Redis解读(4):Redis中HyperLongLog、布隆过滤器、限流、Geo、及Scan等进阶应用
Redis中的HyperLogLog
一般我们评估一个网站的访问量,有几个主要的参数:
- pv,Page View,网页的浏览量
- uv,User View,访问的用户
一般来说,pv 或者 uv 的统计,可以自己来做,也可以借助一些第三方的工具,比如 cnzz,友盟 等。
如果自己实现,pv 比较简单,可以直接通过 Redis 计数器就能实现。但是 uv 就不一样,uv 涉及到另外一个问题,去重。
我们首先需要在前端给每一个用户生成一个唯一 id,无论是登录用户还是未登录用户,都要有一个唯一 id,这个 id 伴随着请求一起到达后端,在后端我们通过 set 集合中的 sadd 命令来存储这个 id,最后通过 scard 统计集合大小,进而得出 uv 数据。
HyperLogLog 问题场景:
例如:CSDN、博客园这种网站首页,或者商城的爆款页面、活动页面。高峰时期都是千万级别的 UV,需要的存储空间就非常惊人,通过Redis中的 Set类型数据结构存储,并不是最佳的解决方案。而且,像 UV 统计这种,一般也不需要特别精确,对于网站服务商来说,800w 的 uv 和 803w 的 uv 数据,其实差别不大。所以,这个场景下,Redis中的 HyperLogLog 就能很好的去解决这个问题。
HyperLogLog 提供了一套不怎么精确但是够用的去重方案,会有误差,官方给出的误差数据是 0.81%,这个精确度,统计 UV 够用了。
HyperLogLog 主要提供了两个命令:pfadd 和 pfcount。
pfadd 用来添加记录,类似于 sadd ,添加过程中,重复的记录会自动去重。
pfcount 则用来统计数据。
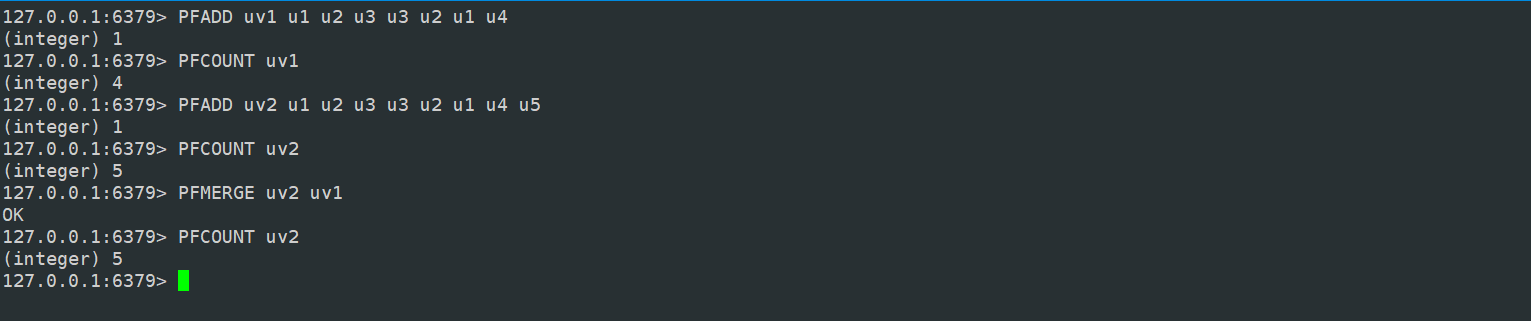
127.0.0.1:6379> pfadd uv u1 u2 u3
(integer) 1
127.0.0.1:6379> PFCOUNT uv
(integer) 3
127.0.0.1:6379> pfadd uv u1 u2 u3 u3 u2 u1 u4
(integer) 1
127.0.0.1:6379> PFCOUNT uv
(integer) 4
目前我们在服务器上统计UV 数据量少的时候看不出来误差。在 Java 中,我们多添加几个元素:
package org.taoguoguo.hyper;
import org.taoguoguo.redis.Redis;
/**
* @author taoguoguo
* @description HyperLogLog
* @website https://www.cnblogs.com/doondo
* @create 2021-04-18 14:10
*/
public class HyperLogLog {
public static void main(String[] args) {
Redis redis = new Redis();
redis.execute(jedis -> {
for (int i = 0; i < 1000; i++) {
//pfadd uv u0 u1
jedis.pfadd("uv","u"+i,"u"+(i+1));
}
long uv = jedis.pfcount("uv");
System.out.println("uv统计值为:" + uv);
});
}
}
控制台打印值:
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
uv统计值为:994
Process finished with exit code 0
理论值是 1001,实际打印出来 994,有误差,但是在可以接受的范围内。
除了 pfadd 和 pfcount 之外,还有一个命令 pfmerge ,合并多个统计结果,在合并的过程中,会自动 去重多个集合中重复的元素。
布隆过滤器
1.问题场景
我们用 HyperLogLog 来估计一个数,有偏差但是也够用。HyperLogLog 主要提供两个方法:
- pfadd
- pfcount
但是 HyperLogLog 没有判断是否包含的方法,例如 pfexists 、pfcontains 等。没有这样的方法存在,但是我们有这样的业务需求。
例如刷今日头条,推送的内容有相似的,但是没有重复的,如何将未推送过的内容进行去重推送?50亿个电话号码,清单中的200个已经拉入工信部黑名单,判断是否在这50亿电话号码中。此类场景如何进行过滤统计?
解决方案很多,例如将用户的浏览历史记录下来,然后每次推送时去比较该条消息是否已经给用户推送了。但是这种方式效率极低,不推荐。即便使用缓存,缓存数据量会特别多,效率也非常低,并不适合此类场景。
使用布隆过滤器,就能很好的解决这个问题。
2.Bloom Filter 介绍
Bloom Filter 专门用来解决我们上面所说的去重问题的,使用 Bloom Filter 不会像使用缓存那么浪费空间。当然,他也存在一个小小问题,就是不太精确。
Bloom Filter 相当于是一个不太精确的 set 集合,我们可以利用它里边的 contains 方法去判断某一个对象是否存在,但是需要注意,这个判断不是特别精确。一般来说,通过 contains 判断某个值不存在,那就一定不存在,但是判断某个值存在的话,则他可能不存在。
以今日头条为例,假设我们将用户的浏览记录用 B 表示,A 表示用户没有浏览的新闻,现在要给用户推送消息,先去 B 里边判断这条消息是否已经推送过,如果判断结果说没推送过(B 里边没有这条记录),那就一定没有推送过。如果判断结果说有推送(B 里边也有可能没有这条消息),这个时候该条消息就不会推送给用户,导致用户错过该条消息,当然这是概率极低的。
3.Bloom Filter 原理
每一个布隆过滤器,在 Redis 中都对应了一个大型的位数组以及几个不同的 hash 函数(无偏hash)。
所谓的 add 操作是这样的:首先根据几个不同的 hash 函数给元素进行 hash 运算一个整数索引值,拿到这个索引值之后,对位数
组的长度进行取模运算,得到一个位置,每一个 hash 函数都会得到一个位置,将位数组中对应的位置设置位 1 ,这样就完成了添加操作。
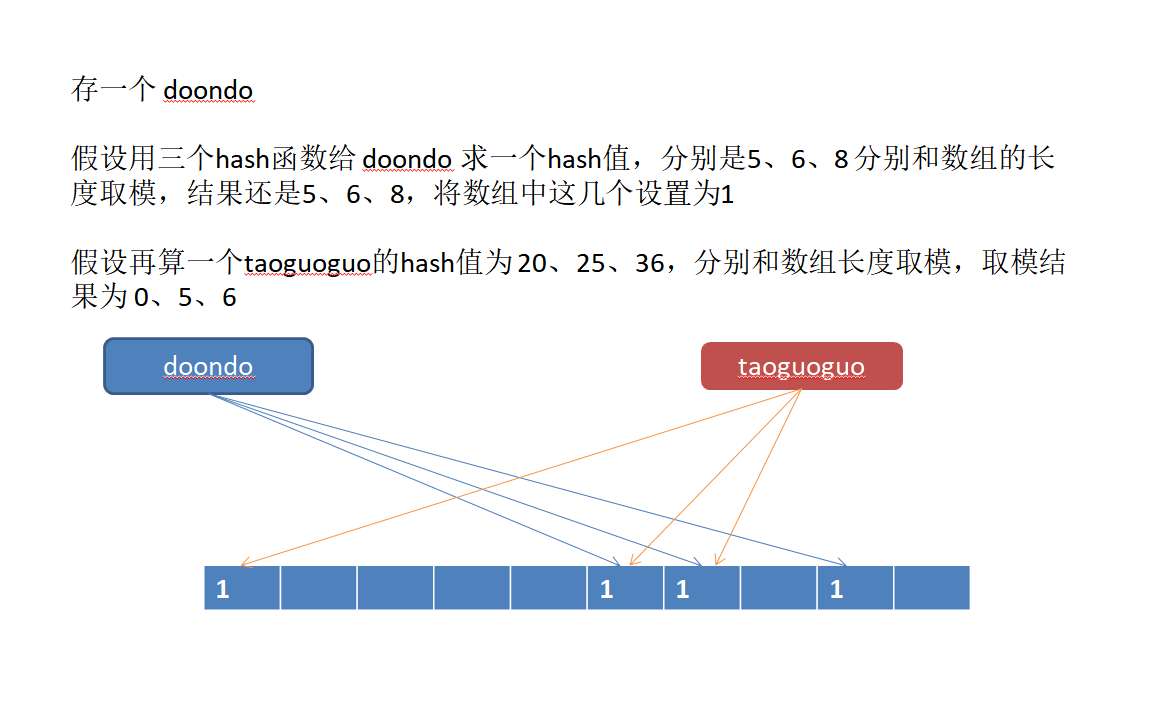
当判断元素是否粗存在时,依然先对元素进行 hash 运算,将运算的结果和位数组取模,然后去对应的
位置查看是否有相应的数据,如果有,表示元素可能存在(因为这个有数据的地方也可能是其他元素存
进来的),如果没有表示元素一定不存在。
Bloom Filter 中,误判的概率和位数组的大小有很大关系,位数组越大,误判概率越小,当然占用的存
储空间越大;位数组越小,误判概率越大,当然占用的存储空间就小。
4.Bloom Filter 安装
布隆过滤器插件官方网站:https://oss.redislabs.com/redisbloom/Quick_Start/
这边主要介绍三种安装方式
-
Docker,指定容器映射端口和别名启动
docker run -p 6379:6379 --name redis-redisbloom redislabs/rebloom:latest -
Git 克隆编译安装启动
cd redis-6.2.1 git clone https://github.com/RedisBloom/RedisBloom.git cd RedisBloom/ make cd .. redis-server redis.conf --loadmodule ./RedisBloom/redisbloom.so -
上传tar包,解压安装启动
cd redis-6.2.1 tar -zxvf RedisBloom-2.2.5.tar.gz mv ./RedisBloom-2.2.5 /home/redis-6.2.1/RedisBloom redis-server redis.conf --loadmodule ./RedisBloom/redisbloom.so
安装完成后,执行 bf.add 命令,测试安装是否成功。
每次启动时都输入 redis-server redis.conf --loadmodule ./RedisBloom/redisbloom.so 比较
麻烦,我们可以将要加载的模块在 redis.conf 中提前配置好。
################################## MODULES #####################################
# Load modules at startup. If the server is not able to load modules
# it will abort. It is possible to use multiple loadmodule directives.
#
# loadmodule /path/to/my_module.so
# loadmodule /path/to/other_module.so
loadmodule /root/redis-5.0.7/RedisBloom/redisbloom.so
最下面这一句,配置完成后,以后只需要 redis-server redis.conf 来启动 Redis 即可
5.基本用法
主要是两类命令,添加和判断是否存在。
- bf.add 添加
- bf.madd 批量添加
- bf.exists 判断是否存在
- bf.mexists 批量判断
#命令使用示例
127.0.0.1:6379> BF.ADD k1 v1
(integer) 1
127.0.0.1:6379> BF.EXISTS k1 v1
(integer) 1
127.0.0.1:6379> BF.EXISTS k1 v2
(integer) 0
127.0.0.1:6379> BF.MADD k1 v1 v2 v3 v4
1) (integer) 0
2) (integer) 1
3) (integer) 1
4) (integer) 1
127.0.0.1:6379> BF.MEXISTS k1 v1 v2 v3 v4 v5
1) (integer) 1
2) (integer) 1
3) (integer) 1
4) (integer) 1
5) (integer) 0
127.0.0.1:6379>
使用 Jedis 操作布隆过滤器,首先添加依赖:
<dependency>
<groupId>com.redislabs</groupId>
<artifactId>jrebloom</artifactId>
<version>1.2.0</version>
</dependency>
进行测试:
package org.taoguoguo.bloom;
import io.rebloom.client.Client;
import org.apache.commons.pool2.impl.GenericObjectPoolConfig;
import redis.clients.jedis.JedisPool;
/**
* @author taoguoguo
* @description BloomFilter
* @website https://www.cnblogs.com/doondo
* @create 2021-04-21 21:04
*/
public class BloomFilter {
public static void main(String[] args) {
GenericObjectPoolConfig config = new GenericObjectPoolConfig();
config.setMaxIdle(300);
config.setMaxTotal(1000);
config.setMaxWaitMillis(30000);
config.setTestOnBorrow(true);
JedisPool pool = new JedisPool(config, "192.168.124.5", 6379, 30000, "123456");
Client client = new Client(pool);
//存入数据
for (int i = 0; i < 100000; i++) {
client.add("name", "taoguoguo-"+ i );
}
//判断是否存在
boolean exists = client.exists("name", "taoguoguo-9");
System.out.println(exists);
}
}
控制台打印:
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
true
布隆过滤器 存在是有可能会误判断的,我们将判断数量加大,尝试执行多次,是会存在误判的。所以布隆过滤器判断不存在时一定准确,判断存在时不一定准确。
6.参数配置
默认情况下,我们使用的布隆过滤器它的错误率是 0.01 ,默认的元素大小是 100。但是这两个参数也
是可以配置的。
我们可以调用 bf.reserve 方法进行配置。
BF.RESERVE k1 0.0001 1000000
第一个参数是 key,第二个参数是错误率,错误率越低,占用的空间越大,第三个参数预计存储的数
量,当实际数量超出预计数量时,错误率会上升。
7.应用场景
-
之前说的新闻推送过滤、电话号码过滤是一个应用场景
-
缓存穿透问题,又叫缓存击穿问题。
假设我有 1亿 条用户数据,现在查询用户要去数据库中查,效率低而且数据库压力大,所以我们会把请
求首先在 Redis 中处理(活跃用户存在 Redis 中),Redis 中没有的用户,再去数据库中查询。现在可能会存在一种恶意请求,这个请求携带上了很多不存在的用户,这个时候 Redis 无法拦截下来请
求,所以请求会直接跑到数据库里去。这个时候,这些恶意请求会击穿我们的缓存,甚至数据库,进而
引起“雪崩效应”。为了解决这个问题,我们就可以使用布隆过滤器。将 1亿条用户数据存在 Redis 中不现实,但是可以存
在布隆过滤器中,请求来了,首先去判断数据是否存在,如果存在,再去数据库中查询,否则就不去数
据库中查询。
Redis限流
1.预备知识
Pipeline(管道)本质上是由客户端提供的一种操作。Pipeline 通过调整指令列表的读写顺序,可以大幅度的节省 IO 时间,提高效率。
怎么理解这个呢?假设A用户在客户端做写入缓存操作和读取缓存操作,B用户也在客户端做写入缓存操作和读取缓存操作。如果没有使用Piepline技术,那么A、B用户写操作和读操作一共需要使用4个网络来回。使用Pipeline进行指令调整,可以把写操作放入同一个网络来回进行写,读取操作放入同一个网络来回进行读取,大幅度节省网络IO,提高效率。
2.简单限流
简单限流思路其实很简单,就是在一个限流周期的时间窗口允许执行的操作次数,这边自己编写的一个代码如下,能达到基本的限流需求。
package org.taoguoguo.limit;
import org.taoguoguo.redis.Redis;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Pipeline;
import redis.clients.jedis.Response;
/**
* @author taoguoguo
* @description RateLimiter Redis简单限流
* @website https://www.cnblogs.com/doondo
* @create 2021-04-21 21:49
*/
public class RateLimiter {
private Jedis jedis;
public RateLimiter(Jedis jedis) {
this.jedis = jedis;
}
/**
* 限流方法
* @param user 操作用户,相当于限流的对象
* @param action 具体的操作
* @param period 时间戳 限流的周期
* @param maxCount 限流次数
* @return
*/
public boolean isAllowed(String user, String action, int period, int maxCount){
//1.首先生成一个key,数据用zset保存
String key = user + "-" + action;
//2.获取当前时间戳
long nowTime = System.currentTimeMillis();
//3.建立管道
Pipeline pipelined = jedis.pipelined();
//开启任务执行
pipelined.multi();
//4.将当前操作先存储下来
pipelined.zadd(key, nowTime, String.valueOf(nowTime));
//5.移除时间窗之外的数据 假设我要统计30S内的操作次数 先移除当前时间之前的统计时间周期内的操作次数
pipelined.zremrangeByScore(key, 0, nowTime- period * 1000);
//6.统计周期内剩下的key
Response<Long> response = pipelined.zcard(key);
//7.将当前key设置一个过期时间,过期时间就是时间窗
pipelined.expire(key, period+1);
//执行任务
pipelined.exec();
//关闭管道
pipelined.close();
return response.get() <= maxCount;
}
public static void main(String[] args) {
Redis redis = new Redis();
redis.execute(j -> {
RateLimiter rateLimiter = new RateLimiter(j);
for (int i = 0; i < 20; i++) {
boolean allowed = rateLimiter.isAllowed("taoguoguo", "addOrder", 5, 3);
System.out.println(allowed);
}
});
}
}
3.Redis-Cell 限流
Redis4.0 开始提供了一个 Redis-Cell 模块,这个模块使用漏斗算法,提供了一个非常好用的限流指令。
漏斗算法就像名字一样,是一个漏斗,请求从漏斗的大口进,然后从小口出进入到系统中,这样,无论
是多大的访问量,最终进入到系统中的请求,都是固定的。
使用漏斗算法,需要我们首先安装 Redis-Cell 模块:https://github.com/brandur/redis-cell
安装步骤
-
安装redis-cell插件
wget https://github.com/brandur/redis-cell/releases/download/v0.2.4/redis-cell- v0.2.4-x86_64-unknown-linux-gnu.tar.gz tar -zxvf redis-cell-v0.2.4-x86_64-unknown-linux-gnu.tar.gz mkdir redis-cell mv libredis_cell.d ./redis-cell mv libredis_cell.so ./redis-cell -
安装 GLIBC依赖,不装GLIBC可能会出现配置完成 reids-cell ,reids服务缺少依赖启动不成功。
// 下载 glibc 压缩包 wget http://ftp.gnu.org/gnu/glibc/glibc-2.18.tar.gz // 解压 glibc 压缩包 tar -zxvf glibc-2.18.tar.gz // 进入解压后的目录 cd glibc-2.18 // 创建编译目录 mkdir build // 进入到创建好的目录 cd build/ // 编译、安装 ../configure --prefix=/usr --disable-profile --enable-add-ons --with-headers=/usr/include --with-binutils=/usr/bin //这步会比较慢 make -j 8 make install接下来修改 redis.conf 文件,加载额外的模块
loadmodule /home/redis-6.2.1/redis-cell/libredis_cell.so然后,启动 Redis:
redis-server redis.confredis 启动成功后,如果存在 CL.THROTTLE 命令,说明 redis-cell 已经安装成功了。
CL.THROTTLE 命令使用
该命令一共有五个参数:
- 第一个参数是 key
- 第二个参数是漏斗的容量
- 时间窗内可以操作的次数
- 时间窗
- 每次漏出数量
执行完成后,返回值也有五个:
- 第一个 0 表示允许,1表示拒绝
- 第二个参数是漏斗的容量
- 第三个参数是漏斗的剩余空间
- 如果拒绝了,多长时间后,可以再试
- 多长时间后,漏斗会完全空出来
命令示例
127.0.0.1:6379> CL.THROTTLE taoguoguo-publish 10 10 60 1
1) (integer) 0
2) (integer) 11
3) (integer) 10
4) (integer) -1
5) (integer) 6
4.客户端Lettuce拓展
定义一个Redis命令拓展接口,可通过命令描述在客户端自由拓展Redis的命令
package org.taoguoguo;
import io.lettuce.core.dynamic.Commands;
import io.lettuce.core.dynamic.annotation.Command;
import java.util.List;
/**
* @author taoguoguo
* @description RedisCommandInterface Redis漏斗限流拓展接口
* @website https://www.cnblogs.com/doondo
* @create 2021-04-22 15:29
*/
public interface RedisCommandInterface extends Commands {
@Command("CL.THROTTLE ?0 ?1 ?2 ?3 ?4")
List<Object> throttle(String key, long init, long count, Long period, Long quota);
}
命令调用
package org.taoguoguo;
import io.lettuce.core.RedisClient;
import io.lettuce.core.api.StatefulRedisConnection;
import io.lettuce.core.dynamic.RedisCommandFactory;
import java.util.List;
/**
* @author taoguoguo
* @description ThrottleTest
* @website https://www.cnblogs.com/doondo
* @create 2021-04-22 15:32
*/
public class ThrottleTest {
public static void main(String[] args) {
RedisClient redisClient = RedisClient.create("redis://123456@172.20.10.2");
StatefulRedisConnection<String, String> connect = redisClient.connect();
RedisCommandFactory factory = new RedisCommandFactory(connect);
RedisCommandInterface commands = factory.getCommands(RedisCommandInterface.class);
List<Object> list = commands.throttle("taoguoguo", 10L, 10L, 60L, 1L);
System.out.println(list);
}
}
Redis Geo
Redis3.2 开始提供了 GEO 模块。该模块也使用了 GeoHash 算法
1.Geo Hash算法
核心思想:GeoHash 是一种地址编码方法,使用这种方式,能够将二维的空间经纬度数据编码成一个一维字符串。
地球上经纬度的划分:以经过伦敦格林尼治天文台旧址的经线为 0 度经线,向东就是东经,向西就是西经。如果我们将西经定
义负,经度的范围就是 [-180,180]。纬度北纬 90 度到南纬 90 度,如果我们将南纬定义负,则纬度的范围就是 [-90,90]。
接下来,以本初子午线和赤道为界,我们可以将地球上的点分配到一个二维坐标中:
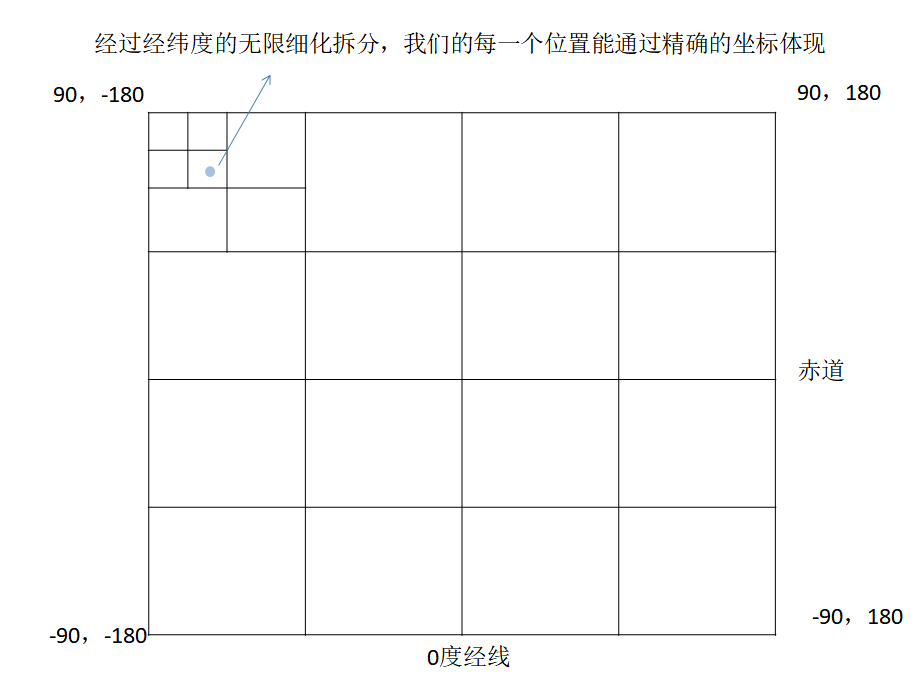
GeoHash 算法就是基于这样的思想,划分的次数越多,区域越多,每个区域中的面积就更小了,精确度就会提高。
GeoHash 具体算法:
以北京天安门广场为例(39.9053908600,116.3980007200)
- 纬度的范围在 (-90,90) 之间,中间值为 0,对于 39.9053908600 值落在 (0,90),因此得到的值为 1
- (0,90) 的中间值为 45,39.9053908600 落在 (0,45) 之间,因此得到一个 0
- (0,45) 的中间值为 22.5,39.9053908600 落在 (22.5,45)之间,因此得到一个 1
- ......
这样,我们得到的纬度二进制是 101,按照同样的步骤,我们可以算出来经度的二进制是 110
接下来将经纬度合并(经度占偶数位,纬度占奇数位):111001
按照 Base32 (0-9,b-z,去掉 a i l 0)对合并后的二进制数据进行编码,编码的时候,先将二进制转换为
十进制,然后进行编码。
将编码得到的字符串,可以拿去 geohash.org 网站上解析
GeoHash 有哪些特点:
- 用一个字符串表示经纬度
- GeoHash 表示的是一个区域,而不是一个点
- 编码格式有规律,例如一个地址编码之后的格式是 123,另一个地址编码之后的格式是 123456,从字符串上就可以看出来,123456 处于 123 之中。
2.Redis 中的使用
经纬度查询网站:http://www.gpsspg.com/maps.htm
添加地址:
GEOADD city 116.3980007200 39.9053908600 beijing
GEOADD city 114.0592002900 22.5536230800 shenzhen
查看两个地址之间的距离:
127.0.0.1:6379> GEODIST city beijing shenzhen km
"1942.5435"
获取元素的位置:
127.0.0.1:6379> GEOPOS city beijing
1) 1) "116.39800339937210083"
2) "39.90539144357683909"
获取元素 hash 值:
127.0.0.1:6379> GEOHASH city beijing
1) "wx4g08w3y00"
通过 hash 值可以查看定位。http://geohash.org/wx4g08w3y00
查看附近的人:
127.0.0.1:6379> GEORADIUSBYMEMBER city beijing 200 km count 3 asc
1) "beijing"
以北京为中心,方圆 200km 以内的城市找出来 3 个,按照远近顺序排列,这个命令不会排除 北京。
当然,也可以根据经纬度来查询(将 member 换成对应的经纬度):
127.0.0.1:6379> GEORADIUS city 116.3980007200 39.9053908600 2000 km withdist
withhash withcoord count 4 desc
Redis Scan
1.简单介绍
scan 实际上是 keys 的一个升级版。
可以用 keys 来查询 key,在查询的过程中,可以使用通配符。keys 虽然用着还算方便,但是没有分页功能。同时因为 Redis 是单线程,所以 key 的执行会比较消耗时间,特别是当数据量大的时候,影响整个程序的运行。
为了解决 keys 存在的问题,从 Redis2.8 中开始,引入了 scan。
scan 具备 keys 的功能,但是不会阻塞线程,而且可以控制每次返回的结果数。
2.基本用法
首先准备 10000 条测试数据:
package org.taoguoguo.scan;
import org.taoguoguo.redis.Redis;
/**
* @author taoguoguo
* @description ScanTest
* @website https://www.cnblogs.com/doondo
* @create 2021-04-25 14:27
*/
public class ScanTest {
public static void main(String[] args) {
Redis redis = new Redis();
redis.execute(jedis -> {
for (int i = 0; i < 10000; i++) {
jedis.set("k" + i, "v" + i);
}
});
}
}
scan 命令一共提供了三个参数,第一个 cursor,第二个参数是 key,第三个参数是 limit。
cursor 实际上是指一维数组的位置索引,limit 则是遍历的一维数组个数(所以每次返回的数据大小可能不确定)。
scan 0 match k8* count 1000
3.遍历原理及渐进式 rehash机制
SCAN的遍历顺序
假设目前有三条数据:
127.0.0.1:6379> keys *
1) "key1"
2) "db_number"
3) "myKey"
127.0.0.1:6379> scan 0 match * count 1
1) "2"
2) 1) "key1"
127.0.0.1:6379> scan 2 match * count 1
1) "1"
2) 1) "myKey"
127.0.0.1:6379> scan 1 match * count 1
1) "3"
2) 1) "db_number"
127.0.0.1:6379> scan 3 match * count 1
1) "0"
2) (empty list or set)
127.0.0.1:6379>
在遍历的过程中,大家发现游标的顺序是 0 2 1 3,从十进制来看好像没有规律,但是从转为二进制,则是有规律的:
00->10->01->11
这种规律就是高位进1,传统的二进制加法,是从右往左加,这里是从左往右加。
实际上,在 Redis 中,它的具体计算流程给是这样:
- 将要计算的数字反转
- 给反转后的数字加 1
- 再反转
那么为什么不是按照 0、1、2、3、4...这样的顺序遍历呢?因为主要考虑到两个问题:
- 字典扩容
- 字典缩容
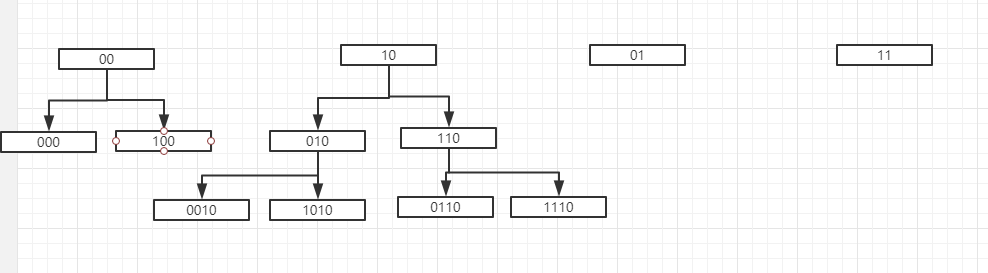
根据Scan遍历原理假如我们将要访问 110 时,发生了扩容,此时 scan 就会从 0110 开始遍历,之前已经被遍历过的元素就不会被重复遍历了
假如我们将要访问 110 时,发生缩容,此时 scan 就会从 10 开始遍历,这个时候,也会遍历到 010,但是 010 之前的不会再被遍历了。所以,在发生缩容的时候,可能返回重复的元素。
Redis一共支持5种数据结构,hash是其中的一种,在hash扩容的时候采用的是渐进式rehash的方式。要想深入理解渐进式rehash,首先要了解以下Redis中hash的数据结构。 哈希表节点 typedef struct...
哈希表节点
typedef struct dictEntry {
void *key; // 键
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v; // 值
struct dictEntry *next; // 下一个节点
} dictEntry;
哈希表
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table; // 哈希表数组
unsigned long size; // 哈希表大小
unsigned long sizemask; // 掩码,计算索引值,size-1
unsigned long used; // 哈希表已有节点的数量
} dictht;
字典
typedef struct dict {
dictType *type; // 类型特定函数
void *privdata; // 私有数据
dictht ht[2]; // 哈希表
// rehash索引
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
特定函数
typedef struct dictType {
// 计算哈希值的函数
uint64_t (*hashFunction)(const void *key);
// 复制键的函数
void *(*keyDup)(void *privdata, const void *key);
// 复制值的函数
void *(*valDup)(void *privdata, const void *obj);
// 对比键的函数
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
// 销毁键的函数
void (*keyDestructor)(void *privdata, void *key);
// 销毁值的函数
void (*valDestructor)(void *privdata, void *obj);
} dictType;
字典中包含一个数据结构dictht的ht数组,一般情况下字典只是用ht[0]用来存储数据,ht[1]在rehash时使用。
哈希算法原理
当向字典中添加一个元素时(假设此时 rehashidx = -1,也就是没有进行rehash),首先通过dict->type->hashFunction计算该元素的hash值,然后通过hash & dict->ht[x].sizemask计算哈希地址index。如果该元素对应的下标没有数据,则直接添加,否则采用链地址法添加到hash对应index元素的链表尾部。
rehash原理
随着操作的不断执行,哈希表中的元素会逐渐增加或者减少,为了让哈希表的负载因子维持在一个合理的范围内,程序需要对哈希表的大小进行相应的扩容和收缩。步骤如下:
- 为
ht[1]哈希表分配空间。如果是扩容操作,ht[1]的大小为第一个大于等于ht[0].used*2的2的n次方幂,如果是收缩操作,ht[1]的大小为第一个大于等于ht[0].used的2的n次方幂 - 将保存在
ht[0]中的所有键值对rehash到ht[1]:rehash指的是重新计算键的哈希值和索引值,然后将键值对放到ht[1]对应位置上 - 当
ht[0]包含的所有键值对都迁移到ht[1]之后,释放ht[0],将ht[1]设置为ht[0],并在ht[1]新创建一个空白哈希表,为下一次rehash做准备
渐进式rehash原理
在扩容和收缩的时候,如果哈希字典中有很多元素,一次性将这些键全部rehash到ht[1]的话,可能会导致服务器在一段时间内停止服务。所以,采用渐进式rehash的方式,详细步骤如下:
- 为
ht[1]分配空间,让字典同时持有ht[0]和ht[1]两个哈希表 - 将
rehashindex的值设置为0,表示rehash工作正式开始 - 在rehash期间,每次对字典执行增删改查操作是,程序除了执行指定的操作以外,还会顺带将
ht[0]哈希表在rehashindex索引上的所有键值对rehash到ht[1],当rehash工作完成以后,rehashindex的值+1 - 随着字典操作的不断执行,最终会在某一时间段上
ht[0]的所有键值对都会被rehash到ht[1],这时将rehashindex的值设置为-1,表示rehash操作结束
渐进式rehash采用的是一种分而治之的方式,将rehash的操作分摊在每一个的访问中,避免集中式rehash而带来的庞大计算量。
需要注意的是在渐进式rehash的过程,如果有增删改查操作时,如果index大于rehashindex,访问ht[0],否则访问ht[1]
4.Scan其他指令
scan 是一系列的指令,除了遍历所有的 key 之外,也可以遍历某一个类型的 key,对应的命令有:
- zscan-->zset
- hscan-->hash
- sscan-->set

 浙公网安备 33010602011771号
浙公网安备 33010602011771号