Ⅷ python单元测试

1.小结
2.单元测试
1.
· TestCase:一个testcase的实例就是一个测试用例
· TestSuite:多个测试用例集合在一起。TestLoader:是用来加载TestCase到TestSuite中的
· TestRunner:用来执行测试用例的。
· fixture:测试用例环境的搭建和销毁。测试前准备环境的搭建(setUp),执行测试代码(run),以及测试后环境的还原(tearDown)

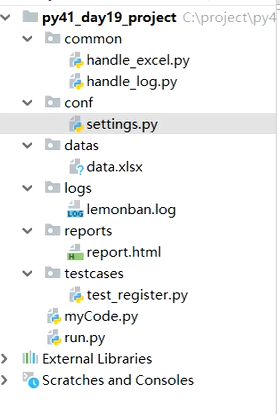
myCode.py
def counter(a, b, method):
"""
计算两个整数加减乘除的计算器
:param a: 数值1
:param b: 数值2
:param method: 数值的运算方法
:return: 运算的结果
"""
# 判断a,b是否是int类型
if isinstance(a, int) and isinstance(b, int):
if method == "+":
return a + b
elif method == "-":
return a - b
elif method == "*":
return a * b
elif method == "/":
return a / b
else:
return '计算方式有误'
else:
return '参数a和b只能为整数类型的数据'
"""
正向用例:
1、加
入参:11,22,+
预期结果:33
2、减
入参:11,22,-
预期结果:-11
3、乘
入参:2,10,*
预期结果:20
4、除
入参:20,10,/
预期结果:2.0
反向用例:
5、传入的计算方式:不是加减乘除
入参: 11,22 , a
预期结果:计算方式有误
6、传入的数值非整数类型
入参:11.3,99,+
预期结果:参数a和b只能为整数类型的数据
7、。。。
8、。。。
"""
# 手工用例:
if __name__ == '__main__':
res = counter(11, 22, '-')
print(res)
·定义一个测试用例类,测试用例类要继承unittest.TestCase
·测试用例类中,测试方法要以test_开头,就是一条测试用例
⭐继承了unittest.TestCase 会有标识;

⭐test_开头的方法也会有标识

编写测试用例示范代码如下:
demo1_testcase.py
# 在写代码之前记得要引入unittest模块以及被测试的函数counter
# 单个用例文件只能单独运行整个模块或类,或单独运行某条用例
import unittest
from myCode import counter
# 定义一个测试用例类
class TestDemo(unittest.TestCase):
def test_01add(self):
# 第一步:准备用例数据
# 用例的入参
params = {'a': 11, 'b': 22, 'method': '+'}
# 预期结果
expected = 33
# 第二步:调用功能函数(调用接口),获取实际结果
result = counter(**params)
# 第三步:比对预期结果和实际结果是否一致(python内置关键字assert断言)
# assert expected == result
# unittest封装的断言方法,断言更详细
self.assertEqual(expected, result)
def test_02(self):
# assert 11 == 22
# 第一步:准备数据
# 用例的入参
params = {'a': 11, 'b': 22, 'method': '-'}
# 预期结果
expected = -11
# 第二步:调用功能函数,获取实际结果
result = counter(**params)
# 第三步:断言
self.assertEqual(expected, result)
def test_03(self):
# self.assertEqual(11, 22)
# 第一步:准备数据
# 用例的入参
params = {'a': 2, 'b': 10, 'method': '*'}
# 预期结果
expected = 20
# 第二步:调用功能函数,获取实际结果
result = counter(**params)
# 第三步:断言
self.assertEqual(expected, result)
def test_04(self):
# 第一步:准备数据
# 用例的入参
params = {'a': 20, 'b': 10, 'method': '/'}
# 预期结果
expected = 2
# 第二步:调用功能函数,获取实际结果
result = counter(**params)
# 第三步:断言
self.assertEqual(expected, result)
def test_05(self):
# 第一步:准备数据
# 用例的入参
params = {'a': 11, 'b': 22, 'method': 'a'}
# 预期结果
expected = '计算方式有误'
# 第二步:调用功能函数,获取实际结果
result = counter(**params)
# 第三步:断言
self.assertEqual(expected, result)
def test_06(self):
# 第一步:准备数据
# 用例的入参
params = {'a': 11.3, 'b': 99, 'method': '+'}
# 预期结果
expected = '参数a和b只能为整数类型的数据'
# 第二步:调用功能函数,获取实际结果
result = counter(**params)
# 第三步:断言
self.assertEqual(expected, result)
# 编写测试用例在main函数下面
if __name__ == '__main__'
unittest.main()
测试套件:unittest.TestSuite
用例加载器:unittest.TestLoader
demo2_testsuite.py
1-用addTest增加一条用例:测试类类名(测试方法名)
# 用addTest增加一条用例:测试类类名(测试方法名)
import unittest
# 一、创建一个套件
suite = unittest.TestSuite()
# 二、增加一条用例,先加哪个套件,先执行
from work15.demo1_testcase import TestDome
suite.addTest(TestDome('test_01add'))
addTest是其中的一种加载测试用例的方式,还有一种是通过TestLoadder来加载测试用例,如下三种方式:
2-通过测试类来加载用例:load.loadTestsFromTestCase
# 添加测试类到测试套件 load.loadTestsFromTestCase
import unittest
# 一、创建一个套件
suite = unittest.TestSuite()
# print(suite) 测试套件里面还没有用例
# <unittest.suite.TestSuite tests=[]>
# 二、创建一个用例加载器
load = unittest.TestLoader()
# 三、加载用例到测试套件
# 3.1添加测试类到测试套件
from work15.demo1_testcase import TestDome
suite.addTest(load.loadTestsFromTestCase(TestDome))
# print(suite) 打印出测试类里面的所有用例
3-通过测试所在模块来加载用例-load.loadTestsFromModule
# 添加测试模块到测试套件 load.loadTestsFromModule
import unittest
# 一、创建一个套件
suite = unittest.TestSuite()
# 二、创建一个用例加载器
load = unittest.TestLoader()
# 三、加载用例到测试套件
# 3.2添加测试模块到测试套件
from work15 import demo1_testcase
suite.addTest(load.loadTestsFromModule(demo1_testcase))
4-添加一个测试的目录load.discover
# 添加一个测试的目录 load.discover
# 测试用例目录下面的用例模块必须要使用test开头(也可以通过参数pattern指定查找用例模块的规则,pattern='test*.py')
import unittest
# 一、创建一个套件
suite = unittest.TestSuite()
# 二、创建一个用例加载器
load = unittest.TestLoader()
# 三、加载用例到测试套件
# 3.3、添加一个测试的目录
suite.addTest(load.discover(r'D:\autotest\pythonn-api-test0\work15\testcase'))
5-测试中使用
import unittest
# 以上三个步骤可以简写为一行(实际使用):
suite = unittest.defaultTestLoader.discover(r'D:\autotest\pythonn-api-test0\work15\testcase')
print(suite)
测试运行程序:unittest.TextTestRunner
此为单独创建一个run.py文件
run.py
import unittest
# 方法一:将测试套件文件导入
from work15 import demo2_testsuite.py
# 创建一个测试运行程序
runner = unittest.TextTestRunner()
runner.run(demo2_testsuite.suite)
# 方法二:创建一个测试套件,加载测试用例到测试套件
# 不单独写测试集模块方法如下:
import unittest
# 方法二:加载测试用例到测试套件
suite = unittest.defaultTestLoader.discover(r'D:\autotest\pythonn-api-test0\work15\testcase')
# 创建一个测试运行程序
runner = unittest.TextTestRunner()
runner.run(suite)
执行结果:

有失败或者错误的结果:
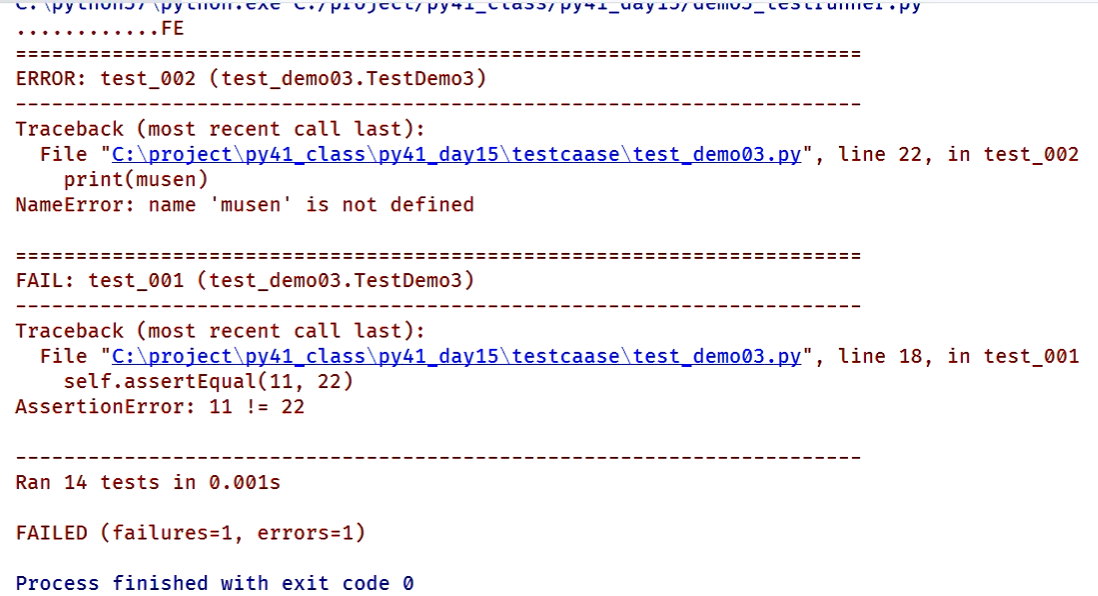

报告打开结果:
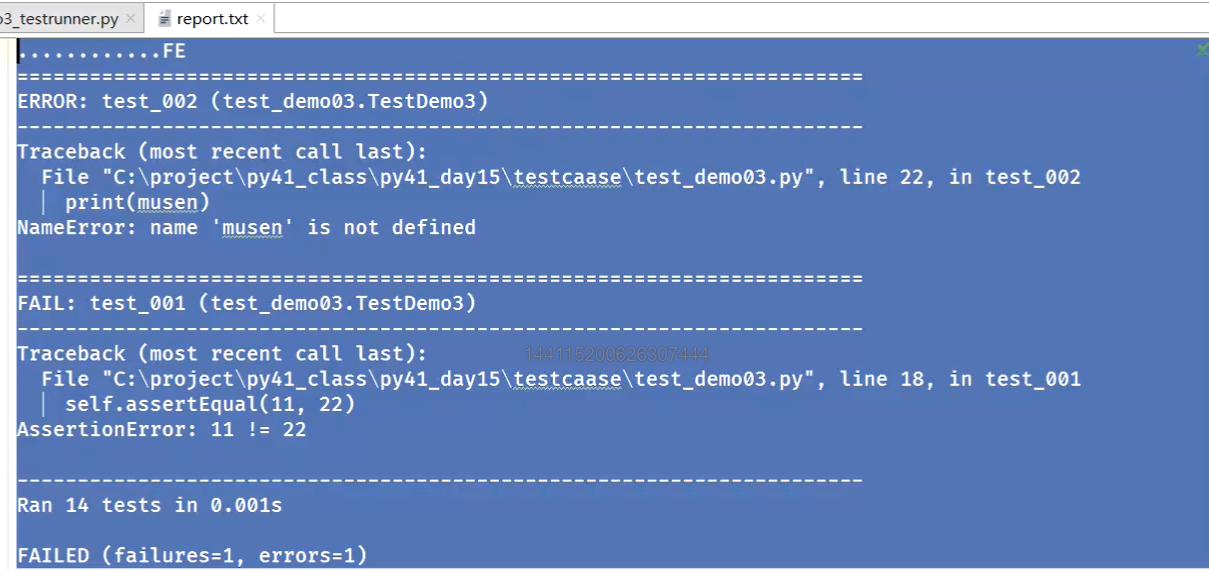
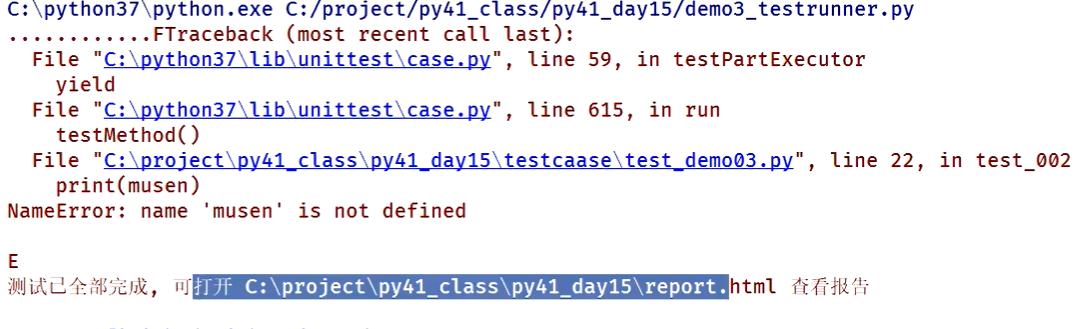
最后要生成测试报告,TextTestRunner是能够直接存储测试结果的,部分源码如下所示(暂不写):
import unittest
# 加载测试用例到测试套件
suite = unittest.defaultTestLoader.discover(r'D:\autotest\pythonn-api-test0\work15\testcase')
# 文本格式的测试报告生产(unittest自带的文本测试报告)
with open('report.txt','w',encoding='utf-8') as f:
# 通过类创建runner对象
runner = unittest.TextTestRunner(stream=f,'test',2)
# runner对象调用他的run方法
runner.run(suite)

# ---------------使用第三方的扩展库来生产测试报告---------------
# 1、安装命令:pip install BeautifulReport
import unittest
suite = unittest.defaultTestLoader.discover(r'C:\project\py41_class\py41_day15\testcase')
from BeautifulReport import BeautifulReport
br = BeautifulReport(suite)
br.report(description='花园生成的报告', filename='report.html', report_dir='./reports')
# 不指定路径,就默认生成在当前运行文件的同级目录下
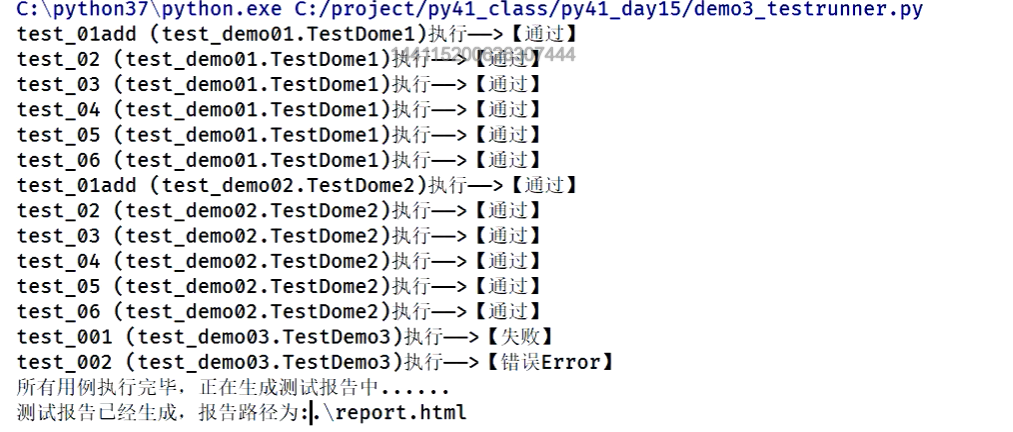
执行结果:
# 可以加镜像源地址下载
# 不要直接在settings里面下,settings里面下载是下到pycharm里面的,脱离了pycharm用不了,
后面用Jenkins跑后,如果包全部在pycharm的settings里面下的,用Jenkins跑的话包就加载不出来
# ===================2unittestreport===================
import unittest
# 安装命令:pip install unittestreport
# 官方文档:https://unittestreport.readthedocs.io/en/latest/#
suite = unittest.defaultTestLoader.discover(r'D:\autotest\pythonn-api-test0\work15\testcase')
from unittestreport import TestRunner
runner = TestRunner(suite,
filename="musen.html",
report_dir="./reports",
title='python自动化研究院生成的报告',
tester='小柠檬',
desc="500万的大项目测试报告",
templates=2
)
runner.run()
执行结果:
demo4_fixture.py
"""
测试夹具(测试用例的前后置方法):
setUp:用例级别的前置方法,每条用例执行之前都会执行
setUpClass:测试类级别的前置方法,每个测试类中的用例执行之前都会执行(只会执行一次)
tearDown:用例级别的后置方法,每条用例执行完之后都会执行
tearDownClass:测试类级别的后置方法,每个测试类中的用例全部执行完之后会执行(只会执行一次)
可以做脏数据的处理
"""

问:跑自动化时,执行过程中产生的脏数据如何清理?
# 整个测试用例跑完后,数据用不到了,可以在后置方法里面执行SQL语句删除(如果有数据库执行权限,如无,则脏数据不用你管)
接口自动化框架演变
def login_check(username=None, password=None):
"""
登录校验的函数
:param username: 账号
:param password: 密码
:return: dict type
"""
if username != None and password != None:
if username == 'python35' and password == 'lemonban':
return {"code": 0, "msg": "登录成功"}
else:
return {"code": 1, "msg": "账号或密码不正确"}
else:
return {"code": 1, "msg": "所有的参数不能为空"}
if __name__ == '__main__':
# 1、账号密码正确
res = login_check('python35', 'lemonban')
expected = {"code": 0, "msg": "登录成功"}
# if res == expected:
# print("用例:正确的账号密码 --执行通过")
assert res == expected
# 2、密码错误
res = login_check('python35', 'lemonban222')
expected = {"code": 1, "msg": "账号或密码不正确"}
assert res == expected
# if res == expected:
# print("用例:密码错误 --执行通过")
import unittest
from work16.work15.myCode import login_check
class TestLogin(unittest.TestCase):
def test_login_pass(self):
"""正向用例:登录成功"""
# 第一步:准备用例数据
params = {'username': "python35", "password": "lemonban"}
expected = {"code": 0, "msg": "登录成功"}
# 第二步:调用被测的功能函数(发送请求调用接口),获取实际结果
result = login_check(**params)
# 第三步:断言
self.assertEqual(expected, result)
def test_login_pwd_error(self):
"""反向用例:密码错误"""
#第一步:准备用例数据
params = {'username': "python35", "password": "lemonban11"}
expected = {"code": 1, "msg": "账号或密码不正确"}
# 第二步:调用被测的功能函数(发送请求调用接口),获取实际结果
result = login_check(**params)
# 第三步:断言
self.assertEqual(expected, result)
def test_login_user_error(self):
"""反向用例:账号错误"""
# 第一步:准备用例数据
params = {'username': "python3522", "password": "lemonban"}
expected = {"code": 1, "msg": "账号或密码不正确"}
# 第二步:调用被测的功能函数(发送请求调用接口),获取实际结果
result = login_check(**params)
# 第三步:断言
self.assertEqual(expected, result)
def test_login_user_and_pwd_error(self):
"""反向用例:账号密码都错误"""
# 第一步:准备用例数据
params = {'username': "python3522", "password": "lemonban111"}
expected = {"code": 1, "msg": "账号或密码不正确"}
# 第二步:调用被测的功能函数(发送请求调用接口),获取实际结果
result = login_check(**params) # (username="python3522",password="lemonban111")
# 第三步:断言
self.assertEqual(expected, result)
def test_login_user_is_none(self):
"""反向用例:账号为空"""
# 第一步:准备用例数据
param = {"password": "lemonban"}
expected = {"code": 1, "msg": "所有的参数不能为空"}
# 第二步:调用被测的功能函数(发送请求调用接口),获取实际结果
result = login_check(**params)
# 第三步:断言
self.assertEqual(expected, result)
def test_login_pwd_is_none(self):
"""反向用例:密码为空"""
# 第一步:准备用例数据
params = {'username': 'python35'}
expected = {"code": 1, "msg": "所有的参数不能为空"}
# 第二步:调用被测的功能函数(发送请求调用接口),获取实际结果
result = login_check(**params)
# 第三步:断言
self.assertEqual(expected, result)
class TestLogin2(unittest.TestCase):
def test_login_pass(self):
"""正向用例:登录成功"""
# 第一步:准备用例数据
params = {'username': "python35", "password": "lemonban"}
expected = {"code": 0, "msg": "登录成功"}
# 第二步:调用被测的功能函数(发送请求调用接口),获取实际结果
result = login_check(**params)
# 第三步:断言
self.assertEqual(expected, result)
def test_login_pwd_error(self):
"""反向用例:密码错误"""
#第一步:准备用例数据
params = {'username': "python35", "password": "lemonban11"}
expected = {"code": 1, "msg": "账号或密码不正确"}
# 第二步:调用被测的功能函数(发送请求调用接口),获取实际结果
result = login_check(**params)
# 第三步:断言
self.assertEqual(expected, result)
def test_login_user_error(self):
"""反向用例:账号错误"""
# 第一步:准备用例数据
params = {'username': "python3522", "password": "lemonban"}
expected = {"code": 1, "msg": "账号或密码不正确"}
# 第二步:调用被测的功能函数(发送请求调用接口),获取实际结果
result = login_check(**params)
# 第三步:断言
self.assertEqual(expected, result)
def test_login_user_and_pwd_error(self):
"""反向用例:账号密码都错误"""
# 第一步:准备用例数据
params = {'username': "python3522", "password": "lemonban111"}
expected = {"code": 1, "msg": "账号或密码不正确"}
# 第二步:调用被测的功能函数(发送请求调用接口),获取实际结果
result = login_check(**params) # (username="python3522",password="lemonban111")
# 第三步:断言
self.assertEqual(expected, result)
def test_login_user_is_none(self):
"""反向用例:账号为空"""
# 第一步:准备用例数据
param = {"password": "lemonban"}
expected = {"code": 1, "msg": "所有的参数不能为空"}
# 第二步:调用被测的功能函数(发送请求调用接口),获取实际结果
result = login_check(**params)
# 第三步:断言
self.assertEqual(expected, result)
def test_login_pwd_is_none(self):
"""反向用例:密码为空""" # 用例方法的文档字符串注释会当成用例的描述,测试报告里面用例描述就是这个
# 第一步:准备用例数据
params = {'username': 'python35'}
expected = {"code": 1, "msg": "所有的参数不能为空"}
# 第二步:调用被测的功能函数(发送请求调用接口),获取实际结果
result = login_check(**params)
# 第三步:断言
self.assertEqual(expected, result)
if __name__ == '__main__':
unittest.main()
import unittest
from unittestreport import TestRunner
suite = unittest.defaultTestLoader.discover(r'D:\autotest\pythonn-api-test0\work16\work15\testcases')
runner = TestRunner(suite,
filename="work15.html",
report_dir="./reports",
title='python自动化大数据研究院生成的报告',
tester='小柠檬',
desc="大数据测试报告",
templates=1
)
runner.run()
| 方法 | 检查 |
|---|---|
| assertEqual(a,b) | a==b |
| assertNotEqual(a,b) | a!=b |
| assertTrue(x) | bool(x) is True |
| assertFalse(x) | bool(x) is False |
| assertIs(a,b) | a is b |
| assertIsNOT(a,b) | a is notb |
| assertIsNone(x) | x is None |
| assertIsNotNone(x) | x is not None |
| assertIn(a,b) | a in b |
| assertNotIn(a,b) | a not in b |
| assertIsInstance(a,b) | isinstance(a,b) |
| assertIsNotInstance(a,b) | not isinstance(a,b) |
| assertGreater(a,b) | a>b |
| assertGreaterEqual(a,b) | a>=b |
| assertLess(a,b) | a<b |
| assertLessEqual(a,b) | a<=b |
# python中非0为True
# 0 0.0 0+0j "" [] {} () False 为False
# 什么地方用?web自动化-点击后是否跳转到对应的页面(找到某个东西则说明进入到了某个页面)
import unittest
class My(unittest.TestCase):
pass
#点击
#TestCase,可以查看到所有的unittest里面的断言方法
import unittest
from ddt import ddt, data
@ddt
class TestDemo(unittest.TestCase):
# 以测试数据为驱动,生成测试用例,data里面有多少条数据就生成多少条测试用例
# 每一条数据,执行用例时会当成参数传给item接收
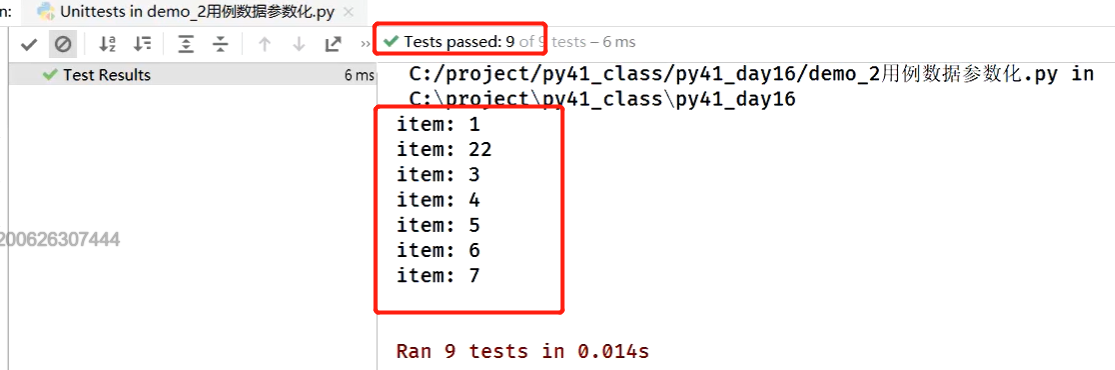
@data(1, 22, 3, 4, 5, 6, 7)
def test_login(self, item):
print('item:', item)
test_demo1.py
import unittest
from work16.work15.myCode import login_check
from ddt import ddt, data
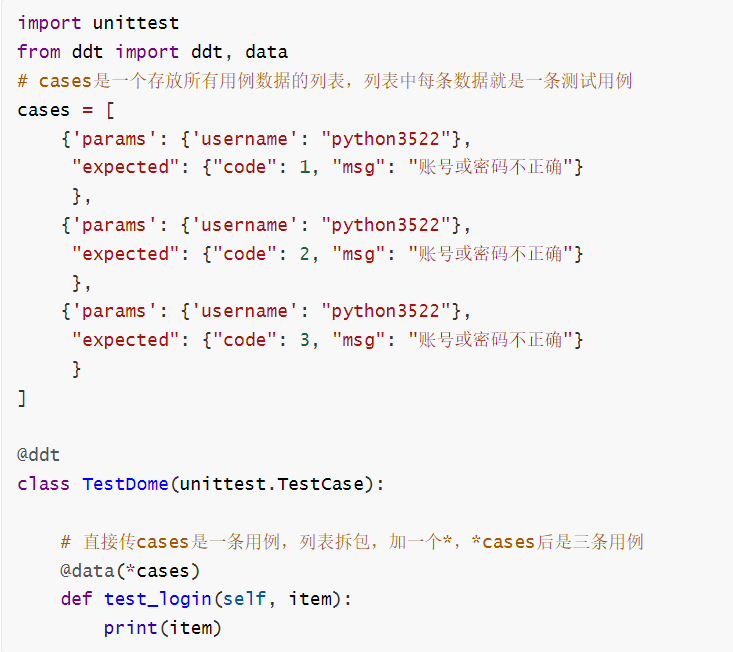
cases = [
{'params': {'username': "python35", "password": "lemonban"},
'expected': {"code": 0, "msg": "登录成功"}
},
{'params': {'username': "python35", "password": "lemonban11"},
'expected': {"code": 1, "msg": "账号或密码不正确"}
},
{'params': {'username': "python3522", "password": "lemonban"},
'expected': {"code": 1, "msg": "账号或密码不正确"}
},
{'params': {'username': "python3522", "password": "lemonban111"},
'expected': {"code": 1, "msg": "账号或密码不正确"}
},
]
@ddt
class TestLogin(unittest.TestCase):
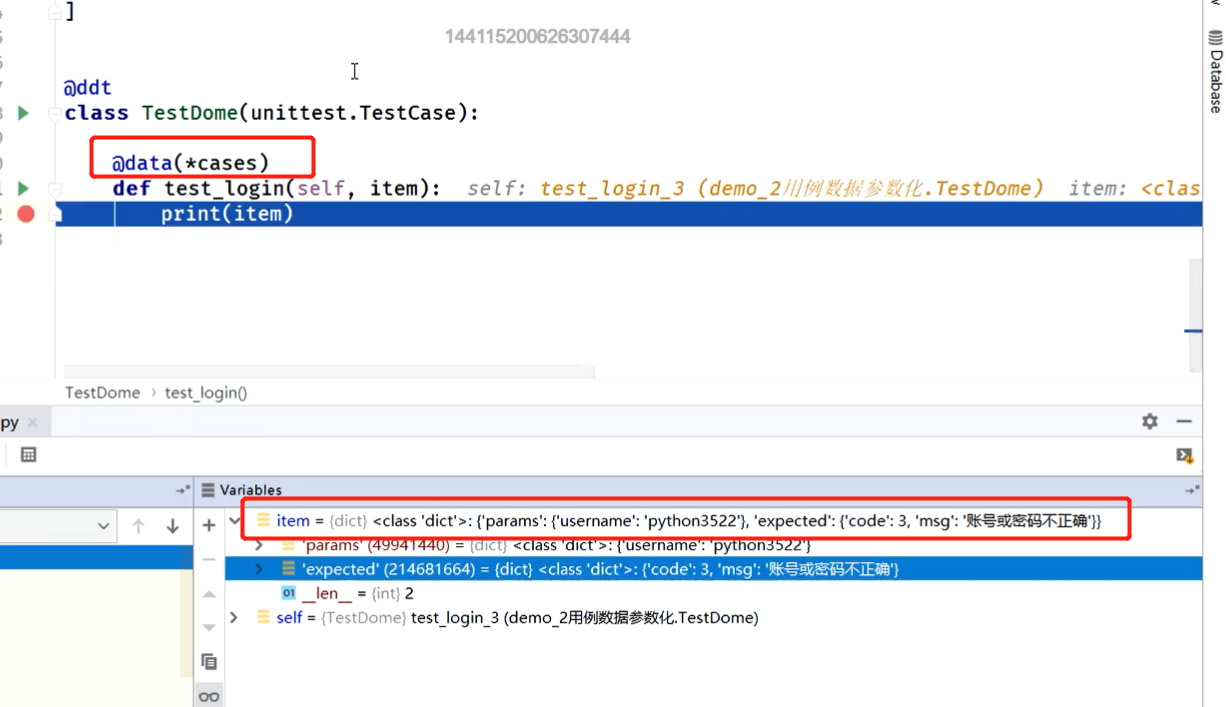
@data(*cases)
def test_login_pass(self, item):
# 删除备注,因为用例描述信息每一条用例都会一样
print('item:', item) # 通过print输出的内容会在测试报告里面显示出来
# 第一步:准备用例数据
# 解包后参数是字典,所以可以通过key取值
params = item['params']
expected = item['expected']
# 第二步:调用被测的功能函数(发送请求调用接口),获取实际结果
result = login_check(**params) # 值也是字典,**解包
# 第三步:断言
self.assertEqual(expected, result)
run.py
import unittest
from unittestreport import TestRunner
suite = unittest.defaultTestLoader.discover(r'D:\autotest\pythonn-api-test0\work16\testcases')
# 不传位置,默认在当前目录下生成report.html测试报告
runner = TestRunner(suite)
runner.run()
用例数据是列表(元组)嵌套字典的格式,title字段可以在测试报告里面添加描述
import unittest
from work16.work15.myCode import login_check
from unittestreport import ddt, list_data
# title会显示在测试报告的用例描述里
cases = [
{'params': {'username': "python35", "password": "lemonban"},
'expected': {"code": 0, "msg": "登录成功"},
'title': "正向用例:登录成功"
},
{'params': {'username': "python35", "password": "lemonban11"},
'expected': {"code": 1, "msg": "账号或密码不正确"},
'title': "反向用例:密码错误"
},
{'params': {'username': "python3522", "password": "lemonban"},
'expected': {"code": 1, "msg": "账号或密码不正确"},
'title': "反向用例:账号错误"
},
{'params': {'username': "python3522", "password": "lemonban111"},
'expected': {"code": 1, "msg": "账号或密码不正确"},
'title': "反向用例:账号密码都错误"
},
]
@ddt
class TestLogin2(unittest.TestCase):
# 不需要解包
@list_data(cases)
def test_login_pass(self, item):
print('item:', item)
# 第一步:准备用例数据
params = item['params']
expected = item['expected']
# 第二步:调用被测的功能函数(发送请求调用接口),获取实际结果
result = login_check(**params)
# 第三步:断言
self.assertEqual(expected, result)
①单独创建一个json文件,放到data文件夹里:login.json
login.json
[
{"params": {"username": "python35", "password": "lemonban"},
"expected": {"code": 0, "msg": "登录成功"},
"title": "正向用例:登录成功"
},
{"params": {"username": "python35", "password": "lemonban11"},
"expected": {"code": 1, "msg": "账号或密码不正确"},
"title": "反向用例:密码错误"
},
{"params": {"username": "python3522", "password": "lemonban"},
"expected": {"code": 1, "msg": "账号或密码不正确"},
"title": "反向用例:账号错误"
},
{"params": {"username": "python3522", "password": "lemonban111"},
"expected": {"code": 1, "msg": "账号或密码不正确"},
"title": "反向用例:账号密码都错误"
}
]
test_demo.py
import unittest
from work16.work15.myCode import login_check
from unittestreport import ddt, json_data
"""
json格式数据和python数据的不同点:
python中的列表 :[] ---->在json中叫做数组 Array
python中的字典 :{key:value} ---->在json中叫做对象 object
python中的布尔值:True False ---->在json中的布尔值 true false
python中的空值:None ---->在json中的布尔值 null
json中的引号 统一使用双引号
关于使用unittestreport中json文件数据做参数化处理:
第一步:from unittestreport import ddt, json_data
第二步:在测试类上面@ddt
第三步:在测试方法上面@json_data,传入json数据文件的路径
第四步:在测试方法中定义一个参数,用来接收json_data传递过来的用例数据
注意点:json文件中的数据 要是数组(列表)嵌套对象(字典)的格式
"""
@ddt
class TestLoginJson(unittest.TestCase):
# 传入json文件的用例数据
@json_data(r'D:\autotest\pythonn-api-test0\work16\data\login.json')
def test_login_json(self, item):
print(item) # 用例描述
# 第一步:准备用例数据
params = item['params']
expected = item['expected']
# 第二步:调用被测的功能函数(发送请求调用接口),获取实际结果
result = login_check(**params)
# 第三步:断言
self.assertEqual(expected, result)
json数据和python中数据类型的转换
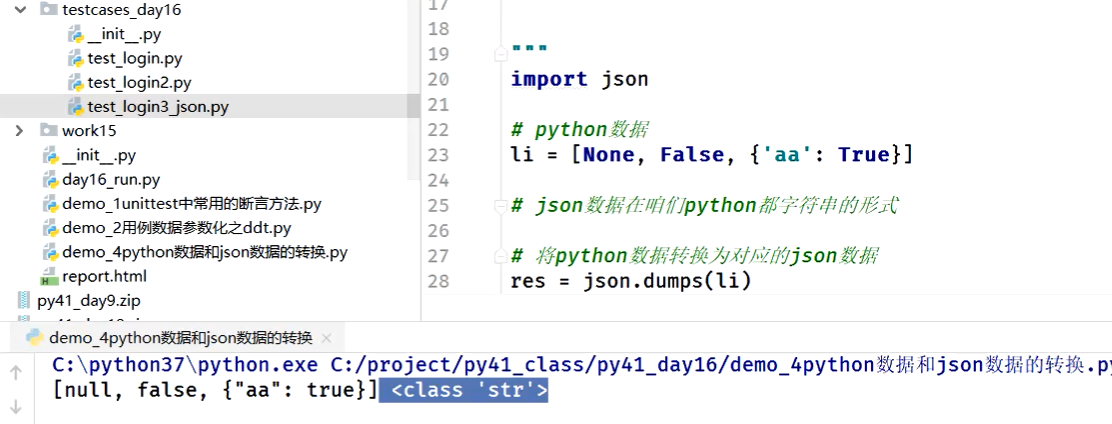
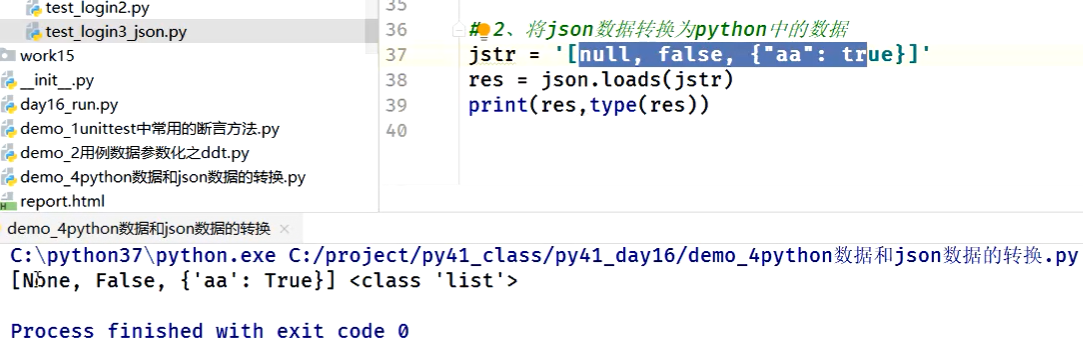
1、json.dumps:将python中的数据转换为 json数据
2、json.loads:将json数据转换为python中的数据
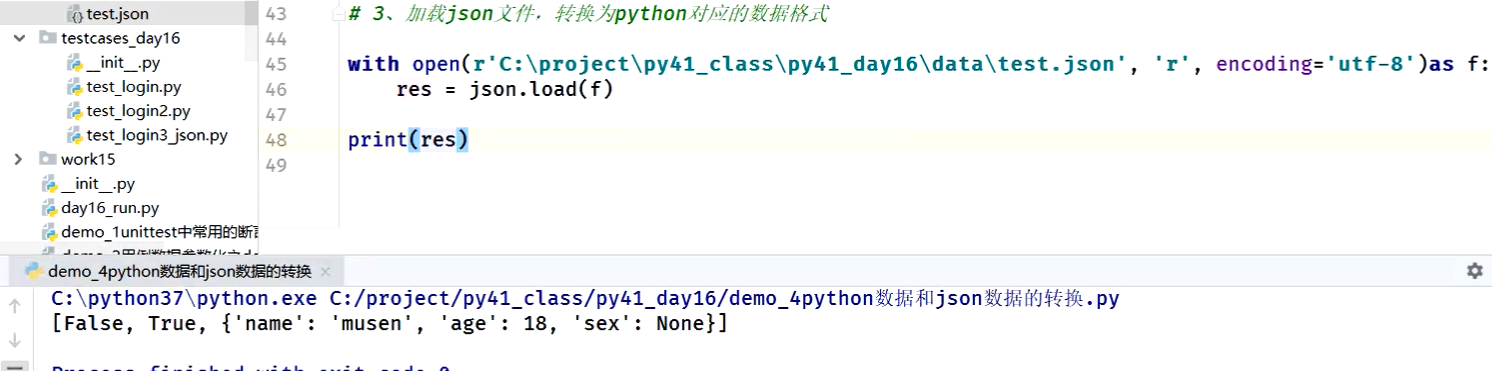
3、json.load:加载json文件,转换为python对应的数据格式
4、json.dump:将python数据,写入json文件(自动化转换格式)
⭐ crtl+R 在login.json文档里可以进行字符替换
json.loads:将json数据转换为python中的数据
json.load:加载json文件,转换为python对应的数据格式
test.json

![]()


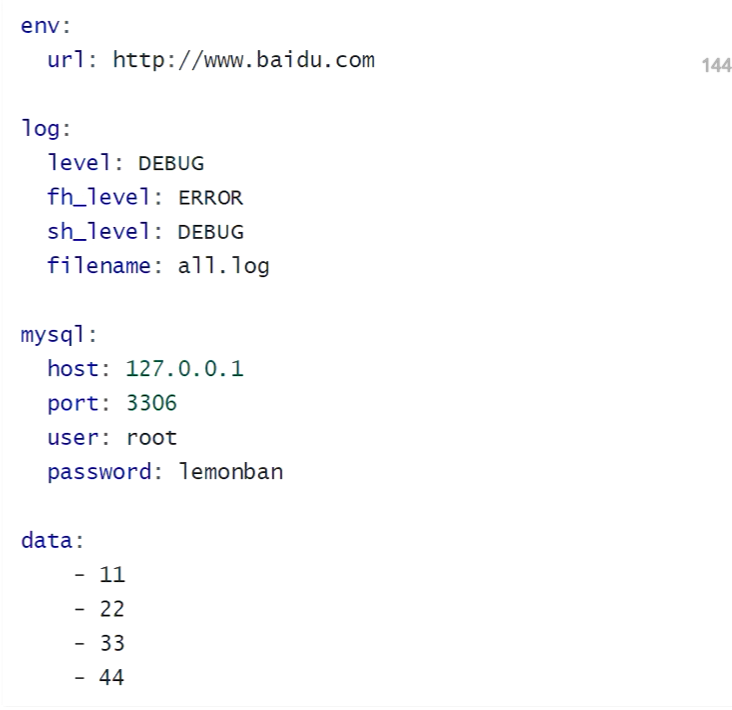
pip install pyyaml
- 11
- 22
- 33
- 44
- age: '18'
name: musen
data2.yaml
name: musen
age: 18
lists:
- 11
- 22
- 33
- 44
- 55
cases:
params: 111
expected: 22

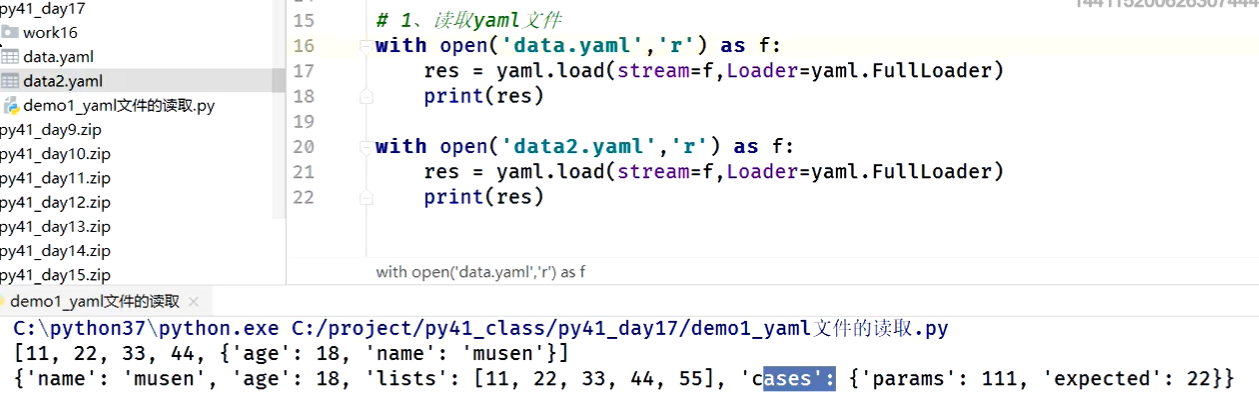
# 把文本格式的数据转换成对应的python数据(列表或字典)
![]()
import yaml
cases = [
{"excepted": {"code": 1, "msg": "注册成功"},
"params": ['python3', '123456', '123456'],
"title": "注册成功"
},
{"excepted": {"code": 0, "msg": "两次密码不一致"},
"params": ['python4', '1234567', '123456'],
"title": "两次密码不一致"
},
{"excepted": {"code": 0, "msg": "该账户已存在"},
"params": ['python31', '123456', '123456'],
"title": "账号已注册"
},
{"excepted": {"code": 0, "msg": "账号和密码必须在6-18位之间"},
"params": ['python1', '12345', '12345'],
"title": "密码长度少于6位"
},
{"excepted": {"code": 0, "msg": "账号和密码必须在6-18位之间"},
"params": ['python21', '1234561234561234567', '1234561234561234567'],
"title": "密码长度大于18位"
},
{"excepted": {"code": 0, "msg": "账号和密码必须在6-18位之间"},
"params": ['py012', '1234567', '1234567'],
"title": "账号长度少于6位"
}
]
with open('musen.yaml', 'w', encoding='utf-8') as f:
yaml.dump(cases, f, allow_unicode=True)
2.4.4 练习:用例数据与测试代码分离
①要测试的代码:myCode.py
②测试用例:testcase文件下以test_开头的py文件
③测试数据:data文件下的用例数据文件
④run.py
①myCode.py
#
users = [{'user': 'python31', 'password': '123456'}]
def register(username=None, password1=None, password2=None):
# 判断是否有参数为空
if not all([username, password1, password2]):
return {"code": 0, "msg": "所有参数不能为空"}
# 注册功能
for user in users: # 遍历出所有账号,判断账号是否存在
if username == user['user']:
# 账号存在
return {"code": 0, "msg": "该账户已存在"}
else:
if password1 != password2:
# 两次密码不一致
return {"code": 0, "msg": "两次密码不一致"}
else:
# 账号不存在 密码不重复,判断账号密码长度是否在 6-18位之间
if 6 <= len(username) <= 18 and 6 <= len(password1) <= 18:
# 注册账号
users.append({'user': username, 'password': password2})
return {"code": 1, "msg": "注册成功"}
else:
# 账号密码长度不对,注册失败
return {"code": 0, "msg": "账号和密码必须在6-18位之间"}
②test_demo.py
import unittest
from work17.work16.myCode import register
from unittestreport import ddt, list_data
cases = [
{"excepted": {"code": 1, "msg": "注册成功"},
"params": ['python3', '123456', '123456'],
"title": "注册成功"
},
{"excepted": {"code": 0, "msg": "两次密码不一致"},
"params": ['python4', '1234567', '123456'],
"title": "两次密码不一致"
},
{"excepted": {"code": 0, "msg": "该账户已存在"},
"params": ['python31', '123456', '123456'],
"title": "账号已注册"
},
{"excepted": {"code": 0, "msg": "账号和密码必须在6-18位之间"},
"params": ['python1', '12345', '12345'],
"title": "密码长度少于6位"
},
{"excepted": {"code": 0, "msg": "账号和密码必须在6-18位之间"},
"params": ['python21', '1234561234561234567', '1234561234561234567'],
"title": "密码长度大于18位"
},
{"excepted": {"code": 0, "msg": "账号和密码必须在6-18位之间"},
"params": ['py012', '1234567', '1234567'],
"title": "账号长度少于6位"
}
]
@ddt
class RegisterTestCase(unittest.TestCase):
@list_data(cases)
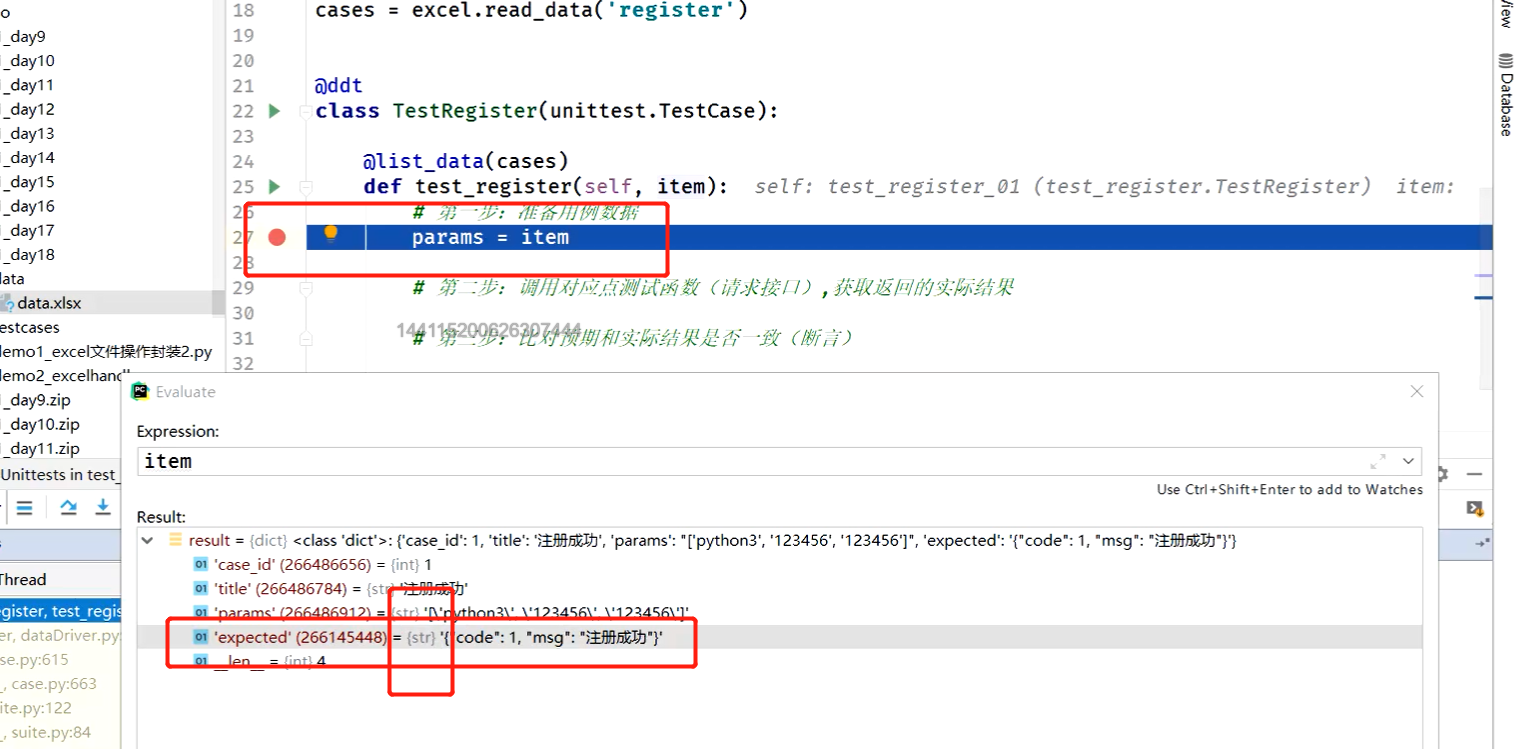
def test_register(self, item):
"""正常注册"""
# 第一步:准备用例的数据
# 预期结果:
excepted = item['excepted']
# 参数:data
data = item['params']
# 第二步:调用被测试的功能函数,传入参数,获取实际结果:
# 对列表拆包,用一个*
res = register(*data)
# 第三步:断言(比对预期结果和实际结果)
self.assertEqual(excepted, res)
③run.py
# unittest调用默认加载器defaultTestLoader,加载用例
import unittest
from unittestreport import TestRunner
# 相对路径,传入当前目录下的testcase目录,加载用例到测试套件
# 运行文件run.py和测试目录在同一级别用.
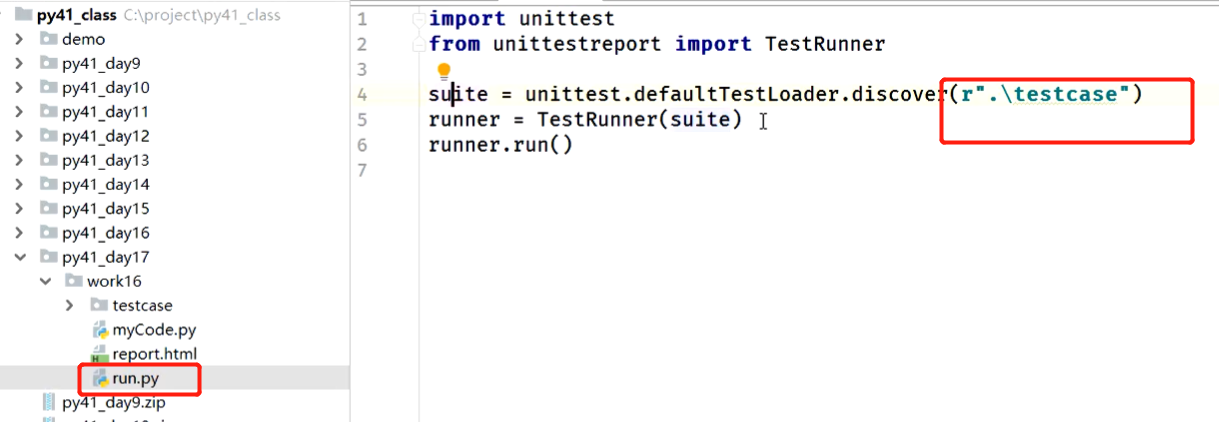
suite = unittest.defaultTestLoader.discover(r".\testcase")
# 创建一个用例运行器,传入测试套件
runner = TestRunner(suite)
# 调用运行器的run方法执行用例
runner.run()

import openpyxl
# 1、加载excel文件为一个工作簿对象(workbook)
wb = openpyxl.load_workbook(filename=r'D:\autotest\pythonn-api-test0\work17\data\data.xlsx')
# print(wb) # ①是一个Workbook对象
# 2、选中要读取的表单
login_sh = wb['login'] # ②是一个表单对象
print(login_sh) # 打印表单对象 <Worksheet "login">
# 3、读取表格中的数据(通过指定行,列取获取格子对象)
res = login_sh.cell(row=1,column=1) # ③cell是一个表格对象
print(res) # 打印格子对象 ,选中第一行第一列这个格子<Cell 'login'.A1>
# 4、获取格子中的数据(格子对象的value属性)
data = res.value
print(data)
# 5、往表格中写入数据,只是写入到工作簿对象里面
login_sh.cell(row=3,column=2,value='java666')
# 6、将最新的工作薄对象保存为文件,保存之后写入才成功
wb.save(filename=r'D:\autotest\pythonn-api-test0\work17\data\data.xlsx')
import openpyxl
# 1、加载文件为工作簿对象
wb = openpyxl.load_workbook(filename=r'D:\①testing\⑤autotest\api-test0\work17\data\data.xlsx')
# 2、选中表单
login_sh = wb['login']
# 3、按行获取表单所有的格子对象--获取出来的数据是列表嵌套元组的格式
rows = login_sh.rows
datas = list(rows)
"""
[
(<Cell 'login'.A1>, <Cell 'login'.B1>, <Cell 'login'.C1>),
(<Cell 'login'.A2>, <Cell 'login'.B2>, <Cell 'login'.C2>),
(<Cell 'login'.A3>, <Cell 'login'.B3>, <Cell 'login'.C3>)
]
"""
# # 遍历读取出来的所有数据
# for item in datas:
# # 遍历出来的item 是每行的所有格子对象
# print(item)
# for c in item:
# # c 是一个格子对象
# print(c.value)
# -----------------需求,将所有的数据读取出来组装为列表嵌套列表的格式------------
new_list = []
# 4、遍历读取出来的数据
for item in datas:
li = []
# 遍历出来的item 是每行的所有格子对象
for c in item:
# c 是一个格子对象
li.append(c.value)
print('li:', li)
# 将这一行的数据添加到new_list中
new_list.append(li)
print(new_list)

# 1、for循环往列表中添加数据
li = []
for i in range(5):
li.append('python{}'.format(i))
print(li)
# 2、列表推导式
li = ['python{}'.format(i) for i in range(5)]
print(li)
import openpyxl
# 1、加载文件为工作簿对象
wb = openpyxl.load_workbook(filename=r'D:\autotest\pythonn-api-test0\work17\data\data.xlsx')
# 2、选中表单
login_sh = wb['login']
# 3、按行获取表单所有的格子对象--获取出来的数据时列表嵌套元组的格式
rows = login_sh.rows
datas = list(rows)
# 4、通过推导式的语法读取表单中的数据
new_list = []
# 遍历读取出来的数据
for item in datas:
li = [c.value for c in item]
new_list.append(li)
print(new_list)
# new_list = [[c.value for c in item] for item in datas]
# print(new_list)

import openpyxl
# 1、加载文件为工作簿对象
wb = openpyxl.load_workbook(filename=r'D:\autotest\pythonn-api-test0\work17\data\data.xlsx')
# 2、选中表单
login_sh = wb['register']
# 3、按行获取表单所有的格子对象--获取出来的数据时列表嵌套元组的格式
rows = login_sh.rows
datas = list(rows)
# 4、通过推导式的语法读取表单中的数据
new_list = []
# 遍历读取出来的数据
for item in datas:
li = [c.value for c in item]
new_list.append(li)
# print(new_list)
"""
[
['case_id', 'title', 'params', 'expected'],
[1, '注册成功', "['python3', '123456', '123456']", '{"code": 1, "msg": "注册成功"}'],
[2, '两次密码不一致', "['python4', '1234567', '123456']", '{"code": 0, "msg": "两次密码不一致"}'],
[3, '账号已注册', "['python31', '123456', '123456']", '{"code": 0, "msg": "该账户已存在"}'],
[4, '密码长度少于6位', "['python1', '12345', '12345']", '{"code": 0, "msg": "账号和密码必须在6-18位之间"}']
]
"""
title = new_list[0]
# print('title:', title)
cases =[]
for i in new_list[1:]:
res = dict(zip(title, i))
cases.append(res)
print(cases)

import openpyxl
# 1、加载文件为工作簿对象
wb = openpyxl.load_workbook(filename=r'D:\autotest\pythonn-api-test0\work17\data\data.xlsx')
# 2、选中表单
login_sh = wb['register']
# 3、按行获取表单所有的格子对象--获取出来的数据时列表嵌套元组的格式
rows = login_sh.rows
datas = list(rows)
# 4、通过推导式的语法读取表单中的数据
new_list = []
# 5、获取表头的数据
title = [i.value for i in datas[0]]
# 6、遍历表头以外的其他行数据
for item in datas[1:]:
# 获取遍历出来的行中所有的数据
li = [c.value for c in item]
# 和表头打包为字典
d = dict(zip(title,li))
# 将打包的字典,添加搭配new_list中
new_list.append(d)
print(new_list)
# 可以用eval去掉params值的引号
"""
封装的需求:
1、方便读取excel中的数据
封装的方法:
1、封装一个读数据的方法
入参:
读取的文件(文件路径)
读取的表单(表单名)
返回值:
读取出来组装好的数据
2、写入数据的方法
入参:文件,表单,行,列,写入的值
"""
import openpyxl
class ExcelHandle:
def read_data(self, filepath, sheet):
"""
读取excel数据的方法
:param filepath: 读取的文件(文件路径)
:param sheet: 读取的表单(表单名)
:return:
"""
# 1、加载文件为工作簿对象
wb = openpyxl.load_workbook(filepath)
# 2、选中表单
sh = wb[sheet]
# 3、按行获取所有的格子对象
rows_list = list(sh.rows)
# 4、获取表头
title = [i.value for i in rows_list[0]]
cases = []
# 5、遍历表头外的其他行
for item in rows_list[1:]:
# 获取遍历出来这一行的所有数据,放到列表中
li = [i.value for i in item]
# 将表头和这一行的数据打包,转换为字典
res = dict(zip(title, li))
cases.append(res)
return cases
def write_data(self, filepath, sheet, row, column, value):
"""
:param filepath: 要写入的excel文件路径
:param sheet: 表单名
:param row: 行
:param column: 列
:param value: 写入的值
:return:
"""
# 1、加载excel文件为一个工作薄对象
wb = openpyxl.load_workbook(filepath)
# 2、选取要操作的表单
sh = wb[sheet]
# 3、写入值
# sh.cell(row=row, column=column, value=value)
sh.cell(row, column).value = value
# 4、将工作薄保存为文件
wb.save(filepath)
if __name__ == '__main__':
excel = ExcelHandle()
data = excel.read_data(r'D:\autotest\pythonn-api-test0\work18\data\data.xlsx', 'register')
# print(data)
file = r'D:\autotest\pythonn-api-test0\work18\data\data.xlsx'
# excel.write_data(file, 'Sheet2', 1, 1, 'python')
excel.write_data(file, 'login', 3, 4, '自动化测试')

"""
封装的需求:
1、方便读取excel中的数据
封装的方法:
1、封装一个读数据的方法
入参:
读取的文件(文件路径)
读取的表单(表单名)
返回值:
读取出来组装好的数据
2、写入数据的方法
入参:文件,表单,行,列,写入的值
"""
import openpyxl
class ExcelHandle:
def __init__(self, filepath):
"""
:param filepath: 要操作的文件
"""
self.file = filepath
def read_data(self, sheet):
"""
读取excel数据的方法
:param sheet: 读取的表单(表单名)
:return:
"""
# 1、加载文件为工作簿对象
wb = openpyxl.load_workbook(self.file)
# 2、选中表单
sh = wb[sheet]
# 3、按行获取所有的格子对象
rows_list = list(sh.rows)
# 4、获取表头
title = [i.value for i in rows_list[0]]
cases = []
# 5、遍历表头外的其他行
for item in rows_list[1:]:
# 获取遍历出来这一行的所有数据,放到列表中
li = [i.value for i in item]
# 将表头和这一行的数据打包,转换为字典
res = dict(zip(title, li))
cases.append(res)
return cases
def write_data(self, sheet, row, column, value):
"""
:param sheet: 表单名
:param row: 行
:param column: 列
:param value: 写入的值
:return:
"""
# 1、加载excel文件为一个工作薄对象
wb = openpyxl.load_workbook(self.file)
# 2、选取要操作的表单
sh = wb[sheet]
# 3、写入值
# sh.cell(row=row, column=column, value=value)
sh.cell(row, column).value = value
# 4、将工作薄保存为文件
wb.save(self.file)
if __name__ == '__main__':
excel = ExcelHandle(r'D:\autotest\pythonn-api-test0\work18\data\data.xlsx')
data = excel.read_data('register')
data2 = excel.read_data('login')
excel.write_data('login', 4, 1, '木森')
import unittest
from work18.demo2_excelhandle import ExcelHandle
from unittestreport import ddt, list_data
from work18.myCode import register
# 读取excel中的用例数据
excel = ExcelHandle(r'D:\autotest\pythonn-api-test0\work18\data\data.xlsx')
cases = excel.read_data('register')
""" 通过用例编号获取行号 """
# @ddt
# class TestRegister(unittest.TestCase):
#
# @list_data(cases)
# def test_register(self, item):
# # 第一步:准备用例数据
# # 如果参数中有true null等使用json.loads
# params = eval(item['params'])
# expected = eval(item['expected'])
# case_id = item['case_id']
# # 第二步:调用对应de测试函数(请求接口),获取返回的实际结果
# result = register(*params)
# try:
# # 第三步:比对预期和实际结果是否一致(断言)
# self.assertEqual(expected, result)
# except AssertionError as e:
# excel.write_data('register', row=case_id + 1, column=5, value='执行不通过')
# print('不通过')
# # 捕获到断言异常之后,一定要使用raise抛出异常,不然unittest监测不到这是一条失败的用例
# raise e
# else:
# excel.write_data('register', row=case_id + 1, column=5, value='通过')
# print('通过')
""" 通过索引获取行号,索引从0开始,与行号相差2"""
@ddt
class TestRegister(unittest.TestCase):
@list_data(cases)
def test_register(self, item):
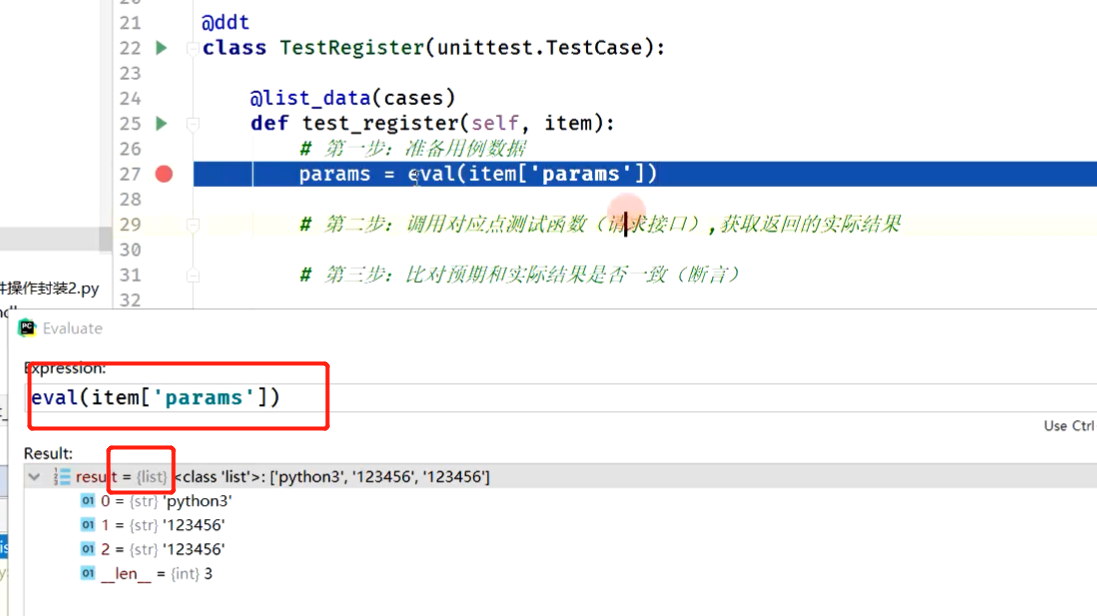
# 第一步:准备用例数据
params = eval(item['params'])
expected = eval(item['expected'])
# 获取行号,用列表的index方法
r = cases.index(item) + 2
# 第二步:调用对应点测试函数(请求接口),获取返回的实际结果
result = register(*params)
try:
# 第三步:比对预期和实际结果是否一致(断言)
self.assertEqual(expected, result)
except AssertionError as e:
excel.write_data('register', row=r, column=5, value='执行不通过')
# 捕获到断言异常之后,一定要使用raise抛出异常,不然unittest是监测不到这是一条失败的用例
raise e
else:
excel.write_data('register', row=r, column=5, value='通过')
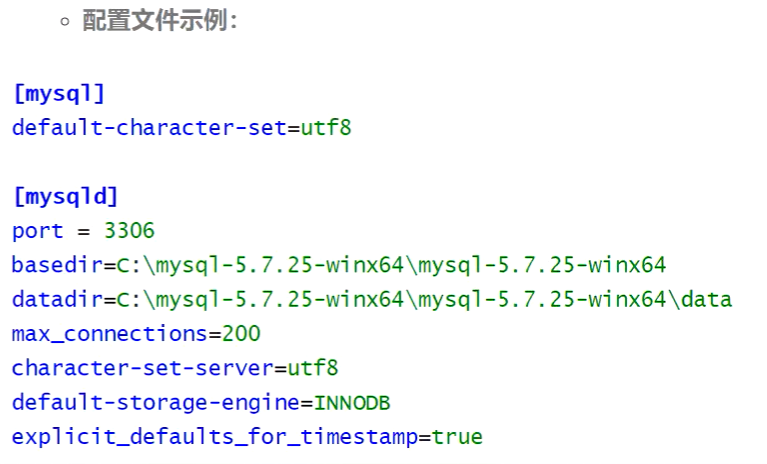
from configparser import ConfigParser
filepath = r'D:\autotest\pythonn-api-test0\work18\data\musem.ini'
# 创建一个配置文件解析器对象
conf = ConfigParser()
# 通过解析器去解析配置文件
conf.read(filepath, encoding='utf-8')
# 返回的是配置文件名称,可以不接收
# 读取配置文件中的配置
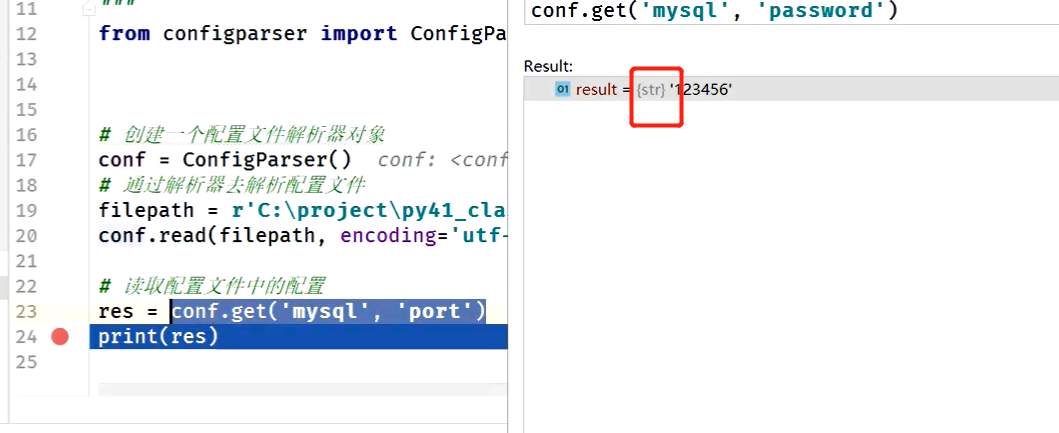
# 1、get方法:读取出来的数据是字符串
res = conf.get('mysql', 'port')
print(res)
# 2、getint : # ----->int(get()) 只能读取数值
res = conf.getint('mysql', 'user')
print(res, type(res))
# 3、getfloat : # ----->float(get())
res = conf.getfloat('mysql', 'port')
print(res, type(res))
# 4、getboolean: # ----->bool(get),只能读取bool值
res = conf.getboolean('mysql', 'status')
print(res,type(res))
# 了解即可
from configparser import ConfigParser
# 1、创建一个配置文件解析器对象
conf = ConfigParser()
# 2、通过解析器去解析配置文件
filepath = r'D:\autotest\pythonn-api-test0\work18\data\musem.ini'
conf.read(filepath, encoding='utf-8')
# 3、往配置文件中写入数据,section option value
conf.set('logging', 'name', 'p99999999999999')
# 4、将写入的内容保存到配置文件
with open(filepath, 'w', encoding='utf-8') as f:
conf.write(f)


from configparser import ConfigParser
# 创建一个配置文件解析器对象
conf = ConfigParser()
# 通过解析器去解析配置文件
filepath = r'D:\autotest\pythonn-api-test0\work18\data\musem.ini'
conf.read(filepath, encoding='utf-8')
# ①获取配置文件中所有的配置块
sections = conf.sections()
print(sections)
if 'db' in sections:
res = conf.get('db', 'port')
print(res)
else:
res = 'report.log'
from configparser import ConfigParser
# 创建一个配置文件解析器对象
conf = ConfigParser()
# 通过解析器去解析配置文件
filepath = r'D:\autotest\pythonn-api-test0\work18\data\musem.ini'
conf.read(filepath, encoding='utf-8')
res = conf.options('mysql')
print(res) # 获取某配置块下所有的配置项
if 'db' in conf.sections() and 'port' in conf.options('db'):
res = conf.get('db', 'port')
print(res)
else:
res = 'report.log'
from configparser import ConfigParser
# 创建一个配置文件解析器对象
conf = ConfigParser()
# 通过解析器去解析配置文件
filepath = r'D:\autotest\pythonn-api-test0\work18\data\musem.ini'
conf.read(filepath, encoding='utf-8')
# 列表嵌套元组
res = conf.items('mysql')
print(res)
# 转换为字典
res = dict(conf.items('mysql'))
print(res)
![]()
![]()
from configparser import ConfigParser
class CfgParser(ConfigParser):
# 重写配置文件解释器对象ConfigParser里面的init方法
def __init__(self, file, encoding='utf-8'):
# 调用被重写的父类方法
super().__init__()
# 初始化时候就把配置文件对象传入进来,加载配置文件到配置文件解析器
# 因为只有read方法使用了file,所以不用单独保存file属性
# 如果封装了一个写入的方法,就可以将file属性保存
# 封装就是简化加载那一步(要加载再读)
self.read(file, encoding=encoding)
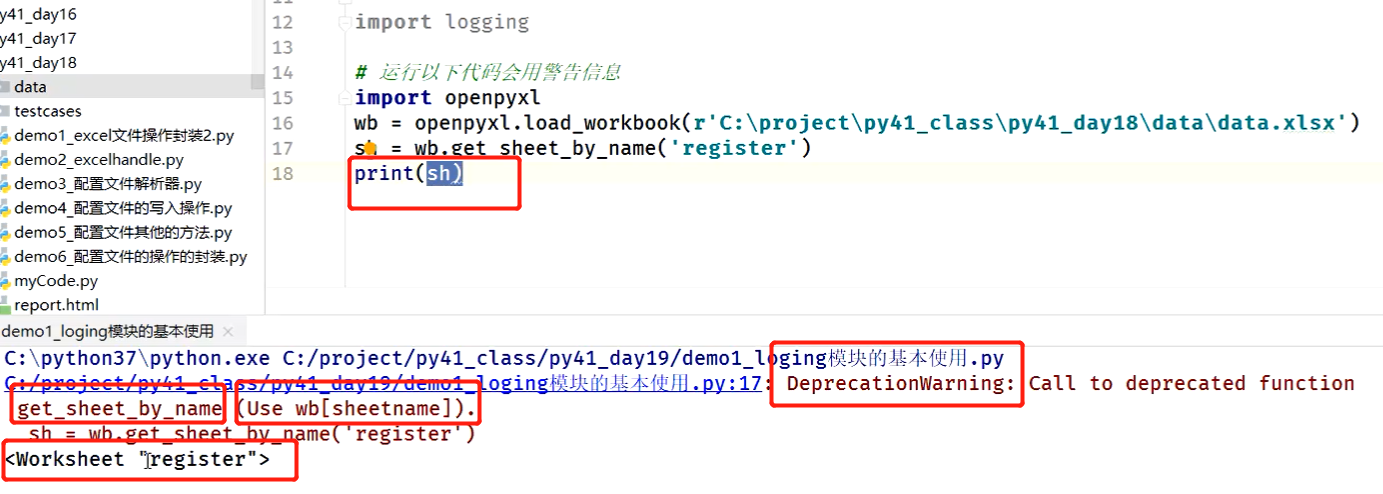
if __name__ == '__main__':
conf = CfgParser(r'D:\autotest\pythonn-api-test0\work18\data\musem.ini')
# 要解析哪个配置文件,直接传给conf就可以了;初始化后,就已经创建了一个配置文件解析器,可以直接读取配置文件内容,不用再调用read方法去加载了
res = conf.get('mysql', 'user')
print(res)




import logging
# 日志收集器的创建:logging.getLogger(日志收集器名称)
http_log = logging.getLogger('HTTP')
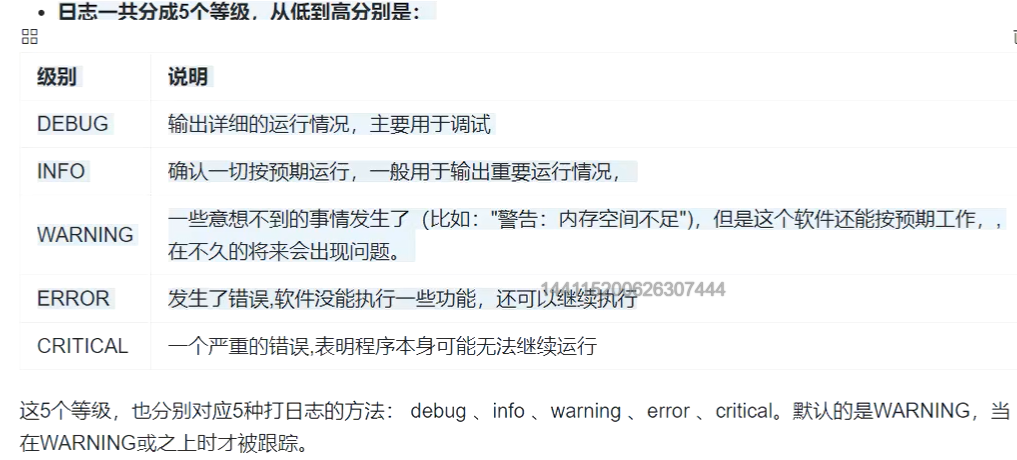
# 设置日志收集的等级为DEBUG,还要设置日志输出的等级。。
http_log.setLevel('DEBUG')
http_log.debug('----------DEBUG----------')
http_log.info('----------info----------')
http_log.warning('----------warning----------')
http_log.error('----------error----------')
http_log.critical('----------critical----------')
# 自己创建的日志收集器没有设置日志输出格式:只输出日志内容

import logging
# 1、日志收集器的创建:logging.getLogger(日志收集器名称)
http_log = logging.getLogger('HTTP')
# 2、设置日志收集的等级为DEBUG
http_log.setLevel('DEBUG')
# 3、创建一个日志输出渠道(控制台)
sh = logging.StreamHandler()
sh.setLevel('DEBUG')
# 4、将日志输出渠道添加到日志收集器中
http_log.addHandler(sh)
http_log.debug('----------DEBUG-------------')
http_log.info('----------info-------------')
http_log.warning('----------warning-------------')
http_log.error('----------error-------------')
http_log.critical('----------critical-------------')

import logging
# 1、日志收集器的创建:logging.getLogger(名称)
http_log = logging.getLogger('HTTP')
# 2、设置日志收集的等级为DEBUG
http_log.setLevel('DEBUG')
# 3、创建一个日志输出渠道(控制台)
sh = logging.StreamHandler()
sh.setLevel('DEBUG')
# 4、将日志输出渠道添加到日志收集器中
http_log.addHandler(sh)
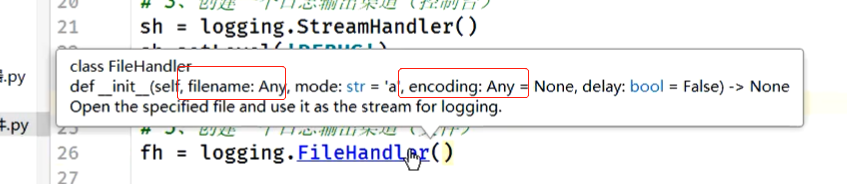
# 5、创建一个日志输出渠道(文件)
# fh = logging.FileHandler('musen.log', encoding='utf-8')
fh = logging.FileHandler(r'D:\①testing\⑤autotest\api-test0\work19\logs\lemon.log', encoding='utf-8')
fh.setLevel('ERROR')
# 6、将日志输出渠道添加到日志收集器
http_log.addHandler(fh)
http_log.debug('----------DEBUG---人人----------')
http_log.info('----------info---哈哈----------')
http_log.warning('----------warning---啊啊----------')
http_log.error('----------error---嗷嗷的----------')
http_log.critical('----------critical---哎哎哎----------')

# pycharm设置的文件默认是utf-8编码格式打开,创建日志输出渠道的时候没有设置输出到文件的编码格式,默认会是GBK
# 自动生成一个日志文件
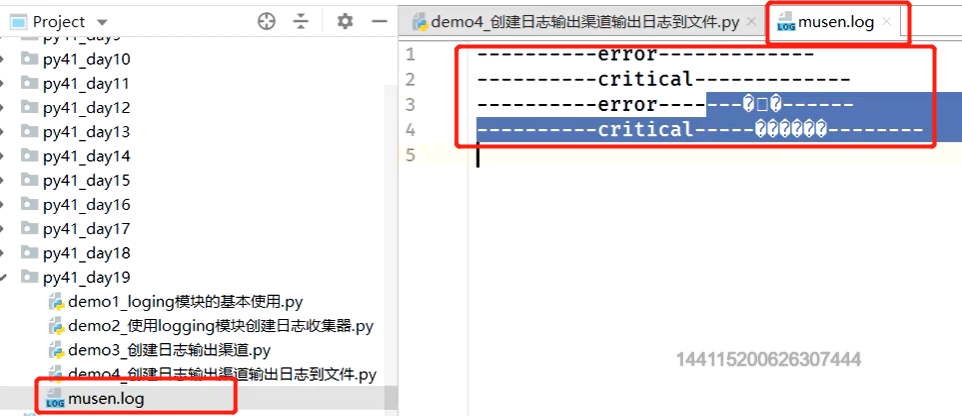

import logging
# 1、日志收集器的创建:logging.getLogger(名称)
http_log = logging.getLogger('HTTP')
# 2、设置日志收集的等级为DEBUG
http_log.setLevel('DEBUG')
# 创建一个日志输出的格式
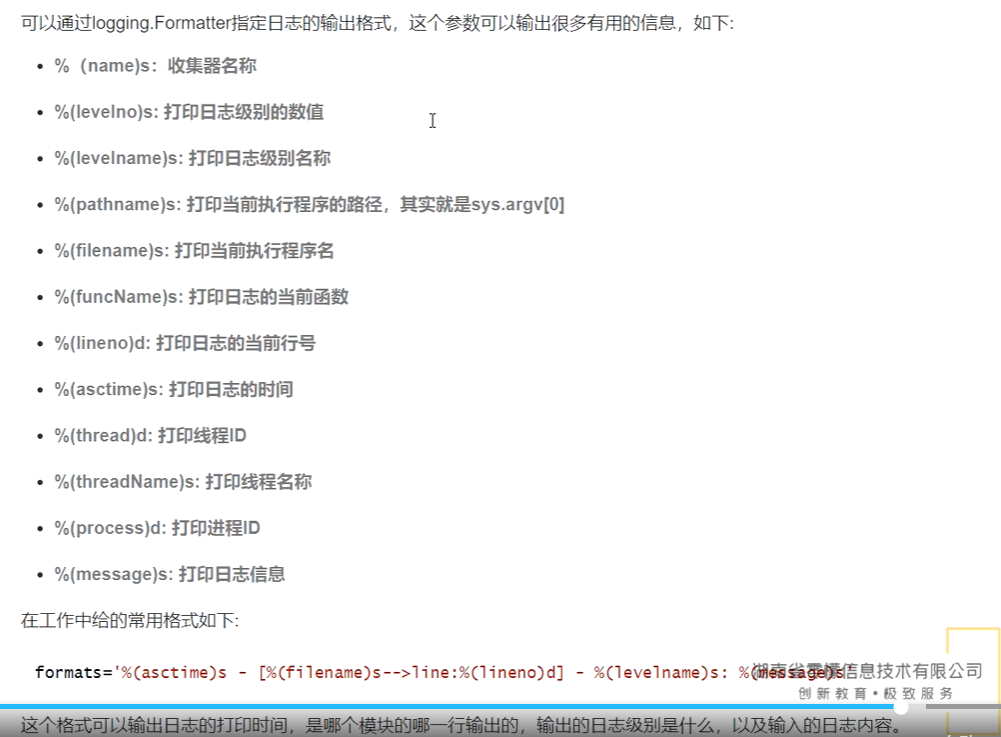
mat= logging.Formatter('%(asctime)s - [%(filename)s-->line:%(lineno)d] - %(levelname)s: %(message)s')
# 3、创建一个日志输出渠道(控制台)
sh = logging.StreamHandler()
sh.setLevel('DEBUG')
sh.setFormatter(mat)
# 4、将日志输出渠道添加到日志收集器中
http_log.addHandler(sh)
# 5、创建一个日志输出渠道(文件)
fh = logging.FileHandler(r'D:\autotest\api-test0\work19\logs\lemon.log', encoding='utf-8')
fh.setLevel('ERROR')
fh.setFormatter(mat)
# 6、将日志输出渠道添加到日志收集器
http_log.addHandler(fh)
http_log.debug('----------DEBUG---人人----------')
http_log.info('----------info---哈哈----------')
http_log.warning('----------warning---啊啊----------')
http_log.error('----------error---嗷嗷的----------')
http_log.critical('----------critical---哎哎哎----------')


# 可以查看Formatter源码看他的日志格式怎么设置
import logging
def create_logger(name, level, f_level, s_level, filepath):
"""
创建日志收集器
:param name: 日志收集器的名称
:param level: 收集器的收集等级
:param f_level: 输出到文件的等级
:param s_level: 输出到控制台的等级
:param filepath: 日志文件的名称
:return:
"""
# 1、日志收集器的创建:logging.getLogger(名称)
http_log = logging.getLogger(name)
# 2、设置日志收集的等级为DEBUG
http_log.setLevel(level)
# 创建一个日志输出的格式
mat = logging.Formatter('【%(name)s】 | [%(asctime)s] | %(levelname)s: %(message)s')
# 3、创建一个日志输出渠道(控制台)
sh = logging.StreamHandler()
sh.setLevel(s_level)
sh.setFormatter(mat)
# 4、将日志输出渠道添加到日志收集器中
http_log.addHandler(sh)
# 5、创建一个日志输出渠道(文件)
fh = logging.FileHandler(filepath, encoding='utf-8')
fh.setLevel(f_level)
fh.setFormatter(mat)
# 6、将日志输出渠道添加到日志收集器
http_log.addHandler(fh)
return http_log
log = create_logger(xxx)
if __name__ == '__main__':
# 封装的文件里面已经调用了create_logger函数,下面就不需要再调用一次了
# log = create_logger(name='MUSEN', level='DEBUG', f_level='DEBUG', s_level='DEBUG', filepath='./lemonban.log')
log.debug('这是DEBUG等级的信息')
log.info('这是INFO等级的信息')
log.warning('这是WARNING等级的信息')
log.error('这是ERROR等级的信息')
log.critical('这是CRITICAL等级的信息')
# 还未分离出参数时,未参数化时在别的地方调用日志函数log对象
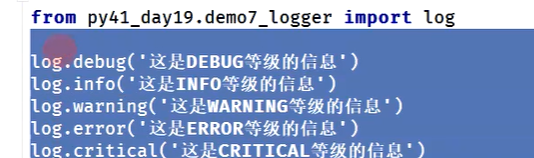
⭐不在模块里面调用函数时,在测试用例中引用参数化后的日志
from demo7_logger import create_logger
log = create_logger(name='MUSEN', level='DEBUG', f_level='DEBUG', s_level='DEBUG', filepath='./lemonban.log')
log.debug('这是DEBUG等级的信息')
log.info('这是INFO等级的信息')
log.warning('这是WARNING等级的信息')
log.error('这是ERROR等级的信息')
log.critical('这是CRITICAL等级的信息')


import logging
from logging.handlers import RotatingFileHandler, TimedRotatingFileHandler
# def create_logger(name, level, f_level, s_level, filepath):
# """
# 创建日志收集器(按文件大小进行轮转)
# :param name: 日志收集器的名称
# :param level: 收集器的收集等级
# :param f_level: 输出到文件的等级
# :param s_level: 输出到控制台的等级
# :param filepath: 日志文件的名称
# :return:
# """
# # 1、日志收集器的创建:logging.getLogger(名称)
# http_log = logging.getLogger(name)
# # 2、设置日志收集的等级为DEBUG
# http_log.setLevel(level)
# # 创建一个日志输出的格式
# mat = logging.Formatter('【%(name)s】 | [%(asctime)s] | %(levelname)s: %(message)s')
# # 3、创建一个日志输出渠道(控制台)
# sh = logging.StreamHandler()
# sh.setLevel(s_level)
# sh.setFormatter(mat)
# # 4、将日志输出渠道添加到日志收集器中
# http_log.addHandler(sh)
# # 5、创建一个日志输出渠道(输出到文件的轮转器)
# fh = RotatingFileHandler(filepath, maxBytes=1024*1024*10, backupCount=3, encoding='utf-8')
# fh.setLevel(f_level)
# fh.setFormatter(mat)
# # 6、将日志输出渠道添加到日志收集器
# http_log.addHandler(fh)
# return http_log
def create_logger(name, level, f_level, s_level, filepath):
"""
创建日志收集器(按时间进行轮转)
:param name: 日志收集器的名称
:param level: 收集器的收集等级
:param f_level: 输出到文件的等级
:param s_level: 输出到控制台的等级
:param filepath: 日志文件的名称
:return:
"""
# 1、日志收集器的创建:logging.getLogger(名称)
http_log = logging.getLogger(name)
# 2、设置日志收集的等级为DEBUG
http_log.setLevel(level)
# 创建一个日志输出的格式
mat = logging.Formatter('【%(name)s】 | [%(asctime)s] | %(levelname)s: %(message)s')
# 3、创建一个日志输出渠道(控制台)
sh = logging.StreamHandler()
sh.setLevel(s_level)
sh.setFormatter(mat)
# 4、将日志输出渠道添加到日志收集器中
http_log.addHandler(sh)
# 5、创建一个日志输出渠道(输出到文件的轮转器)
# 按时间轮转
fh = TimedRotatingFileHandler(filepath, encoding='utf-8', when='S', interval=2, backupCount=7)
fh.setLevel(f_level)
fh.setFormatter(mat)
# 6、将日志输出渠道添加到日志收集器
http_log.addHandler(fh)
return http_log
log = create_logger(name='MUSEN', level='DEBUG', f_level='DEBUG', s_level='DEBUG', filepath='./logs/lemonban.log')
if __name__ == '__main__':
import time
###
log.debug('这是DEBUG等级的信息')
time.sleep(1)
log.info('这是INFO等级的信息')
time.sleep(1)
log.warning('这是WARNING等级的信息')
time.sleep(1)
log.error('这是ERROR等级的信息')
time.sleep(1)
log.critical('这是CRITICAL等级的信息')


![]()
3.4)代码编写
"""
封装读取excel数据的方法
"""
import openpyxl
class ExcelHandle:
def __init__(self, filepath):
"""
:param filepath: 要操作的文件
"""
self.file = filepath
def read_data(self, sheet):
"""
读取excel数据的方法
:param sheet: 读取的表单(表单名)
:return:
"""
# 1、加载文件为工作簿对象
wb = openpyxl.load_workbook(self.file)
# 2、选中表单
sh = wb[sheet]
# 3、按行获取所有的格子对象
rows_list = list(sh.rows)
# 4、获取表头
title = [i.value for i in rows_list[0]]
cases = []
# 5、遍历表头外的其他行
for item in rows_list[1:]:
# 获取遍历出来这一行的所有数据,放到列表中
li = [i.value for i in item]
# 将表头和这一行的数据打包,转换为字典
res = dict(zip(title, li))
cases.append(res)
return cases
def write_data(self, sheet, row, column, value):
"""
:param sheet: 表单名
:param row: 行
:param column: 列
:param value: 写入的值
:return:
"""
# 1、加载excel文件为一个工作薄对象
wb = openpyxl.load_workbook(self.file)
# 2、选取要操作的表单
sh = wb[sheet]
# 3、写入值
# sh.cell(row=row, column=column, value=value)
sh.cell(row, column).value = value
# 4、将工作薄保存为文件
wb.save(self.file)
import logging
from logging.handlers import TimedRotatingFileHandler
from conf.settings import LOG
def create_logger(name, level, f_level, s_level, filepath):
"""
创建日志收集器(按时间进行轮转)
:param name: 日志收集器的名称
:param level: 收集器的收集等级
:param f_level: 输出到文件的等级
:param s_level: 输出到控制台的等级
:param filepath: 日志文件的名称
:return:
"""
# 1、日志收集器的创建:logging.getLogger(名称)
http_log = logging.getLogger(name)
# 2、设置日志收集的等级为DEBUG
http_log.setLevel(level)
# 创建一个日志输出的格式
mat = logging.Formatter('【%(name)s】 | [%(asctime)s] | %(levelname)s: %(message)s')
# 3、创建一个日志输出渠道(控制台)
sh = logging.StreamHandler()
sh.setLevel(s_level)
sh.setFormatter(mat)
# 4、将日志输出渠道添加到日志收集器中
http_log.addHandler(sh)
# 5、创建一个日志输出渠道(输出到文件的轮转器)
fh = TimedRotatingFileHandler(filepath, encoding='utf-8', when='D', interval=1, backupCount=7)
fh.setLevel(f_level)
fh.setFormatter(mat)
# 6、将日志输出渠道添加到日志收集器
http_log.addHandler(fh)
return http_log
log = create_logger(**LOG)
# 日志输出的相关配置
LOG = {
'name': 'MUSEN',
'level': 'DEBUG',
'f_level': 'DEBUG',
's_level': 'ERROR',
'filepath': 'D:\\①testing\\⑤autotest\\api-test1\\logs\\lemonban.log'
}

import unittest
from common.handle_excel import ExcelHandle
from unittestreport import ddt, list_data
from myCode import register
from common.handle_log import log
excel = ExcelHandle(r'D:\①testing\⑤autotest\api-test1\datas\data.xlsx')
cases = excel.read_data('register')
@ddt
class TestRegister(unittest.TestCase):
@list_data(cases)
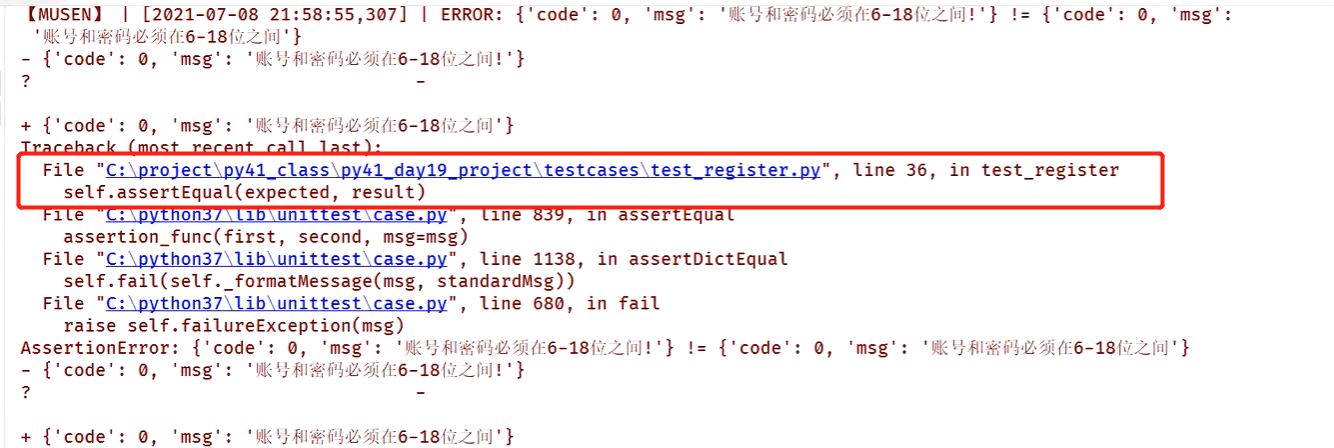
def test_register(self, item):
# 第一步:准备数据
params = eval(item['params'])
expected = eval(item['expected'])
# 第二步:调用功能函数(调用接口),获取实际结果
result = register(*params)
log.info('预期结果:{}'.format(expected))
log.info('实际结果:{}'.format(result))
# 第三:断言
try:
self.assertEqual(expected, result)
except AssertionError as e:
log.error('【{}】-- 用例执行失败'.format(item['title']))
# 输出断言的异常信息
# log.error(e)
log.exception(e)
raise e
else:
log.info('【{}】--用例执行成功'.format(item['title']))
# ⭐用log.error(e)

# ⭐用log.exception(e)异常对象 更详细
import unittest
from unittestreport import TestRunner
suite = unittest.defaultTestLoader.discover(r'D:\①testing\⑤autotest\api-test1\testcases')
runner = TestRunner(suite,report_dir='./reports')
runner.run()
users = [{'user': 'python31', 'password': '123456'}]
def register(username=None, password1=None, password2=None):
# 判断是否有参数为空
if not all([username, password1, password2]):
return {"code": 0, "msg": "所有参数不能为空"}
# 注册功能
for user in users: # 遍历出所有账号,判断账号是否存在
if username == user['user']:
# 账号存在
return {"code": 0, "msg": "该账户已存在"}
else:
if password1 != password2:
# 两次密码不一致
return {"code": 0, "msg": "两次密码不一致"}
else:
# 账号不存在 密码不重复,判断账号密码长度是否在 6-18位之间
if 6 <= len(username) <= 18 and 6 <= len(password1) <= 18:
# 注册账号
users.append({'user': username, 'password': password2})
return {"code": 1, "msg": "注册成功"}
else:
# 账号密码长度不对,注册失败
return {"code": 0, "msg": "账号和密码必须在6-18位之间"}
