
redis学习
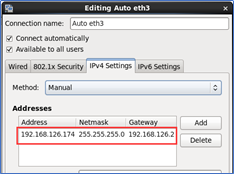
1.1.1 配置静态IP地址
- 检查当前的IP地址 ifconfig
本机IP地址: 192.168.126.174
- 配置静态IP地址
1.1.2 当前系统架构存在的问题
说明:如果有大量的用户请求,如果频繁的读取数据库,这样的效率依然很低,一般大型公司都会采用缓存机制.当前最流行的缓存服务器Redis.
说明:如果有大量的用户请求,如果频繁的读取数据库,这样的效率依然很低,一般大型公司都会采用缓存机制.当前最流行的缓存服务器Redis.
1.1.1 缓存机制
缓存机制:缓存机制能够有效的降低用户访问物理设备的访问频次.缓存中的数据就是数据库中的数据.当数据库数据发现更新操作时,也应该及时更新缓存.保证数据的一致性.
实现缓存需要解决的问题:
- 缓存设计语言. C语言编辑.
- 如何防止缓存数据丢失? 定期将数据持久化
- 如何控制内存大小? LRU算法
- 缓存数据如何存储?什么样的数据结构??? Key-value
1.1.2 Redis介绍
Redis是一个开源(BSD许可),采用key-value结构进行数据存储,用作数据库,缓存和消息队列。它支持数据结构,如字符串,散列,列表,集合,带有范围查询的排序集,位图,超级日志,具有半径查询和流的地理空间索引。Redis具有内置复制,Lua脚本,LRU算法,事务和不同级别的磁盘持久性,并通过Redis Sentinel提供高可用性并使用Redis Cluster自动分区.
速度:读写速度平均10万/秒
1.1.3 Redis下载
http://www.redis.cn/download.html
1.1.4 Redis安装
- 上传安装文件
- 解压文件
- 编辑和安装
Make:编译环境.
安装指令: make install
1.1.5 编辑redis.conf
- 注释IP绑定
- 关闭保护模式
- 开启后台启动
1.1.6 基本命令
- 启动命令: redis-server redis.conf
- 关闭命令: redis-cli -p 6379 shutdown
- 进入客户端: redis-cli -p 6379
- 退出客户端 exit
1.2 Redis命令
1.2.1 String类型
|
命令 |
说明 |
案例 |
|
set |
添加key-value |
set username admin |
|
get |
根据key获取数据 |
get username |
|
strlen |
获取key的长度 |
strlen key |
|
exists |
判断key是否存在 |
exists name 返回1存在 0不存在 |
|
del |
删除redis中的key |
del key |
|
Keys |
用于查询符合条件的key |
keys * 查询redis中全部的key keys n?me 使用占位符获取数据 keys nam* 获取nam开头的数据 |
|
mset |
赋值多个key-value |
mset key1 value1 key2 value2 key3 value3 |
|
mget |
获取多个key的值 |
mget key1 key2 |
|
append |
对某个key的值进行追加 |
append key value |
|
type |
检查某个key的类型 |
type key |
|
select |
切换redis数据库 |
select 0-15 redis中共有16个数据库 |
|
flushdb |
清空单个数据库 |
flushdb |
|
flushall |
清空全部数据库 |
flushall |
|
incr |
自动加1 |
incr key |
|
decr |
自动减1 |
decr key |
|
incrby |
指定数值添加 |
incrby 10 |
|
decrby |
指定数值减 |
decrby 10 |
|
expire |
指定key的生效时间 单位秒 |
expire key 20 key20秒后失效 |
|
pexpire |
指定key的失效时间 单位毫秒 |
pexpire key 2000 key 2000毫秒后失效 |
|
ttl |
检查key的剩余存活时间 |
ttl key |
|
persist |
撤销key的失效时间 |
persist key |
1.2.2 Hash类型
说明:可以用散列类型保存对象和属性值
例子:User对象{id:2,name:小明,age:19}
|
命令 |
说明 |
案例 |
|
hset |
为对象添加数据 |
hset key field value |
|
hget |
获取对象的属性值 |
hget key field |
|
hexists |
判断对象的属性是否存在 |
HEXISTS key field 1表示存在 0表示不存在 |
|
hdel |
删除hash中的属性 |
hdel user field [field ...] |
|
hgetall |
获取hash全部元素和值 |
HGETALL key |
|
hkyes |
获取hash中的所有字段 |
HKEYS key |
|
hlen |
获取hash中所有属性的数量 |
hlen key |
|
hmget |
获取hash里面指定字段的值 |
hmget key field [field ...] |
|
hmset |
为hash的多个字段设定值 |
hmset key field value [field value ...] |
|
hsetnx |
设置hash的一个字段,只有当这个字段不存在时有效 |
HSETNX key field value |
|
hstrlen |
获取hash中指定key的长度 |
HSTRLEN key field |
|
hvals |
获取hash的所有值 |
HVALS user |
1.2.3 List类型
说明:Redis中的List集合是双端循环列表,分别可以从左右两个方向插入数据.
List集合可以当做队列使用,也可以当做栈使用
队列:存入数据的方向和获取数据的方向相反
栈:存入数据的方向和获取数据的方向相同
|
命令 |
说明 |
案例 |
|
lpush |
从队列的左边入队一个或多个元素 |
LPUSH key value [value ...] |
|
rpush |
从队列的右边入队一个或多个元素 |
RPUSH key value [value ...] |
|
lpop |
从队列的左端出队一个元素 |
LPOP key |
|
rpop |
从队列的右端出队一个元素 |
RPOP key |
|
lpushx |
当队列存在时从队列的左侧入队一个元素 |
LPUSHX key value |
|
rpushx |
当队列存在时从队列的右侧入队一个元素 |
RPUSHx key value |
|
lrange |
从列表中获取指定返回的元素 |
LRANGE key start stop Lrange key 0 -1 获取全部队列的数据 |
|
lrem |
从存于 key 的列表里移除前 count 次出现的值为 value 的元素。 这个 count 参数通过下面几种方式影响这个操作:
|
LREM list -2 “hello” 会从存于 list 的列表里移除最后两个出现的 “hello”。 需要注意的是,如果list里没有存在key就会被当作空list处理,所以当 key 不存在的时候,这个命令会返回 0。 |
|
Lset |
设置 index 位置的list元素的值为 value |
LSET key index value |
1.2.4 Redis事务命令
说明:redis中操作可以添加事务的支持.一项任务可以由多个redis命令完成,如果有一个命令失败导致入库失败时.需要实现事务回滚.
|
命令 |
说明 |
案例 |
|
multi |
标记一个事务开始 |
127.0.0.1:6379> MULTI OK |
|
exec |
执行所有multi之后发的命令 |
127.0.0.1:6379> EXEC OK |
|
discard |
丢弃所有multi之后发的命令 |
|
1.3 缓存三大问题
1.3.1 缓存穿透
条件:访问一个不存在的数据
说明:当访问一个不存在的数据时,因为缓存中没有这个key,导致缓存形同虚设.最终访问后台数据库.但是数据库中没有该数据所以返回null.
隐患:如果有人恶意频繁查询一个不存在的数据,可能会导致数据库负载高导致宕机.
总结:业务系统访问一个不存在的数据,称之为缓存穿透.
1.3.2 缓存击穿
条件:当缓存key失效/过期/未命中时,高并发访问该key
说明:如果给一个key设定了失效时间,当key失效时有一万的并发请求访问这个key,这时缓存失效,所有的请求都会访问后台数据库.称之为缓存击穿.
场景:微博热点消息访问量很大,如果该缓存失效则会直接访问后台数据库,导致数据库负载过高.
1.3.3 缓存雪崩
前提:高并发访问,缓存命中较低或者失效时
说明:假设缓存都设定了失效时间,在同一时间内缓存大量失效.如果这时用户高并发访问.缓存命中率过低.导致全部的用户访问都会访问后台真实的数据库.
场景:在高并发条件下.缓存动态更新时
- Day01.
2 Redis高级
2.1 Redis入门
2.1.1 导入jar包
<!-- jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>${jedis.version}</version>
</dependency>
<!--添加spring-datajar包 -->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-redis</artifactId>
<version>1.4.1.RELEASE</version>
</dependency>
2.1.2 String类型案例
前提:关闭防火墙 service iptables stop
/**
* 1.通过IP和端口可以连接Redis
* 2.操作方法就是命令
* **/
@Test
public void StringTest() {
Jedis jedis =
new Jedis("192.168.126.174", 6379);
String result = jedis.set("1811","今天周四");
System.out.println("保存后的返回值为:"+result);
System.out.println("获取数据:"+jedis.get("1811"));
}
2.1.3 Hash类型
//操作hash
@Test
public void testHash() {
Jedis jedis = new Jedis("192.168.126.174", 6379);
jedis.hset("dog", "name","二哈");
jedis.hset("dog", "age", "7");
Map<String,String> map =
jedis.hgetAll("dog");
System.out.println(map);
}
2.1.4 操作List集合
/**操作List集合,改数据类型,不能长期保存数据,
数据最终会被消费.*/
@Test
public void testList() {
Jedis jedis = new Jedis("192.168.126.174", 6379);
jedis.rpush("list","1","2","3");
String a = jedis.rpop("list");
System.out.println(a);
}
2.1.5 Redis事务控制
把redis当做数据库使用时,才会使用事务.
//控制redis事务问题
@Test
public void tx() {
Jedis jedis = new Jedis("192.168.126.174", 6379);
//开启事务
Transaction transaction = jedis.multi();
try {
transaction.set("kk", "kk");
transaction.set("ww", "ww");
int a = 1/0;
transaction.exec();
} catch (Exception e) {
e.printStackTrace();
transaction.discard();
}
}
2.1.6 什么样的数据添加缓存
说明:应该将不变的数据,添加到缓存中.如果数据频繁的修改不适合添加缓存.
- 省/市/县/乡/
- 收货地址
- 商品分类目录
- 当用户点击商品分类按钮时,要进行商品分类的查询.
- 首先应该查询缓存,key必须唯一.
- 3. 如果缓存中的数据为null,则查询数据库.将数据库中查询的结果保存到缓存中. Key:JSON串
- 如果缓存中有数据.将json串转为java对象,之后返回给用户.
2.2 实现商品分类缓存操作
2.2.1 实现原理步骤
2.2.2 ObjectMapper介绍
public class ObjectMapperTest {
@Test
public void objectToJSON() throws IOException {
User user = new User();
user.setId(100);
user.setName("测试");
user.setAge(10000);
user.setSex("男");
ObjectMapper objectMapper = new ObjectMapper();
String json =
objectMapper.writeValueAsString(user);
System.out.println(json);
//将json串转化为对象
User user2 =
objectMapper.readValue(json, User.class);
//get方法获取属性值. set方法为属性赋值.
System.out.println(user2.toString());
}
@SuppressWarnings("unchecked")
@Test
public void listToJSON() throws IOException {
List<User> userList = new ArrayList<User>();
User user1 = new User();
user1.setId(1);
user1.setName("杯子");
user1.setAge(19);
user1.setSex("男");
userList.add(user1);
ObjectMapper objectMapper = new ObjectMapper();
String result =
objectMapper.writeValueAsString(userList);
System.out.println(result);
//将JSON转化为List集合
List<User> uList =
objectMapper.readValue(result,ArrayList.class);
System.out.println(uList);
}
}
2.3 Spring整合Redis
2.3.1 编辑pro文件
2.3.2 编辑Spring配置文件
<!--1.创建objectMapper -->
<bean id="objectMapper" class="com.fasterxml.jackson.databind.ObjectMapper"></bean>
<!--2.创建Jedis对象 -->
<bean id="jedis" class="redis.clients.jedis.Jedis">
<constructor-arg name="host" value="${redis.host}"/>
<constructor-arg name="port" value="${redis.port}"/>
</bean>
2.3.3 编辑ObjectMapper工具类
public class ObjectMapperUtil {
private static ObjectMapper mapper = new ObjectMapper();
public static String toJSON(Object object) {
String json = null;
try {
json = mapper.writeValueAsString(object);
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException();
}
return json;
}
@SuppressWarnings("unchecked")
public static <T> T toObject(String json,Class<?> targetClass) {
T t = null; //定义泛型对象
try {
t = (T) mapper.readValue(json,targetClass);
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException();
}
return t;
}
}
2.3.4 修改Nginx配置项
#编辑后台管理服务器
server {
listen 80;
server_name manage.jt.com;
location / {
#代理请求url路径
#proxy_pass http://jtLinux;
#proxy_pass http://jt;
proxy_pass http://localhost:8091;
proxy_connect_timeout 3;
proxy_read_timeout 3;
proxy_send_timeout 3;
}
}
2.3.5 修改数据库链接
jdbc.driver=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://localhost:3306/jtdb?useUnicode=true&characterEncoding=utf8&autoReconnect=true&allowMultiQueries=true
jdbc.username=root
jdbc.password=root
2.3.6 缓存代码实现
/**
* 1.生成key
* 2.查询redis缓存
* null: 则调用业务层方法获取数据,
* 利用工具类封装为JSON,保存到缓存中
* !null:
* 将缓存转化为对象返回
*/
@SuppressWarnings("unchecked")
@Override
public List<EasyUITree> findCacheItemCat(Long parentId) {
String key = "ITEM_CAT_" + parentId;
String json = jedis.get(key);
List<EasyUITree> treeList = new ArrayList<>();
if(StringUtils.isEmpty(json)) {
treeList = findItemCatList(parentId);
String result =
ObjectMapperUtil.toJSON(treeList);
jedis.set(key, result);
System.out.println("查询数据库!!!!!");
}else {
treeList = ObjectMapperUtil.toObject(json,ArrayList.class);
System.out.println("查询缓存!!!!!!!");
}
return treeList;
}
2.3.7 Redis缓存测试
- 没有缓存
- 添加缓存
2.4 Redis分片技术
2.4.1 单点redis存在问题
说明:单台redis中使用的内存大小有限.默认的内存的大小为10M,如果使用时内存不足,如何处理.
- 扩展内存
修改内存大小:
最大的内存大小不要超过1G 512M-1024M
- 采用分片方式
准备多台redis.实现内存扩容
2.4.2 Redis分片搭建
- 新建文件夹
mkdir shards
- 拷贝redis配置文件
[root@localhost redis-3.2.8]# cp redis.conf shards/redis-6379.conf
[root@localhost redis-3.2.8]# cp redis.conf shards/redis-6380.conf
[root@localhost redis-3.2.8]# cp redis.conf shards/redis-6381.conf
- 修改配置文件端口号
[root@localhost shards]# vim redis-6380.conf
[root@localhost shards]# vim redis-6381.conf
- 启动多台redis
[root@localhost shards]# redis-server redis-6379.conf
[root@localhost shards]# redis-server redis-6380.conf
[root@localhost shards]# redis-server redis-6381.conf
- 检查Redis启动是否成功
ps -ef |grep redis
2.4.3 Redis分片入门案例
@Test
public void test01() {
List<JedisShardInfo> shards =
new ArrayList<JedisShardInfo>();
JedisShardInfo info1 =
new JedisShardInfo("192.168.126.174",6379);
JedisShardInfo info2 =
new JedisShardInfo("192.168.126.174",6380);
JedisShardInfo info3 =
new JedisShardInfo("192.168.126.174",6381);
shards.add(info1);
shards.add(info2);
shards.add(info3);
ShardedJedis jedis = new ShardedJedis(shards);
jedis.set("1811","分片测试");
System.out.println(jedis.get("1811"));
//问:数据保存到了哪个redis节点??如何存储??
}
2.5 Hash一致性
2.5.1 基本实现
角色: node(节点) key
内存:node*n 实现内存扩容.
2.5.2 均衡性
说明:尽可能的让节点均匀的保存数据.
问题:如果没有均衡性算法,则会导致数据负载不均.
解决方法:引入虚拟节点的概念.通过虚拟节点动态的平衡数据.
2.5.3 单调性
说明:当节点新增时,节点信息会动态的划分,实现数据的挂载.
原则:如果节点新增时,尽肯能的保证原有的数据保持不变!只平衡部分数据.
单调性中描述节点只能新增,不能减少,如果节点个数少了.则内存缺失.分片不能使用.
- Day02.
Redis高级
2.6 AOP实现redis缓存
2.6.1 定义注解
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
//反射???? 不加参数??? 方法名称 find
public @interface CacheAnno {
String key(); //定义key值
int index(); //参数定义位置
Class targetClass(); //定义目标类型
CACHE_TYPE cacheType() default CACHE_TYPE.FIND;
//定义泛型类型
enum CACHE_TYPE{
FIND, //定义查找
UPDATE //定义更新
}
}
2.6.2 编辑切面
@Component //交给spring容器管理
@Aspect //标识切面
public class CacheAspect {
//当执行时才注入,后期将该对象换为集群对象
@Autowired(required=false)
private Jedis jedis;
/**
* 控制用户是否查询数据库 目标方法
* @param joinPoint
* @param cacheAnno
* @return
*/
//利用环绕通知 拦截所有的缓存注解
@Around("@annotation(cacheAnno)")
public Object around(ProceedingJoinPoint joinPoint,CacheAnno cacheAnno) {
return getObject(joinPoint,cacheAnno);
}
public Object getObject(ProceedingJoinPoint joinPoint, CacheAnno cacheAnno) {
//获取参数
CACHE_TYPE cacheType = cacheAnno.cacheType();
String key = cacheAnno.key();
int index = cacheAnno.index();
Class<?> targetClass = cacheAnno.targetClass();
//根据位置获取参数
Long id = (Long) joinPoint.getArgs()[index];
//拼接参数 ITEM_CAT_0
String redisKey = key + id;
Object object = null;
switch (cacheType) {
case FIND: //表示查询缓存
object = findObject(joinPoint,redisKey,targetClass);
break;
case UPDATE: //表示更新缓存
object = updateObject(joinPoint,redisKey);
break;
}
return object;
}
private Object findObject(ProceedingJoinPoint joinPoint, String key, Class<?> targetClass) {
//检查缓存中是否有数据
String result = jedis.get(key);
Object object = null;
try {
if(StringUtils.isEmpty(result)) {
//表示缓存中没有数据,则查询数据库
object = joinPoint.proceed();
String json = ObjectMapperUtil.toJSON(object);
jedis.set(key, json);
System.out.println("AOP查询真实数据库!!");
}else {
//表示缓存中有数据,查询缓存
object = ObjectMapperUtil.toObject(result, targetClass);
System.out.println("AOP查询缓存!!");
}
} catch (Throwable e) {
e.printStackTrace();
throw new RuntimeException();
}
return object;
}
private Object updateObject(ProceedingJoinPoint joinPoint, String redisKey) {
//更新缓存,删除即可
Object object = null;
try {
jedis.del(redisKey);
object = joinPoint.proceed();
System.out.println("AOP缓存删除");
} catch (Throwable e) {
e.printStackTrace();
throw new RuntimeException();
}
return object;
}
}
2.7 Spring整合Redis分片
2.7.1 编辑pro文件
redis.host=192.168.126.174
redis.port.a=6379
redis.port.b=6380
redis.port.c=6381
2.7.2 编辑配置文件
<!--value如果存储字符串/基本类型-->
<!--ref存储对象-->
<!--2.redis分片 -->
<bean id="shardJedis" class="redis.clients.jedis.ShardedJedis">
<constructor-arg name="shards">
<list>
<ref bean="info1"/>
<ref bean="info2"/>
<ref bean="info3"/>
</list>
</constructor-arg>
</bean>
<bean id="info1" class="redis.clients.jedis.JedisShardInfo">
<constructor-arg name="host" value="${redis.host}"/>
<constructor-arg name="port" value="${redis.port.a}"/>
</bean>
<bean id="info2" class="redis.clients.jedis.JedisShardInfo">
<constructor-arg name="host" value="${redis.host}"/>
<constructor-arg name="port" value="${redis.port.b}"/>
</bean>
<bean id="info3" class="redis.clients.jedis.JedisShardInfo">
<constructor-arg name="host" value="${redis.host}"/>
<constructor-arg name="port" value="${redis.port.c}"/>
</bean>
2.7.3 分片缺点
- 安全性不好,用户可以利用客户端直接set操作,修改数据.
- 由于单调性的要求,节点只能增,不能减,如果redis节点宕机,整合服务不能运行. 分片没有实现高可用
2.8 Redis中哨兵机制
2.8.1 哨兵机制说明
1.前提:数据必须同步,搭建redis主从.
2.哨兵只会监听主机的状态,通过心跳机制进行检测 ping-pong
3.当哨兵发现主机3次都没有响应时,这时认为主机宕机.内部进行推选.
4.当哨兵通过读取主机的配置文件,发现当前的主机中有2个从机.所以哨兵推选一台从机当做现在的主节点.
5.当哨兵成功推选了从机当主节点时.哨兵会修改另外节点的配置文件.重新定义主从结构.
2.9 主从同步搭建
2.9.1 复制文件夹
cp -r shards sentinel
2.9.2 重启redis
[root@localhost sentinel]# redis-server redis-6379.conf
[root@localhost sentinel]# redis-server redis-6380.conf
[root@localhost sentinel]# redis-server redis-6381.conf
2.9.3 检查redis状态
2.9.4 检查节点状态信息
命令: info replication
2.9.5 实现主从挂载
- 进入6380客户端中 进行主从挂载
redis-cli -p 6380
- 挂载命令
SLAVEOF 192.168.126.174 6379
- 检查状态
- 将6381实现主从挂载.
- 检查主机的状态
2.9.6 配置哨兵
- 复制配置文件
cp sentinel.conf sentinel
- 修改保护模式
- 修改哨兵的配置
sentinel monitor mymaster 192.168.126.174 6379 1
mymaster: 表示主机的变量名称.
IP:端口 主机的IP和端口
2:几票同意,即选举成功!!!
- 修改宕机的推选时间
- 修改推选失败的超时时
2.9.7 哨兵高可用测试
- 启动哨兵
redis-sentinel sentinel.conf
- 哨兵测试
说明:首先将redis主机宕机.之后等待10秒后,检查哨兵是否进行推选.
如果哨兵完成推选.并且将其余的机器更新主从结构,则哨兵测试成功!
2.9.8 关于哨兵配置的错误
- 如果哨兵选举时,内部有误.3个节点中有3主结构.这样的选举结构有问题.
将配置文件全部删除.
2.10 Spring整合哨兵
2.10.1 哨兵配置入门案例
/**
* 参数说明
* 1.masterName 主机的变量名称
* 2.sentinels 哨兵的信息
* String=IP:端口
*/
@Test
public void testSentinel() {
Set<String> sentinels = new HashSet<>();
sentinels.add("192.168.126.174:26379");
JedisSentinelPool pool =
new JedisSentinelPool("mymaster", sentinels);
Jedis jedis = pool.getResource();
jedis.set("aa", "abc");
System.out.println("获取redis数据:"+jedis.get("aa"));
jedis.close();
}
2.10.2 编辑pro文件
redis.masterName=mymaster
redis.node1=192.168.126.174:26379
2.10.3 编辑Spring配置文件
<bean id="jedisSentinelPool" class="redis.clients.jedis.JedisSentinelPool">
<constructor-arg name="masterName" value="${redis.masterName}"/>
<constructor-arg name="sentinels">
<set>
<value>${redis.node1}</value>
</set>
</constructor-arg>
</bean>
2.10.4 编辑工具Service
@Service
public class RedisService {
//使用时注入
@Autowired(required=false)
private JedisSentinelPool pool;
//set get
public void set(String key,String value) {
Jedis jedis = pool.getResource();
jedis.set(key, value);
jedis.expire(key, 7*24*3600);
jedis.close();
}
public String get(String key) {
Jedis jedis = pool.getResource();
String result = jedis.get(key);
jedis.close();
return result;
}
}
编辑完成后,将Common打包!!
2.10.5 修改业务代码
- 注入工具类对象
- 编辑业务代码
2.10.6 页面效果展现
2.11 Redis持久化策略
2.11.1 Redis持久化原理
- redis应该定期将内存中的数据进行持久化.
- 当redis节点重启时.首先应该读取持久化文件.恢复内存数据.
- RDB模式是redis默认的持久化策略.
- RDB模式,能够定期将内存中的数据进行保存.
- RDB模式中可能会丢失数据.所以如果redis当做数据库/队列时不要使用该模式
- RDB模式备份效率是最高的.
- RDB模式备份时做的是内存的快照,并且持久化文件中,只保留最新的内存数据.持久化文件大小是可控的.
- 持久化文件的名称
2.11.2 RDB模式
2.11.2.1 RDB模式说明
2.11.2.2 RDB模式配置
- 持久化文件的路径
- 持久化命令
save :立即执行持久化
bgsave :开启另外的线程进行持久化.
- 默认的持久化周期
save 900 1 #在900秒内,执行一次set操作,则持久化一次
save 300 10 #在300秒内,执行10次set操作,则持久化一次
save 60 10000 #在60秒内,执行10000次set操作,则持久化一次
2.11.3 AOF模式
2.11.3.1 模式说明
- AOF模式默认是关闭的.需要手动的开启.
- AOF模式能够实现数据的实时存储,保证数据的有效性
- AOF模式一般使用在数据库/队列
- AOF模式效率低于RDB模式.
- AOF模式相当于记录了用户全部的操作过程,并且将用户的指令追加到持久化文件中.该持久化文件占用的空间大.恢复内存数据的时间长.
- 开启AOF模式
2.11.3.2 AOF模式配置
- AOF配置文件名称
3.持久化策略
# appendfsync always 每次执行set操作,则持久化一次
appendfsync everysec 每秒持久化一次.
# appendfsync no 由操作系统决定何时持久化一般默认15分钟
4.AOF文件保存的路径

2.12 Redis内存策略
2.12.1 内存策略由来
说明:作为一个优秀的缓存服务器,应该定义内存的大小,同时应该进行动态的维护.如果数据只增不减,.那么redis内存很快会被占满,如果后续有set操作时,则必然会报错.
策略:
- 必须设定redis内存最大值. 10M 最大1024M
- 如果内存使用量达75%时,则优化内存数据.则动态清理数据.
2.12.2 LRU算法
内存管理的一种页面置换算法,对于在内存中但又不用的数据块(内存块)叫做LRU,操作系统会根据哪些数据属于LRU而将其移出内存而腾出空间来加载另外的数据。
关于操作系统的内存管理,如何节省利用容量不大的内存为最多的进程提供资源,一直是研究的重要方向。而内存的虚拟存储管理,是现在最通用,最成功的方式—— 在内存有限的情况下,扩展一部分外存作为虚拟内存,真正的内存只存储当前运行时所用得到信息。这无疑极大地扩充了内存的功能,极大地提高了计算机的并发度。虚拟页式存储管理,则是将进程所需空间划分为多个页面,内存中只存放当前所需页面,其余页面放入外存的管理方式。
然而,有利就有弊,虚拟页式存储管理增加了进程所需的内存空间,却也带来了运行时间变长这一缺点:进程运行过程中,不可避免地要把在外存中存放的一些信息和内存中已有的进行交换,由于外存的低速,这一步骤所花费的时间不可忽略。因而,采取尽量好的算法以减少读取外存的次数,也是相当有意义的事情。
2.12.3 Redis中如何控制内存大小
volatile-lru :在设定了超时时间的数据中采用LRU方式删除数据.
allkeys-lru :在所有的key中采用LRU算法删除数据.
volatile-random :在设定了超时时间的key中随机删除.
allkeys-random :所有的key随机删除.
volatile-ttl : 在设定了超时时间的key中根据ttl(显示存活的剩余时间),将马上要超时的数据提前删除.
noeviction :该配置为默认值.当内存占满时,报错返回.
2.12.4 修改内存策略
2.12.5 Redis分片和哨兵总结
说明:
- redis单台,存储数据量很少
- redis分片.最主要的是实现了内存的扩容!!!!,缺点没有实现高可用.
- Redis哨兵.主要实现了Redis的高可用.但是哨兵没有实现高可用,内部维护繁琐,工作也不使用.
- Redis集群.实现分片+哨兵的全部的功能.并且不需要第三方监管.
Redis集群是通过节点内部进行推选,不需要依赖第三方.
搭建集群时,主机的个数是奇数个.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号