
银行风控模型的建立 Python
背景描述:
以数据bankloan.xls,前8列作为x,最后一列为y,建立银行风控模型。采用三种算法模型分别得到训练的结果,训练的误差以及混淆矩阵。
一、BP神经网络
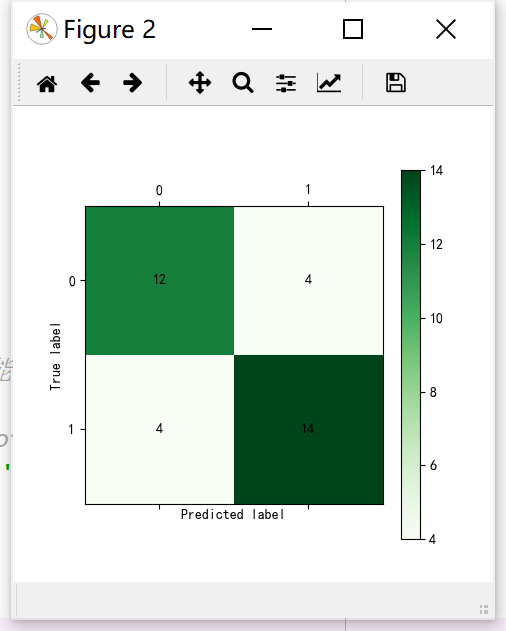
混淆矩阵可视化函数cm_plot:
def cm_plot(y, yp): from sklearn.metrics import confusion_matrix cm = confusion_matrix(y, yp) import matplotlib.pyplot as plt plt.matshow(cm, cmap=plt.cm.Greens) plt.colorbar() for x in range(len(cm)): for y in range(len(cm)): plt.annotate(cm[x,y], xy=(x, y), horizontalalignment='center', verticalalignment='center') plt.ylabel('True label') plt.xlabel('Predicted label') return plt
分类预测训练结果:
import pandas as pd
inputfile = r'C:\Users\86158\Desktop\python数据分析\data\sales_data.xls'
data = pd.read_excel(inputfile, index_col = '序号')
data[data == '好'] = 1
data[data == '是'] = 1
data[data == '高'] = 1
data[data != 1] = 0
x = data.iloc[:,:3].astype(int)
y = data.iloc[:,3].astype(int)
from keras.models import Sequential
from keras.layers.core import Dense, Activation
model = Sequential() # 建立模型
model.add(Dense(input_dim = 3, units = 10))
model.add(Activation('relu')) # 用relu函数作为激活函数,能够大幅提供准确度
model.add(Dense(input_dim = 10, units = 1))
model.add(Activation('sigmoid')) # 由于是0-1输出,用sigmoid函数作为激活函数
model.compile(loss = 'binary_crossentropy', optimizer = 'adam')
model.fit(x, y, epochs = 1000, batch_size = 10)
yp = model.predict_classes(x).reshape(len(y))
from cm_plot import *
cm_plot(y,yp).show()
混淆矩阵如下:
二、支持向量机(SVM)和决策树
import pandas as pd
import time
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier as DTC
from sklearn import svm
from sklearn import tree
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.metrics import roc_curve, auc
from sklearn.neighbors import KNeighborsClassifier as KNN
from sklearn.metrics import plot_roc_curve,roc_curve,auc,roc_auc_score
filePath = r'C:\Users\86158\Desktop\python数据分析\data\bankloan.xls'
data = pd.read_excel(filePath)
x = data.iloc[:,:8]
y = data.iloc[:,8]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=100)
svm_clf = svm.SVC()#支持向量机
dtc_clf = DTC(criterion='entropy')#决策树
#训练
dtc_clf.fit(x_train,y_train)
svm_clf.fit(x_train, y_train)
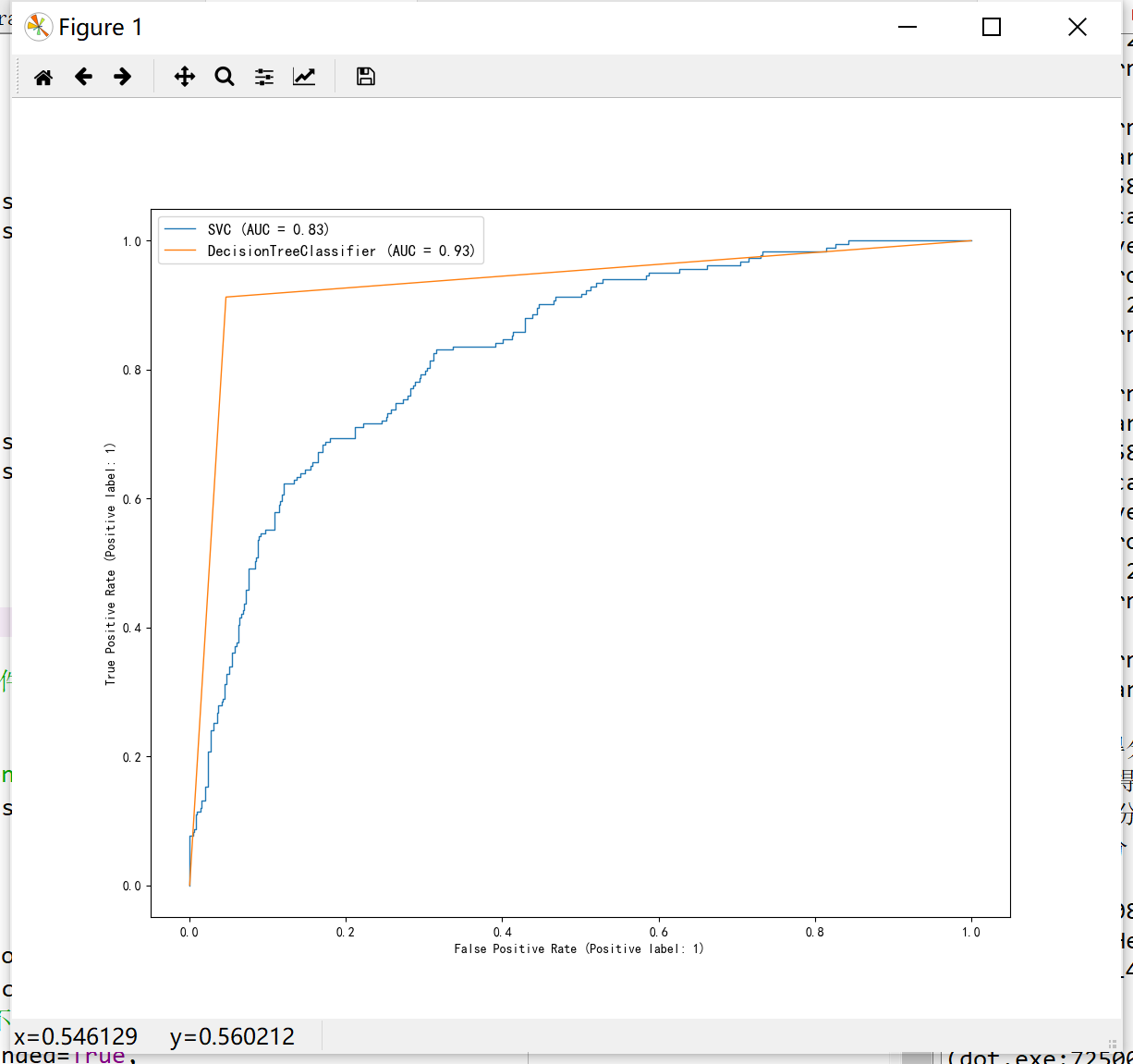
#ROC曲线比较
fig,ax = plt.subplots(figsize=(12,10))
svm_roc = plot_roc_curve(estimator=svm_clf, X=x,
y=y, ax=ax, linewidth=1)
dtc_roc = plot_roc_curve(estimator=dtc_clf, X=x,
y=y, ax=ax, linewidth=1)
ax.legend(fontsize=12)
plt.show()
#模型评价
svm_yp = svm_clf.predict(x)
svm_score = accuracy_score(y, svm_yp)
dtc_yp = dtc_clf.predict(x)
dtc_score = accuracy_score(y, dtc_yp)
score = {"支持向量机得分":svm_score,"决策树得分":dtc_score}
score = sorted(score.items(),key = lambda score:score[0],reverse=True)
print(pd.DataFrame(score))
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
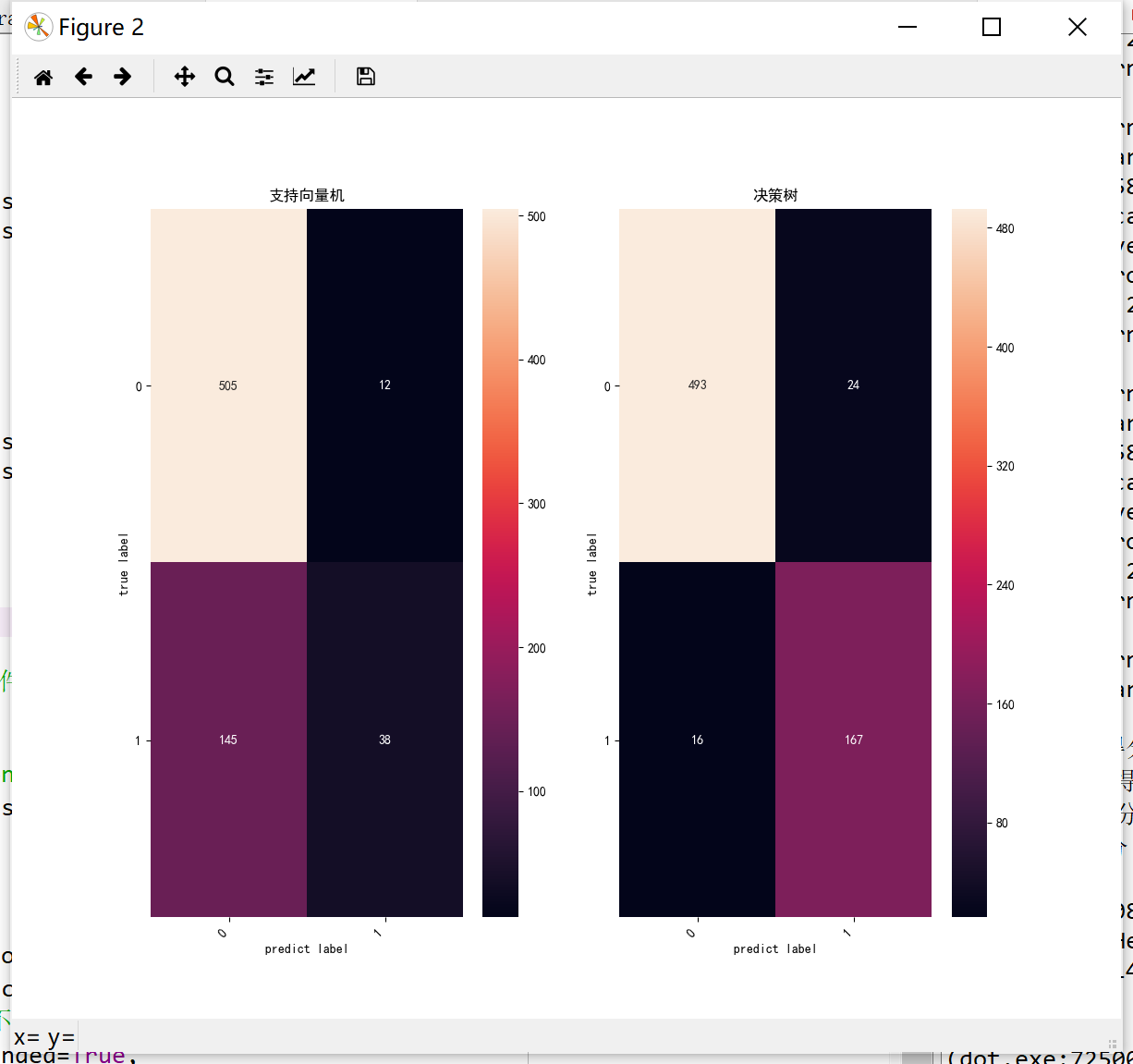
#绘制混淆矩阵
figure = plt.subplots(figsize=(12,10))
plt.subplot(1,2,1)
plt.title('支持向量机')
svm_cm = confusion_matrix(y, svm_yp)
heatmap = sns.heatmap(svm_cm, annot=True, fmt='d')
heatmap.yaxis.set_ticklabels(heatmap.yaxis.get_ticklabels(), rotation=0, ha='right')
heatmap.xaxis.set_ticklabels(heatmap.xaxis.get_ticklabels(), rotation=45, ha='right')
plt.ylabel("true label")
plt.xlabel("predict label")
plt.subplot(1,2,2)
plt.title('决策树')
dtc_cm = confusion_matrix(y, dtc_yp)
heatmap = sns.heatmap(dtc_cm, annot=True, fmt='d')
heatmap.yaxis.set_ticklabels(heatmap.yaxis.get_ticklabels(), rotation=0, ha='right')
heatmap.xaxis.set_ticklabels(heatmap.xaxis.get_ticklabels(), rotation=45, ha='right')
plt.ylabel("true label")
plt.xlabel("predict label")
plt.show()
#画出决策树
import pandas as pd
import os
os.environ["PATH"] += os.pathsep + 'D:/软件下载安装/Graphviz/bin'
from sklearn.tree import export_graphviz
x = pd.DataFrame(x)
with open( r'C:\Users\86158\Desktop\python数据分析\data\banklodan_tree.dot', 'w') as f:
export_graphviz(dtc_clf, feature_names = x.columns, out_file = f)
f.close()
from IPython.display import Image
from sklearn import tree
import pydotplus
dot_data = tree.export_graphviz(dtc_clf, out_file=None, #regr_1 是对应分类器
feature_names=x.columns, #对应特征的名字
class_names= ['不违约','违约'], #对应类别的名字
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data.replace('helvetica',"MicrosoftYaHei"))
graph.write_png(r'C:\Users\86158\Desktop\python数据分析\banklodan_tree.png') #保存图像
Image(graph.create_png())
训练得分:
0 1
0 支持向量机得分 0.775714
1 决策树得分 0.942857
ROC曲线:
混淆矩阵:
决策树:

显然,三种训练模型的对比下,决策树和支持向量机的效果比较好,决策树的效果最好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号