Ⅱ 基本数据类型

思考,是上面的苹果堆好处理(运输,存储,加工)还是下面的有包装的苹果好处理?



1⃣️ Python语法规则
1. 代码结束


@`````````````````````````````````````````````````````````````````````````````````````````````````$
2. 注释


@`````````````````````````````````````````````````````````````````````````````````````````````````$
3. 代码层级


@`````````````````````````````````````````````````````````````````````````````````````````````````$
4. 标识符

2⃣️ Python变量
1. 变量命名规范
在程序运行过程中会有一些中间值,在稍后的执行中会用到,这时可以将这些中间值赋值给变量,
然后在后面的代码中通过调用这些变量名来获取这些值。可以简单的理解为给这些值取一个别名,这个别名就代表这个值。
变量的命名规则:
-
由大小写字母 A-Z a-z,数字 0-9 和下划线
_组成 -
不能以数字开头
-
不能是关键字
-
变量名大小写敏感
-
字母和数字之间可以用下划线隔开 以便阅读
-
见名知意

# 正确的案例
lucky_num = 88
lucky_num2 = 888
# 错误的案例
年龄 = 18 # 错误示范,不要使用其他的字符创建变量名,切记
1lucky_num = 88 # 错误示范,会语法报错

# 上面的age 和 Age是两个不同的变量
Age = 19
python 官方占用了一些变量名作为程序的关键字,总共 35 个,这些关键字不能作为自定义变量名使用。

@`````````````````````````````````````````````````````````````````````````````````````````````````$
2. 变量名定义与引用


3⃣️ 什么是数据类型
编程语言通过一些复杂的计算机物理底层机制,创造不同类型的数据,用来表示现实世界中的不同信息,以便于计算机更好的存储和计算。
每种编程语言都会有一些基本的数据类型用来表示现实世界中的常见信息。
⭐基本数据类型:python预先定义的类型
自定义类型:面向对象时自封装的类型
Python 中的常见数据类型如下:
数值类型
| 名称 | 描述 |
|---|---|
| int(整数) | 数学概念中的整数 |
| float(浮点数) | 数学概念中的实数 |
| complex(复数) | 数学概念中的复数 |
⭐编写表格的原生方法:

语法说明:

@`````````````````````````````````````````````````````````````````````````````````````````````````$
序列类型
| 名称 | 描述 |
|---|---|
| str(字符串) | 字符串是字符的序列表示,用来表示文本信息 |
| list(列表) | 列表用来表示有序的可变元素集合。例如表示一个有序的数据组。 |
| tuple(元组) | 元组用来表示有序的不可变元素集合。 |
@`````````````````````````````````````````````````````````````````````````````````````````````````$
散列类型
| 名称 | 描述 |
|---|---|
| set(集合) | 数学概念中的集合,无限不重复元素的集合 |
| dict(字典) | 字典是无序键值对的集合。用来表示有关联的数据,例如表示一个人的基本信息。 |
@`````````````````````````````````````````````````````````````````````````````````````````````````$
其他类型
| 名称 | 描述 |
|---|---|
| bool(布尔型) | bool 型数据只有两个元素,True 表示真,False 表示假。用来表示条件判断结果。 |
| None | None 表示空。 |
4⃣️ 数值类型

1. 整数类型(int)
python 中整数类型用 int 表示,与数学中的整数概念一致
age = 18
其中 age 是变量名,= 是赋值运算符,18 是值。
上面的代码表示创建一个整数 18 然后赋值给变量 age。
@`````````````````````````````````````````````````````````````````````````````````````````````````$
1.1 赋值运算符
在 python 中 = 是赋值运算符,而不是数学意义上的等于号。
<span style="color:red">python 解释器会先计算 = 右边的表达式,然后将结果赋值给 = 左边的变量。</span>
res = 1 # 定义变量res赋值为1
res = res + 1 # 先计算res + 1 再赋值给变量res
res # res的值为2
运行结果:
2
@`````````````````````````````````````````````````````````````````````````````````````````````````$
1.2 type 函数和 print 函数
❀python 提供了内建函数 type 用来查看值或者变量的类型。
只需要将变量或者值作为参数传入 type 函数即可。
type(age) # 返回对象的类
运行结果:
int
type(18) # ①输出值的类型 交互式输出
运行结果:
int
❀print 函数用来在屏幕上输出传入的数据的字符串表现形式,是代码调试最重要的函数。
![]()
print(age)
print(type(age)) # ②打印值的字符串表现形式 print函数输出
运行结果:
18
<class 'int'>

❀print 函数和交互式输出的其他区别

@`````````````````````````````````````````````````````````````````````````````````````````````````$
1.3 整数的常见表示形式
在 python 中整数最常见的是 10 进制整数,也有二进制,八进制和十六进制。
a = 10 # 十进制
print('a的类型为:', type(a), a)
a 的类型为: <class 'int'> 10
b = 0b1110 # 二进制 0b,0B前导符,print的时候会转换为10进制
print('b的类型为:', type(b),b)
b 的类型为: <class 'int'> 14
c = 0o57 # 八进制
print('c的类型为:', type(c),c)
c 的类型为: <class 'int'> 47
d = 0xa5c # 十六进制
print('d的类型为:', type(d), d)
d 的类型为: <class 'int'> 2652
⭐注意:python中没有四进制:

@`````````````````````````````````````````````````````````````````````````````````````````````````$
1.4 整数的取值范围
python 中整数类型的理论取值范围是[-无穷,无穷],实际取值范围受限于运行 python 程序的计算机内存大小。

@`````````````````````````````````````````````````````````````````````````````````````````````````$
2. 浮点数类型(float)
python 中浮点数用 float 表示,与数学中的实数概念一致,也可以理解为有理数。
a = 0.0
print('a的类型为:', type(a))
a 的类型为: <class 'float'>
@`````````````````````````````````````````````````````````````````````````````````````````````````$
2.1 浮点数的表现形式
在 python 中浮点数可以表示为 a.b 的格式,也可以表示为小写e或大写 E 的科学计算法。例如:
a = 0.0
print('a的类型为:', type(a))
a 的类型为: <class 'float'>
# 小数部分为零可以被省略
b = 76.
print('b的类型为:', type(b))
b 的类型为: <class 'float'>
c = -3.1415926
print('c的类型为:', type(c))
c 的类型为: <class 'float'>
d = 9.5e-2
print('d的类型为:', type(d))
d 的类型为: <class 'float'>
思考:
浮点数可以表示所有的整数数值,python 为何要同时提供两种数据类型?
整数是最好存储,最好处理的数据。计算机底层就是二进制数。
相同的操作整数要比浮点数快5-20倍
@`````````````````````````````````````````````````````````````````````````````````````````````````$
2.2 数学运算符
与数学中的常用运算符一致
| 运算符 | 描述 |
|---|---|
+ |
加法运算符 1+1 |
- |
减法运算符 3-2 |
* |
乘法运算符 9*9 |
/ |
除法运算符 9/3,除法运算后的结果一定为 float 类型 |
// |
整除运算符 10/3,也称为 地板除 向下取整 |
% |
取模运算符 10%3,表示 10 除以 3 取余数 |
** |
幂次运算符 2**3,表示 2 的 3 次幂 |
() |
括号运算符,括号内的表达式先运算 (1+2)* 3 |


注意:一个浮点数和一个整数进行运算后的结果一定为浮点数
2+1.0
3.0
9/3 # 除法运算的结果一定为float
3.0
9//2 # 地板除,向下取整,如果符号两边都是整数,结果才是整数
4

⭐ 除和整除的区别:

@`````````````````````````````````````````````````````````````````````````````````````````````````$
2.3 组合赋值运算符
赋值运算符与算术运算符可以组合使用,注意算术运算符要写在前面且中间不能有空格。
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 等于-简单的赋值 | c = a + b print(c) # 30 |
| += | 加等于 | c += a 等同于 c = c + a |
| -= | 减等于 | c -= a 等同于 c = c - a |
| *= | 乘等于 | c *= a 等同于 c = c * a |
| /= | 除等于 | c /= a 等同于 c = c/a |
| %= | 取余等于 | c%=a 等同于 c = c%a |
| **= | 幂等于 | c ** =a 等同于 c = c ** a |
| //= | 取整除等于 | c//=a 等同于 c = c//a |
体现了程序员的"懒惰",这种懒惰大力提倡,使得代码简洁和高效。
a = 1
a += 2 # a = a+2
a
3
@`````````````````````````````````````````````````````````````````````````````````````````````````$
2.4 浮点数的不精确性
整数和浮点数在计算机中的表示不同,python 提供无限制且准确的整数计算,浮点数却是不精确的,例如:
0.2+0.1
0.30000000000000004
根据 sys.float_info.dig 的值,计算机只能提供 15 个数字的准确性。浮点数在超过 15 位数字计算中产生的误差与计算机内部采用二进制运算有关。
import sys
print(sys.float_info.dig)
15
思考:
3.141592653589*1.23456789 的计算怎么准确
拓展:高精度浮点运算类型
import decimal
a = decimal.Decimal('3.141592653589')
b = decimal.Decimal('1.23456789')
print(a * b)
3.87850941358087265721
⭐因为整数计算是无限制且精准的,所以可以先转换成整数计算,再移动小数点

@`````````````````````````````````````````````````````````````````````````````````````````````````$
2.5 浮点数和整数的相互转化
int,float 是 python 的内置函数,通过它们可以对浮点数类型和整数类型相互转化
a = 1.9
# 转化为整数
# 通过调用int函数,提取浮点数的整数部分
b = int(a)
print(b, type(b))
1 <class 'int'>
c = 2
# 转化为浮点数
# 通过调用float函数,将整数转化为小数部分为0的浮点数
d = float(c)
print(d, type(d))
2.0 <class 'float'>
⭐布尔型 转为 整型/浮点型
print('True转为整数后,结果为:',int(True), type(int(True)))
print('True转为浮点数后,结果为:',float(True), type(float(True)))
True转为整数后,结果为:1 <class 'int'>
True转为浮点数后,结果为:1.0 <class 'float'>
@`````````````````````````````````````````````````````````````````````````````````````````````````$
3. 复数(complex)
科学计算中的复数。
![]()
a = 12.3+4j
print('a的类型为:', type(a))
# 运行结果:a的类型为: <class 'complex'>
print(a.real) # 实部
print(a.imag) # 虚部
a 的类型为: <class 'complex'>
12.3
4.0
⭐复数用来解决负整数的平方根

@`````````````````````````````````````````````````````````````````````````````````````````````````$
4. 布尔型(bool)
条件表达式的运算结果返回布尔型(bool),布尔型数据只有两个,True 和 False 表示 真 和 假。
True
True

False # 注意首字母大写
False
@`````````````````````````````````````````````````````````````````````````````````````````````````$
1.1 比较运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 等于-比较对象的值是否相等 | print(a==b) # False |
| is | 等于-比较对象的内存地址是否相同 | print(a is b) |
| != | 不等于 | print(a!=b) # True |
| > | 大于 | print(a>b) # False |
| < | 小于 | print(a<b) # True |
| >= | 大于等于 | print(a>=b) # False |
| <= | 小于等于 | print(a<=b) # True |
比较运算符运算后的结果是布尔型
python3不支持<>
a = 1
b = 2
a == b
False
a = 300
b = 300
a is b
False
a == b
True


@`````````````````````````````````````````````````````````````````````````````````````````````````$
1.2 成员运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则 False | L = [1, 2, 3, 4, 5] a = 3 print(a in L) # True |
| not in | 如果在指定的序列中没有找到值返回 True,否则 False | print(a not in L) # False |
ls = [1,2,3,4,5]
1 in ls
True
s = ['abcdefg'] # 列表s里面只有一个元素
'a' in s
False

t = (1,2,3)
4 in t
False
#字典成员运算符默认检查的是key
#字典检索key很快
d = {'name': 'Felix','age':18}
'name' in d
True
st = {1,2,3}
1 in st
True
⭐
num = 1234 # 数字不能用于包含与被包含的判断
print(1 in num)
⭐
bol = True # bol值也不能用于这个计算
print("T" in bol)
@`````````````````````````````````````````````````````````````````````````````````````````````````$
1.3 布尔型运算
布尔型数据可以和数值类型数据进行数学计算,这时 True 表示整数1, False 表示整数 0
布尔型是整型的子类。加减乘除都可以算
True + 1
2
False + 1
1
@`````````````````````````````````````````````````````````````````````````````````````````````````$
1.4 布尔类型转换
任意数据都可以通过函数 bool 转换成布尔型。
在 python 中,None, 0(整数),0.0(浮点数),0.0+0.0j(复数),""(空字符串),空列表,空元组,空字典,空集合的布尔值都为 False,其他数值为 True
print(bool(0))
print(bool(0.0))
print(bool(0.0+0.0j))
print(bool(''))
print(bool([]))
print(bool(()))
print(bool({}))
print(bool(set()))
print(bool(None))
False
False
False
False
False
False
False
False
False
@`````````````````````````````````````````````````````````````````````````````````````````````````$
1.5 逻辑运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| and | 与,如果 x 为 False,x and y 返回 x 的值,否则返回 y 的值 | print(a and b) # True |
| or | 或,如果 x 为 True,x and y 返回 x 的值,否则返回 y 的值 | print(a or b) # True |
| not | 非,如果 x 为 True,返回 False,反之,返回 True | print(not a) # False |
逻辑运算符两边的表达式不是布尔型时,在运算前会转换为布尔型。
True and True
True
True and False
False
0 and 1 # 短路
0
1 and 2 # and左边为True时,则由右边的值来决定整个表达式的值
2
True or False
True
False or False
False
1 or 0 # 短路
1
0 or '' #or左边为False时,则由右边的值来决定整个表达式的值
''
not 运算符返回的永远是True或者False


⭐运算符的优先级:



序列类型
序列类型用来表示有序的元素集合。
1. 字符串

python 中字符串用 str 表示,字符串是使用成对的单引号,双引号,三引号包裹起来的字符的序列,用来表示文本信息。
@`````````````````````````````````````````````````````````````````````````````````````````````````$
1.1 字符串的定义
a = 'a'
b = "bc"
c = """hello,world"""
d = '''hello,d'''
e = """
hello,
world!
"""
print('a的类型为:', type(a)) # a的类型为: <class 'str'>
print('b的类型为:', type(b)) # b的类型为: <class 'str'>
print('c的类型为:', type(c)) # c的类型为: <class 'str'>
print('d的类型为:', type(d)) # d的类型为: <class 'str'>
print('e的类型为:', type(e)) # e的类型为: <class 'str'>
使用单引号和双引号进行字符串定义没有任何区别,当要表示字符串的单引号时(可使用转义),也可用双引号进行定义字符串,反之亦然。
一对单引号或双引号只能创建单行字符串,三引号可以创建多行表示的字符串。三双引号一般用来做多行注释,表示函数,类定义时的说明。三单引号一般用来定义一个变量。
print('最近我看了"平凡的世界"') # 最近我看了"平凡的世界"
print("最近我看了'平凡的世界'") # 最近我看了'平凡的世界'
⭐三引号创建多行表示的字符串

定义空字符串
a = ''
print(a)
⭐字符串另一写法:

@`````````````````````````````````````````````````````````````````````````````````````````````````$
1.2 字符串的索引
任何序列类型中的元素都有 索引 用来表示它在序列中的位置。
字符串是字符的序列表示,单个字符在字符串中的位置使用 索引 来表示,也叫下标。
索引使用整数来表示。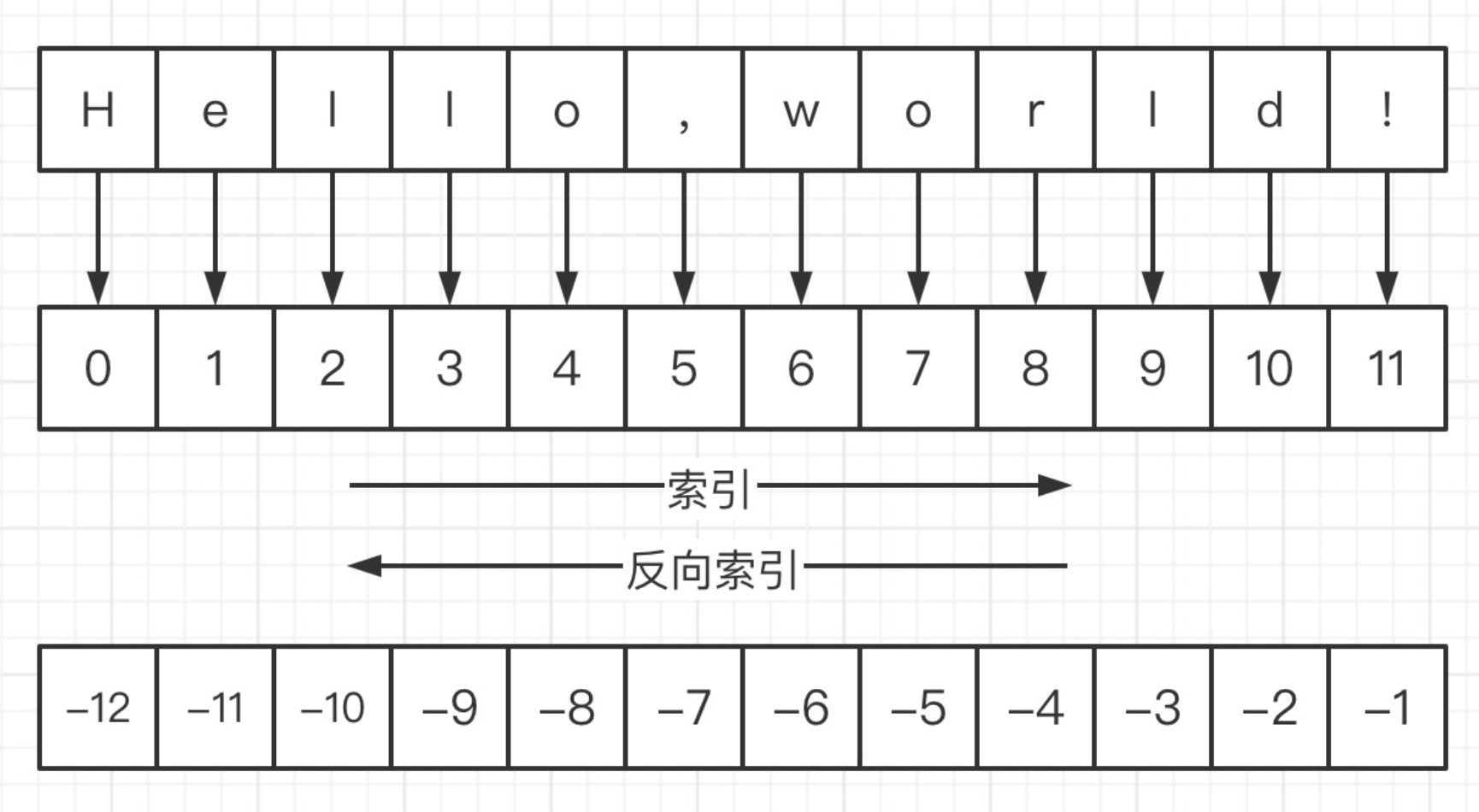
通过 索引 可以获取字符串中的单个字符
索引即偏移量,表示元素距离序列头部偏移位置的个数
语法如下:
str[index]
s = 'hello world!'
print(s[0])
print(s[-1])
h
!
注意字符串索引从 0 开始
@`````````````````````````````````````````````````````````````````````````````````````````````````$
1.3 字符串的切片
⭐ 字符串可以当作一个列表用
获取序列中的子序列叫切片。
字符串的切片就是获取字符串的子串。
字符串切片的语法如下:
str[start:end:step]
start 表示起始索引,end 表示结束索引,step 表示步长。
str[m:n:t] 表示从字符串索引为 m 到 n 之间不包含 n 每隔 t 个字符进行切片。
当 step 为 1 的时候可以省略。
特别的,当 step 为负数时,表示反向切片。
s = '0123456789'
print(s[1:5]) # 包头不包尾
1234
print(s[:5]) # 从头开始切可以省略start
01234
print(s[1:]) # 切到末尾省略end
123456789
print(s[1::2]) # 步长为2进行切片
13579
❀从1开始切,每两个里面取第一个 13579
# 无论正向还是反向切片,索引是独立的[hello,world],无论正反,,的索引都是5
# (按步长分组后取每个组的第一个字符,负切片反向为头)
print(s[1::-2]) # 步长为负数反向切片 # 1
思考
获取一个字符串的逆串,例如 'abc' 的逆串是 'cba'。
@`````````````````````````````````````````````````````````````````````````````````````````````````$
1.4 字符串拼接
python 中可以通过 + 拼接两个字符串
a = 'hello'
b = ' '
c = 'world!'
print(a+b+c)
hello world!
字符串和整数进行乘法运算-表示重复拼接这个字符串
print('*' * 10)
@`````````````````````````````````````````````````````````````````````````````````````````````````$
1.5 字符串常用方法
通过内建函数 dir 可以返回传入其中的对象的所有方法名列表。

str.capitalize()
返回原字符串的副本,其首个字符大写,其余为小写。

str.endswith(suffix[, start[, end]])
如果字符串以指定的 suffix 结束返回 True,否则返回 False。 suffix 也可以为由多个供查找的后缀构成的元组。 如果有可选项 start,将从所指定位置开始检查。 如果有可选项 end,将在所指定位置停止比较。
⭐判断变量name是否以al结尾
print(name[-2:]) == 'al'
print(name.endswith("al"))
str.startswith(prefix[, start[, end]])
如果字符串以指定的 prefix 开始则返回 True,否则返回 False。 prefix 也可以为由多个供查找的前缀构成的元组。 如果有可选项 start,将从所指定位置开始检查。 如果有可选项 end,将在所指定位置停止比较。
⭐判断变量name是否以al开头
print(name[:2]) == 'al'
print(name.startswith("al"))
str.isalnum()
如果字符串中的所有字符都是字母或数字且至少有一个字符,则返回 True , 否则返回 False 。 如果 c.isalpha() , c.isdecimal() , c.isdigit() ,或 c.isnumeric() 之中有一个返回 True ,则字符c是字母或数字。
str.isdigit()
如果字符串中的所有字符都是数字,并且至少有一个字符,返回 True ,否则返回 False 。 数字包括十进制字符和需要特殊处理的数字,如兼容性上标数字。这包括了不能用来组成 10 进制数的数字,如 Kharosthi 数。 严格地讲,数字是指属性值为 Numeric_Type=Digit 或 Numeric_Type=Decimal 的字符。
str.islower()
如果字符串中至少有一个区分大小写的字符且此类字符均为小写则返回 True ,否则返回 False 。
str.isupper()
如果字符串中至少有一个区分大小写的字符
>>> 'BANANA'.isupper()
True
>>> 'banana'.isupper()
False
>>> 'baNana'.isupper()
False
>>> ' '.isupper()
False
str.upper()
返回原字符串的副本,其中所有区分大小写的字符
所用转换大写算法的描述请参见 Unicode 标准的 3.13 节。
str.isspace()
如果字符串中只有空白字符且至少有一个字符则返回 True ,否则返回 False 。
空白 字符是指在 Unicode 字符数据库 (参见
str.lower()
返回原字符串的副本,其所有区分大小写的字符
所用转换小写算法的描述请参见 Unicode 标准的 3.13 节。
str.replace(old, new[, count])
返回字符串的副本,其中出现的所有子字符串 old 都将被替换为 new。 如果给出了可选参数 count,则只替换前 count 次出现。

str.strip([chars])
返回原字符串的副本,移除其中的前导和末尾字符。 chars 参数为指定要移除字符的字符串。 如果省略或为 None,则 chars 参数默认移除空白符。 实际上 chars 参数并非指定单个前缀或后缀;而是会移除参数值的所有组合:
>>> ' spacious '.strip()
'spacious'
>>> 'www.example.com'.strip('cmowz.')
'example'
最外侧的前导和末尾 chars 参数值将从字符串中移除。 开头端的字符的移除将在遇到一个未包含于 chars 所指定字符集的字符时停止。 类似的操作也将在结尾端发生。 例如:
>>> comment_string = '#....... Section 3.2.1 Issue #32 .......'
>>> comment_string.strip('.#! ')
'Section 3.2.1 Issue #32'

⭐输入字符串(列表)对应的前两个字符/后三个字符
print(li[-2:])
print(li[:3])
通过内建函数 help 可以返回传入函数的帮助信息。

@`````````````````````````````````````````````````````````````````````````````````````````````````$
1.6 字符串和数值的相互转化
1 和 '1' 不同,1.2 和 '1.2' 也不相同,但是它们可以相互转化
# 整数和字符串之间的转化
# 整数字符串,10进制的整数字符串
int('1') # 1
⭐int不能转化非十进制的整数字符串

str(1)
'1'
⭐使用base=0,将二进制、八进制、十六进制的整数字符串转化为整数

# 浮点数和字符串之间的转化
float('1.2')
1.2
str(1.2)
'1.2'
# 尝试 int('1.2')看看结果会是什么
int('1.2') #报错,int只能将整数字符串转换为整数,必须是十进制数
# 布尔值和字符串之间的转化
print('True转为字符串后,结果为:',str(True),'类型为:',type(str(True)))
# 字符串转为bool值
print('""转为布尔值后,结果为:',bool(""),'类型为:',type(bool("")))
True转为字符串后,结果为:True 类型为:<class 'str'>
""转为布尔值后,结果为:False 类型为:<class 'bool'>
⭐非零值为True,0为False
@`````````````````````````````````````````````````````````````````````````````````````````````````$
1.7 转义符
在需要在字符中使用特殊字符时,python 用反斜杠 \ 转义字符。常用转义字符如下表:
| (在行尾时) | 续行符 |
|---|---|
\\ |
反斜杠符号 |
\' |
单引号 |
\" |
双引号 |
| \a | 响铃 |
| \n | 换行 |
| \t | 横向制表符 |
| \r | 回车 |
| \f | 换页 |
print('窗前明月光,\n疑是地上霜。') # 输出换行
窗前明月光,
疑是地上霜。
print('对\\错') # 输出反斜杠本身
对\错
⭐\

print('\'') # 输出单引号本身
'
⭐\r

⭐\a

在定义字符串的时候,有时需要强制不转义
在字符串前面加上r这个引导符,字符串会原样输出,raw
⭐双反斜杠即输出反斜杠自身
![]()
⭐加r / R,或者斜杠(\)可以原样输出,而不会再输出许多个换行
@`````````````````````````````````````````````````````````````````````````````````````````````````$
1.8 字符串格式化


在实际工作中经常需要动态输出字符。
例如,我们通过程序计算计算机的内存利用率,然后输出
10:15 计算机的内存利用率为30%
其中下划线内容会动态调整,需要根据程序执行结果进行填充,最终形成上述格式的字符串输出。
python 支持三种形式的字符串格式化
①% 字符串格式化
语法格式如下:
%[(name)][flags][width][.precision]typecode
-
(name)可选,用于选择指定的key -
flags 可选,可供选择的值有,注意只有在和数值类型的typecode配合才起作用
-
+, 右对齐,正数前加正号,负数前加负号 -
-, 左对齐,正数前无符号,负数前加负号 -
空格, 右对齐,正数前加空格,负数前加负号 -
0, 右对齐,正数前无符号,负数前加负号;用0填充空白处
-
-
width,可选,字符串输出宽度 -
.precision可选,小数点后保留位数,注意只有在和数值类型的typecode配合才起作用 -
typecode 必选-
s,获取传入对象的字符串形式,并将其格式化到指定位置 -
r,获取传入对象的__repr__方法的返回值,并将其格式化到指定位置 -
c,整数:将数字转换成其 unicode 对应的值,10 进制范围为 0 <= i <= 1114111(py27 则只支持 0-255);字符:将字符添加到指定位置 -
o,将整数转换成 八 进制表示,并将其格式化到指定位置 -
x,将整数转换成十六进制表示,并将其格式化到指定位置 -
d,将整数、浮点数转换成 十 进制表示,并将其格式化到指定位置 -
e,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(小写 e) -
E,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(大写 E) -
f, 将整数、浮点数转换成浮点数表示,并将其格式化到指定位置(默认保留小数点后 6 位) -
F,同上 -
g,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过 6 位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是 e;)` -
G,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过 6 位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是 E;)` -
%,当字符串中存在格式化标志时,需要用 %% 表示一个百分号
-
⭐写法1:%typecode
res = '%s计算机的内存利用率为%s%%' % ('11:15', 75)
print(res)
# '%s'作为槽位和 % 号后提供的值按顺序一一对应
11:15 计算机的内存利用率为 75%
⭐写法2:%[(name)]typecode
res = '%(time)s计算机的内存利用率为%(percent)s%%' % {'time':'11:15', 'percent': 75}
# % 后是字典时,可以通过name指定key对应的值
print(res)
11:15 计算机的内存利用率为 75%
⭐写法3:%[(flags)(width)]typecode
# 输出两位数的月份,例如01,02
# 宽度为2,配合flages右对齐用0填充空白处,因为是整数所以不能用s
res = '%02d' % 8
print(res)
08
⭐写法4:%[(name)(.precision)]typecode
# 保留2为小数
res = '%(time)s计算机的内存利用率为%(percent).2f%%' % {'time':'11:15', 'percent': 75.123}
print(res)
11:15 计算机的内存利用率为 75.12%
⭐写法5:%[(name)]typecode
print('字符串%(key)s,十进制%(key)d,科学计数%(key)e,八进制%(key)o,
16进制%(key)x,unicode字符%(key)c' % {'key': 65})
字符串 65,十进制 65,科学计数 6.500000e+01,八进制 101,16 进制 41,unicode 字符 A
@`````````````````````````````````````````````````````````````````````````````````````````````````$
②format 函数格式化
% 的字符串格式化继承自 C 语言,python 中给字符串对象提供了一个 format 函数进行字符串格式化,且功能更强大,并且大力推荐,所以我们要首选使用。
❀format是字符串的一个方法

基本语法是:
<模板字符串>.format(<逗号分隔的参数>)
在模板字符串中使用 {} 代替以前的 % 作为槽位
'{}计算机的内存利用率为{}%'.format('11:15', 75)
'11:15 计算机的内存利用率为 75%'
当 format 中的参数使用位置参数提供时,{} 中可以填写参数的整数索引和参数一一对应
'{0}计算机的内存利用率为{1}%'.format('11:15', 75)
'11:15 计算机的内存利用率为 75%'
当 format 中的参数使用关键字参数提供时,{}中可以填写参数名和参数一一对应
'{time}计算机的内存利用率为{percent}%'.format(time='11:15', percent=75)
'11:15 计算机的内存利用率为 75%'
{} 中除了可以写参数索引外,还可以填写控制信息来实现更多的格式化功能,语法如下
{<参数序号>:<格式控制标记>}
其中格式控制标记格式如下
[fill][align][sign][#][0][width][,][.precision][type]
-
fill 【可选】空白处填充的字符
❀可以写0 或 任意的单个字符 填充
-
align 【可选】对齐方式(需配合 width 使用)
-
<,内容左对齐
-
>,内容右对齐(默认)
-
=,内容右对齐,将符号放置在填充字符的左侧,且只对数字类型有效。 即:符号 + 填充物 + 数字
-
^,内容居中
-
-
sign 【可选】有无符号数字
-
+,正号加正,负号加负;
-
-,正号不变,负号加负;
-
空格 ,正号空格,负号加负;
-
-
#【可选】对于二进制、八进制、十六进制,如果加上#,会显示 0b/0o/0x,否则不显示
-
, 【可选】为数字添加分隔符,如:1,000,000
-
width 【可选】格式化位所占宽度
-
.precision 【可选】小数位保留精度
-
type 【可选】格式化类型
-
传入” 字符串类型 “的参数
-
s,格式化字符串类型数据
-
空白,未指定类型,则默认是 None,同 s
-
-
传入“ 整数类型 ”的参数
-
b,将 10 进制整数自动转换成 2 进制表示然后格式化
-
c,将 10 进制整数自动转换为其对应的 unicode 字符
-
d,十进制整数
-
o,将 10 进制整数自动转换成 8 进制表示然后格式化;
-
x,将 10 进制整数自动转换成 16 进制表示然后格式化(小写 x)
-
X,将 10 进制整数自动转换成 16 进制表示然后格式化(大写 X)
-
-
传入“ 浮点型或小数类型 ”的参数
-
e, 转换为科学计数法(小写 e)表示,然后格式化;
-
E, 转换为科学计数法(大写 E)表示,然后格式化;
-
f , 转换为浮点型(默认小数点后保留 6 位)表示,然后格式化;
-
F, 转换为浮点型(默认小数点后保留 6 位)表示,然后格式化;
-
g, 自动在 e 和 f 中切换
-
G, 自动在 E 和 F 中切换
-
%,显示成百分比(默认显示小数点后 6 位)
-
-
⭐写法1:[fill][align][width]
# 输出两位数的月份,例如01,02
# 宽度为2右对齐,空白处填充0
res = '{:0>2}'.format(8)
print(res)
08
⭐写法2:[.precision][type]
# 保留2为小数
res = '{time}计算机的内存利用率为{percent:.2%}'.format(time='11:15', percent=0.75123)
print(res)
11:15 计算机的内存利用率为 75.12%
⭐写法3:
print('字符串{key},十进制{key:d},科学计数{key:e},八进制{key:o},
16进制{key:x},unicode字符{key:c}'.format(key=65))
字符串 65,十进制 65,科学计数 6.500000e+01,八进制 101,16 进制 41,unicode 字符 A
❀加前导符

❀为数字添加分隔符

不要小数点后面的小数 :.0%

'电脑内存占用率为{:.0%}'

@`````````````````````````````````````````````````````````````````````````````````````````````````$
③f表达式
3.6 新版功能:
1.定义:格式字符串字面值或称为 f-string f字符串 f表达式,是标注了 'f' 或 'F' 前缀的字符串字面值。
这种字符串可包含替换字段,即以 {} 标注的表达式。
基本语法是:
literal_char{expression[:format_spec]}
-
literal_char普通字符 -
expression表达式,变量或函数。 -
format_spec格式字符串,规则和format 里面的控制符一模一样
直接在 f 字符串的花括号内写上变量名,解释器会自动将变量的值的字符串形式替换
time = '11:15'
percent = 75
f'{time}计算机的内存利用率为{percent}%'
'11:15计算机的内存利用率为75%'

带格式的 f 字符串
# 输出两位数的月份,例如01,02
month = 8
res = f'{month:0>2}'
print(res)
08
# 保留2为小数
time = '11:15'
percent = 0.75123
res = f'{time}计算机的内存利用率为{percent:.2%}'
print(res)
11:15计算机的内存利用率为75.12%
key = 65
print(f'字符串{key},十进制{key:d},科学计数{key:e},八进制{key:#o},16进制{key:x},unicode字符{key:c}')
字符串65,十进制65,科学计数6.500000e+01,八进制0o101,16进制41,unicode字符A
包含运算和函数的 f 字符串
⭐可以输出表达式 与 其值
num = -1
print(f'{num+1=}')
num+1=0
print(f'{abs(num)=}')
abs(num)=1
s = 'abcd'
print(f'{s[::-1]=}')
s[::-1]='dcba'

2. 列表

python 中列表(list)用来表示有序可变元素的集合,元素可以是任意数据类型,序列中的元素可以增,删,改。
@`````````````````````````````````````````````````````````````````````````````````````````````````$
2.1 列表的定义
列表由一对中括号进行定义,元素与元素之间使用逗号隔开。
a = [] # 空列表
b = ["a", "b", "cde"] # 字符串列表项
c = [1, "b", "c"] # 数字列表项
d = [1, "b", []] # 列表列表项
e = [1, "b", [2, "c"]] # 列表作为列表的元素叫做列表的嵌套
print('a的类型为:', type(a)) # a的类型为: <class 'list'>
print('b的类型为:', type(b)) # b的类型为: <class 'list'>
print('c的类型为:', type(c)) # c的类型为: <class 'list'>
print('d的类型为:', type(d)) # d的类型为: <class 'list'>
print('e的类型为:', type(e)) # e的类型为: <class 'list'>
⭐列表的另一种写法:

@`````````````````````````````````````````````````````````````````````````````````````````````````$
2.2 列表的拼接
像字符串一样,列表之间可以进行加法运算实现列表的拼接,列表可以和整数进行乘法运算实现列表的重复。
[1,2,3] + [4,5,6]
[1, 2, 3, 4, 5, 6]
[1,2,3] * 3
[1, 2, 3, 1, 2, 3, 1, 2, 3]
@`````````````````````````````````````````````````````````````````````````````````````````````````$
2.3 列表的索引和切片
序列的切片操作完全一致,参见字符串
注意嵌套列表的元素获取
ls = [1,2,['a','b']]
ls[2][0]
'a'
@`````````````````````````````````````````````````````````````````````````````````````````````````$
2.4 列表的常用操作
python 中的列表操作非常灵活,是非常重要和经常使用的数据类型。
2.4.1)修改元素
列表的中的元素可以进行修改,只需使用索引赋值即可。
ls = [1,2,3]
ls[1] = 'a' # 修改单个元素
print(ls)
[1, 'a', 3]
lst = ['java','selenium','postman']
# 将"selenium","postman"修改为['测试框架']
lst[1:] = ['测试框架'] # 修改多个元素
print(lst)
2.4.2)增加元素
给列表添加元素需要使用到列表的方法
.append(el),在列表的末尾添加一个元素
ls = [1,2,3]
ls.append(4)
print(ls)
[1, 2, 3, 4]

.insert(index, el),在列表的指定索引元素的前面插入一个元素
ls = [1,2,3]
ls.insert(0,0)
print(ls)
[0, 1, 2, 3]

.extend(iterable),扩展列表,元素为传入的可迭代对象中的元素
⭐脱掉一层外壳,后依次加入
ls = [1,2,3]
ls.extend([4,5,6])
print(ls)
[1, 2, 3, 4, 5, 6]


2.4.3)删除元素
.pop(index=-1),删除指定索引的元素,并返回该元素,没有指定索引默认删除最后一个元素
ls = [1,2,3]
ls.pop()
3
print(ls)
[1, 2]
ls.pop(0)
1
print(ls)
[2]

.remove(value),从列表中删除第一个指定的值 value,如不存在 value 则报错。
ls = [1,2,3,1]
ls.remove(1)
print(ls)
[2, 3, 1]

.clear(),清空列表,原列表变成空列表
ls = [1,2,3]
ls.clear()
print(ls)
[]
.del列表名[索引值],根据索引值删除单个元素/多个元素
⭐ 删除列表中的第2至第4个元素
del li[1:4]
print(li)
@`````````````````````````````````````````````````````````````````````````````````````````````````$
2.5 列表的其他方法
.copy() 返回一个列表的浅拷贝。在讲可变与不可变类型的时候再详细讨论。
.count(value),统计列表中 value 的出现次数,返还数量
ls = [1,2,3,1]
ls.count(1)
2.index(self, value, start=0, stop=9223372036854775807),返回列表中指定值 value 的第一个索引值,不存在则报错
ls = [1,2,3,1]
ls.index(1)
0
ls.index(1,1) #找value值为1所在的索引,从索引start为1的位置开始
3.reverse(),翻转列表元素顺序
ls = [1,2,3]
ls.reverse() #因为reverse()函数返回值为None,所以要先操作倒叙
print(ls) # 然后再打印ls
# print(ls[::-1]) # 使用切片方式反转
[3, 2, 1]
.sort(key=None, reverse=False),对列表进行排序,默认按照从小到大的顺序,当参数 reverse=True 时,从大到小。注意列表中的元素类型需要相同,否则抛出异常。
ls = [2,1,3]
ls.sort()
print(ls)
[1, 2, 3]
# 从大到小
ls.sort(reverse=True)
print(ls)
[3, 2, 1]
ls = [1,2,'3']
ls.sort()
TypeError Traceback (most recent call last)
in
1 ls = [1,2,'3']
----> 2 ls.sort()
TypeError: '<' not supported between instances of 'str' and 'int'
⭐
![]()
![]()
lst = [1,'python','selenium','postman',True,123.345,'python']
print('python元素的索引值:',lst.index('python'))
del lst[lst.index('python')]
print(lst)
del lst[lst.index('python')]
print(lst)
@`````````````````````````````````````````````````````````````````````````````````````````````````$
2.6)字符串和列表的转换
字符串是字符组成的序列,可以通过 list 函数将字符串转换成单个字符的列表。
s = 'hello world!'
ls = list(s)
print(ls)
['h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd', '!']
由字符组成的列表可以通过字符串的 join 方法进行拼接
# 接上面的案例
''.join(ls)
'hello world!'


num1 = 100
print(list(num1)) #报错:TypeError: 'int' object is not iterable
3. 元组
元组(tuple)表示有序不可变元素的集合,元素可以是任意数据类型,序列中的元素不能增,删,改,可以说元组就是不可变的列表。
⭐元组与列表的区别:元组就是不可变的列表
@`````````````````````````````````````````````````````````````````````````````````````````````````$
3.1 元组的定义
元组通过一对小括号进行定义,元组之间使用逗号隔开。
a = () # 空元祖
b = ("a", "b", "cde") # 字符串元组
c = (1, "b", "c") # 数字元组
d = (1, "b", []) # 列表元组
e = (1, "b", (2, "c")) # 元祖的嵌套
f = 1,2
g = (1,) # 单元素元组
print('a的类型为:', type(a)) # a的类型为: <class 'tuple'>
print('b的类型为:', type(b)) # b的类型为: <class 'tuple'>
print('c的类型为:', type(c)) # c的类型为: <class 'tuple'>
print('d的类型为:', type(d)) # d的类型为: <class 'tuple'>
print('e的类型为:', type(e)) # e的类型为: <class 'tuple'>
print('f的类型为:', type(f)) # f的类型为: <class 'tuple'>
注意单元素元组的定义,一定要多加个逗号
g = ('hello')
h = ('hello',)
print('g的类型为:', type(g)) # g的类型为: <class 'str'>
print('h的类型为:', type(h)) # h的类型为: <class 'tuple'>
@`````````````````````````````````````````````````````````````````````````````````````````````````$
3.2 元组的索引和切片
序列的索引和切片完全一致,参见字符串。
@`````````````````````````````````````````````````````````````````````````````````````````````````$
3.3 元组的常用操作
元组的元素不能修改,增加和删除,其他操作和列表的操作一致。
元组利用不可修改的特性,应用在多变量赋值和函数多返回值上。
a, b = (1, 2)
# 经常简写为a, b= 1, 2
当然多变量赋值时可以使用可迭代对象,但是元组最安全,它是不可变的。
关于函数多返回值的问题我们后面再讲
⭐tuple + ,形成一个新的元组(可用pythontutor.com/visualize.html#mode=display进行验证)
tp1 = (1, 2, 3, 4, 5)
tp2 = (100, 3.14)
res = tp1 + tp2
print(res)
print(tp1)
print(tp2)
(100, 3.14, 1, 2, 3, 4, 5)
(1, 2, 3, 4, 5)
(100, 3.14)

⭐元组不可操作,要你操作怎么做?
tp1 = (1, 2, 3, 4, 5)
print(id(tp1))
ls = list(tp1) # 先把元组变成列表
ls.append(6) # 操作list
tp1 = tuple(ls) # 然后再变成tuple
print(tp1)
print(type(tp1)) # 但已不再是以前的tuple
print(id(tp1)) # id 不一样了
@`````````````````````````````````````````````````````````````````````````````````````````````````$
3.4 元组的常用方法
元组只有两个公有方法 count,index 用法与列表相同。
@`````````````````````````````````````````````````````````````````````````````````````````````````$
3.5 len 函数
python 内建函数 len 可以获取对象中包含的元素个数
s = 'hello'
ls = [1,2,3]
t = (1,2,3)
print(len(s)) #5
print(len(ls)) #3
print(len(t)) #3
@`````````````````````````````````````````````````````````````````````````````````````````````````$
4. 可变与不可变对象
python 中的对象根据底层内存机制分为可变与不可变两种。
可变对象可以在其 id() 保持固定的情况下改变其取值。
❀id(a),拿的是a地址的位置
下面的列表 a,修改值后,id 保持不变
a = [1,2,3]
id(a) # 虚拟内存地址,一个大整数,每次运行都会变
14053670614592
# 修改a的值
a[0] = 'a'
id(a)
14053670614592


基本数据类型中列表,集合和字典都是可变数据类型。
如果修改一个对象的值,必须创建新的对象,那么这个对象就是不可变对象。
例如下面的字符串 s,修改内容后 id 发生了改变。
s = 'hello'
id(s)
140453671058032
s = 'Hello'
id(s)
140453671058032
基本数据类型中数字,字符串,元组是不可变对象。
@`````````````````````````````````````````````````````````````````````````````````````````````````$
5. 可哈希对象
一个对象的哈希值如果在其生命周期内绝不改变,就被称为可哈希。可哈希对象都可以通过内置函数 hash 进行求值。
它们在需要常量哈希值的地方起着重要的作用,例如作为集合中的元素,字典中的键。
不可变数据类型都是可哈希对象,可变数据类型都是不可哈希对象。
hash(1)
1
hash([1,2])
TypeError Traceback (most recent call last)
in
----> 1 hash([1,2])
TypeError: unhashable type: 'list'
@`````````````````````````````````````````````````````````````````````````````````````````````````$
6. 赋值与深浅拷贝
6.1 赋值
python 是解释型编程语言,当解释器在碰到赋值语句时它首先会计算赋值符号右边的表达式的值,然后再创建左边的变量。
变量中实际存储的是值在内存中的地址,引用变量时通过地址指向内存中的值。通过内建函数 id 可以查看解释器中变量的虚拟内存地址整数值。
a = 1
id(a)
140721806448288
python 的赋值语句不复制对象,而是创建目标和对象的绑定关系。
所以将一个变量赋值给另外一个变量时,并不会创建新的值,只是新变量会指向值的内存地址
a = 1
b = a
id(a) == id(b)
True
对于字符串和数字这样的不可变数据类型,当上例中的变量 a 自加 1 时,会创建一个新值重新,它不会改变原来的值。因此对变量 b 没有影响。
a += 1
print(a)
print(b)
2
1
但是看下面的案例
ls = [1,2,3]
ln = ls
ls[0] = 2
print(ln)
[2, 2, 3]
会发现变量 ls 在修改列表的值后,变量 ln 的值也发生了同样的改变,这是因为 ls,ln 指向相同的列表。对可变数据类型进行变量赋值时要考虑这个特性。
@`````````````````````````````````````````````````````````````````````````````````````````````````$
6.2 浅拷贝
导入 copy 模块中的 copy 函数就是浅拷贝操作
import copy
a = 123
s = 'hello'
b = copy.copy(a)
d = copy.copy(s)
print(id(a),id(b))
print(id(s),id(d))
4382616384 4382616384
140571355341296 140571355341296
对于字符串、数字这种不可变数据类型来说,浅拷贝相当于变量赋值,所以变量 a 和 b 的 id 相等,变量 s 和 d 的 id 相等。
a += 1
print(a)
print(b)
124
123
对原变量的修改会创建新的值,不会影响浅拷贝生成的变量,变量 a 自加 1 后指向值 124,变量 b 的值不变
对于可变数据类型:列表,字典,集合等浅拷贝会有不一样的结果。
ls = [1,'2',['a','b']]
ln = copy.copy(ls)
print(id(ls),id(ln))
140571352915648 140571355343040
当对可变数据类型进行浅拷贝时,会创建一个新的数据,所以变量 ls 和 ln 的 id 不相等。
print(id(ls[2]),id(ln[2]))
140571355288384 140571355288384
浅拷贝将原始对象中找到的对象引用插入其中。
也就是说,ls 列表中的元素,ln 中只是引用,ln 中的每个对应位置指向的内存地址和 ls 相同。
ls[0] = 2
print(ls)
print(ln)
[2, '2', ['a', 'b']]
[1, '2', ['a', 'b']]
修改 ls 中第一个元素,因为是不可变数据类型,所以 ls 中第一个位置指向了新的内存地址,ln 中的不变。

ls[2][1] = 'c'
print(ls)
print(ln)
[2, '2', ['a', 'c']]
[1, '2', ['a', 'c']]
修改 ls 中最后一个元素,因为是可变数据类型,所以 ln 中的值也发生了改变。

@`````````````````````````````````````````````````````````````````````````````````````````````````$
6.3 深拷贝
不可变数据类型的深浅拷贝一致。
复杂数据类型进行深拷贝会对数据中的所有元素完全重新复制一份,不管有多少层嵌套,互不影响。
import copy
ls = [1,2,3,['a', 'b']]
# 深拷贝使用deepcopy
ln = copy.deepcopy(ls)
ls[3][0]='b'
print(ls)
print(ln)
[1, 2, 3, ['b', 'b']]
[1, 2, 3, ['a', 'b']]
⭐~浅拷贝:拷贝的是对象的引用,只会拷贝一层
⭐~深拷贝:会递归的拷贝对象里面每个元素所有的副本
⭐~浅拷贝:如同第二个文件夹复制第一个文件夹里面文件的快捷方式,当修改第二个文件夹里面快捷文件的内容时,第一个文件夹里面对应文件的内容也会改变。

⭐~深拷贝:如同拷贝一个文件夹副本,当修改原文件夹中文件的内容时,副本文件夹里面文件的内容,完全不受影响。

散列类型
散列类型用来表示无序集合。
1. 集合

python 中集合(set)类型与数学中的集合类型一致,用来表示无序不重复元素的集合。
![]()
@`````````````````````````````````````````````````````````````````````````````````````````````````$
1.1 集合定义
集合使用一对大括号 {} 进行定义,元素之间使用逗号隔开。集合中的元素必须是不可变类型。
a = {1, 2, 3, 4, 5, 6}
b = {1,2,'a',('a',),1.5} # 集合中元素必须是不可变类型
print('a的类型为:', type(a)) # a的类型为: <class 'set'>
print('b的类型为:', type(b)) # b的类型为: <class 'set'>
{[1,2,3],(1,2,3)}
TypeError Traceback (most recent call last)
in
----> 1 {[1,2,3],(1,2,3)}
TypeError: unhashable type: 'list'
注意空集合的定义方式是 set()
a = set() # 空集合
# 注a = {} 是空字典
print(a)
set()
⭐集合不支持拼接和多次输出
@`````````````````````````````````````````````````````````````````````````````````````````````````$
1.2 集合的常用操作
1.2.1)添加元素
集合添加元素常用函数有两个:add 和 update
set.add(obj),向集合中添加元素 obj,如果集合中不存在则添加
s = {1,2}
s.add(1)
print(s)
{1, 2}
s.add(3)
print(s)
{1, 2, 3}

set.update(iterable),向集合中添加多个元素,如果集合中不存在则添加
iterable:可迭代类型,即可被for循环的,除了数字、bool值和None
s = {1,2}
s.update({2,3})
print(s)
{1, 2, 3}
s.update([3,4]) # 把3,4依次添加进集合
print(s)
{1, 2, 3, 4}

1.2.2)删除元素
set.pop() 随机删除并返回集合中的一个元素,如果集合中元素为空则抛出异常。
可做抽奖代码
s = {'a','b','c'}
s.pop()
'a'
set.remove(ele),从集合中删除元素 ele,如果不存在则抛出异常。
s = {'a','b','c'}
s.remove('a')
print(s)
{'b', 'c'}
s.remove('d')
KeyError Traceback (most recent call last)
in
----> 1 s.remove('d')
KeyError: 'd'
set.discard(ele),从集合中删除元素 ele,如果不存在不做任何操作
s = {'a','b','c'}
s.discard('d')
print(s)
{'a', 'b', 'c'}
set.clear(),清空集合
s = {1,2,3}
s.clear()
print(s)
set()
1.2.3)集合运算
| 数学符号 | python 运算符 | 含义 | 定义 |
|---|---|---|---|
| ∩ | & | 交集 | 一般地,由所有属于 A 且属于 B 的元素所组成的集合叫做 AB 的交集。 |
| ∪ | | | 并集 | 一般地,由所有属于集合 A 或属于集合 B 的元素所组成的集合,叫做 AB 的并集 |
| -或\ | - | 相对补集/差集 | A-B,取在 A 集合但不在 B 集合的项 |
| ^ | 对称差集/反交集 | A^B,取只在 A 集合和只在 B 集合的项,去掉两者交集项 |
交集 intersection()
取既属于集合 A 和又属于集合 B 的项组成的集合叫做 AB 的交集
s1 = {1,2,3}
s2 = {2,3,4}
s = s1 & s2
print(s)
# print(s1.intersection(s2))
{2, 3}
并集 union()
集合 A 和集合 B 的所有元素组成的集合称为集合 A 与集合 B 的并集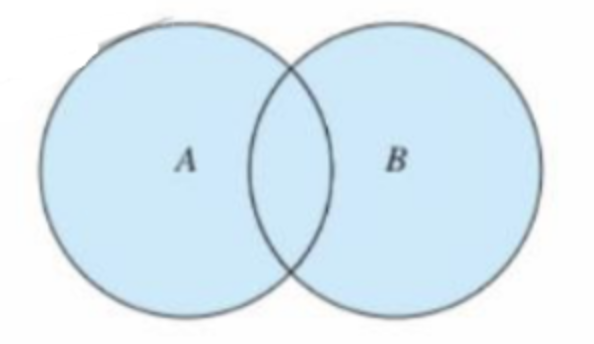
s1 = {1,2,3}
s2 = {2,3,4}
s = s1|s2
print(s)
# print(s1.union(s2))
{1, 2, 3, 4}
补集 difference()(差集)
取在集合 A 中不在集合 B 中的项组成的集合称为 A 相对 B 的补集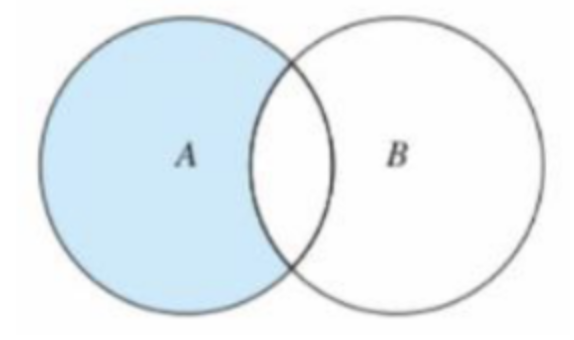
s1 = {1,2,3}
s2 = {2,3,4}
s = s1-s2
print(s)
print(s1.difference(s2))
{1}
对称差集 symmetric_difference()
取不在集合 AB 交集里的元素组成的集合称为对称差集,也叫反交集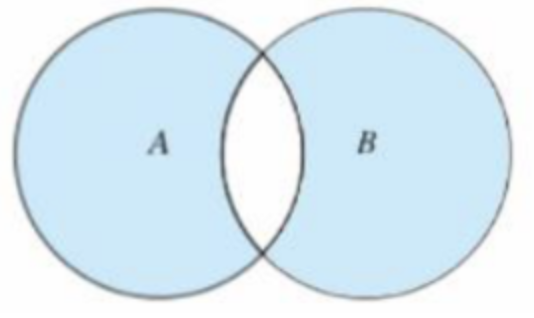
s1 = {1,2,3}
s2 = {2,3,4}
s = s1^s2
print(s)
print(s1.symmetric_difference(s2))
{1, 4}
1.2.4)集合查询
⭐ set 无序的,查询需要转换成列表
s1 = {"huahua","花花","为什么","那么","红"}
lst1 = list(s1) # 进行转换
print(lst1[0])
@`````````````````````````````````````````````````````````````````````````````````````````````````$
1.3 集合去重
集合具有天生去重的性质,因此可以利用它来去除序列中的重复元素
ls = [1,1,2,3,4,4,3,2,5]
ls = list(set(ls))
print(ls)
[1, 2, 3, 4, 5]
set('aabbcc')
{'a', 'b', 'c'}
@`````````````````````````````````````````````````````````````````````````````````````````````````$
1.4 集合类型转换


@`````````````````````````````````````````````````````````````````````````````````````````````````$
2. 字典

因为集合无序,因此不能很便捷的获取特定元素。利用集合元素不重复的特性,使集合中的元素映射值组成键值对,再通过键来获取对应的值。
@`````````````````````````````````````````````````````````````````````````````````````````````````$
2.1 字典的定义
python 中的字典(dict)数据类型就是键值对的集合,使用一对大括号进行定义,键值对之间使用逗号隔开,键和值使用冒号分割。
字典中的键必须是不可变数据类型,且不会重复,值可以是任意数据类型,且支持修改。
⭐ key通常用str
a = {} # 空字典
b = {
1: 2, # key:数字;value:数字
2: 'hello', # key:数字;value:字符串
('k1',): 'v1', # key:元祖;value:字符串
'k2': [1, 2, 3], # key:字符串;value:列表
'k3': ('a', 'b', 'c'), # key:字符串;value:元祖
'k4': { # key:字符串;value:字典
'name': 'feifei',
'age': '18'
}
}
print('a的类型为:', type(a)) # a的类型为: <class 'dict'>
print('b的类型为:', type(b)) # b的类型为: <class 'dict'>
⭐ 字典不支持加号拼接和乘号多次输出

@`````````````````````````````````````````````````````````````````````````````````````````````````$
2.2 字典的索引
字典通过键值对中的键作为索引来获取对应的值。字典中的键是无序的。
d = {1:2, 'key': 'value'}
print(d[1])
2
print(d['key'])
value
这种方式很好的将键和值联系起来,就像查字典一样。

@`````````````````````````````````````````````````````````````````````````````````````````````````$
2.3 字典的常用操作
2.3.1)增加元素
字典可以直接利用 key 索引赋值的方式进行添加元素,如果 key 存在则修改字典
d = {'name': 'xinlan'}
d['age'] = 18
print(d)
{'name': 'xinlan', 'age': 18}
dict.update(new_dict),将 new_dict 合并进 dict 中。
d = {'name': 'xinlan'}
n_d = {'age':18, 'sex':'男'}
d.update(n_d)
print(d)
{'name': 'xinlan', 'age': 18, 'sex': '男'}
d.update({'sex': '女','height': 170}) # 当有重复key的时候会覆盖原值
print(d)
{'name': 'xinlan', 'age': 18, 'sex': '女', 'height': 170}
2.3.2)修改元素
直接通过 key 索引赋值的方式可以对字典进行修改,如果 key 不存在则添加
d = {'name': 'xinlan'}
d['name'] = 'XinLan'
print(d)
{'name': 'XinLan'}
多修改:update
2.3.3)删除元素
dict.pop(key[,d]),删除指定的 key 对应的值并返回该值,如果 key 不存在则返回 d,如果没有给定 d,则抛出异常
d = {'name': 'xinlan','age': 18}
d.pop('age')
18
print(d)
{'name': 'xinlan'}
d.pop('age') # 报错

dict.popitem(),按照LIFO(last-in,first-out)后进先出的方式删除字典 dict 中的一个键值对,并以二元元组 (key,value) 的方式返回
d = {'name': 'Felix','age': 18}
d.popitem()
('age', 18)

clear(),清空字典
d = {'name': 'Felix','age': 18}
d.clear()
del字典名[key],通过key来进行删除,删除键值对
2.3.4)查询元素
通过 key 索引可以直接获取 key 对应的值,如果 key 不存在则抛出异常。
d = {1:2, 'key': 'value'}
print(d[1])
2
d['name']
KeyError Traceback (most recent call last)
in
----> 1 d['name']
KeyError: 'name'
dict.get(key,default=None),获取 key 对应的 value 如果不存在返回 default
交互式输出,返回None不显示,可以用print打印出来

d = {1:2, 'key': 'value'}
d.get(1)
2
d.get('name',0)
0
2.3.5)字典常用方法



@`````````````````````````````````````````````````````````````````````````````````````````````````$
2.4 字典的转换


7️⃣ 其他类型
1. None
None 是 python 中的特殊数据类型,它的值就是它本身 None,表示空,表示不存在。
print(None) # 注意首字母大写
None
练习:
1.用户输入三角形三边长度,并计算三角形的面积
a = float(input("请输入三角形第一边的边长 a:"))
b = float(input("请输入三角形第二边的边长 b:"))
c = float(input("请输入三角形第三边的边长 c:"))
if a+b>c or b+c>a or c+a>b:
p = (a+b+c)/2
s = (p*(p-a)*(p-b)*(p-c))**0.5
print("三角形的面积是:{}".format(s))
else:
print("两边之和必须大于第三边")
