案例分享:爬取17k小说网小说
目的要求:
- 爬取17k小说网,自己书架内的小说并做每一章节的存储
分析思路
- 1、顺利进入自己的书架
- 2、爬取到书架里的全部书籍名字及详细链接
- 3、通过访问书籍详细链接,获取每一章的链接
- 4、访问每一章的链接获取到章节标题和内容
- 5、打开文件进行存储
具体流程
1、分析目标网址
- 首先分析目标网址:https://www.17k.com/
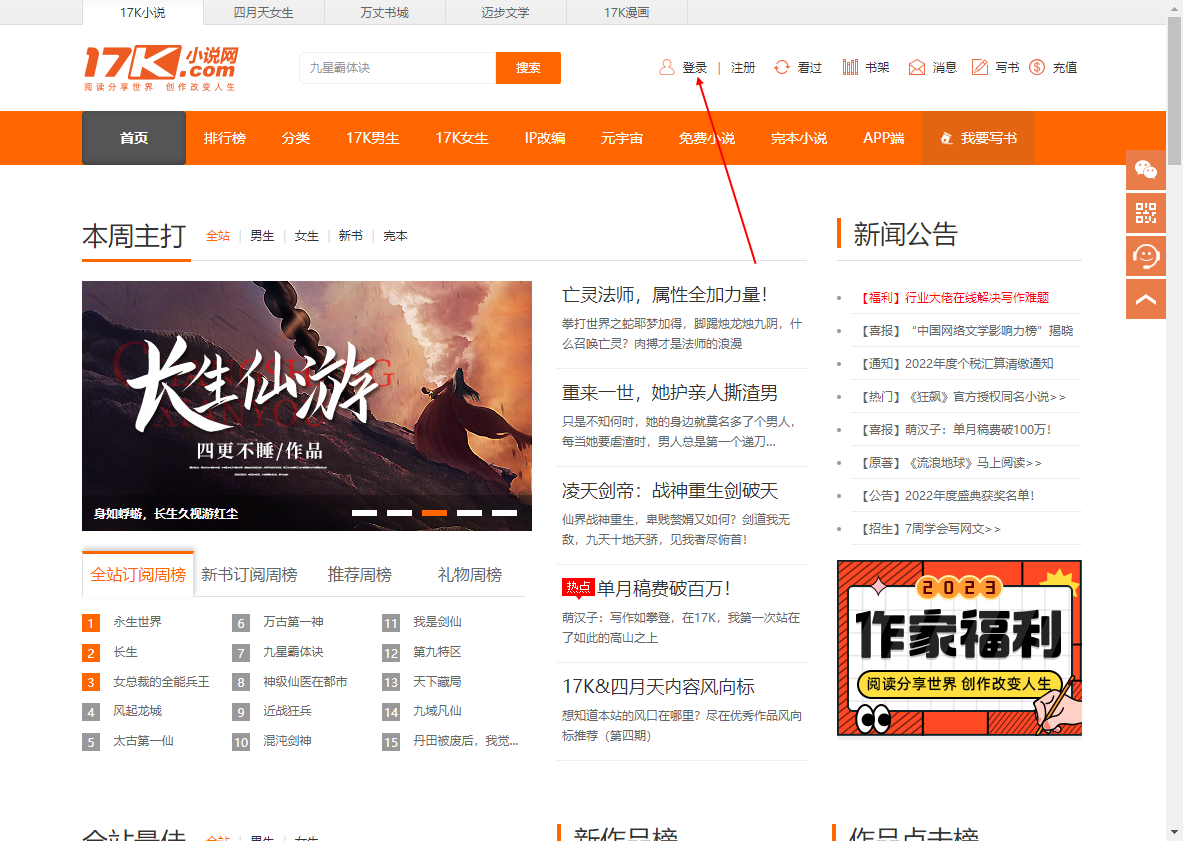
- 发现需要登陆(注册):正常的requests请求无法获得我们想要的数据
2、分析问题
-
思考:如何解决跳过验证?
- 利用浏览器返回的cookie,在headers中进行伪装
- 在登陆界面登录的同时打开开发者模式并找到network选项卡
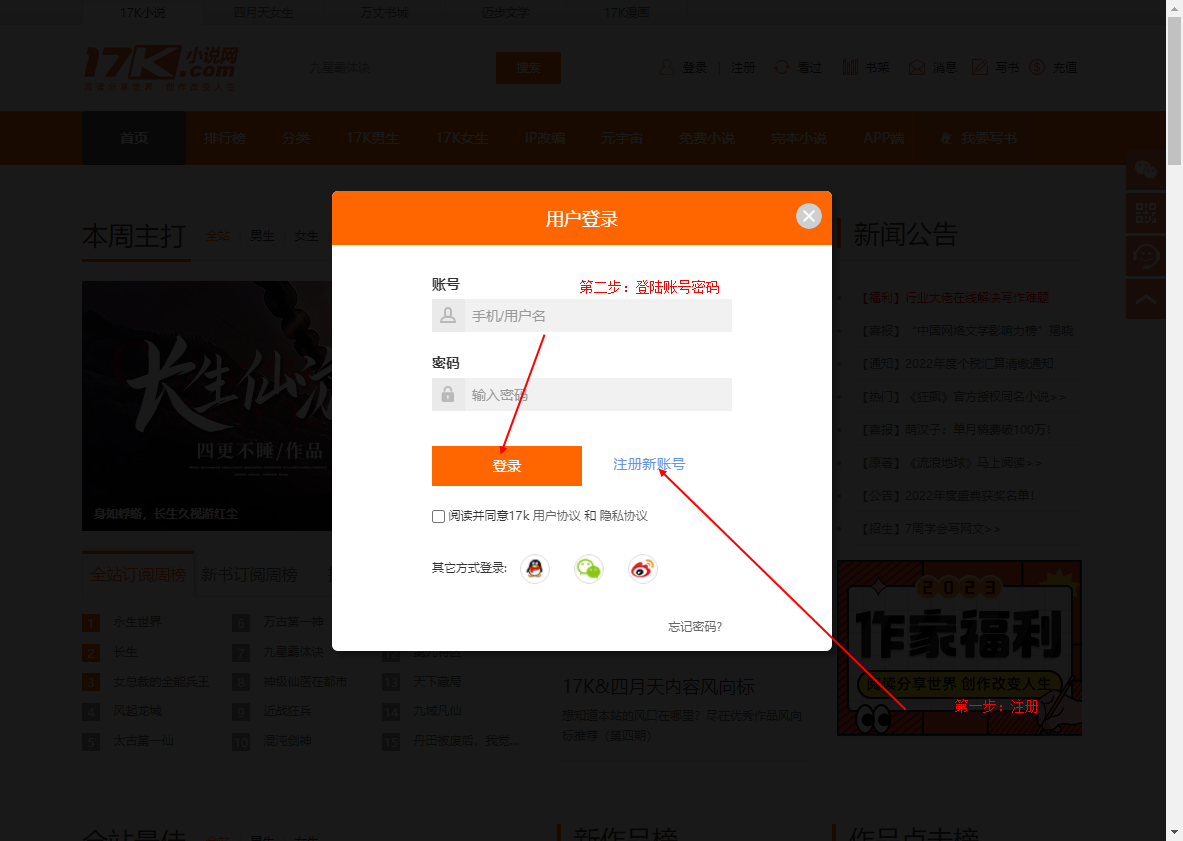
-
登陆成功后,找到并点击www.17k.com,在headers(标头)中的请求标头会看到cookie,全部复制并保存。
-
cookie: GUID=b11825a8-e117-4d1f-83a1-4138ad8caf5b; c_channel=0; c_csc=web; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22186c156800ed0f-06730abee4d1db4-26031951-2073600-186c156800ffe9%22%2C%22first_id%22%3A%22%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_referrer%22%3A%22%22%7D%2C%22identities%22%3A%22eyIkaWRlbnRpdHlfY29va2llX2lkIjoiMTg2YzE1NjgwMGVkMGYtMDY3MzBhYmVlNGQxZGI0LTI2MDMxOTUxLTIwNzM2MDAtMTg2YzE1NjgwMGZmZTkifQ%3D%3D%22%2C%22history_login_id%22%3A%7B%22name%22%3A%22%22%2C%22value%22%3A%22%22%7D%2C%22%24device_id%22%3A%22186c156800ed0f-06730abee4d1db4-26031951-2073600-186c156800ffe9%22%7D; accessToken=avatarUrl%3Dhttps%253A%252F%252Fcdn.static.17k.com%252Fuser%252Favatar%252F10%252F50%252F89%252F99998950.jpg-88x88%253Fv%253D1676264177000%26id%3D99998950%26nickname%3D15833861707z%26e%3D1693897155%26s%3D4ba307ba68dde422 -
同时我们发现在www.17k.com的相应数据中无法搜到我们想要的书架上的小说
3、分析书架
-
进入到我的书架的页面
-
采用全局搜索,搜索我们想要的内容。先点击www.17k.com,再按Ctrl+F。搜索书架上的书名。《独断万古》,回车确定。
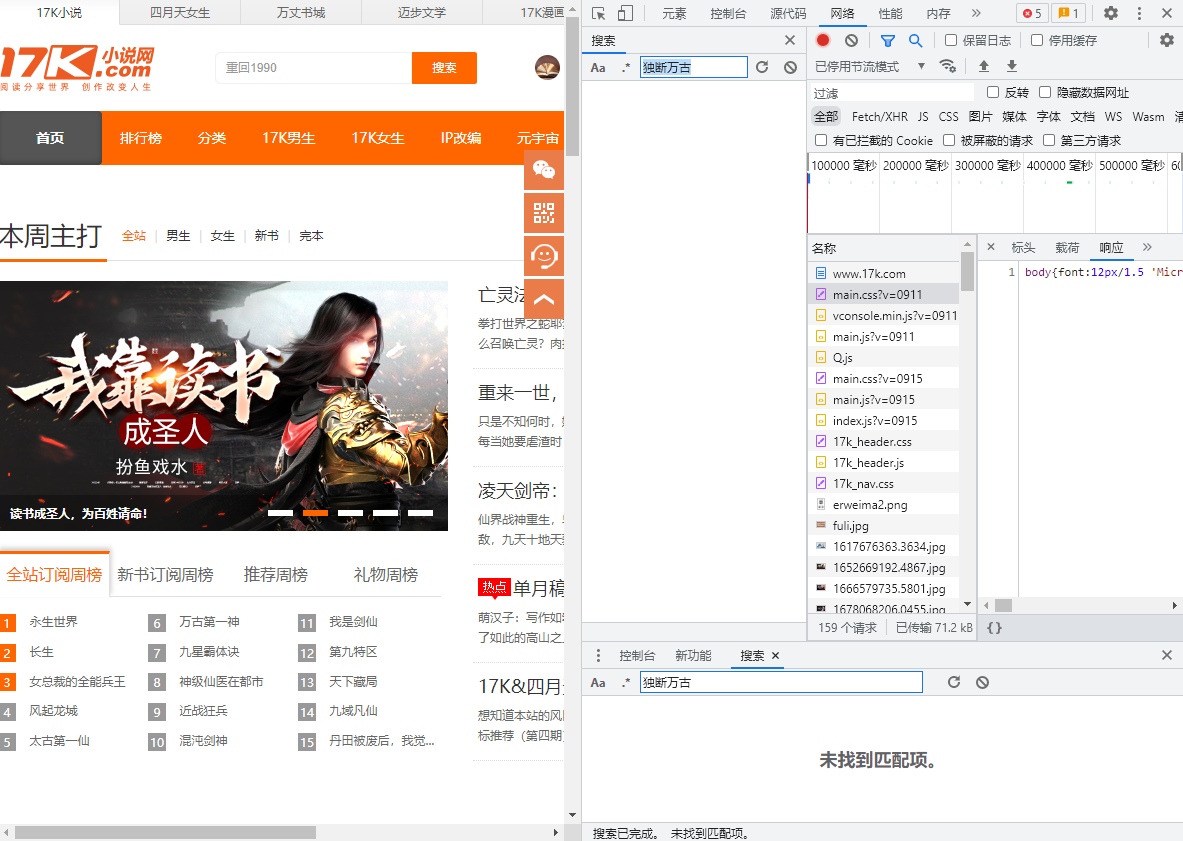
- 搜索书架上的书名。《独断万古》
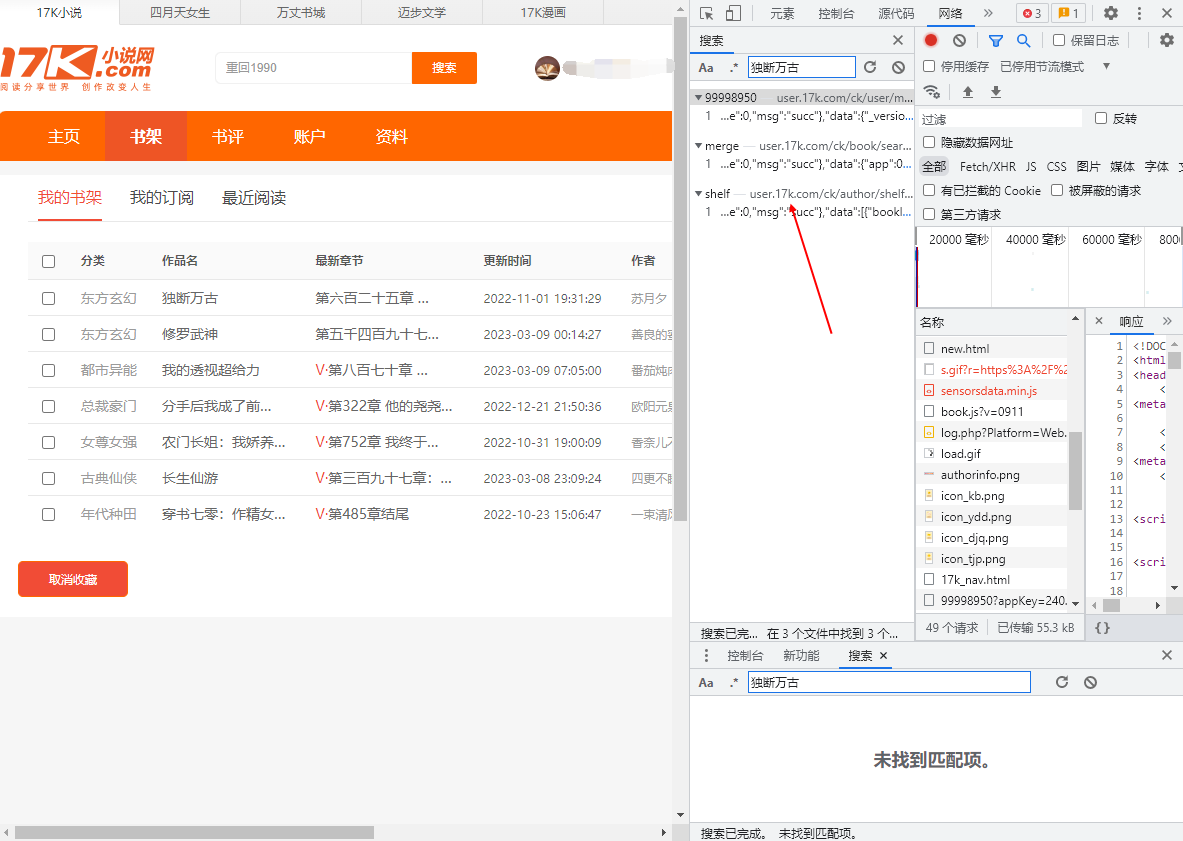
- 逐一排查,发现该文件是我们想要的内容
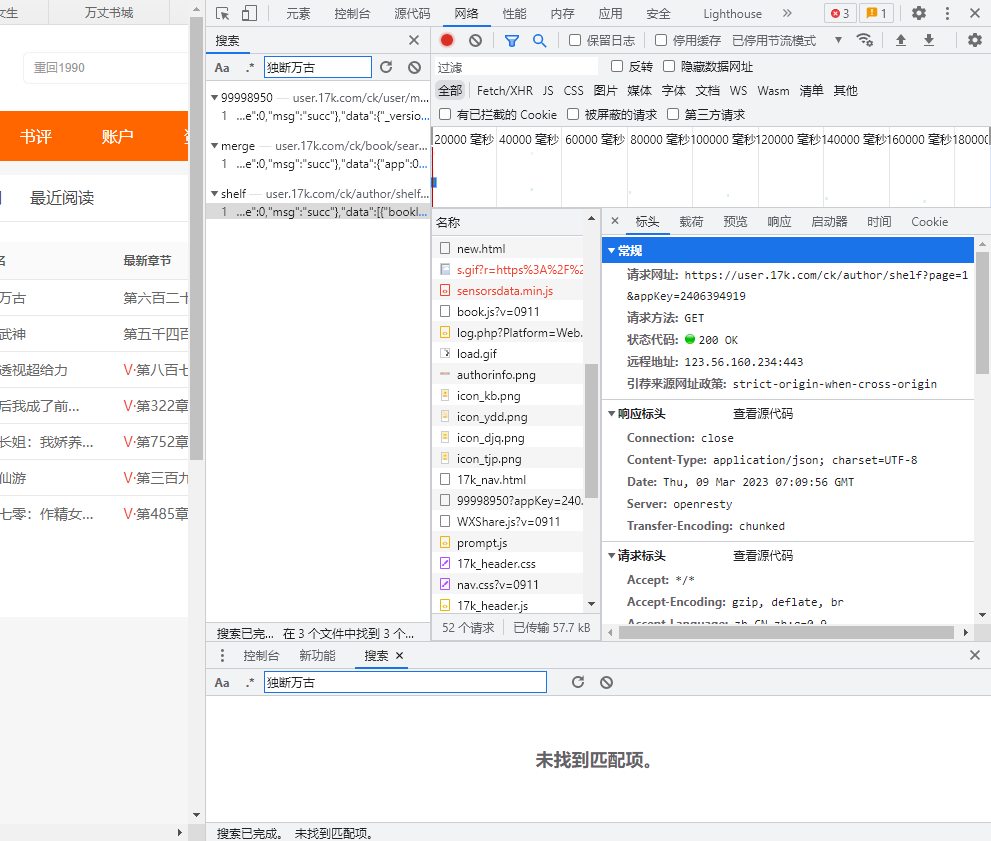
- 逐一查看标头,特别注意:
- 请求网址: 对该网址发起请求才能获得我们想要的数据
- 请求方法: get请求和post请求的请求方法不一样
- Cookie: 是破解验证登录的重要一环
- Referer:该网址的来源网址,若不带,则可能会报错
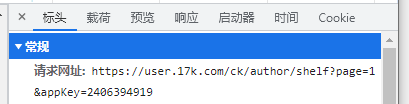
- 查看载荷
- 发现其带有请求参数,这一点从请求网址中也有所体现
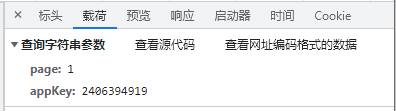
- 查看响应数据,发现是json数据格式。同时可以直观地看到我们想要的数据内容即,书籍名。
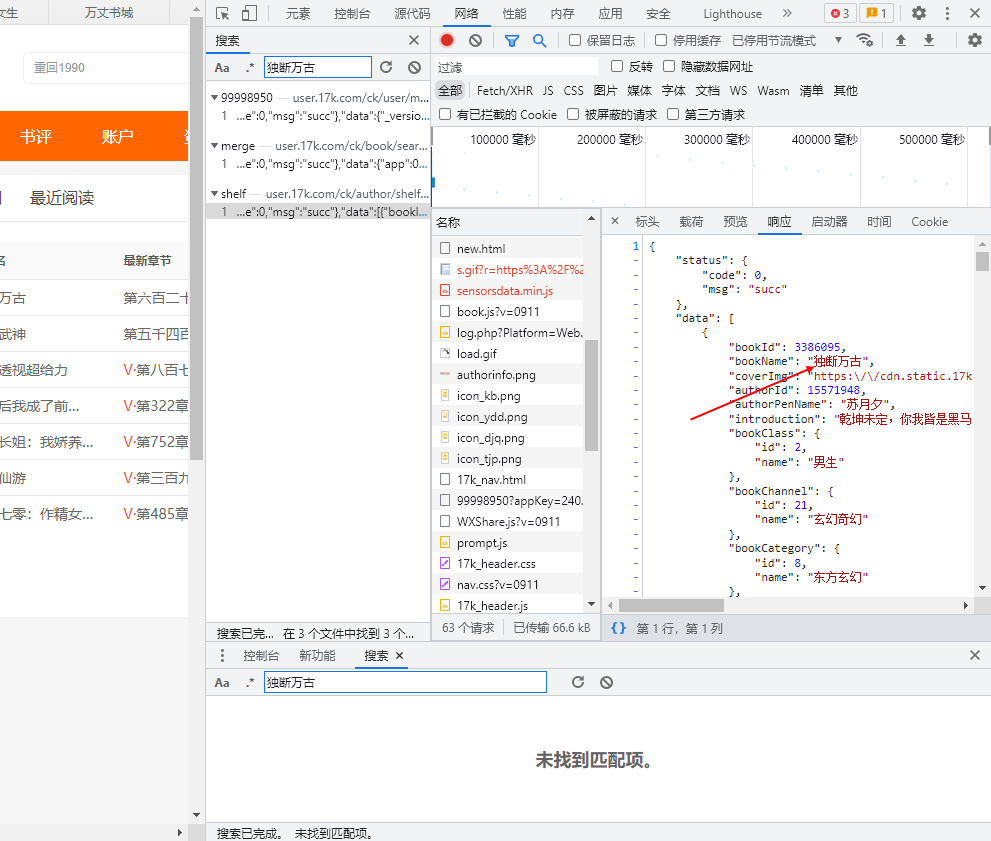
- 点进某本小说,发现其具体网址为:https://www.17k.com/book/3386095.html
- 通过分析发现其组成为https://www.17k.com/book/ + bookId + .html
总结:
- 查看目标网址
- 需要绕过登陆(先思考cookie)
- 查看书架内容
- 搜索到书籍所在代码文件
- 解析目标文件
代码分析及书写
1、导入模块
from fake_useragent import UserAgent #(UA)伪装
import random #随机模块
import requests #requests请求模块
from lxml import etree #xpath方法模块
import time #time模块
from time import sleep #睡眠模块
import re #正则方法模块
import json #json方法模块
import os #os模块
2、UA伪装:需要带UA和cookie
为防止多次请求被封ip,采用代理池
# 构建一个代理池
proxy_url = 'http://webapi.http.zhimacangku.com/getip?num=10&type=2&pro=&city=0&yys=0&port=1&pack=292706&ts=0&ys=0&cs=0&lb=1&sb=0&pb=4&mr=1®ions='
json_data = requests.get(url=proxy_url,headers=headers).json()
json_list = json_data['data']
proxy_list = [] #代理池,每次请求,可以随机从代理池中选择一个代理来用
UA伪装
# UA伪装:随机选用headers
fake_ua = UserAgent()
# 需要跳过登陆验证,所以带cookie
headers = {
'User-Agent': fake_ua.random,
'Cookie': 'GUID=b11825a8-e117-4d1f-83a1-4138ad8caf5b; c_channel=0; c_csc=web; accessToken=avatarUrl%3Dhttps%253A%252F%252Fcdn.static.17k.com%252Fuser%252Favatar%252F10%252F50%252F89%252F99998950.jpg-88x88%253Fv%253D1676264177000%26id%3D99998950%26nickname%3D15833861707z%26e%3D1693810664%26s%3D72ff5fac39d4c099',
'Referer': 'https://user.17k.com/www/bookshelf/index.html'
}
3、分析网址发现需要带请求参数
params = {
'page': 1,
'appKey': '2406394919'
}
总结:UA伪装+请求体参数
# UA伪装:随机选用headers
fake_ua = UserAgent()
# 需要跳过登陆验证,所以带cookie
headers = {
'User-Agent': fake_ua.random,
'Cookie': 'GUID=b11825a8-e117-4d1f-83a1-4138ad8caf5b; c_channel=0; c_csc=web; accessToken=avatarUrl%3Dhttps%253A%252F%252Fcdn.static.17k.com%252Fuser%252Favatar%252F10%252F50%252F89%252F99998950.jpg-88x88%253Fv%253D1676264177000%26id%3D99998950%26nickname%3D15833861707z%26e%3D1693810664%26s%3D72ff5fac39d4c099',
'Referer': 'https://user.17k.com/www/bookshelf/index.html'
}
params = {
'page': 1,
'appKey': '2406394919'
}
# 起始url即书架url
url = 'https://user.17k.com/ck/author/shelf?'
# url = 'https://user.17k.com/www/bookshelf/'
# 对书架url发起请求,获得响应数据
response = requests.get(url=url, headers=headers, params=params)
4、获得响应数据,
- 发现是json数据,利用json方法进行解析
- 提取到我们想要的那部分数据即data数据
# 防止获得到的是乱码,对返回的数据进行解码
response.encoding = 'utf8'
# 将获得到的响应数据做json格式化处理
page_text = response.json()
book_data = page_text["data"]
5、解析响应数据
-
获取到书籍名字,书籍网址
# 存储每一本小说的链接 book_urls = [] for i in book_data: book_name = i["bookName"] book_id = i["bookId"] # https://www.17k.com/book/3386095.html book_url = 'https://www.17k.com/list/' + str(book_id) + '.html' book_urls.append(book_url) # 循环访问每一本小说的url
6、解析每一本小说的具体数据
# 循环访问每一本小说的url
for book_url in book_urls:
# 解析每一本小说的响应数据
response_every = requests.get(url=book_url, headers=headers)
response_every.encoding = 'utf8'
page_text = response_every.text
# 实例化etree对象
tree = etree.HTML(page_text)
# 利用xpath方法提取到每一章URL所在的标签
a_lists = tree.xpath('/html/body/div[5]/dl[2]/dd/a')
#循环解析每一章的具体网址
for a in a_lists:
novel_detail_href = 'https://www.17k.com' + a.xpath('./@href')[0]
# 循环获取每一章节的url并做解析
content1 = requests.get(url=novel_detail_href, headers=headers)
content1.encoding = 'utf8'
content = content1.text
tree = etree.HTML(content)
#获取到每一章的章节标题
n_title = tree.xpath('//*[@id="readArea"]/div[1]/h1/text()')[0]
#利用xpath获取到每一章的文本内容
n_content_detail = re.findall(r'<div class="p">(.*?)<p class="copy ">', content, re.S)[0]
#数据清洗,删除不必要的数据
n_content = n_content_detail.replace('<p>', '').replace('</p>', '').replace(' ', '').strip()
#数据拼接,章节标题+内容
n_detail = '--------' + n_title + '--------' + '\n' + n_content + '\n'
#缓冲2s,加载缓存到的数据
sleep(2)
#利用try方法,检测是否会发生错误,若发生错误,则报错
try:
#声明文件路径
filepath = filename + '/' + '%s' % book_name + ".txt"
with open(filepath, mode='a+', encoding='utf8') as f:
f.write(n_detail)
print(n_title, '下载完成')
f.close()
except Exception as e:
print(e)
总结:完整代码
from fake_useragent import UserAgent
import random
import requests
from lxml import etree
import time
from time import sleep
import re
import json
import os
#判断文件夹是否存在
filename = '小说'
if not os.path.exists(filename):
os.mkdir(filename)
# UA伪装:随机选用headers
fake_ua = UserAgent()
# 需要跳过登陆验证,所以带cookie
headers = {
'User-Agent': fake_ua.random,
'Cookie': 'GUID=b11825a8-e117-4d1f-83a1-4138ad8caf5b; c_channel=0; c_csc=web; accessToken=avatarUrl%3Dhttps%253A%252F%252Fcdn.static.17k.com%252Fuser%252Favatar%252F10%252F50%252F89%252F99998950.jpg-88x88%253Fv%253D1676264177000%26id%3D99998950%26nickname%3D15833861707z%26e%3D1693810664%26s%3D72ff5fac39d4c099',
'Referer': 'https://user.17k.com/www/bookshelf/index.html'
}
#请求参数
params = {
'page': 1,
'appKey': '2406394919'
}
#构建一个代理池
proxy_url = 'http://webapi.http.zhimacangku.com/getip?num=10&type=2&pro=&city=0&yys=0&port=1&pack=292706&ts=0&ys=0&cs=0&lb=1&sb=0&pb=4&mr=1®ions='
json_data = requests.get(url=proxy_url,headers=headers).json()
json_list = json_data['data']
proxy_list = [] #代理池,每次请求,可以随机从代理池中选择一个代理来用
for dic in json_list:
ip = dic['ip']
port = dic['port']
n_dic = {
'https':ip+':'+str(port) # {'https':'111.1.1.1:1234'}
}
proxy_list.append(n_dic)
# 起始url即书架url
url = 'https://user.17k.com/ck/author/shelf?'
# url = 'https://user.17k.com/www/bookshelf/'
# 对书架url发起请求,获得响应数据
response = requests.get(url=url, headers=headers, params=params,proxies=random.choice(proxy_list))
# 防止获得到的是乱码,对返回的数据进行解码
response.encoding = 'utf8'
# 将获得到的响应数据做文本处理
page_text = response.json()
book_data = page_text["data"]
# 存储每一本小说的链接
book_urls = []
for i in book_data:
book_name = i["bookName"]
book_id = i["bookId"]
# https://www.17k.com/book/3386095.html
book_url = 'https://www.17k.com/list/' + str(book_id) + '.html'
book_urls.append(book_url)
# 循环访问每一本小说的url
for book_url in book_urls:
# 解析每一本小说的响应数据
response_every = requests.get(url=book_url, headers=headers,proxies=random.choice(proxy_list))
response_every.encoding = 'utf8'
page_text = response_every.text
# 实例化etree对象
tree = etree.HTML(page_text)
# 利用xpath方法提取到每一章URL所在的标签
a_lists = tree.xpath('/html/body/div[5]/dl[2]/dd/a')
#循环解析每一章的具体网址
for a in a_lists:
novel_detail_href = 'https://www.17k.com' + a.xpath('./@href')[0]
# 循环获取每一章节的url并做解析
content1 = requests.get(url=novel_detail_href, headers=headers,proxies=random.choice(proxy_list))
content1.encoding = 'utf8'
content = content1.text
tree = etree.HTML(content)
#获取到每一章的章节标题
n_title = tree.xpath('//*[@id="readArea"]/div[1]/h1/text()')[0]
#利用xpath获取到每一章的文本内容
n_content_detail = re.findall(r'<div class="p">(.*?)<p class="copy ">', content, re.S)[0]
#数据清洗,删除不必要的数据
n_content = n_content_detail.replace('<p>', '').replace('</p>', '').replace(' ', '').strip()
#数据拼接,章节标题+内容
n_detail = '--------' + n_title + '--------' + '\n' + n_content + '\n'
#缓冲2s,加载缓存到的数据
sleep(2)
#利用try方法,检测是否会发生错误,若发生错误,则报错
try:
#声明文件路径
filepath = filename + '/' + '%s' % book_name + ".txt"
with open(filepath, mode='a+', encoding='utf8') as f:
f.write(n_detail)
print(n_title, '下载完成')
f.close()
except Exception as e:
print(e)
本文来自博客园,作者:Chimengmeng,转载请注明原文链接:https://www.cnblogs.com/dream-ze/p/17198746.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号