Day 22 22.2:scrapy部署
scrapy项目部署
scrapyd部署工具介绍
- scrapyd是一个用于部署和运行scrapy爬虫的程序,它由 scrapy 官方提供的。它允许你通过JSON API来部署爬虫项目和控制爬虫运行。
所谓json api本质就是post请求的webapi
- 选择一台主机当做服务器,安装并启动 scrapyd 服务。再这之后,scrapyd 会以守护进程的方式存在系统中,监听爬虫地运行与请求,然后启动进程来执行爬虫程序。
环境安装
- scrapyd服务:
pip install scrapyd
- scrapyd客户端:
pip install scrapyd-client
一定要安装较新的版本10以上的版本,如果是现在安装的一般都是新版本
启动scrapyd服务
- 打开终端在scrapy项目路径下 启动scrapyd的命令:
scrapyd

- scrapyd 也提供了 web 的接口。方便我们查看和管理爬虫程序。默认情况下 scrapyd 监听 6800 端口,运行 scrapyd 后。在本机上使用浏览器访问
http://localhost:6800/地址即可查看到当前可以运行的项目。
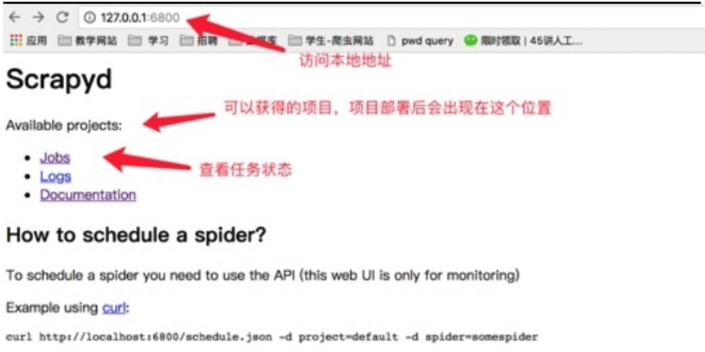
- 点击job可以查看任务监控界面
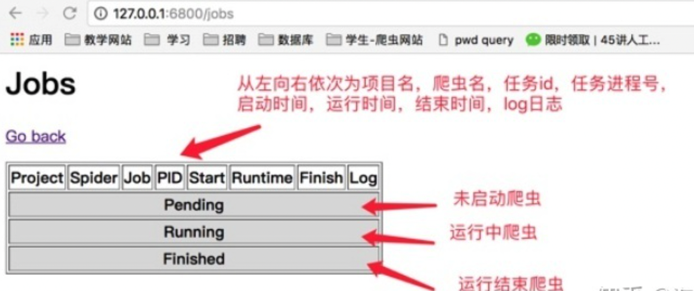
scrapy项目部署
配置需要部署的项目
- 编辑需要部署的项目的scrapy.cfg文件(需要将哪一个爬虫部署到scrapyd中,就配置该项目的该文件)
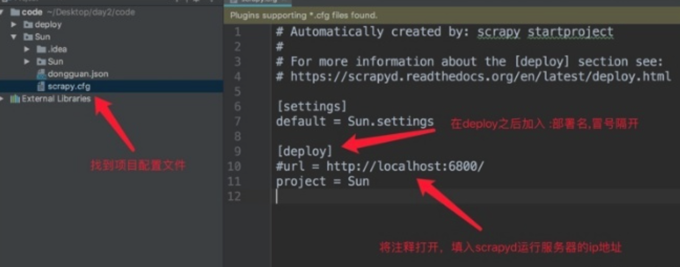
[deploy:部署名(部署名可以自行定义)]
url = http://localhost:6800/
project = 项目名(创建爬虫项目时使用的名称)
username = dream # 如果不需要用户名可以不写
password = 123456 # 如果不需要密码可以不写
部署项目到scrapyd
-
同样在scrapy项目路径下执行如下指令:
#pycharm scrapyd-deploy 部署名(配置文件中设置的名称) -p 项目名称 -
部署成功之后就可以看到部署的项目
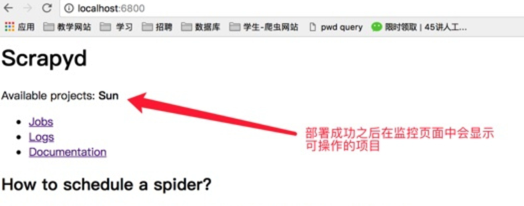
-
使用以下命令检查部署爬虫结果:
-
#pycharm scrapyd-deploy -L 部署名
-
管理scrapy项目
指令管理
-
安装curl命令行工具
- window需要安装
- linux和mac无需单独安装
-
window安装步骤:
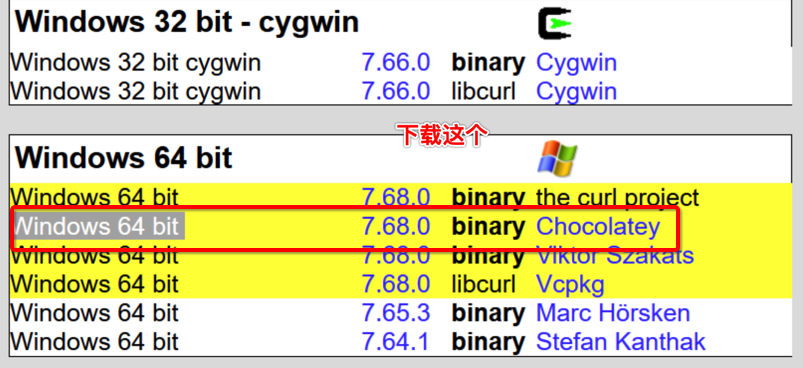
- 下载后,放置到一个无中文的文件夹下直接解压缩,解压后将bin文件夹配置环境变量!
- 参考网页:https://www.cnblogs.com/lisa2016/p/12193494.html
-
启动项目:
curl http://localhost:6800/schedule.json -d project=项目名 -d spider=爬虫名-
返回结果:注意期中的jobid,在关闭项目时候会用到
-
{"status": "ok", "jobid": "94bd8ce041fd11e6af1a000c2969bafd", "node_name": "james-virtual-machine"}
-
-
-
关闭项目:
-
curl http://localhost:6800/cancel.json -d project=项目名 -d job=项目的jobid
-
-
删除爬虫项目:
-
curl http://localhost:6800/delproject.json -d project=爬虫项目名称
-
requests模块控制scrapy项目
import requests
# 启动爬虫
url = 'http://localhost:6800/schedule.json'
data = {
'project': 项目名,
'spider': 爬虫名,
}
resp = requests.post(url, data=data)
# 停止爬虫
url = 'http://localhost:6800/cancel.json'
data = {
'project': 项目名,
'job': 启动爬虫时返回的jobid,
}
resp = requests.post(url, data=data)
本文来自博客园,作者:Chimengmeng,转载请注明原文链接:https://www.cnblogs.com/dream-ze/p/17150150.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号