实践Jmeter + ant + jenkins自动化框架
什么是自动化
通过一些自动化测试工具或自己造轮子实现模拟之前人工点点/写写的工作并验证其结果完成整个测试过程,这样的测试过程,便是自动化测试。
但其实每一个自动化测试的case都是从手工测试做起的,如果没有手工测试的基础,是没法进行自动化测试。(艺术源于生活)
为什么要做接口自动化
#1 自动测试的收益和手工测试的成本
接口自动化主要不是为了发现bug,而是为了节省成本和提高效率
1、回归和冒烟
2、持续集成
3、尽早发现bug
4、保证版本的稳定性
#2 不足之处
1、维护成本比较高
2、还是得依赖手工测试,很多问题无法发现
3、不是所有系统功能都适合做自动化
什么是框架
定义:为解决某些特定问题而约束边界,支撑整个问题解决方案,配套了一些解决问题的组件而构成的工具。(一位叫老_张博主的见解)
特定问题:什么问题?——自动化测试
约束边界:为什么约束?——明确测试范围和目的
解决方案:用什么方案解决问题?——编程语言+工具+其他
构成工具的组件:哪些组件?—— 用例、脚本、数据、日志、报告、通知
工具:特点是什么?—— 灵活性、可扩展性、高内聚低耦合
接口自动化需要的功能
1、校验(验证接口返回结果的正确性)
2、数据隔离(参数化、解耦)
3、数据传递(数据依赖)
4、可配置(多个环境下运行,好切换)
5、执行日志(帮助定位解决问题)
6、可视化报告(展示结果)
7、持续集成(可以每日构建,提前发现问题)
推荐常见框架对比
①、python + request + pytest + jenkins + mysql——数据驱动,比较灵活,很好封装,但是需要掌握python和pytest(很推荐)
②、Robot Framework + python——关键字驱动,上手难度较高(python,开发关键字)
③、Jmeter + ant/maven + jenkins——上手相对上面两个简单,可视化界面(完全支持java,不友好)
框架都有共通点:编程语言/接口工具+扫描编译工具+持续集成工具+数据库+项目管理工具
编程语言/接口工具:编写测试脚本,要么工具,要么代码;
扫描编译工具:要测试的文件扫描编译,一般配合集成工具使用;
持续集成工具:jenkins;
数据库:测试数据管理;
项目管理工具:测试结果统计管理;
搭建Jmeter + ant + jenkins框架(基于linux)
原理逻辑:jenkins驱动ant执行,ant驱动jmeter执行
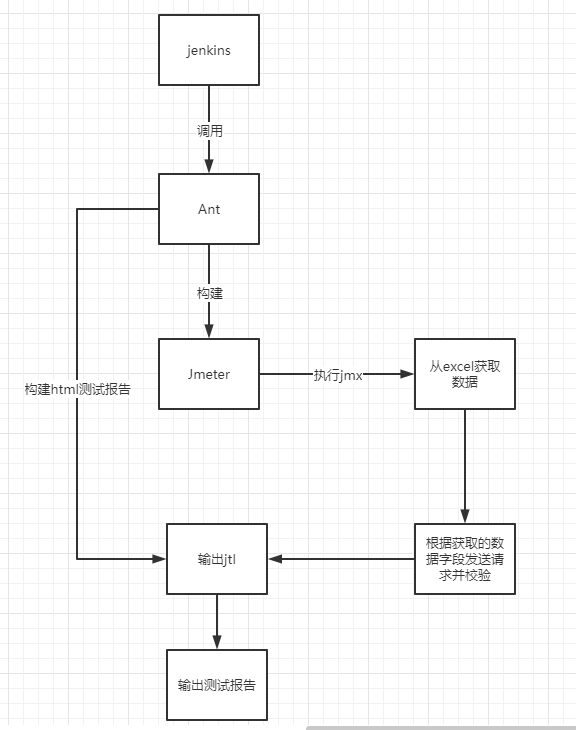
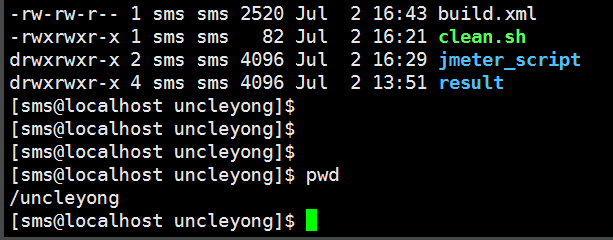


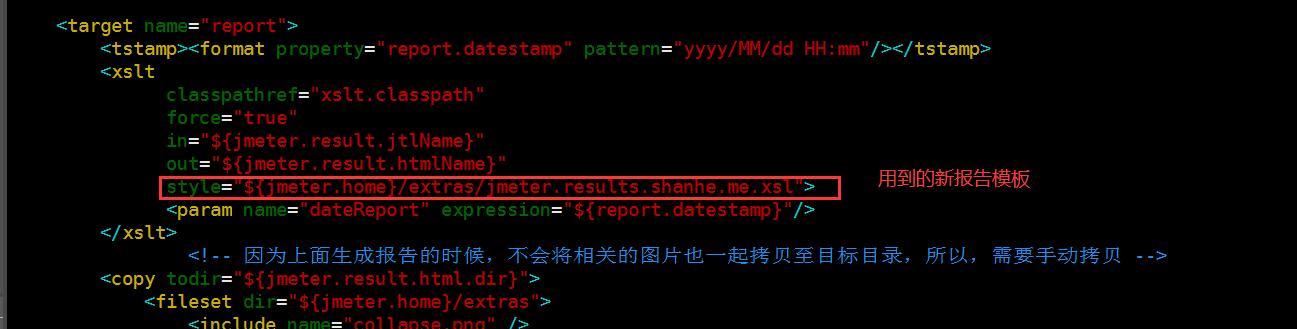

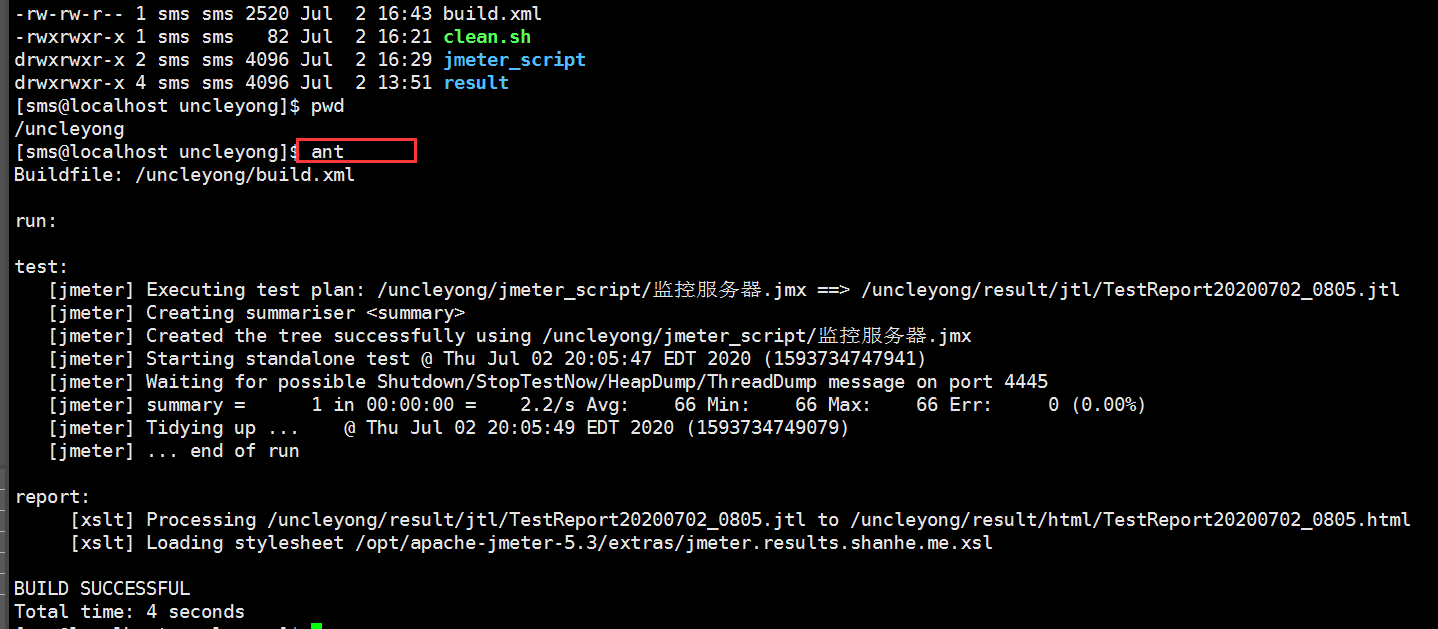
7)查看测试报告
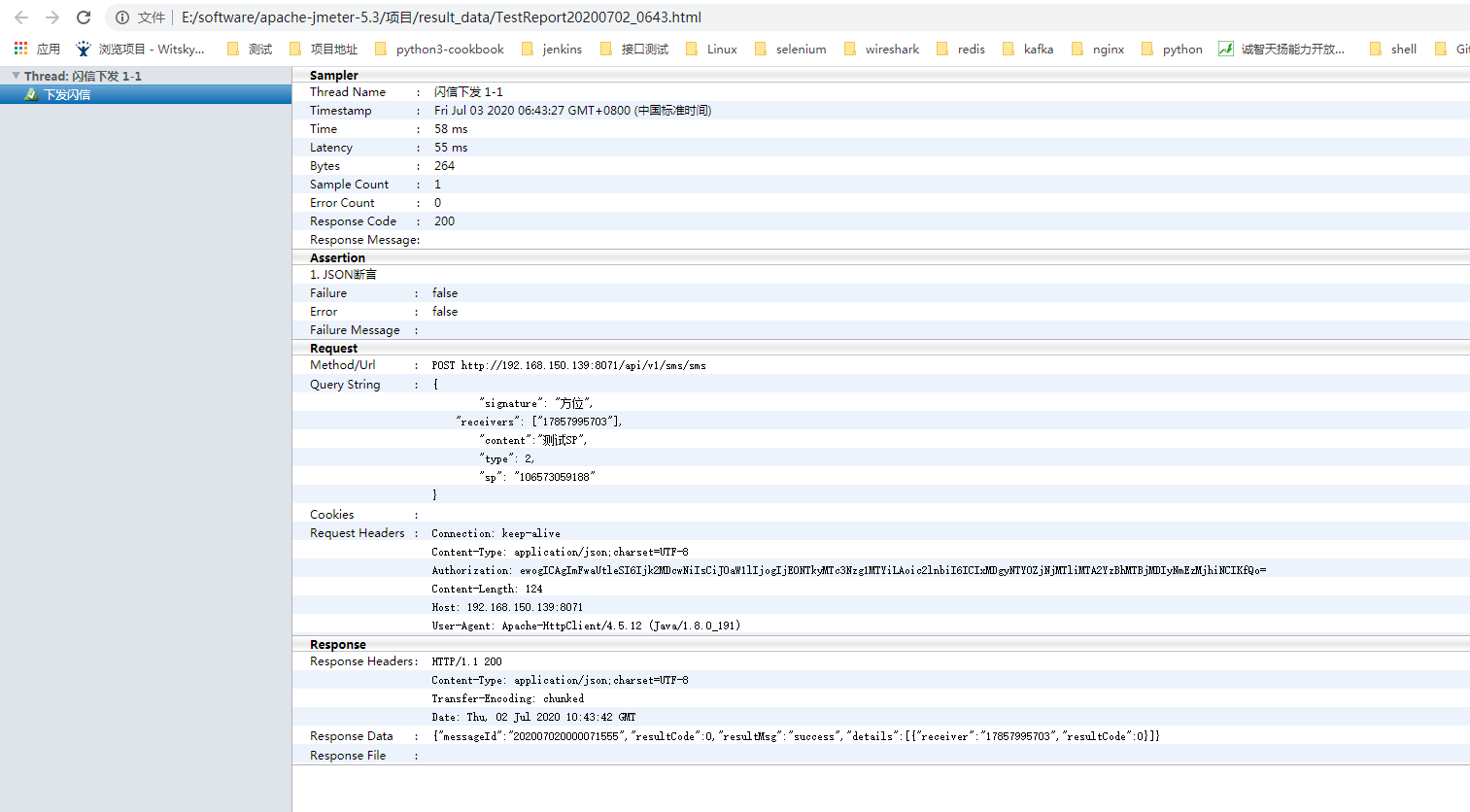
③、 ant调用jmeter脚本(通过jenkins)
1)系统设置——全局工具配置:ant
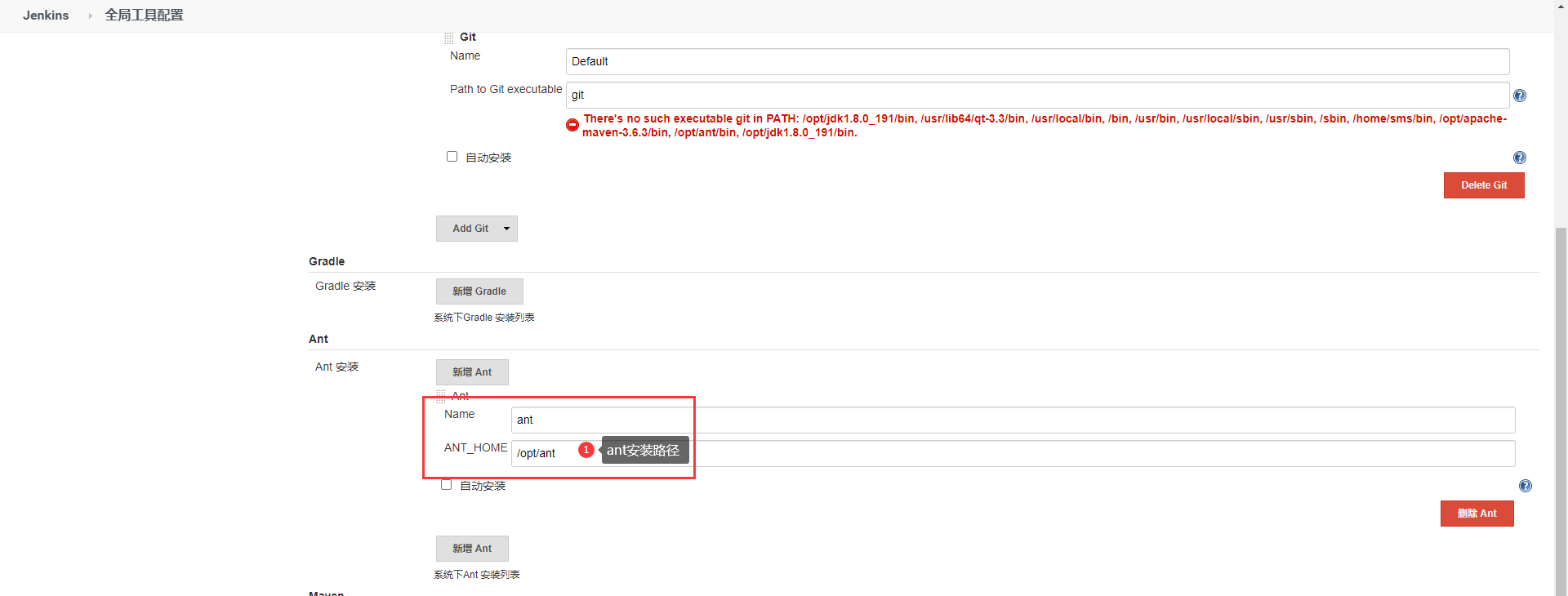
2)安装ant插件:

3)新建任务,配置
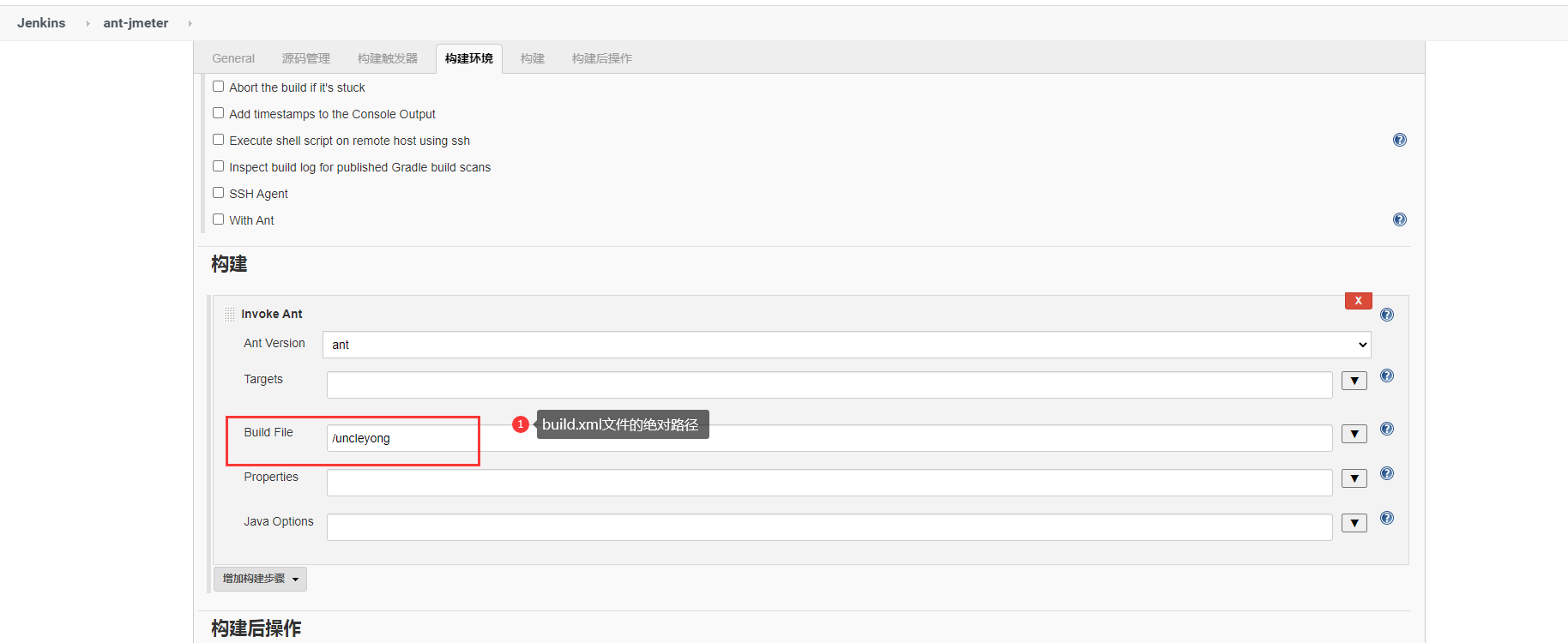
4)构建
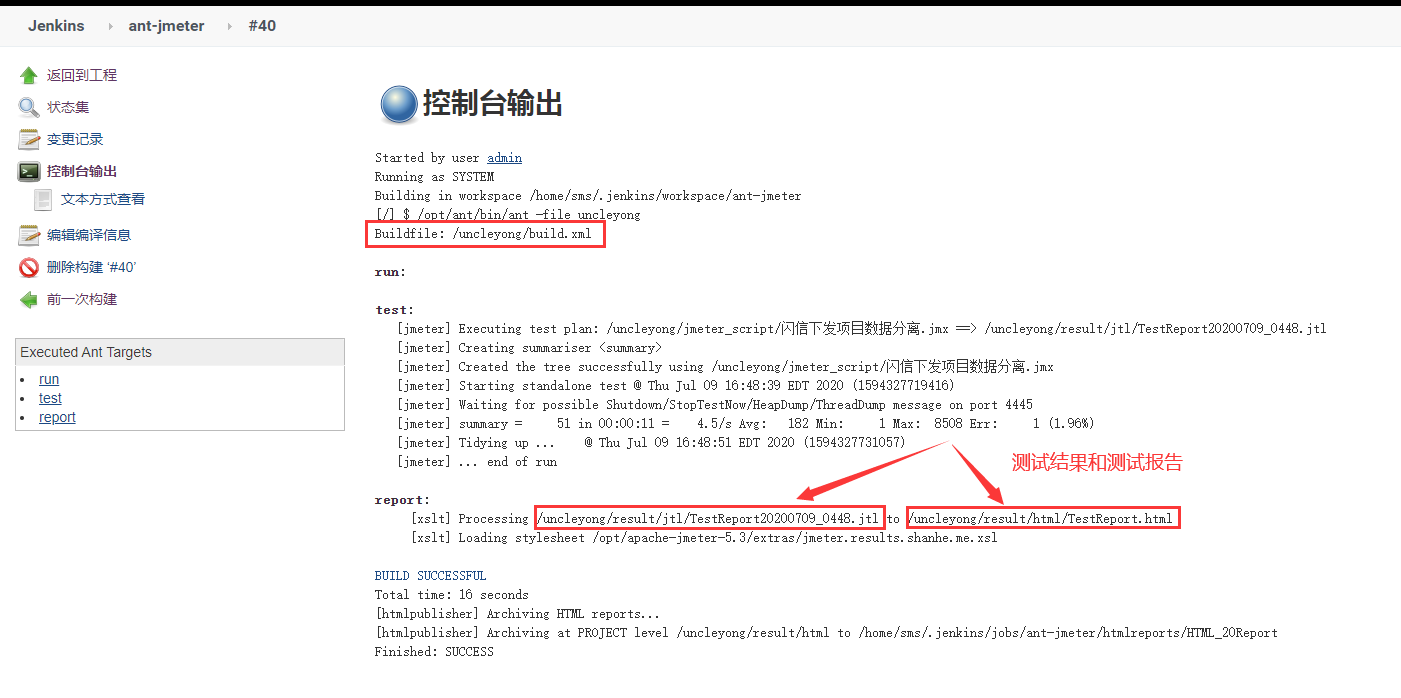
Jmeter脚本设计编写
主要思路:
通用配置:数据库连接,常用信息配到全局变量,
测试脚本:一个接口一个线程组一个csv测试数据文件一个邮件通知
测试数据:csv文件
断言:json断言(需要站我jsonPath语法)、beanshell断言(掌握java)、响应断言


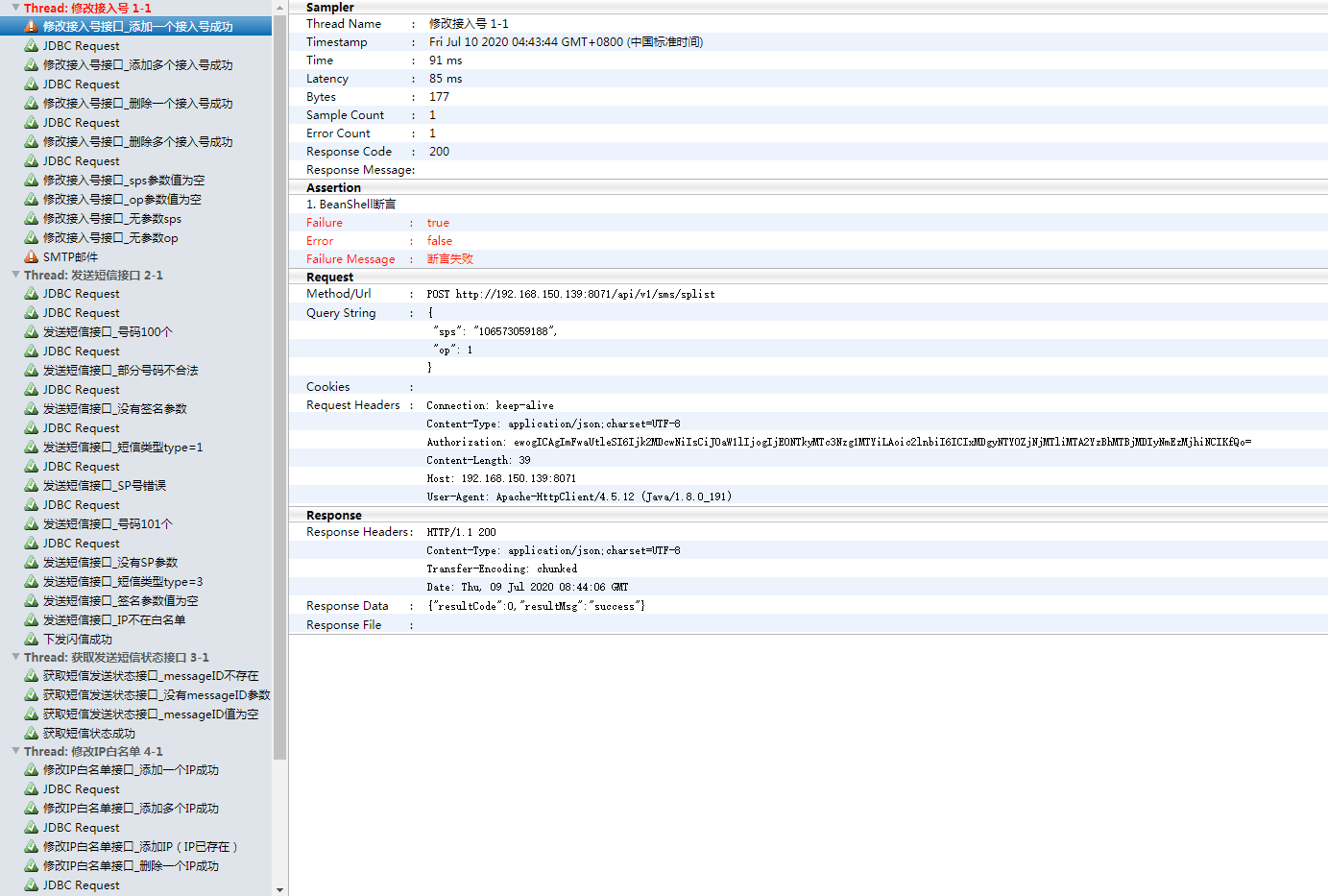
实践碰到的问题:
目前可见待优化问题和挑战:
框架优化:
1、邮件发送的实现
2、数据关联
项目:
1、接口文档变动及时通知

 浙公网安备 33010602011771号
浙公网安备 33010602011771号