MySql 常用语法
1 #开启关闭服务 2 #管理员启动cmd,,net start/stop mysql,, 3 #登录数据库,,mysql 【-h localhost -P 端口号】 -u 用户名 -p,, 4 #退出数据库,,exit,, / #ctrl+c 5 #查看版本号,,mysql -V,, 6 ##常见语句 7 #查看当前所有数据库 8 SHOW DATABASES; 9 #打开指定的库,,use 库名; 10 #查看某库所有的表,,show tables; // show tables from 库名; 11 /*创建表,, create table( 12 字段名称 字段类型, 13 字段名称 字段类型 14 );*/ 15 #查看表结构,,desc 表名; 16 #修改字符集 set names gbk; 17 #查看表内容,,select * from 表名; 18 #插入内容,,insert into 表名 (id , name) values (1,‘yangbo’); 19 #更新修改内容,,update 表名 set name='yb' where id=1; 20 #删除内容,,delete from 表名 where id=1;
执行顺序:

单行函数 做处理使用
如 CONCAT(str1,str2,...) LENGTH(str) IFNULL(expr1,expr2)
分组函数 做统计使用,又成为统计函数/聚合函数
-- 字符函数
1.LENGTH(str)
2.CONCAT(str1,str2,...)
3.UPPER(str)/LOWER(str)
4.SUBSTR(str FROM pos FOR len) 索引从1 开始
5. INSTR(str,substr) 返回substr在str的起始索引
6.TRIM([remstr FROM] str)/LTRIM(str)/RTRIM(str) SELECT TRIM('a' FROM 'aaaaaaLOVEaaaaaa') as out_put;
7.LPAD(str,len,padstr)/RPAD(str,len,padstr) 用指定字符实现左/右填充至指定长度字符串 SELECT LPAD('LOVE',10,'*') AS out_put;
8.REPLACE 替换 SELECT REPLACE('张无忌爱上了周芷若','周芷若','赵敏') AS out_put;
---数学函数
1.ROUND(X) 四舍五入
2.CEIL(X) 向上取整
3.FLOOR(X) 向下取整
4.TRUNCATE(X,D) 截断 SELECT TRUNCATE(1.678888,1);
5.MOD(N,M) 取模 SELECT MOD(10,3)
--日期函数
1.NOW() 返回当前系统日期,不包含时间 SELECT YEAR(NOW()) out_put;
2.CURDATE() 返回当前系统日期,不包含时间
3.CURTIME() 返回当前时间,不包含日期
4.STR_TO_DATE(str,format) 合法的字符串转换为日期 SELECT STR_TO_DATE('1991-07-06','%Y-%m-%d');
5.DATE_FORMAT(date,format) 将日期输出为指定格式 SELECT DATE_FORMAT(NOW(),'%Y年/%m月/%d日') out_put;
--流程控制函数
1.IF 函数 if...else效果 SELECT last_name,commission_pct,IF(commission_pct IS NULL,'No bonus',commission_pct) AS bonus_status
FROM employees;
2.CASE 函数 switch..case效果
使用一:
SELECT salary,department_id,
CASE department_id
WHEN 30 THEN
salary* 1.1
WHEN 40 THEN
salary * 1.2
WHEN 50 THEN
salary *1.3
ELSE
salary
END AS new_salary
FROM employees;
使用二:类似于多重if
CASE
WHEN 条件1 THEN 要显示的值或语句1
WHEN 条件2 THEN 要显示的值或语句2
...
ELSE 要显示的值或语句n
END
SELECT last_name, salary,
CASE
WHEN salary>20000 THEN
'A'
WHEN salary>15000 THEN
'B'
WHEN salary>10000 THEN
'C'
ELSE
'D'
END AS salary_class
FROM employees;
SELECT salary,department_id, CASE department_id WHEN 30 THEN salary* 1.1 WHEN 40 THEN salary * 1.2 WHEN 50 THEN salary *1.3 ELSE salary END AS new_salary FROM employees;
SELECT last_name, salary, CASE WHEN salary>20000 THEN 'A' WHEN salary>15000 THEN 'B' WHEN salary>10000 THEN 'C' ELSE 'D' END AS salary_class FROM employees;
--自连接
SELECT e.last_name,e.employee_id,m.employee_id,m.last_name FROM employees e, employees m WHERE e.manager_id = m.employee_id;
sql99语法
语法:
SELECT 查询列表
FROM 表1 别名【连接类型】
JOIN 表2 别名 ON 连接条件
【WHERE 筛选条件】
【GROUP BY 分组】
【HAVING 筛选类型】
【ORDER BY 排序列表】
分类:
内连接:INNER
语法:
SELECT 查询表名
FROM 表1 别名
INNER JOIN 表2 别名
ON 连接条件;
分类:等值连接,非等值连接,自连接
等值连接:
SELECT last_name,department_name FROM employees e INNER JOIN departments d ON e.department_id = d.department_id; SELECT last_name,job_title FROM employees e INNER JOIN jobs j ON e.job_id = j.job_id WHERE last_name LIKE '%e%'; SELECT city, COUNT(*) FROM locations l INNER JOIN departments d ON l.location_id = d.location_id GROUP BY city HAVING COUNT(*) > 3; SELECT department_name,COUNT(*) FROM departments d INNER JOIN employees e ON d.department_id = e.department_id GROUP BY department_name HAVING COUNT(*) >= 3 ORDER BY COUNT(*) DESC; SELECT e.last_name,d.department_name,j.job_title FROM employees e INNER JOIN departments d ON e.department_id = d.department_id INNER JOIN jobs j ON e.job_id = j.job_id ORDER BY department_name DESC;
非等值连接:
SELECT e.last_name,e.salary,j.grade_level FROM employees e INNER JOIN job_grades j ON salary BETWEEN lowest_sal AND heighest_sal;
SELECT j.grade_level,COUNT(*) FROM employees e INNER JOIN job_grades j ON e.salary BETWEEN j.lowest_sal AND j.heighest_sal GROUP BY j.grade_level ORDER BY j.grade_level DESC;
自连接
SELECT e.last_name,m.last_name FROM employees e INNER JOIN employees m ON e.manager_id = m.employee_id WHERE e.last_name LIKE '%a%';
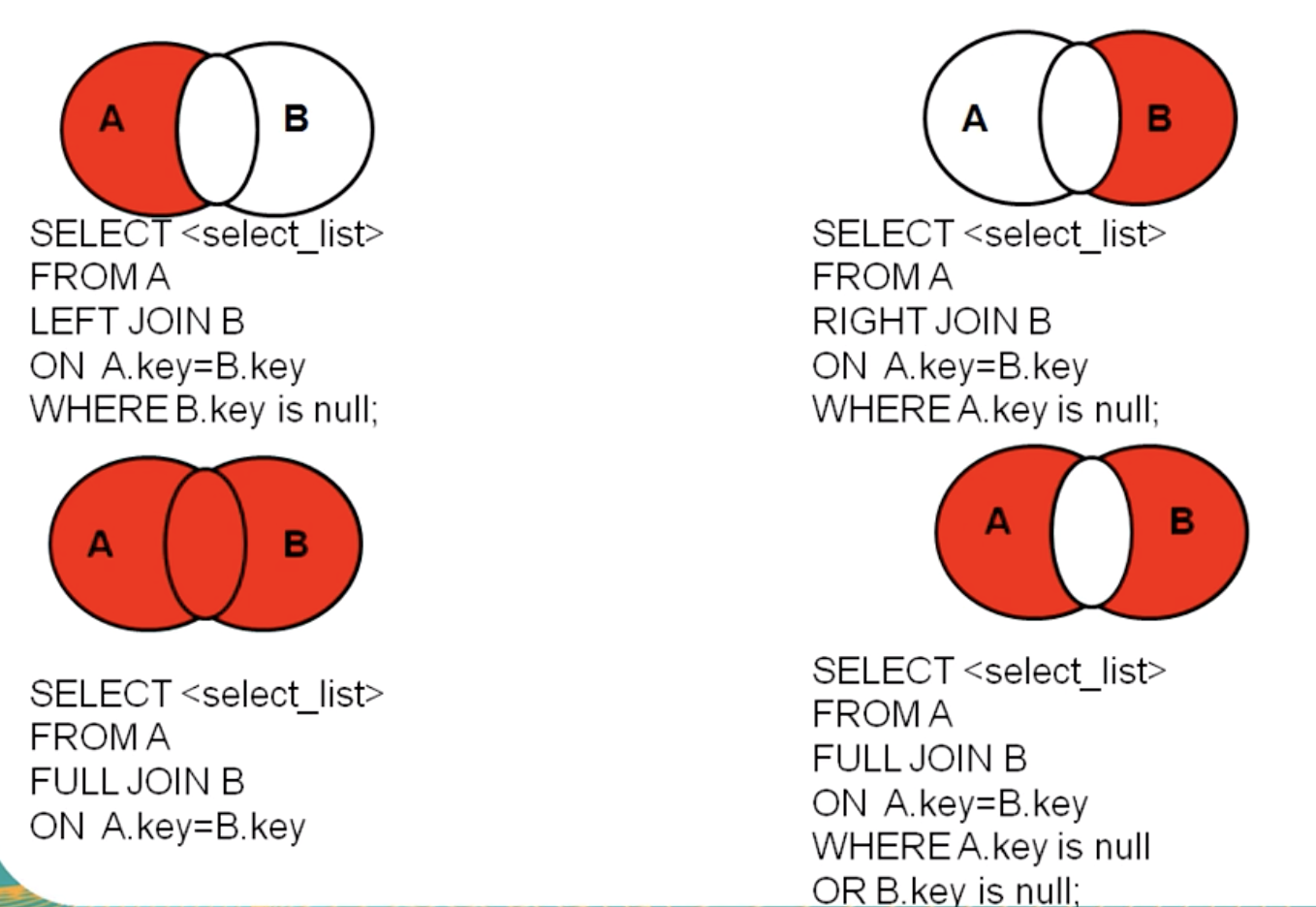
外连接:
左外:LEFT [OUTER]
右外:RIGHT[OUTER]
全外:FULL [OUTER]
交叉连接:CROSS :相当于笛卡尔乘积
外连接:
应用场景:用于查询一个表里有,另一个表里没有的记录
特点:外连接的查询结果为主表中的所有记录,如果从表中有和它匹配的,则显示匹配的值
如果没有和它匹配的,则显示null,外连接查询结果=内连接结果+主表中有而从表中没有的记录。
左外连接,LEFT JOIN 左边的是主表
右外连接:RIGHT JOIN 右边的是主表
左外和右外交换两个表的顺序,可以实现同样的效果。
--左连接: SELECT e.last_name,e.department_id, d.* FROM departments d LEFT JOIN employees e ON e.department_id = d.department_id WHERE last_name IS NULL; --右连接: SELECT d.*,e.department_id FROM employees e RIGHT JOIN departments d ON e.department_id = d.department_id WHERE last_name IS NULL;
交叉连接:CROSS :相当于笛卡尔乘积
SELECT b.*,bo.* FROM beauty b CROSS JOIN boys bo;
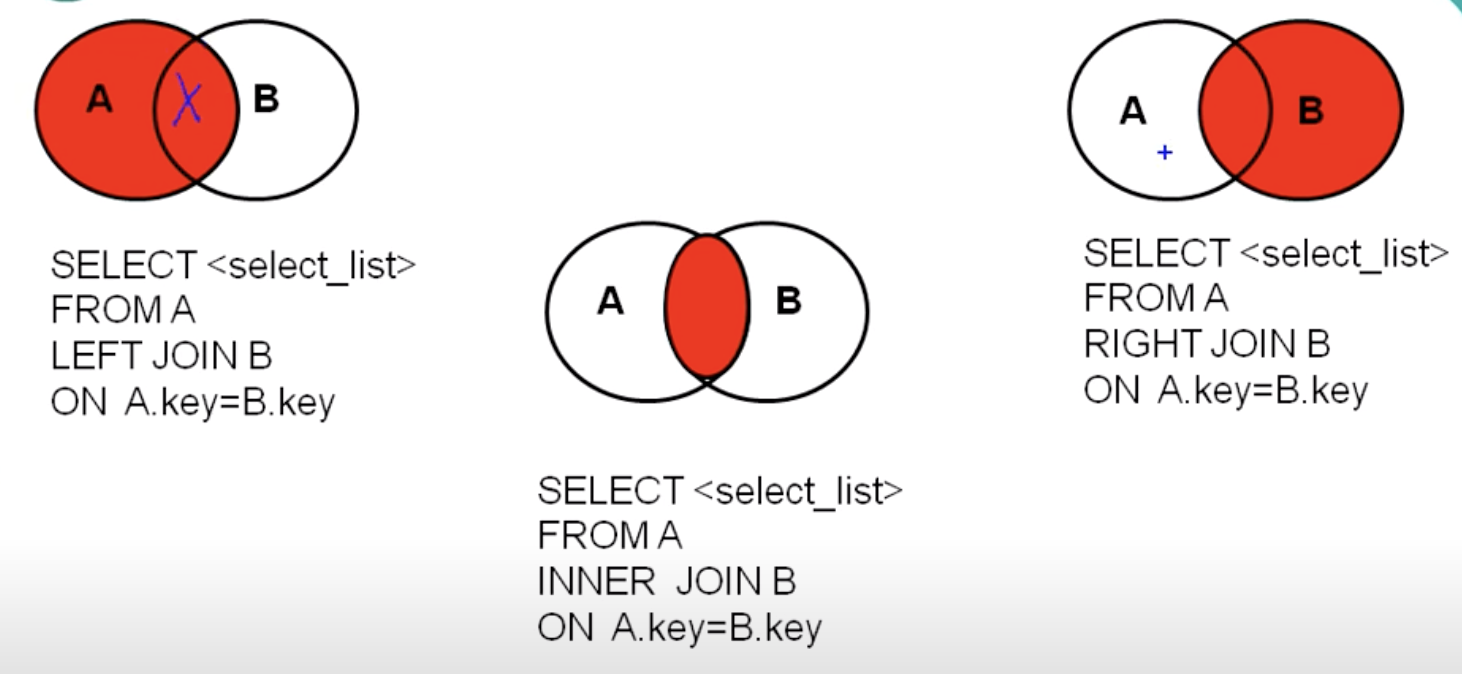
--子查询
含义:出现在其他语句中的select语句,称为子查询或内查询
外部的查询称为主查询或者外查询。
分类:
按子查询出现的位置:
SELECT 后面:标量子查询
FROM 后面: 表子查询 特点:将子查询充当一张表,要求子查询中的表必须取别名
⭐️WHERE或HAVING 后面 :标量子查询,列子查询, 行子查询
EXISTS 后面(相关子查询): 表子查询
按结果集的行列数不同:
标量子查询(结果集只有一行一列)
列子查询(结果集只有一列多行)
行子查询(结果集有一行多列)
表子查询 (一般为多行多列)
️WHERE或HAVING :
标量子查询 (单行子查询)
列子查询 (多行子查询)
行子查询 (多列多行)
特点:
1.子查询放在小括号内
2.子查询一般放在条件的右侧
3.标量子查询,一般搭配着单行操作符(> < >= <= = <> )使用
列子查询,一般搭配着多行操作符(IN,ANY/SOME,ALL)使用
子查询的执行优先于主查询
----分页查询:
应用场景:当要显示的数据,一页显示不全,需要分页提交sql请求
语法:
SELECT 查询列表
FROM 表
【JOIN type】JOIN 表2
ON 连接条件
WHERE 筛选条件
GROUP BY 分组字段
HAVING 分组后的筛选
ORDER BY 排序的手段
LIMIT OFFSET size;
OFFSET 要显示条目的起始索引(起始索引从0开始)
size要显示的条目个数;
特点:
1.limit语句放在查询语句的最后
2.limit (page-1)*size (要显示的页数是page,每页的条目数是size)
SELECT * FROM employees LIMIT 0,5: --OFFSET 为0时可以省略不写 SELECT * FROM employees LIMIT 10,15; SELECT * FROM employees WHERE commission_pct IS NOT NULL ORDER BY salary DESC LIMIT 0,10;
SELECT SUBSTR(email,1,INSTR(email,'@')-1) username FROM student;
SELECT sex,COUNT(*) FROM student GROUP BY sex;
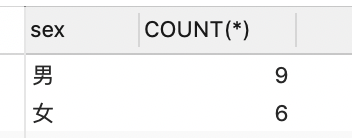
--联合查询
union 联合,合并:将多条查询语句的结果合并成一个结果
语法:
查询语句1
union
查询语句2
union
....
应用场景:要查询的结果来源于多个表,且多个表没有直接的连接关系,但查询的信息一致时。
特点:
1.要求多条查询语句的查询列数一致
2.要求多条查询语句的查询每一列的类型和顺序最好一致
3.union关键字默认去重,如果使用union all可以包含重复项。
--不使用联合查询 SELECT * FROM employees WHERE department_id > 90 OR email LIKE '%a%'; --使用联合查询 SELECT * FROM employees WHERE department_id > 90 UNION SELECT * FROM employees WHERE email LIKE '%a%';
--DML语言
数据操作语言:
插入:insert
语法:方式一:inset into 表名(列名,...)values(值1,...)
支持插入多行
方式二:insert into 表名 set 列名=值,列名=值,...
修改:update
删除:delete
*/
插入:insert
语法:
方式一:inset into 表名(列名,...)values(值1,...)
特点:
1.列的顺序可以调换 2.字段个数和字段值必须一一对应 3.可以省略列名,默认为所有字段,且按照表中顺序排列
支持插入多行
insert into beauty values(14,'刘雨欣','女','1991-8-9','1898383848',null,3), (15,'刘雨欣2','女','1991-8-9','1898383848',null,3), (16,'刘雨欣3','女','1991-8-9','1898383848',null,3);
方式二:insert into 表名 set 列名=值,列名=值,...
--方式一支持子查询,方式二不支持 INSERT INTO beauty(id,`name`,phone) SELECT 23,'宋茜','1862737373'
--修改语句
1.修改单表的记录
语法:
update 表名
set 列=新值,列=新值...
WHERE 筛选条件
UPDATE beauty SET phone ='138883474' WHERE `name` LIKE '刘%'; UPDATE boys SET boyName ='张飞',userCP=1000 WHERE id = 2;
2.修改多表的记录
语法:
(1)sql92语法:
update 表1 别名,表2 别名
set 列=值
where 连接条件
and 筛选条件
(2) sql99语法:
update 表1 别名,
inner/left/right join表2 别名
on 连接条件
set 列=值...
where 筛选条件
UPDATE boys bo INNER JOIN beauty b ON bo.id = b.boyfriend_id SET b.phone ='144' WHERE bo.boyName='张无忌';
UPDATE beauty b left JOIN boys bo ON b.boyfriend_id = bo.id SET boyfriend_id = 2 WHERE boyfriend_id IS NULL;
https://www.cnblogs.com/super-yb/p/12699452.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号