【大数据系列】Hadoop DataNode读写流程
DataNode的写操作流程
DataNode的写操作流程可以分为两部分,第一部分是写操作之前的准备工作,包括与NameNode的通信等;第二部分是真正的写操作。
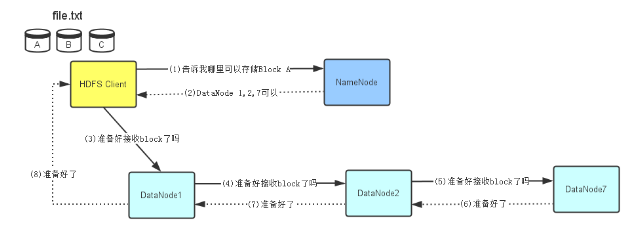
一、准备工作
1、首先,HDFS client会去询问NameNoed,看哪些DataNode可以存储Block A,file.txt文件的拆分是在HDFS client中完成的,拆分成了3个Block(A B C).因为NameNode存储着整个文件系统的元数据,它知道哪个DataNode上有空间可以存储这个Block A.
2、NameNode通过查看它的元数据信息,发现DataNode1、2、7上有空间可以存储Block A,预示将此信息高速HDFS Client.
3、HDFS Client接到NameNode返回的DataNode列表信息后,它会直接联系第一个DataNode-DataNode 1,让它准备接收Block A--实际上就是建立彼此之间的TCP连接。然后将Block A和NameNode返回的所有关于DataNode的元数据一并传给DataNode1.
4、在DataNode1与HDFS Client建立好TCP连接后,它会把HDFS Client要写Block A的请求顺序传给DataNode2(在与HDFS Client建立好TCP连接后从HDFS Client获得的DataNode信息),要求DataNode2也准备好接收Block A(建立DataNode2到DataNode1的TCP连接)。
5、同上,建立DataNode2到DataNode7的TCP连接
6、当DataNode7准备好之后,它会通知DataNode2,表示可以开始接收Block A
7、同理,当DataNode2准备好之后,他会通知DataNode1,表明可以开始接收Block A
8、当HDFS Client接收到DataNode1的成功反馈信息后,说明这3个DataNode都已经准备好了,HDFS Client就会开始往这三个DataNode写入Block A
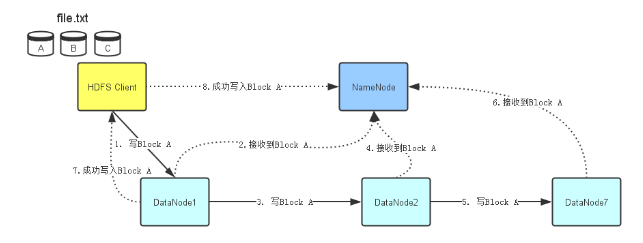
二、流程
在DataNode1 2 7都准备好接收数据后,HDFS Client开始往DataNode1写入Block A数据。同准备工作一样,当DataNode1接受完A数据后,它会顺序将Block A数据传输给DataNode2,然后DataNode2再传输给DataNode7.每个DataNode在接受完Block A 数据后,会发消息给NameNode,告诉他Block数据已经接收完毕,NameNode同时会根据它接收到的小心更新它保存的文件系统元数据信息。当Block A成功写入3个DataNode之后,DataNode1会发送一个成功消息给HDFS Client,同时HDFS Client也会发一个Block A成功写入的信息给NameNode,之后HDFS Client才能开始继续处理下一个Block:Block B。
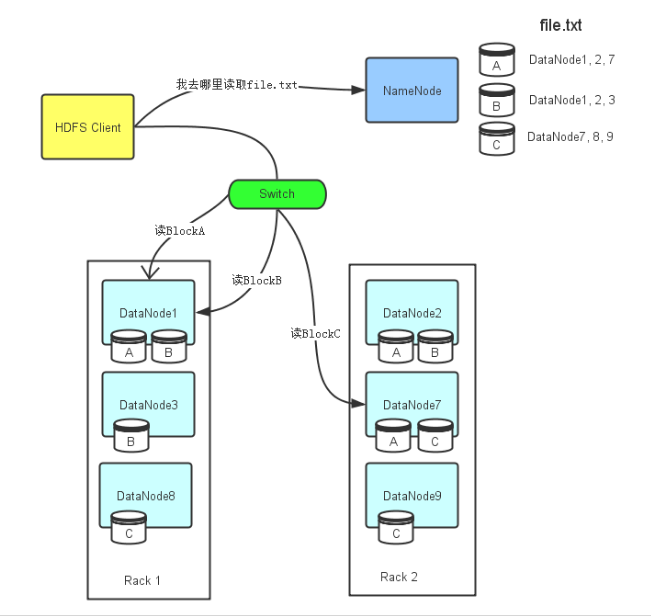
DataNode的读操作流程:
首先,HDFS Client会先去联系NameNode,询问file.txt总共分为几个Block ,而且这些Block分别存放在哪些DataNode上。由于每个Block都会存在几个副本,所以NameNode会把file.txt文件组成的Block对应的所有DataNode列表都返回给HDFS Client.然后HDFS Client会选择DataNode列表里的第一个DataNode去读取对应的Block,比如Block A存储在DataNode 1 2 7,那么HDFS Client会到DataNode1去读取Block A,Block c存储在DataNode7 8 9那么HDFS Client就回到DataNode7去读取Block C.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号