
1.如果有5张数据量过亿的表,如何查询总数据量?
对于大数据量的表,一般不用count(*),因为这个需要扫描整个表,性能有瓶颈
法1:用索引,如果有合适的索引,比如我有id,那就用count(id)来加速查询,避免扫描整个表
法2:用information_schema就可以直接获取到整个表的行数

2. CompletableFuture实现原理
是异步编程的一个工具,支持异步调用任务,他有两个参数,result用来存调用结果,stack是一个用链表实现的栈,用来保存所有后面依赖这个future的动作
当一个任务完成后,他会找到自己依赖的future,然后通过这个栈找到下一个要执行的completion,从而执行下一个任务。
流程:
- 检查主任务状态:未完成
- 将回调封装成 Completion 对象
- 使用 CAS 操作压入栈中
- 当主任务完成时,弹出栈中的 Completion 并执行
无锁并发
- 所有状态更新都使用 CAS(Compare-And-Swap) 操作
- 避免锁竞争,提高并发性能
3. 链式调用机制
- 每个回调(如
thenApply)被封装成Completion对象 - 使用 Treiber栈(无锁栈)存储这些依赖任务
- 当主任务完成时,依次弹出栈中的任务执行
4. 执行策略
- 同步执行:
thenApply()- 当前线程直接执行 - 异步执行:
thenApplyAsync()- 使用线程池(默认 ForkJoinPool.commonPool)
5. 状态管理
- 使用状态机管理任务状态:未完成 → 正常完成/异常完成/取消
- 任务完成后触发
postComplete()方法,执行所有依赖任务
3.IO 这一块常见的接口或者抽象类有哪些
分为字节流和字符流,字节流分为inputStream用来字节输入,和outputStream用来字节输出,字符流分为read和write,分别用于字符的输入和输出。还有FileSystem是文件相关的,常用方法有getPath(),getSeperstor()用于获取文件路径分隔符
4. spring的controller是单例还是多例,怎么保证并发的安全??
是单例,线程不安全的。怎么保证安全:不要使用非静态的成员变量,否则会发生数据逻辑混乱。如果非要使用,通过注解@Scope(“prototype”),将其设置为多例模式。
singleton(单例):只有一个共享的实例存在,所有对这个bean的请求都会返回这个唯一的实例。
prototype(多例):对这个bean的每次请求都会创建一个新的bean实例,类似于new。
5.jdk、cglib实现的区别
JDK动态代理:基于接口实现,生成的代理对象必须实现一个或多个接口,适用于目标对象没有实现接口的情况
cglib动态代理:基于继承实现,生成的代理对象不需要实现接口,适用于目标对象实现了接口的情况
6.Oracle与MySql的区别
Oracle更加大型,集群能力更强,适用于核心业务系统,高可用的场景。
Mysql是轻量级的,部署和维护更容易,适合中小型场景。
7.MySql大数据量表添加字段
1.创建一个新表,并删除他的主键和索引
2.在新表中添加新的字段
3.把旧表中的数据全部迁移到新表中
4.添加主键和索引
5.修改表名
8.登陆方式有哪几种鉴权?
JWT:用户信息存储在客户端(本地),不受跨域限制
cookie:用户信息存储在客户端(浏览器),
session:用户信息存储在服务端,占用服务器资源,有硬件成本
1.基于coockie-session的鉴权
1.用户登录时候,服务端验证账号密码后,创建一个唯一的Session(用于存储用户信息),并生成SessionID(用于传递给Cookie,由于只是一个ID,方便Cookie携带)
2.服务端将SessionID写入客户端Cookie,后续请求请求时客户端会自动携带该Cookie
3.服务端通过Cookie中的SessionID查找对应的Session,验证身份
优点:实现简单,无需额外前端处理(Cookie自动携带)、安全性较高(Session存储在服务端,客户端仅保存ID,减少敏感信息暴露风险)、支持服务端主动销毁Session(如强制登出)
缺点:Session存储在服务端(内存/数据库),对分布式系统不友好(需额外实现Session共享,如Redis集群)。
依赖Cookie(因为前面SessionID存入到Cookie中了),易受CSRF(跨站请求伪造)攻击(需配合Token和SameSite属性缓解)
2.基于Token的鉴权
Token是服务端生成的一串加密字符串,作为客户端请求的“通行证”,常见的有JWT(JSON Web Token)。
基于Token鉴权的原理:
1.用户登录后,服务端生成Token(包含用户信息、过期时间等,通过密钥签名)并返回给客户端。
2.客户端将Token存储在localStorage/sessionStorage/Cookie中,后续请求通过Header(如Authorization: Bearer <token>)携带。
3.服务端验证Token的签名和有效性(无需查询数据库),确认用户身份。
优点:无状态(服务端无需存储Token,仅通过密钥验证,适合分布式系统和微服务架构)
跨域友好:Token可通过Header携带,解决Cookie跨域限制。
灵活性高:支持多端(web、App、小程序)共用一套鉴权逻辑。
缺点:安全性依赖存储方式:若存在localStorage中,可能因XSS(跨站脚本攻击)攻击被盗取(建议结合HttpOnly Cookie存储)
难以主动销毁:Token一旦生成,在过期前无法强制失效(需配合黑名单机制弥补)。
payload可解码:虽然签名不可篡改,但payload是Base64编码(非加密),不可包含敏感信息
3.基于OAuth 2.0的第三方登录
OAuth2.0是一种授权框架,允许用户通过第三方平台(如微信、Github)登录应用,无需暴露账号密码。
基于OAuth2.0的第三方登录的原理:
1.应用请求用户授权第三方登录
2.用户同意,第三方返回授权码,应用通过授权码向第三方平台获取Access Token
3.应用使用Access Token从第三方平台上获取信息,完成登录。
优点:降低用户注册成本,提升登录体验、无需管理用户密码,减少安全风险、支持联合登录(同一用户在多平台上身份关联)
缺点:实现复杂,需对接第三方平台的OAuth接口、依赖第三方平台的稳定性和政策、存在隐私风险(用户信息需要共享到第三方)
4.基于SSO(单点登录)的鉴权
SSO允许用户在多个关联系统中,只需要登录一次即可访问所有系统(如企业内部系统、阿里云生态)
基于SSO鉴权的原理:
1.用户在SSO认证中心登录,获得全局票据(如Token)
2.访问其他系统时,系统会跳转到SSO中心验证票据,验证通过后无需再次登录
优点:提升用户体验,减少重复登录操作、集中管理用户身份,便于权限统一控制。
缺点:实现复杂度高(需设计统一的认证中心和票据验证机制)、单点故障风险:SSO中心故障会导致所有关联系统无法访问
5.基于生物识别的鉴权
利用用户生物特征(指纹、人脸、虹膜)进行身份验证,常见于移动端 App。
基于生物识别鉴权的原理:设备采集用户生物特征,与预存模板比对,验证通过后完成登录(通常结合本地加密和服务端二次校验)
优点:安全性极高,生物特征难以伪造;
便捷性强,无需记忆密码
缺点:依赖设备硬件支持(如指纹传感器、摄像头)、生物信息一旦泄露,无法像密码一样修改、适用场景有限
9. RBAC 用户,权限,角色
是一种权限管理模型,它将用户与权限通过角色进行关联,实现了权限管理的解耦和简化。
10.缓存预热
在 Spring Boot 项目启动时,预先将数据加载到缓存系统(如 Redis)中的一种机制。
在 Spring Boot 启动之后,可以通过以下手段实现缓存预热:
- 使用启动监听事件实现缓存预热。
- 使用 @PostConstruct 注解实现缓存预热。
- 使用 CommandLineRunner 或 ApplicationRunner 实现缓存预热。
- 通过实现 InitializingBean 接口,并重写 afterPropertiesSet 方法实现缓存预热。
11.常见的nosql数据库
键值型:redis. 使用场景:缓存热点数据、分布式锁、限流、计数器。
文档型:MongoDB 使用场景:用户评论,电商商品信息
列族型:HBase 使用场景:适用于海量数据存储,比如社交网络好友推荐
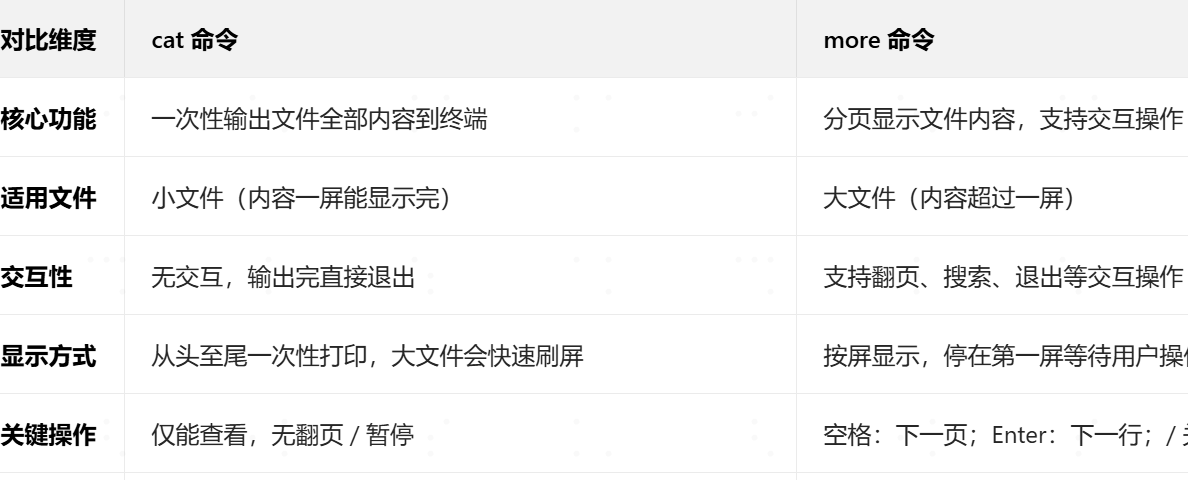
12.cat和more的区别
13.servlet生命周期
加载类,实例化,初始化,处理请求,销毁
14. servlet和jsp
servlet是处理业务逻辑的,jsp是处理页面内容的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号