自研Web漏洞扫描器后的几点思考
 本文主要记录我在Web漏洞扫描器实践过程中的一些思考,篇幅较长,没有图片,都是文字性叙述,大多结论、论述来自自己的思考、近些年的所见所闻、朋友的交流等,肯定有很多不全面、错误的地方,欢迎指教与交流。
本文主要记录我在Web漏洞扫描器实践过程中的一些思考,篇幅较长,没有图片,都是文字性叙述,大多结论、论述来自自己的思考、近些年的所见所闻、朋友的交流等,肯定有很多不全面、错误的地方,欢迎指教与交流。
0x00 前言
本文主要记录我在Web漏洞扫描器实践过程中的一些思考,篇幅较长,没有图片,都是文字性叙述,大多结论、论述来自自己的思考、近些年的所见所闻、朋友的交流等,肯定有很多不全面、错误的地方,欢迎指教与交流。
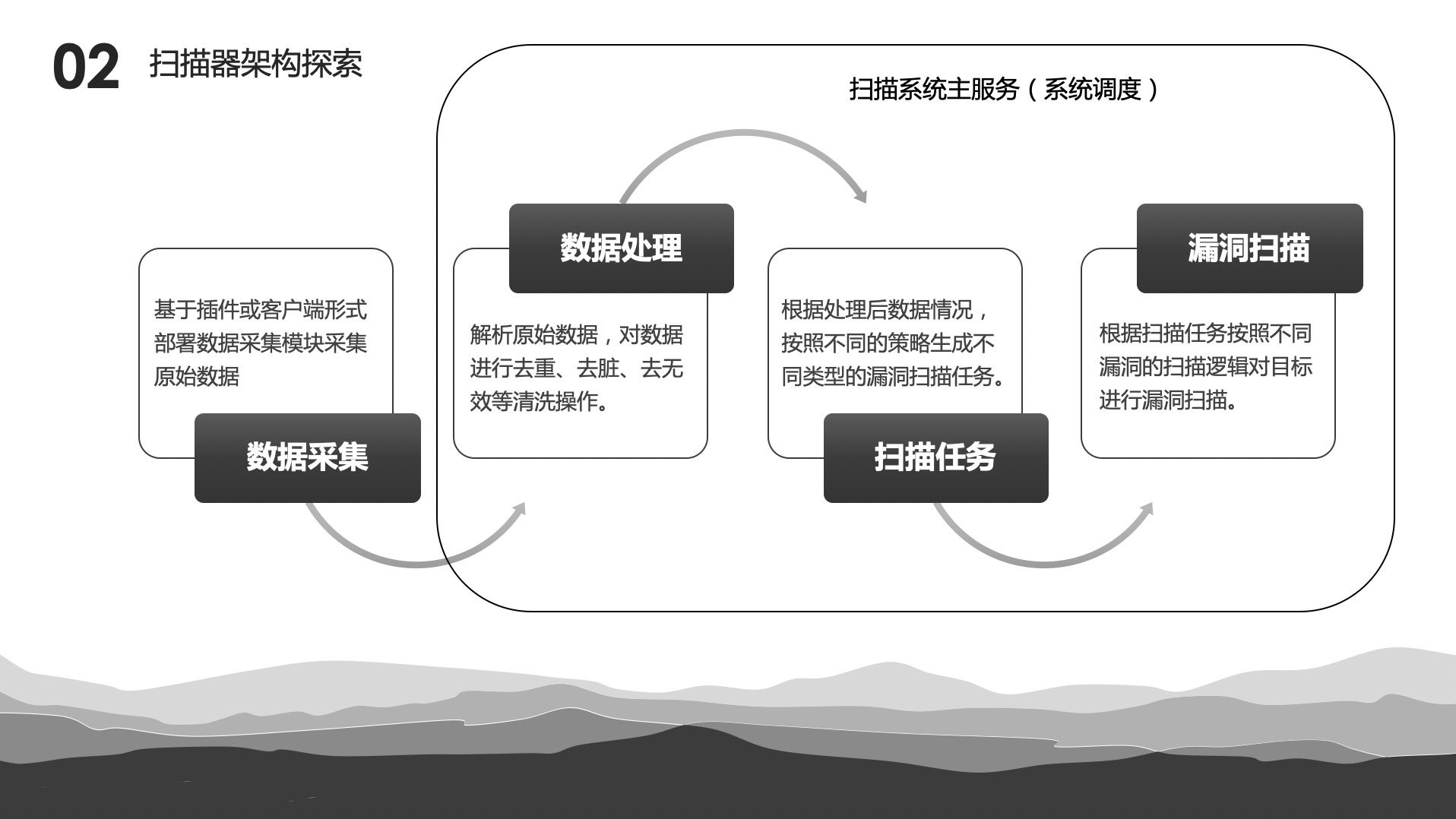
0x01 数据采集
在我的毕业设计项目《半自动化Web漏洞扫描器系统设计与实现》中我将数据处理分为两种,一种为主动,即扫描器主动获取原始数据,获取数据是扫描器的功能之一;一种为被动方式,即通过第三方或其他数据采集设备、软件提供原始数据,最原始数据采集功能不属于扫描器的一部分。
两种模式主要包含如下几种数据源。
模式/数据源主动被动1爬虫流量2系统代理前端日志3浏览器代理后端日志4浏览器插件
上表粗糙的概括了几种数据源,其中被动模式流量可以通过多种方式进行采集,比如流量分析系统、基于网络的入侵检测系统、核心交换机流量镜像等方式,通过流量的方式存在的一个问题是对HTTPS加密数据的处理上,可以通过统一证书管理或统一HTTPS代理入口后采集等方式解决。
前端日志通过在前端页面插入js的方式,通过js获取有限的访问日志,后端日志有很多种,包括可以通过反向代理中间件、WAF等系统获取数据。
而主动模式,爬虫因为其本身的局限性以及目前前端技术的发展导致一定会产生误报,而代理插件等模式,不能实现完全的自动化扫描,需要结合人工,对于扫描器产品提供商爬虫+请求采集的模式,即使用Headless浏览器进行页面爬取通过Headless浏览器接口或插件或代理等方式采集请求或许是目前能够最有效的数据获取的方式。
不管怎么说,最大的问题还是触发页面ajax请求!
因此笔者在进行扫描器设计的过程中,因为不能有效的解决爬虫问题,采用了浏览器插件的方式进行数据采集,但是Chrome浏览器目前提供的接口存在一定的局限性,以及其他的一些细节问题,完全可以再写一篇文章了,因此本文不再详细说明。
0x02 数据处理
如果说数据采集这个问题还不算是一个非常大的问题的话,那么数据处理一定是一个非常令人头疼的问题。我定义的扫描器数据处理包括两个部分,一个是数据解析,一个是数据清洗。数据解析即将原始的一个请求,比如从流量中获取HTTP报文,也即HTTP
Header+HTTP
Body,将各种不同类型的请求转化为代码,以方便在扫描模块中进行扫描,并能够根据不同的HTTP数据格式进行更加精细化的漏洞扫描,如fastjson反序列化、XML实体注入等。
目前针对这个问题的公开文章并不多(几乎没有),我推测各类扫描器的数据解析也大多是非常粗糙的,很难做到非常精细化的数据解析,我在进行相关处理的过程中,还是采用了中规中矩的方式,先通过Content-type获取一个格式然后进行解析,解析失败的再通过模糊数据解析正则进行识别。相关的代码可以参考SQLMAP
-r参数下数据解析。
数据解析的另外一个问题是key-value情况下,value的复杂格式问题,比如加密、base64、url编码等等。关于这个东西我也没有很好的解决方案,只进行了比较有限的数据处理。
数据清洗是在漏洞扫描系统的设计实现过程中减少系统负载等一个重要的问题,主要包括去除静态、去除完全重复数据、去除语义重复数据等工作。我在进行扫描器设计实现过程中,改进了seay法师曾经提出的一周根据url生成key,通过key进行去重的方案,独创(嘻嘻)多级去重方案,根据一个请求的不通部分生成多级去重key,将去重key保存在数据库中,当获取新的请求数据后,计算出多级去重key,查询数据库,以查不出则不重复为首要原则实施去重方案,效果还行==
0x03 系统架构
安全人员不是专业的开发人员,很少具备架构设计能力,虽然说这种专业的事情应当交给专业的人去做,但是迫于团队人员有限,往往许多安全团队不具备非常专业的开发人员。在扫描器系统的架构设计上目前流行于市面上的是python
celery框架结合Redis/RabbitMQ做成任务分发队列,celery的核心是将大量的任务分发到不同的节点上执行。完全的抽象了对Redis/RabbitMQ等消息中间件的代码,当我在做我的扫描器的过程中,我发现直接与Redis/RabbitMQ进行交互没有想象中的那么复杂,做一个生产者消费者模型基本上已经满足了扫描器的任务队列需求,多节点的任务分发也只是多个消费者而已。并且可以灵活的通过消息队列传递不通类型的消息。
扫描器应当具备的一个核心系统能力是任务队列,因为扫描任务不可能瞬间完成,系统会存在大量的等待任务;系统的第二个能力是不同模块间的协调,不通模块间的消息传递,也即消息队列;系统的第三个高端一点的能力是根据系统负载进行灵活的调度,能实时分析整个系统当前的负载状态。
在我的扫描器实践过程中,消息队列和任务队列被弱化成一回事,一个RabbitMQ队列对数据处理模块来说是消息队列,对扫描模块来说又是一个扫描任务,曾经看到有人的任务队列使用Mysql数据库存储,定时查询数据库获取任务,我不是很理解这样设计的原有,可能是考虑任务本身包含了数据比较多不方便通过RabitMQ等消息中间件传递?但是也可以通过只传递主键,具体数据存储在数据库,消费者拿到主键后查询数据库获取数据的方式解决。
对于系统负载灵活调度的能力方面,我做的就比较粗糙,单纯的在系统主进程中定时根据当前系统等待任务量和各个模块进程数量,增加和降低模块进程量。
0x04 速率控制
扫描速率控制在甲方扫描器建设中应当是一个非常重要的功能,为了避免对业务的影响,扫描器在发包过程中需要支持扫描速率控制,也即QPS,每秒发包量。由于我在实践过程中并没有加入扫描器速率控制这一功能,但是我自己也在考虑加入速率控制,我思考的两种方法QPS的控制方法,在扫描器系统可以通过两个环节来实现,一个是扫描任务生成时控制任务生成速率从而实现控制QPS,一个是将请求构造与请求发送分离,在请求发送时控制QPS。
QPS控制的粒度是域名或IP,速率控制是一个非常精细化的功能,但是又很难做到真正的非常精细化的秒级控制,企业级扫描器数据源与扫描分离,即扫描需要的数据不受数据增量的影响或影响较小,当数据源不影响扫描的情况下,扫描数据解析、处理后进行任务分发,扫描插件生成请求并发送请求判断漏洞或扫描插件仅生成请求,单独的请求发送模块发送请求,请求生成和请求发送分离意味着根据响应信息的漏洞识别工作将更加复杂,需要将请求与具体的漏洞扫描任务关联,通过回调或存储的方式通知漏洞判断逻辑进行漏洞识别。通过任务生成的速率控制需要结合已生成任务量、任务完成速率、单一任务发包量等情况综合调控,太复杂来!
0x05 漏洞扫描
漏洞扫描是扫描器建设后续需要持续维护的一个部分,是安全策略工作的核心,目前扫描器大多将平台与
策略分离,扫描器运营工作划分更加明确,策略专心搞策略,开发专心搞开发,扫描模块直接与扫描任务挂钩,扫描任务主要用于系统调控、并发扫描等能力,扫描任务的实现有很多方式,比如进程、线程,以及更加轻量的协程。
衡量漏洞扫描效果的几个指标:漏报率、误报率、平均发包量、漏洞覆盖率等,漏洞扫描逻辑是一个很细节的工作,细节到payload的合并,payload的先后顺序等,扫描逻辑的建设往往需要一个非常专业的安全团队来进行,也不是一天两天即可完成,当然,目前开源与被开源的扫描器中有很多扫描逻辑可以来借鉴,比如sqlmap中盲注扫描、awvs部分漏洞扫描策略等,而针对某些已知组件、框架漏洞,则相对于通用漏洞要简单许多。
0x06 总结
扫描是一种攻击行为,通过不断模拟人的攻击路径,贴近真实的攻击方式,来让扫描发挥出更好的效果,用代码重塑攻击者的视角,将人所具备的安全能力融入进扫描器,实现扫描过程的全面化、平台化、动态化的目标。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号