大模型, 底层原理探究
W_Q : 我现在想问别人什么信息:
W_K: 我是谁, 可以被别人关注吗
W_V: 我提供什么信息.

-
Q(Query):代表“我想知道什么”
-
K(Key):代表“我是谁”
-
V(Value):代表“我提供什么信息”


QK的转置
Q 是一个矩阵,每一行对应一个词的 Query 向量;
Kᵀ 是 Key 的转置矩阵,每一列对应一个词的 Key 向量。
于是 QKT 的结果是一个 词与词之间相似度(相关性)矩阵:
举一个例子:
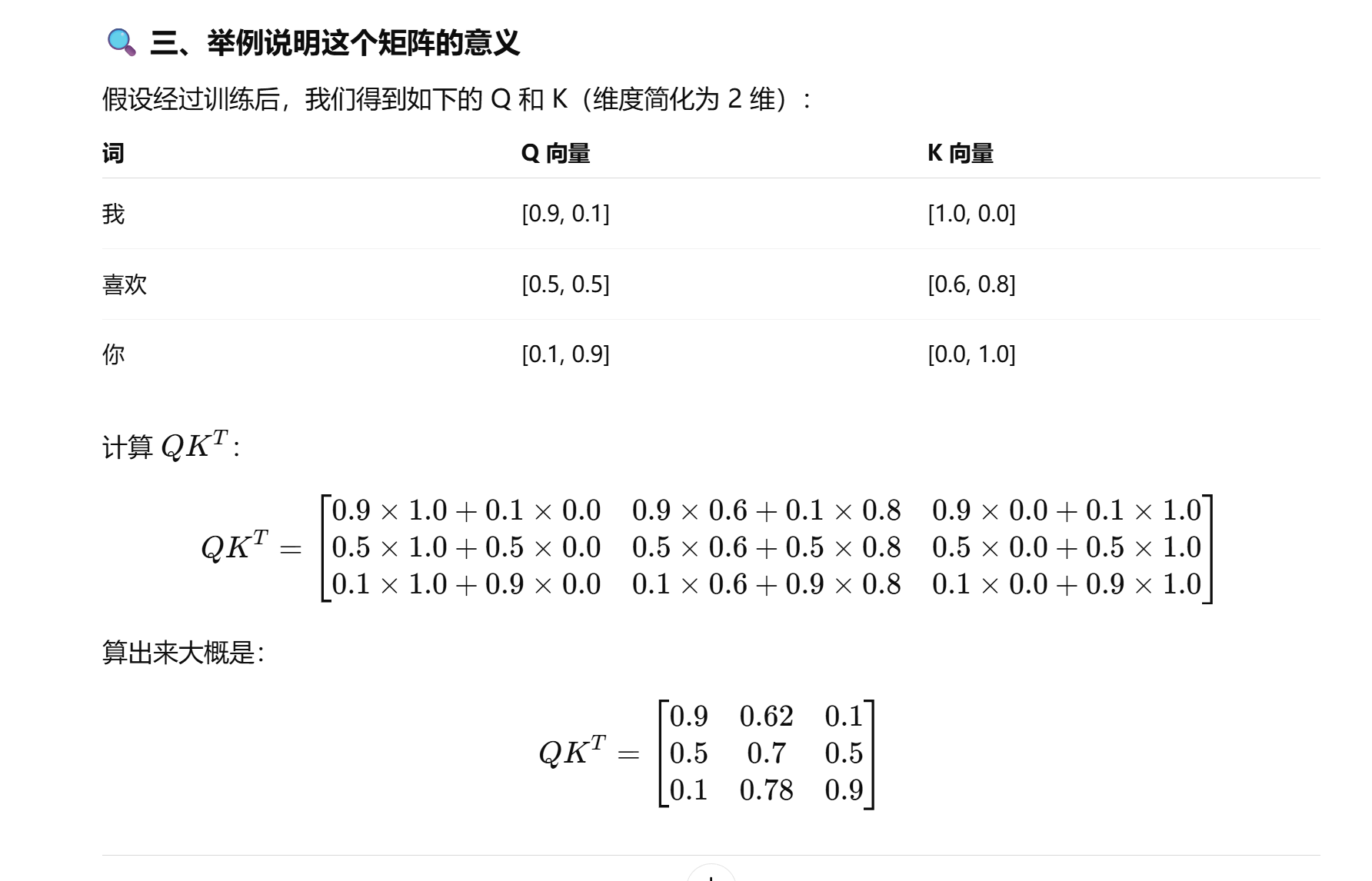
解释每一行的意义
每一行表示一个词,去“看”别的词时的注意力得分:
-
第一行(“我”):
对“我”自己最相关(0.9),对“喜欢”也有一点(0.62),对“你”几乎没关系(0.1)
👉 “我”主要关注自己。 -
第二行(“喜欢”):
对“喜欢”自己 0.7,但也对“我”和“你”都关注。
👉 “喜欢”在语义上既和主语(我)相关,也和宾语(你)相关。 -
第三行(“你”):
对“你”自己 0.9,但对“喜欢”也有较强关注(0.78)。
👉 “你”关注动词“喜欢”。五、为什么还要 softmax
Softmax 的作用是把这些相似度分数变成“概率权重”,方便后面加权求和。
比如对于“喜欢”这行
[0.5, 0.7, 0.5]:softmax(0.5,0.7,0.5)=[0.30,0.40,0.30]\text{softmax}(0.5, 0.7, 0.5) = [0.30, 0.40, 0.30]softmax(0.5,0.7,0.5)=[0.30,0.40,0.30]
意思是:
当模型在理解“喜欢”这个词时,
它 40% 的注意力放在“喜欢”自己身上,
30% 放在“我”,30% 放在“你”。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号