CMU15445 Lecture12-13 Query Execution
Lecture 12
Query Plan

DBMS将SQL语句转换为查询计划,查询计划中的运算符排列在树上(如上图),运算符通常是二元的。数据由叶子节点流向根节点,根节点的输出为查询结果。同样的查询计划可以由多种执行方式,大多数DBMS会尽可能的使用索引扫描(Index Scan)
Processing Models
Processing Model定义了系统如何执行一个查询计划,它规定了诸如读取查询计划的方向,以及沿途在运算符之间传递什么样的数据。有不同的处理模型,对不同的工作负载有不同的权衡。

Processing Model可以实现从上到下(top-to-bottom)或从下到上(bottomto-top)地调用运算符。虽然从上到下的方法更常见,但从下到上的方法可以允许对流水线中的缓存/寄存器进行更严格的控制。

Iterator Model
迭代器模型的工作原理是为查询计划中的每个运算符实现一个Next函数,查询计划中的每个节点在查询计划中调用其子节点的Next函数,直到到达叶子节点,叶子节点开始发出元组来
进行处理。每个元组在下一个元组被检索之前尽可能地在计划中被处理。在基于磁盘的DBMS中是很有用的,因为它允许我们在访问下一个元组或页面之前充分使用内存中的每个元组。
每个查询计划运算符实现一个Next函数:
- 每次调用Next,运算符要么返回单个tuple,要么返回一个null标记(表明没有元组了)。
- 运算符循环调用Next在其孩子节点上去获取他们的tuples,然后处理。
迭代器模型也称火山模型或流水线模型。
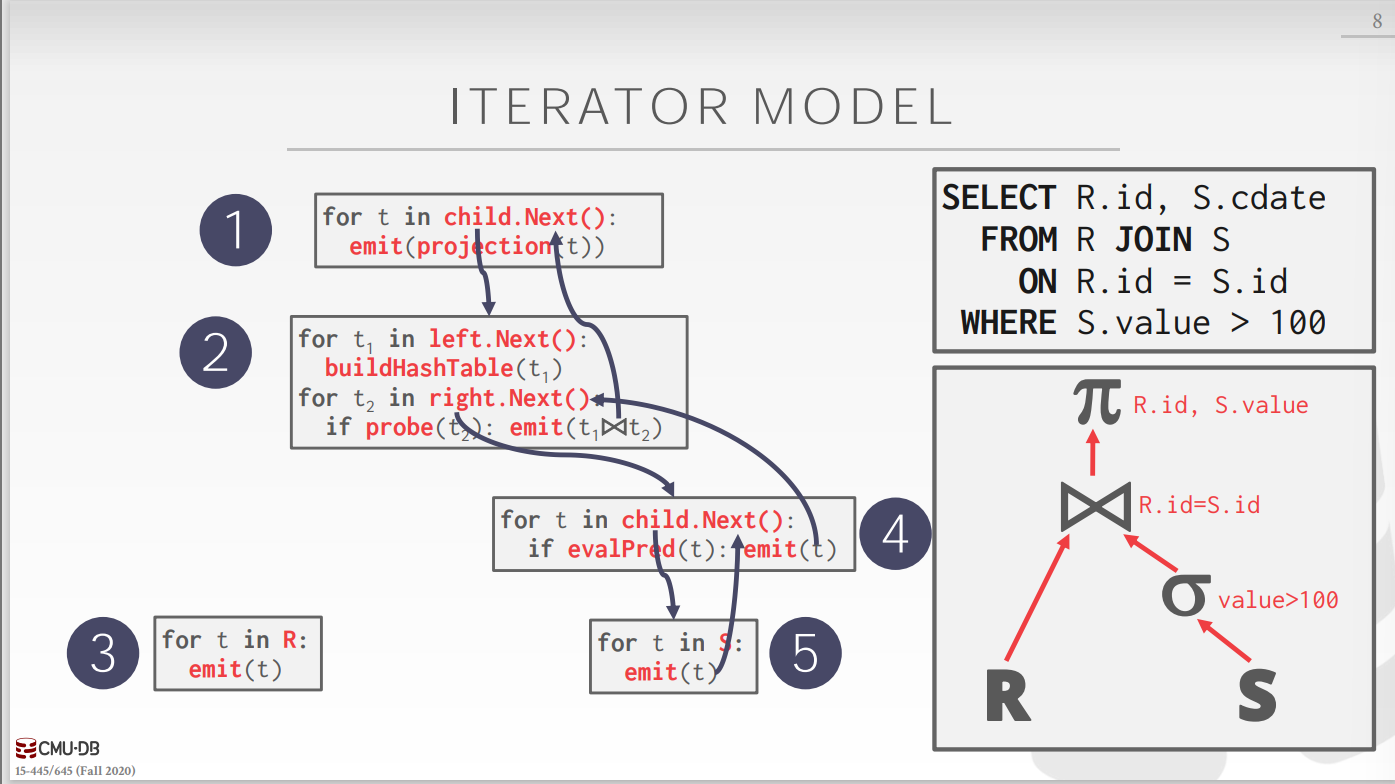
运算符joins/subqueries/order by会阻塞直到孩子发出所有的元组,称之为pipeline breakers.
输出控制使用此方法(LIMIT)很方便,操作符可以停止调用下一个子运算符一旦它具有所需的所有元组。
Materialization Model
物化模型是迭代器模型的一种特例,每个运算符都是一次性处理其输入,然后一次性发出其输出。每个运算符在每次到达时都会返回其所有的元组,而不是有一个返回单个元组的Next函数。为了避免扫描太多的元组,DBMS可以向下传播关于需要多少元组的信息给后续的运算符。运算符将其输出物化为一个单一的结果。输出可以是整个元组(NSM),也可以是一个列的子集(DSM)。
每个查询计划运算符实现一个output函数:
- 运算符一次处理来自孩子节点的所有元组
- 这个函数的返回结果是该运算符将发出的所有元组。当运算符执行完毕后,DBMS就不需要再返回去检索更多的数据了。

物化模型更适合于OLTP工作负载,因为查询一次只访问少量元组:
- 降低执行/协调开销。
- 更少的函数调用
物化模型不适合具有较大中间结果的OLAP查询,因为DBMS可能需要在运算符之间将这些结果溢出到磁盘。
Vectorization Model
与迭代器模型一样,矢量化模型的每个运算符都实现了一个Next函数。然而,每个操作符都会发出一批(即向量)数据,而不是一个单一的元组。操作符的内部循环实现被优化为处理成批的数据,而不是一次处理一个单项。批量的大小可以根据硬件或查询属性而变化。

矢量模型方法对于必须扫描大量元组的OLAP查询来说是理想的,因为对Next函数的调用较少。
允许操作者使用矢量(SIMD)指令来处理成批的元组。
Access Methods
访问方法是DBMS可以访问存储在表中的数据的一种方式。
三种基本方法:Sequential Scan, Index Scan, Multi-Index/ "Bitmap" Scan.
Sequential Scan

几个概念区分:
Heap: 堆是一个没有任何底层顺序的存储表。
Clustered Index: 替代无序heap的方法定义一个带有聚集索引的表。此索引为定义索引的表提供固有排序,并遵循定义索引的任何列顺序。在聚集索引中,插入、更新或删除行时,将保留数据的基础顺序。
Index Scan


Multi-Index Scan

PostgreSQL Bitmap indexes: https://www.postgresql.org/message-id/12553.1135634231@sss.pgh.pa.us
Modification Queries

对于insert有两种方式:
- 直接在运算符内物化元组 INSERT INTO table VALUES (value1,value2,value3);
- 插入由孩子运算符传递的元组
Halloween Problem

可能发生在聚集索引表或索引扫描上
如何避免?
首先执行定义更新的查询、创建受影响的元组列表、最后一步更新元组和索引以此来避免,但是打破执行计划增加了成本。更新操作可以被优化为首先核查是否存在万圣节问题,如果不存在,当查询处理时执行更新操作。
Expression Evaluation



Lecture 13
Background

上一节的查询假定由单个worker(线程...)执行,本节将讨论由多个worker并行执行查询。
并行执行为DBMS提供了许多关键的好处:
- 性能提升,吞吐(每秒更多的query),延迟(每个query需要更少时间)
- 提高响应性和可用性。
- 可能降低总拥有成本(TCO)。
DBMS通常支持两种并行,query间并行/query内并行
Parallel vs Distributed Databases

资源要么是指可计算的(CPU cores, CPU sockets, GPUs, 额外的机器),要么是指存储(disks, memory)。

并行DBMS资源物理接近,节点间通信高速且可靠,分布式DBMS资源分散各地,节点间通信通过公网,慢且通信故障不可忽略。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号