (0x0800), length 98: (tos 0x0, ttl 63, id 1755, offset 0, flags [DF], proto ICMP (1), length 84) 2.2.2.2 > 9.9.9.1: ICMP echo request, id 16024, seq 5, length 64 11:53:49.715776 00:00:01:02:03:05 > 00:00:01:02:03:04, ethertype IPv4 (0x0800), length 98: (tos 0x0, ttl 63, id 57273, offset 0, flags [none], proto ICMP (1), length 84) 9.9.9.1 > 2.2.2.2: ICMP echo reply, id 16024, seq 5, length 64
gso调用
vxlan_xmit_skb --> udp_tunnel_xmit_skb --> iptunnel_xmit --> ip_local_out -->ip_finish_output-->ip_finish_output_gso -->skb_gso_segment
__dev_queue_xmit-->validate_xmit_skb --> skb_gso_segment --> skb_gso_segment
由 Linux UDP 协议栈提供 UDP 分片逻辑而不是 IP 分片逻辑,这使得每个分片都有完整的 UDP 包头,然后继续 IP 层的 GSO 分片
L3 paload size = mtu : call dev_queue_xmit
L3 paload size => mtu : call frag
L3 paload size < mtu : call dev_queue_xmit
#define skb_walk_frags(skb, iter) \ for (iter = skb_shinfo(skb)->frag_list; iter; iter = iter->next)
static inline bool skb_gso_size_check(const struct sk_buff *skb, unsigned int seg_len, unsigned int max_len) { const struct skb_shared_info *shinfo = skb_shinfo(skb); const struct sk_buff *iter; if (shinfo->gso_size != GSO_BY_FRAGS) return seg_len <= max_len; /* Undo this so we can re-use header sizes */ seg_len -= GSO_BY_FRAGS; skb_walk_frags(skb, iter) { if (seg_len + skb_headlen(iter) > max_len) return false; } return true; } /** * skb_gso_validate_network_len - Will a split GSO skb fit into a given MTU? * * @skb: GSO skb * @mtu: MTU to validate against * * skb_gso_validate_network_len validates if a given skb will fit a * wanted MTU once split. It considers L3 headers, L4 headers, and the * payload. */ bool skb_gso_validate_network_len(const struct sk_buff *skb, unsigned int mtu) { return skb_gso_size_check(skb, skb_gso_network_seglen(skb), mtu); }
static int ip_finish_output_gso(struct net *net, struct sock *sk, struct sk_buff *skb, unsigned int mtu) { netdev_features_t features; struct sk_buff *segs; int ret = 0; /* common case: seglen is <= mtu */ if (skb_gso_validate_network_len(skb, mtu)) //不需要gso return ip_finish_output2(net, sk, skb); /* Slowpath - GSO segment length exceeds the egress MTU. * * This can happen in several cases: * - Forwarding of a TCP GRO skb, when DF flag is not set. * - Forwarding of an skb that arrived on a virtualization interface * (virtio-net/vhost/tap) with TSO/GSO size set by other network * stack. * - Local GSO skb transmitted on an NETIF_F_TSO tunnel stacked over an * interface with a smaller MTU. * - Arriving GRO skb (or GSO skb in a virtualized environment) that is * bridged to a NETIF_F_TSO tunnel stacked over an interface with an * insufficent MTU. */ features = netif_skb_features(skb); BUILD_BUG_ON(sizeof(*IPCB(skb)) > SKB_SGO_CB_OFFSET); segs = skb_gso_segment(skb, features & ~NETIF_F_GSO_MASK); if (IS_ERR_OR_NULL(segs)) { kfree_skb(skb); return -ENOMEM; } consume_skb(skb); do { struct sk_buff *nskb = segs->next; int err; skb_mark_not_on_list(segs); err = ip_fragment(net, sk, segs, mtu, ip_finish_output2); if (err && ret == 0) ret = err; segs = nskb; } while (segs); return ret; }
tatic int ip_finish_output_gso(struct net *net, struct sock *sk, struct sk_buff *skb, unsigned int mtu) { netdev_features_t features; struct sk_buff *segs; int ret = 0; /* Slowpath - GSO segment length is exceeding the dst MTU. * * This can happen in two cases: * 1) TCP GRO packet, DF bit not set * 2) skb arrived via virtio-net, we thus get TSO/GSO skbs directly * from host network stack. */ features = netif_skb_features(skb); segs = skb_gso_segment(skb, features & ~NETIF_F_GSO_MASK); #这里最终会调用到 UDP 的 gso_segment 回调函数进行 UDP GSO 分段 if (IS_ERR_OR_NULL(segs)) { kfree_skb(skb); return -ENOMEM; } consume_skb(skb); do { struct sk_buff *nskb = segs->next; int err; segs->next = NULL; err = ip_fragment(net, sk, segs, mtu, ip_finish_output2); #需要的话,再进行 IP 分片,因为 UDP GSO 是按照 MSS 进行,MSS 还是有可能超过 IP 分段所使用的宿主机物理网卡 MTU 的 if (err && ret == 0) ret = err; segs = nskb; } while (segs); return ret;
Linux4.1.12源码分析
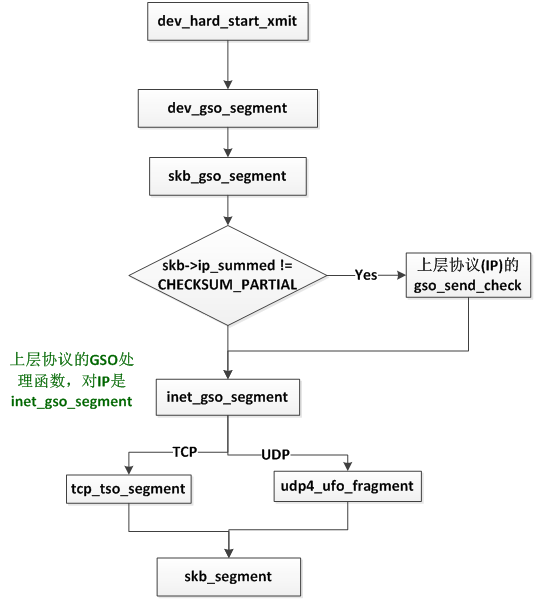
Linux 内核的 TSO 会在真正将skb发送到网卡前做GSO的检查:
对于真实硬件设备,是在sch_direct_xmit中调用validate_xmit_skb_list检查
对于虚拟设备,则是在__dev_queue_xmit中调用validate_xmit_skb检查
static int __dev_queue_xmit(struct sk_buff *skb, void *accel_priv) { struct net_device *dev = skb->dev; struct netdev_queue *txq; struct Qdisc *q; int rc = -ENOMEM; ...... txq = netdev_pick_tx(dev, skb, accel_priv); q = rcu_dereference_bh(txq->qdisc); ...... //该设备有对应的网卡队列,说明是真实网卡设备,在该队列上进行Qdisc调度,并发送skb if (q->enqueue) { rc = __dev_xmit_skb(skb, q, dev, txq); goto out; } /* The device has no queue. Common case for software devices: loopback, all the sorts of tunnels... Really, it is unlikely that netif_tx_lock protection is necessary here. (f.e. loopback and IP tunnels are clean ignoring statistics counters.) However, it is possible, that they rely on protection made by us here. Check this and shot the lock. It is not prone from deadlocks. Either shot noqueue qdisc, it is even simpler 8) */ //此处是虚拟设备 if (dev->flags & IFF_UP) { int cpu = smp_processor_id(); /* ok because BHs are off */ if (txq->xmit_lock_owner != cpu) { ....... //对于虚拟设备,同样检查GSO分段 skb = validate_xmit_skb(skb, dev); if (!skb) goto drop; HARD_TX_LOCK(dev, txq, cpu); if (!netif_xmit_stopped(txq)) { //实际发送到网卡设备 skb = dev_hard_start_xmit(skb, dev, txq, &rc); __this_cpu_dec(xmit_recursion); if (dev_xmit_complete(rc)) { HARD_TX_UNLOCK(dev, txq); goto out; } } HARD_TX_UNLOCK(dev, txq); ...... } else { ...... } } ...... return rc; }
int dev_hard_start_xmit(struct sk_buff *skb, struct net_device *dev, struct netdev_queue *txq) { const struct net_device_ops *ops = dev->netdev_ops; int rc; if (likely(!skb->next)) { if (!list_empty(&ptype_all)) dev_queue_xmit_nit(skb, dev); //判断网卡是否需要协议栈负责gso if (netif_needs_gso(dev, skb)) { //真正负责GSO操作的函数 if (unlikely(dev_gso_segment(skb))) goto out_kfree_skb; if (skb->next) goto gso; } //…… gso: do { //指向GSO分片后的一个skb struct sk_buff *nskb = skb->next; skb->next = nskb->next; nskb->next = NULL; if (dev->priv_flags & IFF_XMIT_DST_RELEASE) skb_dst_drop(nskb); //将通过GSO分片后的包逐个发出 rc = ops->ndo_start_xmit(nskb, dev); if (unlikely(rc != NETDEV_TX_OK)) { nskb->next = skb->next; skb->next = nskb; return rc; } txq_trans_update(txq); if (unlikely(netif_tx_queue_stopped(txq) && skb->next)) return NETDEV_TX_BUSY; } while (skb->next); skb->destructor = DEV_GSO_CB(skb)->destructor; out_kfree_skb: kfree_skb(skb); return NETDEV_TX_OK; }
报文GSO分段的入口函数是skb_gso_segment函数,是在validate_xmit_skb函数中被调用。
__dev_queue_xmit
┣━validate_xmit_skb
┣━skb_gso_segment
┣━__skb_gso_segment
┣━skb_mac_gso_segment
struct sk_buff *skb_mac_gso_segment(struct sk_buff *skb, netdev_features_t features) { struct sk_buff *segs = ERR_PTR(-EPROTONOSUPPORT); struct packet_offload *ptype; int vlan_depth = skb->mac_len; //__skb_gso_segment函数中计算得到 __be16 type = skb_network_protocol(skb, &vlan_depth); //得到skb协议 if (unlikely(!type)) return ERR_PTR(-EINVAL); __skb_pull(skb, vlan_depth); //skb data指针移动到IP头 rcu_read_lock(); list_for_each_entry_rcu(ptype, &offload_base, list) { if (ptype->type == type && ptype->callbacks.gso_segment) { segs = ptype->callbacks.gso_segment(skb, features); //调用IP层的GSO segment函数 break; } } rcu_read_unlock(); __skb_push(skb, skb->data - skb_mac_header(skb)); //skb data指针移动到MAC头 return segs;
MAC层的GSO分段,主要初始化了SKB_GSO_CB(skb)对象的数据供后续使用,然后指向IP头并调用IP层的GSO segment函数。
二层报文发送之报文GSO分段(IP层)
IP层的GSO/GRO定义在ip_packet_offload结构体中。
static struct packet_offload ip_packet_offload __read_mostly = { .type = cpu_to_be16(ETH_P_IP), .callbacks = { .gso_segment = inet_gso_segment, //gso分段函数 .gro_receive = inet_gro_receive, //gro收包函数 .gro_complete = inet_gro_complete, }, }; ————————————————
inet_gso_segment函数
static struct sk_buff *inet_gso_segment(struct sk_buff *skb, netdev_features_t features) { struct sk_buff *segs = ERR_PTR(-EINVAL); const struct net_offload *ops; unsigned int offset = 0; bool udpfrag, encap; struct iphdr *iph; int proto; int nhoff; int ihl; int id; if (unlikely(skb_shinfo(skb)->gso_type & ~(SKB_GSO_TCPV4 | SKB_GSO_UDP | SKB_GSO_DODGY | SKB_GSO_TCP_ECN | SKB_GSO_GRE | SKB_GSO_GRE_CSUM | SKB_GSO_IPIP | SKB_GSO_SIT | SKB_GSO_TCPV6 | SKB_GSO_UDP_TUNNEL | SKB_GSO_UDP_TUNNEL_CSUM | SKB_GSO_TUNNEL_REMCSUM | 0))) goto out; skb_reset_network_header(skb); nhoff = skb_network_header(skb) - skb_mac_header(skb); //根据network header和mac header得到IP头相对MAC的偏移 if (unlikely(!pskb_may_pull(skb, sizeof(*iph)))) //检测skb是否可以移动到L4头? goto out; iph = ip_hdr(skb); ihl = iph->ihl * 4; //得到IP包头的实际长度,基于此可以得到L4的首地址 if (ihl < sizeof(*iph)) goto out; id = ntohs(iph->id); proto = iph->protocol; //L4层协议类型 /* Warning: after this point, iph might be no longer valid */ if (unlikely(!pskb_may_pull(skb, ihl))) //检测skb是否可以移动到L4头? goto out; __skb_pull(skb, ihl); //报文data指针移动到传输层 encap = SKB_GSO_CB(skb)->encap_level > 0; if (encap) features &= skb->dev->hw_enc_features; //如果encap,那么feature与hw_enc_features取交集 SKB_GSO_CB(skb)->encap_level += ihl; //用来标示是否为内层报文 skb_reset_transport_header(skb); //设置transport header值 segs = ERR_PTR(-EPROTONOSUPPORT); if (skb->encapsulation && skb_shinfo(skb)->gso_type & (SKB_GSO_SIT|SKB_GSO_IPIP)) udpfrag = proto == IPPROTO_UDP && encap; else udpfrag = proto == IPPROTO_UDP && !skb->encapsulation; //vxlan封装报文走此分支,此时udpfrag为false ops = rcu_dereference(inet_offloads[proto]); if (likely(ops && ops->callbacks.gso_segment)) segs = ops->callbacks.gso_segment(skb, features); //UDP或TCP的分段函数 if (IS_ERR_OR_NULL(segs)) goto out; skb = segs; do { iph = (struct iphdr *)(skb_mac_header(skb) + nhoff); //根据分段报文的mac header 和 IP偏移 if (udpfrag) { //ip分片报文 iph->id = htons(id); iph->frag_off = htons(offset >> 3); //设置ip头的frag_off值 if (skb->next) iph->frag_off |= htons(IP_MF); //后面还有报文,需要设置more frag标记 offset += skb->len - nhoff - ihl; //计算offset值,下一个报文需要使用 } else { iph->id = htons(id++); //每个报文为完整的IP报文 } iph->tot_len = htons(skb->len - nhoff); ip_send_check(iph); //计算ip头 csum值 if (encap) //如果encap值非空,说明当前处于内层报文中,所以需要设置inner heaer值 skb_reset_inner_headers(skb); skb->network_header = (u8 *)iph - skb->head; //设置network header } while ((skb = skb->next)); out: return segs; }
static struct sk_buff *inet_gso_segment(struct sk_buff *skb, int features) { struct sk_buff *segs = ERR_PTR(-EINVAL); struct iphdr *iph; const struct net_protocol *ops; int proto; int ihl; int id; unsigned int offset = 0; if (!(features & NETIF_F_V4_CSUM)) features &= ~NETIF_F_SG; //校验待软GSO分段的的skb,其gso_tpye是否存在其他非法值 if (unlikely(skb_shinfo(skb)->gso_type & ~(SKB_GSO_TCPV4 | SKB_GSO_UDP | SKB_GSO_DODGY | SKB_GSO_TCP_ECN | 0))) goto out; //分段数据至少大于IP首部长度 if (unlikely(!pskb_may_pull(skb, sizeof(*iph)))) goto out; //检验首部中的长度字段是否有效 iph = ip_hdr(skb); ihl = iph->ihl * 4; if (ihl < sizeof(*iph)) goto out; //再次通过首部中的长度字段检测skb长度是否有效 if (unlikely(!pskb_may_pull(skb, ihl))) goto out; //注意:这里已经将data偏移到了传送层头部了,去掉了IP头 __skb_pull(skb, ihl); skb_reset_transport_header(skb);//设置传输层头部位置 iph = ip_hdr(skb); id = ntohs(iph->id);//取出首部中的id字段 proto = iph->protocol & (MAX_INET_PROTOS - 1);//取出IP首部的协议值,用于定位与之对应的传输层接口(tcp还是udp) segs = ERR_PTR(-EPROTONOSUPPORT); rcu_read_lock(); ops = rcu_dereference(inet_protos[proto]);//根据协议字段取得上层的协议接口 if (likely(ops && ops->gso_segment)) segs = ops->gso_segment(skb, features);//调用上册协议的GSO处理函数 rcu_read_unlock(); if (!segs || IS_ERR(segs)) goto out; //开始处理分段后的skb skb = segs; do { iph = ip_hdr(skb); if (proto == IPPROTO_UDP) {//对于UDP进行的IP分片的头部处理逻辑 iph->id = htons(id);//所有UDP的IP分片id都相同 iph->frag_off = htons(offset >> 3);//ip头部偏移字段单位为8字节 if (skb->next != NULL) iph->frag_off |= htons(IP_MF);//设置分片标识 offset += (skb->len - skb->mac_len - iph->ihl * 4); } else iph->id = htons(id++);//对于TCP报,分片后IP头部中id加1 iph->tot_len = htons(skb->len - skb->mac_len); iph->check = 0; //计算校验和,只是IP头部的 iph->check = ip_fast_csum(skb_network_header(skb), iph->ihl); } while ((skb = skb->next)); out: return segs; }
这里有个问题,UDP经过GSO分片后每个分片的IP头部id是一样的,这个符合IP分片的逻辑,但是为什么TCP的GSO分片,IP头部的id会依次加1呢?原因是: tcp建立三次握手的过程中产生合适的mss(具体的处理机制参见TCP/IP详解P257),这个mss肯定是<=网络层的最大路径MTU,然后tcp数据封装成ip数据包通过网络层发送,当服务器端传输层接收到tcp数据之后进行tcp重组。所以正常情况下tcp产生的ip数据包在传输过程中是不会发生分片的!由于GSO应该保证对外透明,所以其效果应该也和在TCP层直接分片的效果是一样的,所以这里对UDP的处理是IP分片逻辑,但对TCP的处理是构造新的skb逻辑。
l 小结:对于GSO
UDP:所有分片ip头部id都相同,设置IP_MF分片标志(除最后一片) (等同于IP分片)
TCP:分片后,每个分片IP头部中id加1, (等同于TCP分段)
二层报文发送之报文GSO分段(UDP)
UDP报文GSO分段的入口函数是udp4_ufo_fragment,由udpv4_offload常量中定义。
1、udp4_ufo_fragment函数
--------> skb_segment
static struct sk_buff *udp4_ufo_fragment(struct sk_buff *skb, netdev_features_t features) { struct sk_buff *segs = ERR_PTR(-EINVAL); unsigned int mss; __wsum csum; struct udphdr *uh; struct iphdr *iph; if (skb->encapsulation && (skb_shinfo(skb)->gso_type & (SKB_GSO_UDP_TUNNEL|SKB_GSO_UDP_TUNNEL_CSUM))) { segs = skb_udp_tunnel_segment(skb, features, false); //封装报文的GSO分段,可以基于内层报文进行GSO分段 goto out; } if (!pskb_may_pull(skb, sizeof(struct udphdr))) goto out; mss = skb_shinfo(skb)->gso_size; if (unlikely(skb->len <= mss)) goto out; if (skb_gso_ok(skb, features | NETIF_F_GSO_ROBUST)) { /* Packet is from an untrusted source, reset gso_segs. */ int type = skb_shinfo(skb)->gso_type; if (unlikely(type & ~(SKB_GSO_UDP | SKB_GSO_DODGY | SKB_GSO_UDP_TUNNEL | SKB_GSO_UDP_TUNNEL_CSUM | SKB_GSO_TUNNEL_REMCSUM | SKB_GSO_IPIP | SKB_GSO_GRE | SKB_GSO_GRE_CSUM) || !(type & (SKB_GSO_UDP)))) goto out; skb_shinfo(skb)->gso_segs = DIV_ROUND_UP(skb->len, mss); //如果报文来源不可信,则重新计算segs,返回 segs = NULL; goto out; } /* Do software UFO. Complete and fill in the UDP checksum as * HW cannot do checksum of UDP packets sent as multiple * IP fragments. */ uh = udp_hdr(skb); iph = ip_hdr(skb); uh->check = 0; csum = skb_checksum(skb, 0, skb->len, 0); //计算csum值 uh->check = udp_v4_check(skb->len, iph->saddr, iph->daddr, csum); //计算udp头的check值 if (uh->check == 0) uh->check = CSUM_MANGLED_0; skb->ip_summed = CHECKSUM_NONE; /* Fragment the skb. IP headers of the fragments are updated in * inet_gso_segment() */ segs = skb_segment(skb, features); //报文根据mss进行分段,因为包含UDP头,所以分段的结果是IP分片报文 out: return segs; }
skb_udp_tunnel_segment函数
struct sk_buff *skb_udp_tunnel_segment(struct sk_buff *skb, netdev_features_t features, bool is_ipv6) { __be16 protocol = skb->protocol; const struct net_offload **offloads; const struct net_offload *ops; struct sk_buff *segs = ERR_PTR(-EINVAL); struct sk_buff *(*gso_inner_segment)(struct sk_buff *skb, netdev_features_t features); rcu_read_lock(); switch (skb->inner_protocol_type) { //vxlan封装时,该值为ENCAP_TYPE_ETHER case ENCAP_TYPE_ETHER: protocol = skb->inner_protocol; gso_inner_segment = skb_mac_gso_segment; //vxlan封装,内层报文为完整的报文(二层、三层、四层),继续从mac开始分段 break; case ENCAP_TYPE_IPPROTO: offloads = is_ipv6 ? inet6_offloads : inet_offloads; ops = rcu_dereference(offloads[skb->inner_ipproto]); if (!ops || !ops->callbacks.gso_segment) goto out_unlock; gso_inner_segment = ops->callbacks.gso_segment; //调用4层协议的GSO分段能力,GRE/IPIP等等 break; default: goto out_unlock; } segs = __skb_udp_tunnel_segment(skb, features, gso_inner_segment, //upd封装报文GSO分段 protocol, is_ipv6); out_unlock: rcu_read_unlock(); return segs;
__skb_udp_tunnel_segment函数
static struct sk_buff *__skb_udp_tunnel_segment(struct sk_buff *skb, netdev_features_t features, struct sk_buff *(*gso_inner_segment)(struct sk_buff *skb, netdev_features_t features), __be16 new_protocol, bool is_ipv6) { struct sk_buff *segs = ERR_PTR(-EINVAL); u16 mac_offset = skb->mac_header; int mac_len = skb->mac_len; int tnl_hlen = skb_inner_mac_header(skb) - skb_transport_header(skb); //vxlan头长度 UDP + vxlan, __be16 protocol = skb->protocol; netdev_features_t enc_features; int udp_offset, outer_hlen; unsigned int oldlen; bool need_csum = !!(skb_shinfo(skb)->gso_type & SKB_GSO_UDP_TUNNEL_CSUM); bool remcsum = !!(skb_shinfo(skb)->gso_type & SKB_GSO_TUNNEL_REMCSUM); bool offload_csum = false, dont_encap = (need_csum || remcsum); oldlen = (u16)~skb->len; if (unlikely(!pskb_may_pull(skb, tnl_hlen))) goto out; skb->encapsulation = 0; __skb_pull(skb, tnl_hlen); //报文移动到内层报文的MAC头 skb_reset_mac_header(skb); //设置skb的mac header skb_set_network_header(skb, skb_inner_network_offset(skb)); //设置skb的 ip header skb->mac_len = skb_inner_network_offset(skb); //设置skb mac len skb->protocol = new_protocol; //设置skb protocol,至此skb已经切换到内层,可以继续进行GSO分段 skb->encap_hdr_csum = need_csum; skb->remcsum_offload = remcsum; /* Try to offload checksum if possible */ offload_csum = !!(need_csum && (skb->dev->features & (is_ipv6 ? NETIF_F_V6_CSUM : NETIF_F_V4_CSUM))); /* segment inner packet. */ enc_features = skb->dev->hw_enc_features & features; segs = gso_inner_segment(skb, enc_features); //如果是vxlan报文,则重新开始mac层的GSO分段 if (IS_ERR_OR_NULL(segs)) { skb_gso_error_unwind(skb, protocol, tnl_hlen, mac_offset, mac_len); goto out; } outer_hlen = skb_tnl_header_len(skb); //计算外层报文的长度 udp_offset = outer_hlen - tnl_hlen; //外层UDP头的偏移 skb = segs; //此时skb指向内层报文的mac头位置 do { struct udphdr *uh; int len; __be32 delta; if (dont_encap) { skb->encapsulation = 0; skb->ip_summed = CHECKSUM_NONE; } else { /* Only set up inner headers if we might be offloading * inner checksum. */ skb_reset_inner_headers(skb); //此时skb指向内层报文,可以建立inner header值 skb->encapsulation = 1; } skb->mac_len = mac_len; skb->protocol = protocol; skb_push(skb, outer_hlen); //skb移到外层报文的mac头 skb_reset_mac_header(skb); //设置mac header skb_set_network_header(skb, mac_len); //设置network header,ip层需要 skb_set_transport_header(skb, udp_offset); //设置transport header len = skb->len - udp_offset; uh = udp_hdr(skb); //找到UDP头很重要,GSO分段后,有些数据需要刷新,包括长度等 uh->len = htons(len); if (!need_csum) continue; delta = htonl(oldlen + len); uh->check = ~csum_fold((__force __wsum) ((__force u32)uh->check + (__force u32)delta)); if (offload_csum) { skb->ip_summed = CHECKSUM_PARTIAL; skb->csum_start = skb_transport_header(skb) - skb->head; //重新计算csum值,位置更新了 skb->csum_offset = offsetof(struct udphdr, check); } else if (remcsum) { /* Need to calculate checksum from scratch, * inner checksums are never when doing * remote_checksum_offload. */ skb->csum = skb_checksum(skb, udp_offset, //软件计算csum值 skb->len - udp_offset, 0); uh->check = csum_fold(skb->csum); if (uh->check == 0) uh->check = CSUM_MANGLED_0; } else { uh->check = gso_make_checksum(skb, ~uh->check); //计算伪头check值 if (uh->check == 0) uh->check = CSUM_MANGLED_0; } } while ((skb = skb->next)); out: return segs; }
udp4_ufo_fragment提升了对vxlan等封装报文的支持,对GSO报文封装后报文的能够正确GSO分段,而不会产生IP分片报文。 实现这个功能,离不开skb_segment函数的支持,能够复制外层报文头而不管有多长,所以只要少量修改,内核能够支持多层封装的GSO分段。
UDP encapsulation offload
对于UDP encapsulation packet,不会对外层UDP进行分片,只会对根据PMTU对内层packet进行分片。
GSO for UDP encapsulation packet
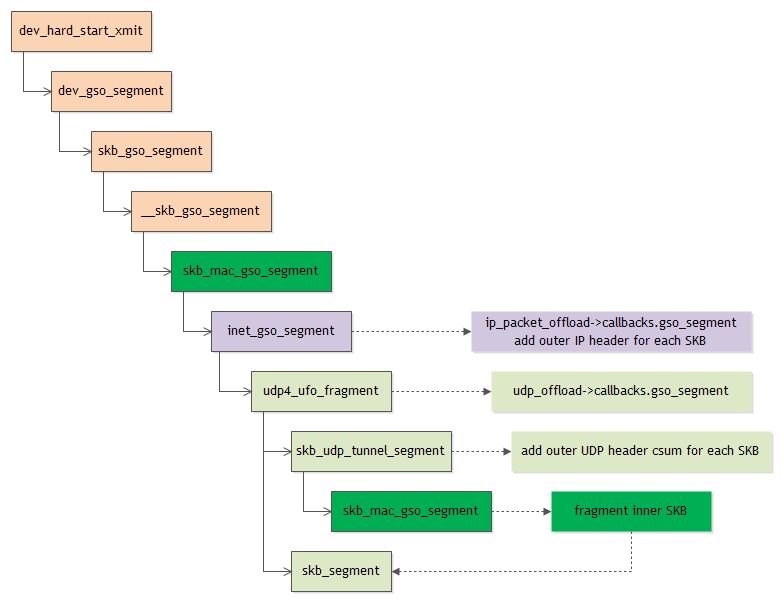
详细过程参考ixgbe.
VXLAN example
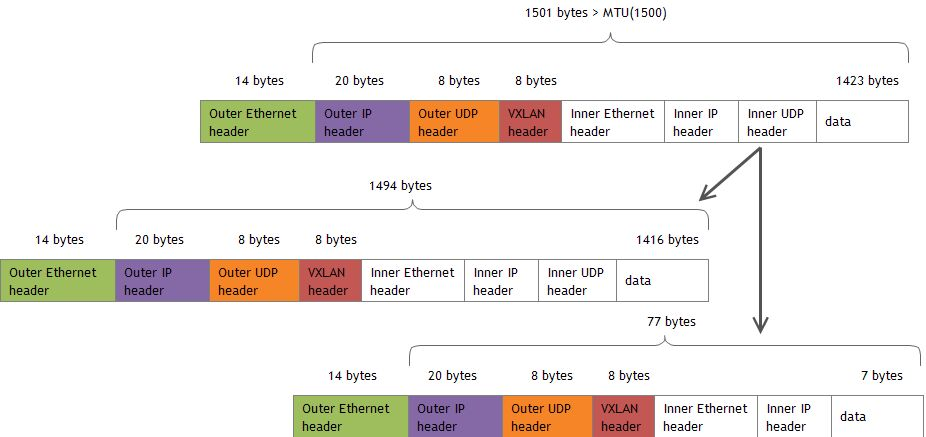
对于VXLAN,有50字节的额外开销:Outer L2 header(14 bytes) + Outer L3 header(20 bytes) + Outer UDP header(8 bytes) + VXLAN header(8 bytes)。如果underlay network的MTU为1500,需要将VXLAN设备的MTU设置为1450。
如果基于VXLAN发送一个1422字节(1450 - 20 - 8)的UDP包,内层UDP包不会发生分片: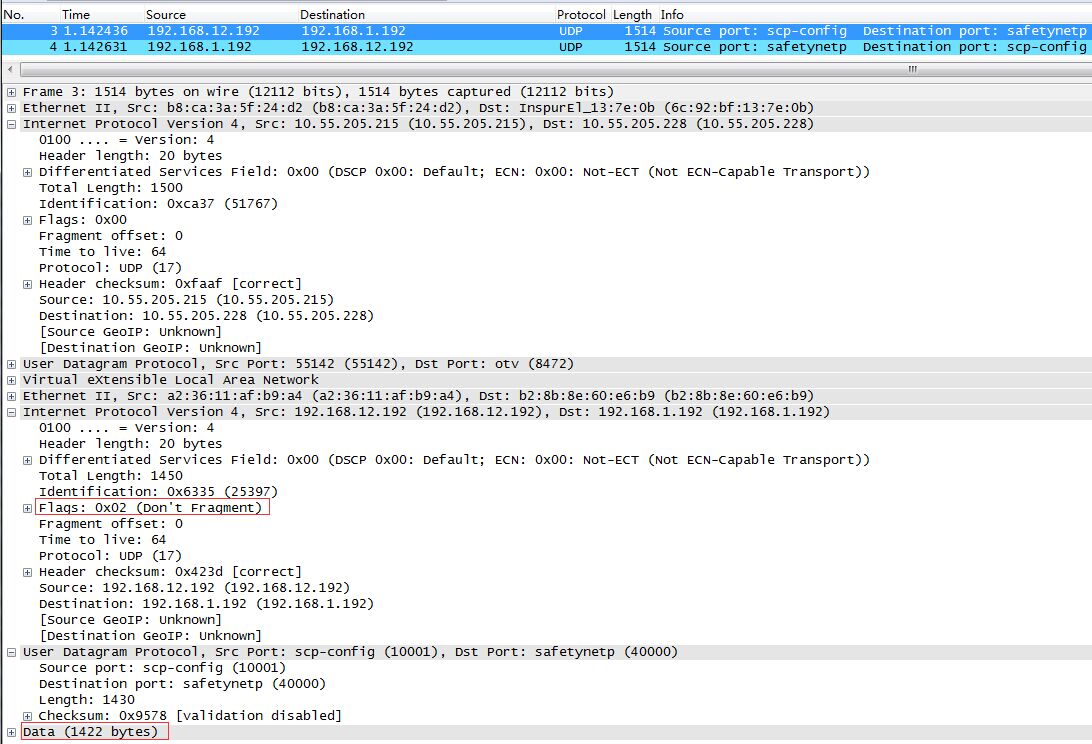
如果发送一个1423字节的UDP包,我们就会观察内层UDP包发生分片: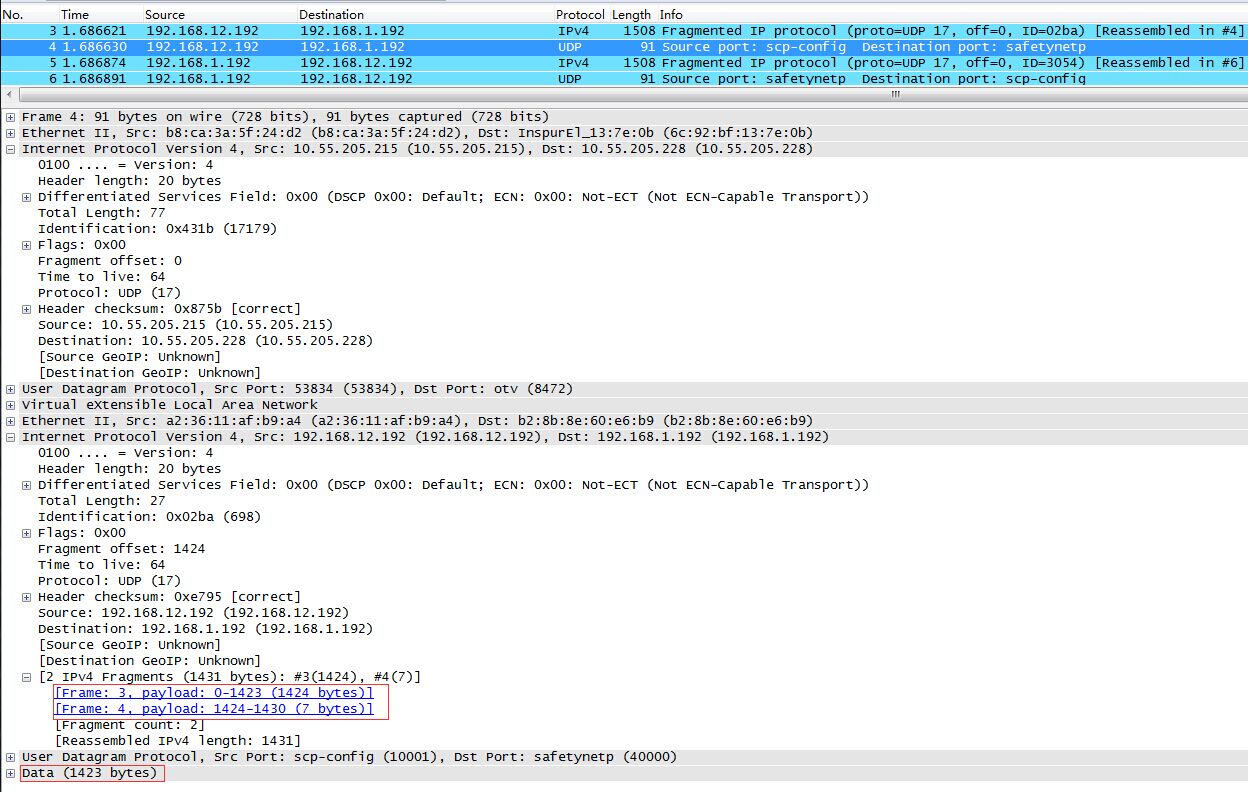
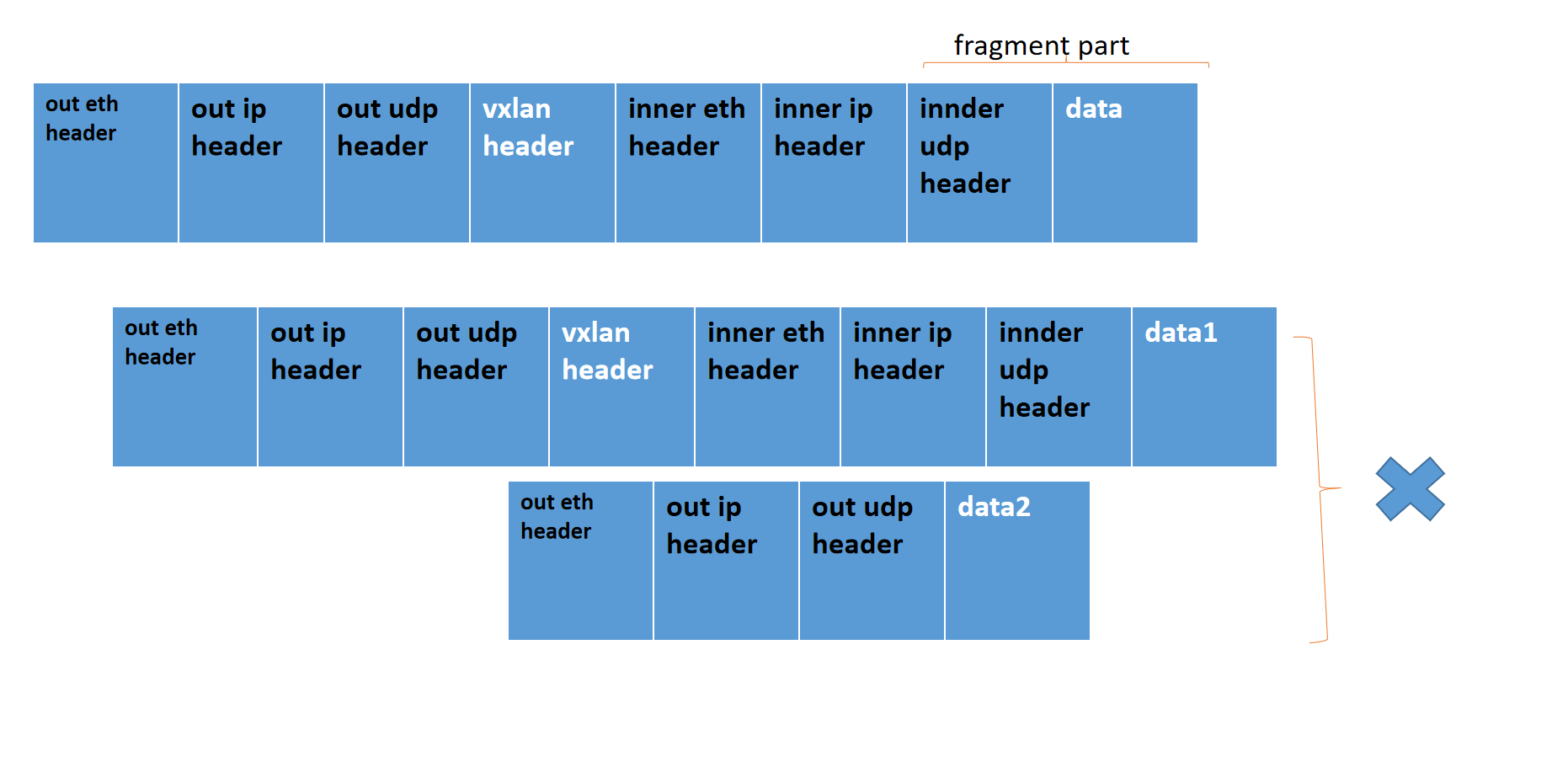
** 值得注意的是,第1个frame只有1508字节,也就是说只包含1416字节的用户数据,第2个frame包含剩下的7个字节。(原因呢???) **
总结
| Offload | 传输段还是接收端 | 针对的协议 | Offloading 的位置 | ethtool 命令输出中的项目 | ethtool 命令中的 option | 网卡/Linux 内核支持情况 |
| TSO | 传输段 | TCP | NIC | tcp-segmentation-offload | tso |
Linux 内核从 2.5.33 引入 (2002) 网卡普遍支持 |
| UFO | 传输段 | UDP | NIC | udp-fragmentation-offload | ufo |
linux 2.6.15 引入 (2006) 网卡普遍不支持 |
| GSO | 传输段 | TCP/UDP | NIC 或者 离开 IP 协议栈进入网卡驱动之前 | generic-segmentation-offload | gso |
GSO/TCP: Linux 2.6.18 中引入(2006) GSO/UDP: linux 3.16 (2014) |
| LRO | 接收段 | TCP | NIC | large-receive-offload | lro |
Linux 内核 2.6.24 引入(2008) 网卡普遍支持 |
| GRO | 接收段 | TCP | NIC 或者离开网卡驱动进入 IP 协议栈之前 | generic-receive-offload | gro |
Linux 内核 2.6.18 引入(2006) 网卡普遍支持 |
linux 2.6.32源码分析
http://blog.chinaunix.net/uid-28541347-id-5763781.html
Linux4.1.12源码分析
https://blog.csdn.net/one_clouder/article/details/52771550?utm_source=blogxgwz1&utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-0&spm=1001.2101.3001.4242
Linux环境中的网络分段卸载技术 GSO/TSO/UFO/LRO/GRO
https://rtoax.blog.csdn.net/article/details/108748689


 浙公网安备 33010602011771号
浙公网安备 33010602011771号