Day 16 16.4 案例分析之对比单线程与多线程
线程案例:爬取斗图吧表情包图片
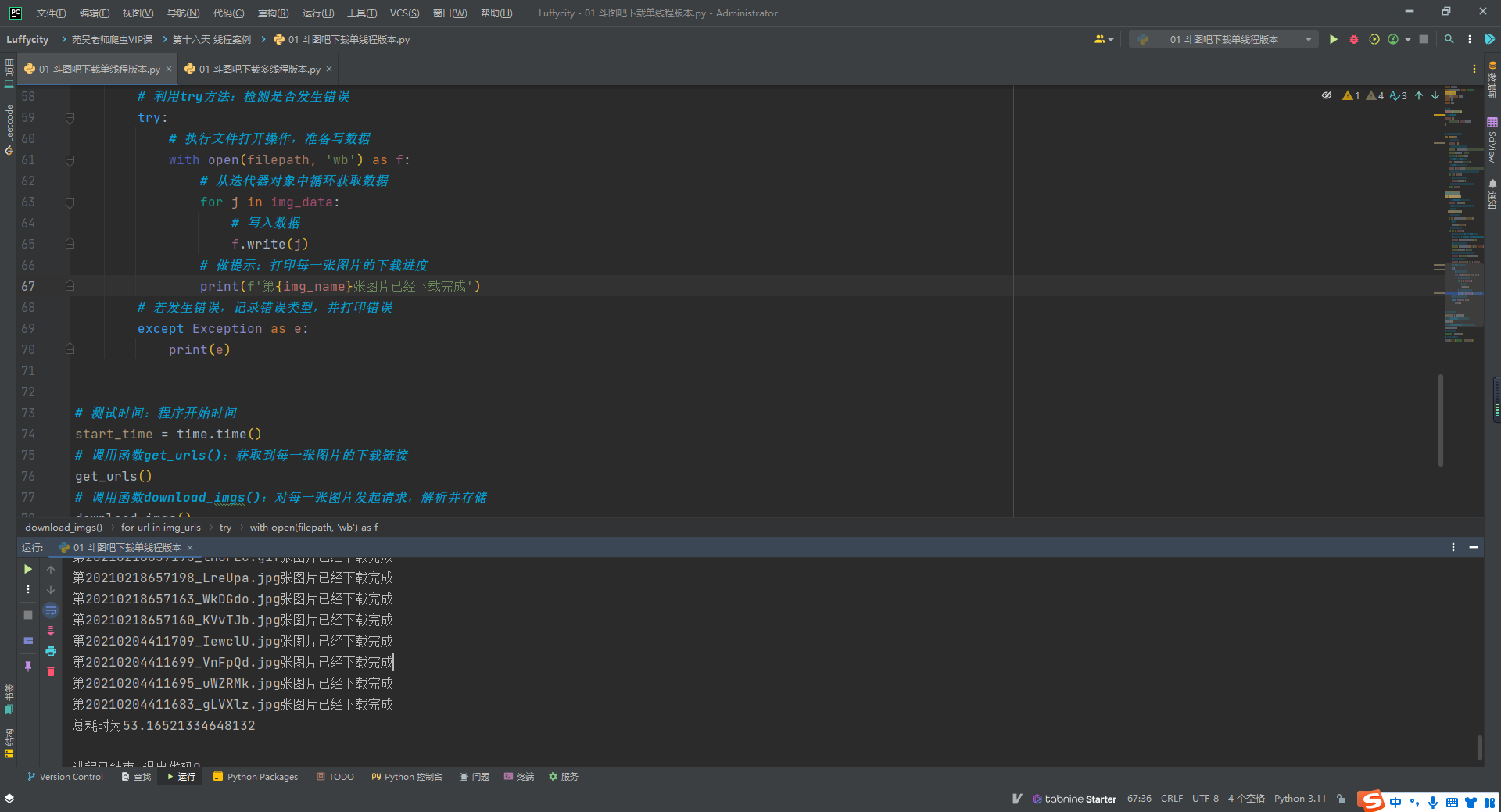
方案一:单线程版本
- 耗时慢
import requests
from fake_useragent import UserAgent
import random
from lxml import etree
import os
import time
# 伪装UA
fake_ua = UserAgent()
# 请求头:headers
headers = {
'User-Agent': fake_ua.random
}
# 定义函数:请求并解析到每一张图片的网址
def get_urls():
# 存放所有的图片下载网址
img_urls = []
# 发起请求:对目标网址发起请求,获取到响应数据
response = requests.get('https://www.pkdoutu.com/photo/list/', headers=headers)
response.encoding = 'utf8'
page_text = response.text
# 实例化etree对象:为xpath解析做准备
tree = etree.HTML(page_text)
# 利用xpath方法提取到每一张图片的下载网址
img_src = tree.xpath('//*[@id="pic-detail"]/div/div[2]/div[2]/ul/li/div/div/a/img[@data-backup]/@data-backup')
# 本次请求请求到的是所有的图片下载网址,循环存储每一张图片的网址到网址列表里
for i in img_src:
# 将每一张图片的网址添加到网址列表里
img_urls.append(i)
# 返回对象:为下一个请求本函数的函数提供数据。返回图片网址列表
return img_urls
#定义函数:解析并对每一张图片做存储
def download_imgs():
# 获取到get_urls()函数所得到的图片网址列表
img_urls = get_urls()
# 利用OS模块进行文件夹操作:即判断是否存在某个文件夹,无则创建
# 定义文件夹名称
filename = 'imgs'
# 判断该路径下是否存在文件夹
if not os.path.exists(filename):
# 无则创建
os.mkdir(filename)
# 将图片列表里的网址循环调取出来
for url in img_urls:
# 命名每一张图片的文件名:利用OS模块,返回path的最后文件名
# 该方法也可等同于 : img_name = url.spilt('/')[-1]
img_name = os.path.basename(url)
# 对每一张图片的网址发起请求并做解析
response = requests.get(url=url, headers=headers)
response.encoding = 'utf8'
# 图片数据过大时可采用迭代器对象方法,循环存储较大的数据
img_data = response.iter_content()
# 定义文件路径,为写入数据做准备
filepath = filename + '/' + img_name
# 利用try方法:检测是否发生错误
try:
# 执行文件打开操作,准备写数据
with open(filepath, 'wb') as f:
# 从迭代器对象中循环获取数据
for j in img_data:
# 写入数据
f.write(j)
# 做提示:打印每一张图片的下载进度
print(f'第{img_name}张图片已经下载完成')
# 若发生错误,记录错误类型,并打印错误
except Exception as e:
print(e)
# 测试时间:程序开始时间
start_time = time.time()
# 调用函数get_urls():获取到每一张图片的下载链接
get_urls()
# 调用函数download_imgs():对每一张图片发起请求,解析并存储
download_imgs()
# 测试时间:程序结束时间
end_time = time.time()
# 计算时间:结束时间-开始时间
print(f'总耗时为{end_time - start_time}')
#总耗时为53.16521334648132
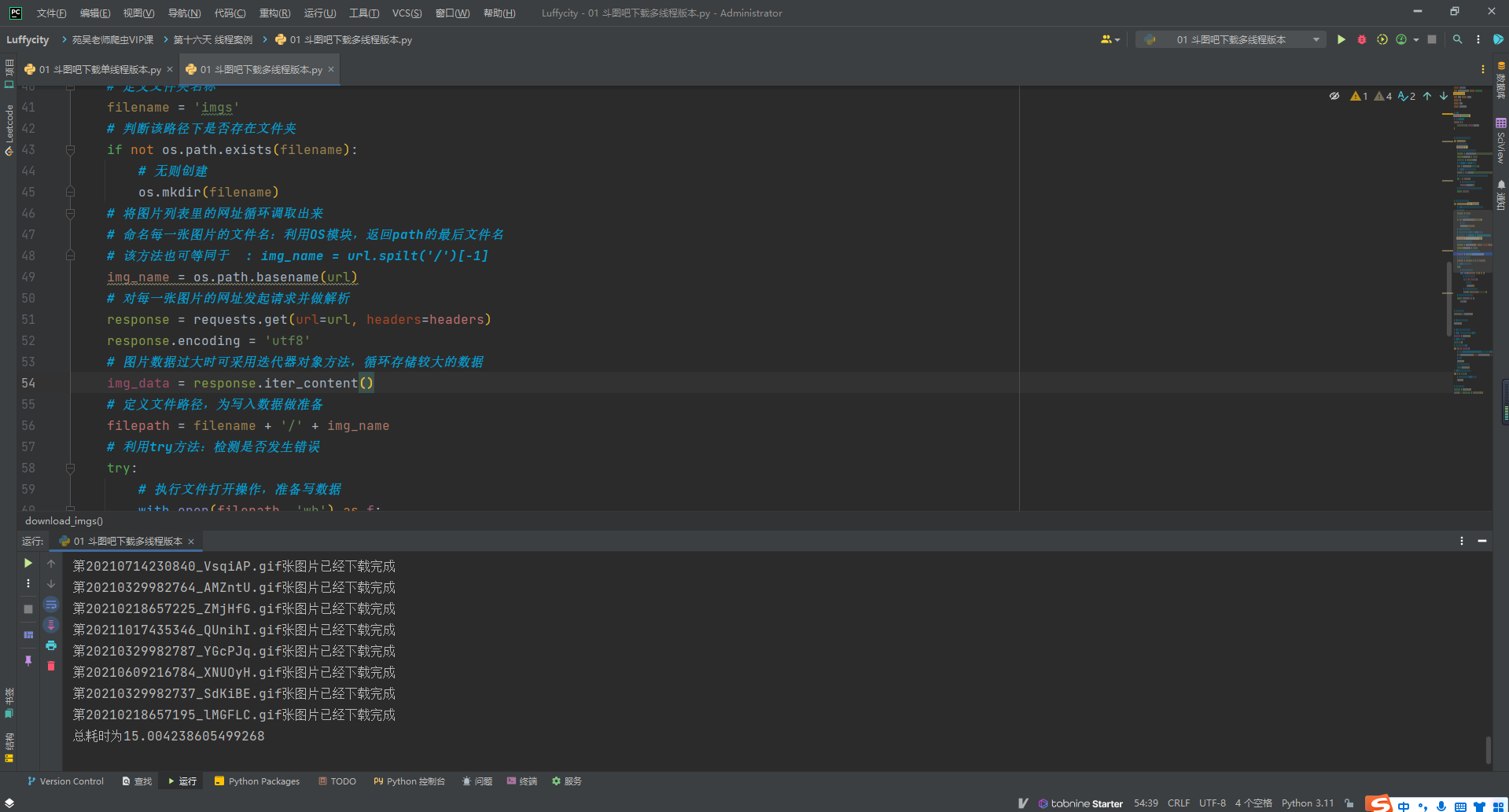
方案二:多线程版本
- 速度快
import requests
from fake_useragent import UserAgent
import random
from lxml import etree
import os
import time
import threading
# 伪装UA
fake_ua = UserAgent()
# 请求头:headers
headers = {
'User-Agent': fake_ua.random
}
# 定义函数:请求并解析到每一张图片的网址
def get_urls():
# 存放所有的图片下载网址
img_urls = []
# 发起请求:对目标网址发起请求,获取到响应数据
response = requests.get('https://www.pkdoutu.com/photo/list/', headers=headers)
response.encoding = 'utf8'
page_text = response.text
# 实例化etree对象:为xpath解析做准备
tree = etree.HTML(page_text)
# 利用xpath方法提取到每一张图片的下载网址
img_src = tree.xpath('//*[@id="pic-detail"]/div/div[2]/div[2]/ul/li/div/div/a/img[@data-backup]/@data-backup')
# 本次请求请求到的是所有的图片下载网址,循环存储每一张图片的网址到网址列表里
for i in img_src:
# 将每一张图片的网址添加到网址列表里
img_urls.append(i)
# 返回对象:为下一个请求本函数的函数提供数据。返回图片网址列表
return img_urls
# 定义函数:解析并对每一张图片做存储
def download_imgs(url):
# 利用OS模块进行文件夹操作:即判断是否存在某个文件夹,无则创建
# 定义文件夹名称
filename = 'imgs'
# 判断该路径下是否存在文件夹
if not os.path.exists(filename):
# 无则创建
os.mkdir(filename)
# 将图片列表里的网址循环调取出来
# 命名每一张图片的文件名:利用OS模块,返回path的最后文件名
# 该方法也可等同于 : img_name = url.spilt('/')[-1]
img_name = os.path.basename(url)
# 对每一张图片的网址发起请求并做解析
response = requests.get(url=url, headers=headers)
response.encoding = 'utf8'
# 图片数据过大时可采用迭代器对象方法,循环存储较大的数据
img_data = response.iter_content()
# 定义文件路径,为写入数据做准备
filepath = filename + '/' + img_name
# 利用try方法:检测是否发生错误
try:
# 执行文件打开操作,准备写数据
with open(filepath, 'wb') as f:
# 从迭代器对象中循环获取数据
for j in img_data:
# 写入数据
f.write(j)
# 做提示:打印每一张图片的下载进度
print(f'第{img_name}张图片已经下载完成')
# 若发生错误,记录错误类型,并打印错误
except Exception as e:
print(e)
# 测试时间:程序开始时间
start_time = time.time()
# (1)获取图片网址并存储到列表里
get_urls()
# (2)对每一张图片发起请求,解析并存储
# (2.1) 需要提交参数,获取到下载图片的url列表
img_urls = get_urls()
# (2.2)存放线程的列表
t_list = []
# 循环获取每一个下载图片的url
for url in img_urls:
# 建立线程:threading.Thread(target=需要运行的程序名, args=(给需要运行的程序提交的参数,))
t = threading.Thread(target=download_imgs, args=(url,))
# 开始线程
t.start()
# 将开始的线程加入到线程列表里
t_list.append(t)
# (2.3)循环获取每一个需要运行的线程
for t in t_list:
# 开始线程,多线程并发,利用join方法阻塞线程
t.join()
# 测试时间:程序结束时间
end_time = time.time()
print(f'总耗时为{end_time - start_time}')
#总耗时为15.004238605499268
本文来自博客园,作者:Chimengmeng,转载请注明原文链接:https://www.cnblogs.com/dream-ze/p/17218113.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号