指令流水线归纳总结
Pipelining
流水线
中山大学
报告目录
一. 思维导图--------------------------------- 3
二. 课件理解--------------------------------- 4
三. 名词解释--------------------------------- 14
四. 归纳总结--------------------------------- 15
五. 参考文献--------------------------------- 18
六. 附录------------------------------------- 18

二.课件理解
Lecture3回顾
n 微编码:一种有效的技术用于管理控制单元的复杂性,发明于60年代。
n 由于ROM和RAM速度的不同,引入了更多复杂的指令。
n 技术的进步导致产生fast SRAM,使得技术预测失效
n 复杂的指令阻碍了并行与流水的实现
n 简化的指令集具有更好的效率(新VLSI上),也导致微处理器的发展与流行
处理器性能的铁律

n 每个程序中的指令数依赖于源代码、编译技术以及ISA
n 每条指令的周期(CPI)数依赖于ISA和微体系结构
n 每个周期的运行时间依赖于微体系结构和基础技术

典型的5-stage RISC 流水线
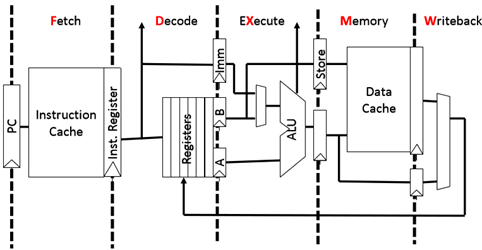
流水线的同步读写
CPI的示例
n 微编码机器:3条指令,22个周期,CPI = 7.33 > 1

n 非流水线机器:3条指令,3个周期,CPI = 1

n 流水线机器:3条指令,3个周期,CPI = 1
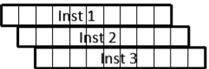
流水线中指令间的相互影响
流水线中的一条指令可能需要另一条指令正在使用的资源
n 结构冲突:Structural hazard
- 流水线中的一条指令可能依赖于前面指令产生的结果
- 这种依赖可能是一个数据值
n 数据冲突(也称为数据依赖):Data hazard
- 这种依赖也可能是下一条指令的地址
n 控制冲突(也称为地址依赖):Control hazard
- 解决策略:通常通过向指令中加入气泡(bubbles)的方式使CPI变大。
流水线CPI示例
测量从第一条指令完成到当序列中的最后一个指令完成
n 3条指令在3个周期中完成,CPI = 3/3 = 1

n 3条指令在个4周期中完成,CPI = 4/3 = 1.33
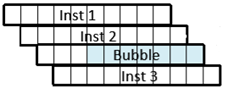
n 3条指令在5个周期中完成,CPI = 5/3 = 1.67
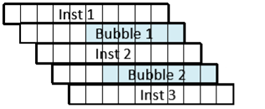
可见,随着流水线的增多,CPI不断增大。
解决结构性冲突
n 当两条指令同时需要相同的资源时就会出现结构性冲突
可以在硬件通过拖延新的指令,先执行旧指令,后执行新指令的方式解决
n 通过增加硬件设计的方式总是可以避免结构性冲突
例如,如果两条指令同时需要存储器的某部件,我们可以通过增加另一个该部件的方式避免冲突。
n 典型的RISC 5-stage纯整数计算流水线一般没有结构性冲突
多周期单元容易引起结构性冲突,比如在乘法器、触发器、浮点运算单元上面易出现结构性冲突,在寄存器的回写部件上面也容易出现结构性冲突
数据冲突类型
考虑下面一系列register-register指令类型:

n 数据依赖:在这种类型是true data-dependence

n 反依赖:

n 输出依赖:

- 反依赖和输出依赖又称为名称依赖(Name-dependence not the DD)不是真正的数据依赖,在简单的流水线中没有这样的冲突,但在复杂的流水线中可能存在。
n 注:我们必须要保证程序按顺序执行读写
对数据冲突的三种策略
n 互锁Interlock(stall):
- 通过控制问题阶段的依赖指令来等待hazard被清理
n 绕行,回避Bypass(forwarding):
- 尽可能快的在早期通过回避数值来解决hazard
n 预测Speculate :
- 先假设一个值,如果假设错误,再进行改正。
互锁与绕行的对比
n 互锁:
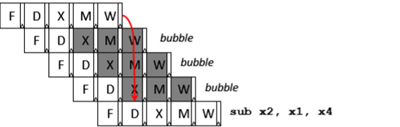
等待了3个cycles,指令在解码阶段(decode)被互锁(stall)
n 绕行:

指令1在ALU阶段的结果,直接传给指令2的EX阶段,从而整个过程没有空等待(bubbles).
绕行(Bypass)路径示例
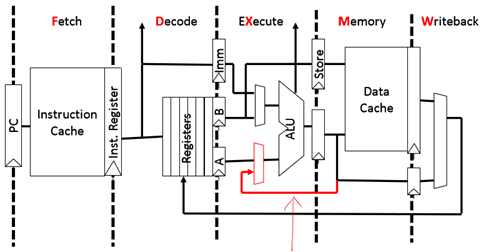
Bypass需要修改datapath(forwarding)
完整的Bypass 数据路径图
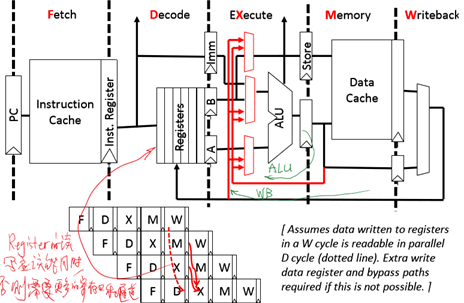
RAM 数据冲突值预测Value Speculation for RAW Data Hazards
n 可以猜出一个数值,而不是等待。至今,这种方式仅在限定的情况下可行:
- 分支预测(条件跳转指令)
- 栈指针更新(子例程调用时)
- 存储器地址解析(绝对跳转)
控制冲突Control Hazards
各种指令为了得到下一个PC值需要什么:
n 对于无条件跳转
- Opcode,PC,以及offset
n 对于跳转寄存器
- Opcode,Register value,以及offset
n 对于条件分支
- Opcode,Register(for condition),PC以及offset
n 对于所有其他指令
- Opcode和PC(但是必须保证不是上面所说的任何一种情况)
流水线中的控制流信息
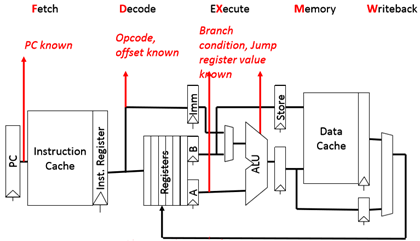
在各阶段上可获得控制流信息
无条件的PC相对跳转
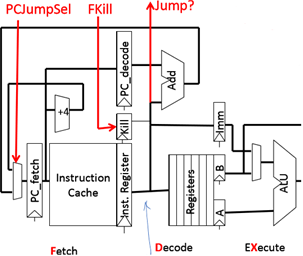
在decode stage 上可以决定是否跳转,若要跳转,修改PC值,并将一个已经fetch的指令kill掉(这样会产生一个气泡)
无条件的PC相对跳转流水线

在J target指令的D阶段,可以确定跳转以及地址,可以用Fkill将取得的第二个指令无效,用PCsd选取要跳转的目标。如果在D阶段发现不是J指令,则不会发生跳转,也不会引入一个bubble。
分支延迟槽Branch Delay Slots
n 早期的RISC采用微编程流水线的思路,改变了ISA语义定义,因此在分支/跳转后的指令总是在控制流改变发生之前被执行:

n 所以软件应该在slot放置有效的指令,或者放空指令。

Post-1990 RISC ISAs没有延迟槽
n 编码中,将微体系结构的内容引入了ISA,不符合ISA抽象
- 例如:IBM 650 drum layout
n 性能问题:影响效率
- 在没有使用到的延迟槽中的NOPS中,I-caches增加
- 延迟槽中I-caches的丢失,导致机器等待,即使延迟槽是一个NOP
n 使更高级的微体系结构变得复杂
n 更好的分支预测可以取代
RISC-V Conditional Branches RISC-V条件分支跳转

在X阶段产生跳转条件,因此在D和下个阶段都要kill(如果真的跳转)
Pipelining for Conditional Branches 条件分支流水线

Pipelining for Jump Register 跳转寄存器流水线
在X阶段获得地址:
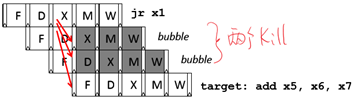
在典型5-stage流水线(CPI>1)中,指令不一定在每个周期都能被调用的原因
n 实现代价太大:完全绕行(fully bypassing)实现代价太大
- 通常所有频繁被用到的路径都会被提供
- 一些不经常使用的绕行路径可能会增加cycle time而抵消了CPI的作用
n 转入指令有两种时钟的延迟
- 装入之后的指令不能使用转入结果
- MIPS-I ISA定义了装入延迟槽,一个软件可见的流水线hazard(编译器会安排独立的指令或者插入NOP来避免hazard),而在MIPS-II中被移除(在硬件中增加了流水线互锁装置((pipeline interlocks))
- MIPS:Microprocessor without Interlocked Pipeline Stages 无互锁装置的流水线微处理器
n 跳转/条件分支可能会产生bubbles
- 如果没有延迟槽,就会kill后面的指令
拥有软件可见延迟槽的机器,可能会执行相当多的由编译器加入的NOP指令
NOPS会减少CPI,但是会增加instructions/program
在pipeline上导致CPI增加的原因。
陷阱和中断
相关术语:
n 异常:不正常的内部事件,如缺页,溢出等
n 陷阱:由异常引起的控制转换(传递)到管态
- 并不是所有的异常都会产生陷阱
n 中断:程序执行之外的事件引起控制传递到管态
n 陷阱和中断通常在流水线上得到相同的处理机制
异常处理的历史
n 分析机就已经有溢出异常
n 第一个产生陷阱的系统是Univac-I, 1951
- 算术溢出
- 在地址0处触发执行两个指令修复例程,或者
- 程序员终止计算机
- 在之后的Univac 1103, 1955系统上修改添加外部指令
用于收集实时风洞数据
n 第一个有I/O中断的系统是DYSEAC, 1954
- 拥有两个程序计数器,I/O信号的改变让两种PC交替
- 也是第一个具有DMA(直接内存访问)的系统
- 是第一台可以移动计算机(20吨)
异步中断
n 有优先级的中断请求线:I/O请求需要得到请求线的关注
n 处理器处理中断:
- 它会在指令Ii处停止当前执行的指令,完成到Ii-1为止的所有指令的执行(精确中断)
- 它会将Ii的PC值保存在一个特殊的寄存器(EPC异常程序计数器)(中断断点)
- 它将禁用中断和转移控制到指定的中断处理程序在内核模式下运行
Interrupt Handler中断处理程序
n 启用嵌套中断之前保存EPC
- 需要一个中断将EPC移动到GPRs(通用寄存器)中
- 需要一种方式掩盖后来的中断直到EPC被保存
n 需要读入状态寄存器来表明 中断发生的原因
n 使用一个间接跳转指令SRET(中断返回指令)来:
- 启用中断
- 将处理器恢复到用户模式
- 恢复硬件状态和控制状态
Synchronous Trap 同步性陷阱
n 指定指令的异常导致一个同步陷阱
n 异常指令一般需要再异常处理之后重新启动
- 需要恢复一个或多个指令的执行
n 为了防止一个系统调用陷阱,该指令被认为已经完成
- 一种特殊的跳转指令的引入致使特权级转换到内核模式
5-Stage流水线异常处理
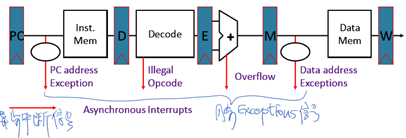
如何处理外部中断?
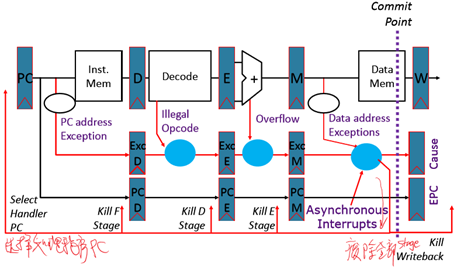
n 保持流水线异常标识直到提交点为止(M stage)
n 对于一个给定的指令,早期状态中的异常重写后面的异常
n 在提交点注入外部中断(重写其他)
n 如果在提交时产生异常:更新记录和EPC寄存器,kill所有stage,在取指令阶段插入处理程序的PC。
Speculating on Exceptions 异常预测
n 预测机制
- 异常发生的几率是很小的,因此预测无异常一般是个非常准确的
n 检查预测机制
- 在指令执行后检测异常,有很多特殊的硬件装置用于处理不同的异常类型
n 恢复机制
- 在提交点仅仅写入体系结构状态,所以可以异常后面的部分指令
- 记忆机器状态,在刷新流水线后启动异常处理程序
n Bypassing(绕行)的方式允许后面的指令使用未提交的的指令结果。
Issues in Complex Pipeline Control在复杂流水线控制中的事项
n execution stage:在编译执行阶段如果一些浮点单元(FDU)或一些存储单元在流水线传输或执行超过了一个周期,就会出现结构性冲突
n write-back stage:在回写阶段由于不同功能单元块的各种延迟,会出现结构性冲突
n 由于不同功能单元的各种延迟,会产生无序的写冲突(Out-of-order write hazards)
n 如何解决冲突?
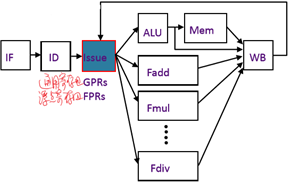
Complex In-Order Pipeline复杂有序流水线
n 延迟回写,因而所有的操作到回写阶段(W stage)都有相同的延迟
- 写端口从来不会超额执行(每个周期中,每个进入指令对应一个写出指令)
- 在长延迟操作中拖住流水线,例如在执行除法、高速缓存缺失时
- 在提交指令阶段按顺序执行
n 而对于纯整数的操作,应用bypassing消除延迟。

In-Order Superscalar Pipeline超标量顺序流水线
n 每个周期取回2个指令,如果一个事整数或是存储指令,另一个是浮点运算指令,两个同时执行。
n 是一种提高吞吐量的廉价方式,这样的例子包括Alpha 21064 (1992)、MIPS R5000 series (1996)等。
n 同样的想法可以通过复制功能单元扩展到更广泛的问题,例如4-issue UltraSPARC和Alpha 21164,但是寄存器组端口和bypassing成本快速增长。

三.名词解释
本段主要是对上述课件中出现的一些名词的解释和理解:
n 微指令:
- 在微程序控制的计算机中,将由同时发出的控制信号所执行的一组微操作称为微指令。所以微指令就是把同时发出的控制信号的有关信息汇集起来形成的。将一条指令分成若干条微指令,按次序执行就可以实现指令的功能。若干条微指令可以构成一个微程序,而一个微程序就对应了一条机器指令。因此,一条机器指令的功能是若干条微指令组成的序列来实现的。简言之,一条机器指令所完成的操作分成若干条微指令来完成,由微指令进行解释和执行。
n ROM和RAM:
- ROM和RAM指的都是半导体存储器,ROM是Read Only Memory的缩写,RAM是Random Access Memory的缩写。ROM在系统停止供电的时候仍然可以保持数据,而RAM通常都是在掉电之后就丢失数据,典型的RAM就是计算机的内存。
- RAM有两大类:一种称为静态RAM(Static RAM/SRAM),SRAM速度非常快,是目前读写最快的存储设备了,但是它也非常昂贵,所以只在要求很苛刻的地方使用,譬如CPU的一级缓冲,二级缓冲。另一种称为动态RAM(Dynamic RAM/DRAM),DRAM保留数据的时间很短,速度也比SRAM慢,不过它还是比任何的ROM都要快,但从价格上来说DRAM相比SRAM要便宜很多,计算机内存就是DRAM的。
n VLSI:
- VLSI是超大规模集成电路(Very Large Scale Integration)的简称,指几毫米见方的硅片上集成上万至百万晶体管、线宽在1微米以下的集成电路。随着VLSI技术的进步,使得建造具有数千甚至数万个处理器的超大型并行分布式系统已经可以实现了。
n 分支延迟槽 branch delay slots:
- 分支延迟槽,简单地说就是位于分支指令后面的一条指令,不管分支发生与否其总是被执行,而且位于分支延迟槽中的指令先于分支指令提交 (commit)。引入分支延迟槽的目的主要是为了提高流水线的效率。
- 简单说,一般CPU的分支跳转指令流是:分支跳转指令->目标跳转地址的指令。但MIPS的分支跳转指令流是:分支跳转指令 -> 延时槽指令 -> 目标跳转地址的指令,在中间操作插入了延时槽指令。
- 如果PC在延时槽地址中断后,中断返回时返回延时槽指令地址的话,重新执行的指令流为:延时槽指令 -> (延时槽指令地址 + 4)地址的指令,没有跳转了。这样完全不是原来被打断的指令流,为了恢复原来的指令流需要将延时槽前面的跳转指令重新装入流水线。所以在延时槽中断后返回的地址是前面跳转指令的地址。
n DYSEAC:
- DYSEAC was the second Standards Electronic Automatic Computer. (See SEAC.)
- DYSEAC was a first-generation computer built by the National Bureau of Standards for the US Army Signal Corps. It was housed in a truck, making it one of the first portable computers (perhaps the first). It went into operation in April 1954.
- DYSEAC used 900 vacuum tubes and 24,500 crystal diodes. It had a memory of 512 words of 45 bits each (plus one parity bit), using mercury delay line memory. Memory access time was 48–384 microseconds. The addition time was 48 microseconds and the multiplication/division time was 2112 microseconds. These times are excluding the memory access time, which added up to approximately 1500 microseconds to those times.
四.归纳总结
这部分主要是我对本次报告的归纳与总结,以及自己的一些收获:
从第一部分的思维导图可以看到本次课程主要讲解了这些内容:一、处理器的性能铁律;二、 RISC经典5级流水线;三、CPI相关概念;四、流水线的相关示例;五、流水线指令间的相互影响;六.流水线存在的问题;七、陷阱与中断,八、复杂流水线等。然后一一扩展开来,深入讲解流水线的相关内容。
同样可以从第一部分中的思维导图可以看出,本节课的重点是RISC经典五级流水线的组成与运行原理;流水线指令之间的相互影响:结构冲突、数据冲突、控制冲突产生以原因及解决的策略;另一部分重要内容就是陷阱与中断的处理。下面是通过本次课程的学习我的学习收获:
本节内容主要讲解了指令流水线的内容:我学习到流水线技术是一种将多条指令重叠执行的并行方法,如今,流水线技术是用于加快CPU速度的关键技术。通过学习RISC处理器的经典五级流水线,我理解了RISC子集中每条指令都可以在5个时钟周期中完成,这五个时钟周期分别是:指令提取周期(IF):程序计数器(PC)发送到存储器,从存储器提取当前指令。向程序计数器加4,将程序计数器更新到下一个连续程序计数器。下面是对这5个过程的具体解释:
RISC指令集中一条指令的五个主要执行步骤分别是:IF(Instruction fetch,取指令),ID(Instruction decode/register fetch cycle,指令解码),EX(Execution/effective address cycle,执行),MEM(Memory access,内存访问),WB(Write-back cycle,写回)
IF:根据PC(program counter,程序计数器)中所存储的内存地址,在内存中找到该地址所指向的指令,并将该指令存储在寄存器中。同时,PC指向下一条指令,完成这个操作要求PC加4(以32位指令集为例,如果是64位则要加8)。
ID: 操作从IF阶段获取来的指令。将指令解码,最终找到指令所需要的寄存器中存储的数据。如果该指令只一条跳转指令,那么在这一阶段需要根据跳转指令的意义对获取的值进行比较,如果比较结果为true则执行跳转,如果比较结果为false则不执行跳转,继续下一条指令的执行;如果指令需要对指令中某些位进行填充,也在ID阶段完成,比如对高四位进行填充以满足指令结果是32位;计算可能跳转的指令的地址。
EX: ALU(Arithmetic Logic Unit,算术逻辑单元)对ID阶段的结果进行计算。在ID阶段已经获得了指令计算所需要的寄存器的值,那么在EX阶段需要根据指令的意义对这些寄存器的值进行计算。计算根据指令的不同变得不同。主要有三种类型的ALU计算:
1. ALU根据ID中补充地址,对有效地址单元进行计算,最终得到所需的内存地址;
2. 根据指令的意义,对从寄存器中获取的值进行操作,如对两寄存器的值进行相加;
3. 根据寄存器的值以及补充的值,计算出立即数的结果。
MEM:如果当前指令是Load指令,那么,根据EX计算出的内存地址,从内存中获取对应的值;如果当前指令是store,那么,根据EX计算出的内存地址和寄存器的值,将寄存器的值存入该内存地址中。其他的指令一般不会设计内存的访问。
WB:将计算出来的最终的寄存器的值写入到register file(寄存器文件)中。这部操作包括从内存中获取的值以及通过算术运算得到的结果。
接着讨论了流水线的性能,我学习到流水线提高了CPU指令吞吐量(单位时间内完成指令数),但不会缩短单条指令的执行时间。事实上,由于流水线控制会产生额外的开销,太通常还会延长每条指令的执行时间,尽管单条指令的执行速度并没有加快,指令吞吐量的增长意味着程序可以更快的运行,总执行时间缩短。
其后又接着讨论了在流水线中会遇到的问题与阻碍:流水线的主要阻碍—流水线冒险:在指令流水线中,会出现冒险情况阻碍程序的执行,主要有以下三类冒险:结构冒险:在重叠执行模式下,如果硬件无法同时支持指令的所有可能组合形式,就会出现资源冲突,从而导致结构冒险;数据冒险:根据流水线中的指令重叠,指令之间存在先后顺序,如果一条指令取决于先前指令的执行结果,就可能导致数据冒险;控制冒险:分支指令以及其他改变程序计数器的指令实现流水化时就可能会导致控制冒险。
在陷阱与中断这一部分中,我学习到:
何为陷阱:计算机有两种运行模式:用户态,内核态。其中操作系统运行在内核态,在内核态中,操作系统具有对所有硬件的完全访问权限,可以使机器运行任何指令;相反,用户程序运行在用户态,在用户态下,软件只能使用少数指令,它们并不具备直接访问硬件的权限。这就出现了问题,假如软件需要访问硬件或者需要调用内核中的函数该怎么办呢,这就是陷阱的作用了。陷阱指令可以使执行流程从用户态陷入内核(这也就是为什么叫做陷阱,而不是捕猎的陷阱)并把控制权转移给操作系统,使得用户程序可以调用内核函数和使用硬件从而获得操作系统所提供的服务。
何为中断:中断是由外部事件导致并且它发生的时间是不可预测的,这一点和陷阱不同。外部事件主要是指时钟中断,硬件中断等。硬件中断顾名思义就是由硬件引起的中断,比如一个程序需要用户输入一个数据,但用户一直没有输入,操作系统决定是一直等待用户输入还是转而运行别的进程,一般情况是转而运行别的进程,如果用户的输入到来了,那么键盘驱动器会产生一个中断通知操作系统,操作系统保存正在运行的程序的状态,从而切换到原来的进程处理到来的数据。所以中断发生是随机的且主要作用是完成进程间切换,从而支持CPU和设备之间的并行。中断和异常的另一个重要差别是,CPU处理中断的过程中会屏蔽中断,不接受新的中断直到此次中断处理结束。而陷阱的发生并不屏蔽中断,可以接受新的中断。
何为异常:异常就是程序执行过程中的异常行为。比如除零异常,缓冲区溢出异常等。不同的操作系统定义了不同种类和数量的异常并且每个异常都有一个唯一的异常号,异常会扰乱程序的正常执行流程,所以异常是在CPU执行指令时本身出现的问题,比如除数为零而出现的除零异常。异常的产生表示程序设计不合理,所以在编程的时候要尽量避免异常的产生。
最后介绍了了更为复杂的流水线设计,通过讲解复杂流水线中的控制事项、复杂有序流水线、超标量顺序流水线等内容,加深了对流指令流水线执行的理解。
通过本次报告的翻译总结与归纳,将散乱的知识归纳为一个整体,有效巩固了以前学到的知识,通过总结将它们串联起俩,加深了理解与记忆,复习思路更加清晰,基本掌握了流水线的相关知识,总之获益良多。
五. 参考文献
[1] John L Hennessy David A Patterson, 贾洪峰 译.计算机体系结构-量化研究方法[M].第5版.北京:人民邮电出版社, 2013.
[2] wikipedia 维基百科.DYSEAC[EB/OL].[2016-12-18].https://en.wikipedia.org/wiki/DYSEAC.
[3] CSDN.MIPS中的分支延迟槽[EB/OL].[2016-12-18]. http://blog.csdn.net/ljl1603/article/details/6553957.
[4] 博客园.RAM和ROM[EB/OL].[2016-12-18]. http://www.cnblogs.com/yinjingyu/archive/2012/02/16/2353616.html.
[5] 百度百科.微指令[EB/OL].[2016-12-18]. http://baike.baidu.com/link?url=K2G4qnCfGDRcbE6YhOOwtM8p_aVRYA8wcLK5ZGjut6oa7frkhHrtrtCZ987-ChKCPS2tx5L5ADOc89y-FRmTOq.
[6] 百度百科.VLSI[EB/OL].[2016-12-18]. http://baike.baidu.com/link?url=24h73G0JSC3OPJps9otrZ6PpwcRKHAAks7haHI_MIChnupJf13MZt2dCChH8xFUS4hTx1OiXBMNITPEZPo68qK.
六. 附录
此报告为本人原创,中山大学
转发请注明原文地址:http://www.cnblogs.com/dragonir/p/6196602.html
联系方式:dragonir@sina.cn

 浙公网安备 33010602011771号
浙公网安备 33010602011771号