

分布式面试题
分布式锁和分布式事务的区别
分布式锁是在集群环境下,用来控制不同机器对共享资源的访问。例如:秒杀场景中的防止超卖问题。
分布式事务是在集群环境下,用来保证全局事务的一致性,保证多个数据库的数据整体上能从一个一致性状态转到另一个一致性状态。
分布式锁的实现方式有几种
1.基于数据库来实现
2.基于redis来实现
3.基于zookeeper来实现
基于关系型数据库来实现分布式锁。可以使用数据库表的唯一键来做。
做法:新创建一个表,就一个id字段和lockname字段(因为不同的锁的名称是不一样的,比方说有专门针对减库存的(抢茅台、抢手机等等都是不同的锁名称)),lockname一定要设置上唯一索引。加锁的时候,就是向表中插入一条记录,释放锁的时候就是将表中的这条记录删除掉。就可以了。
基于redis实现分布式锁的做法:是基于setnx,结合expire命令超时时间来做的。
基于zookeeper实现分布式锁的做法:是基于创建临时znode节点来做的。
分布式锁https://blog.csdn.net/weixin_56311692/article/details/128744825
zookeeper实现分布式锁的原理:
在项目中有用到过分布式锁吗?(面试有被问到)
在分布式系统中,当多个服务节点需要操作共享资源(如数据库中的唯一记录、缓存中的全局计数器、分布式任务调度等)时,本地锁(如synchronized、ReentrantLock)只能控制单个 JVM 内的并发,无法解决多节点间的竞争问题,此时需要分布式锁。
我遇到的具体场景包括:
- 库存扣减:秒杀系统中,多个服务节点同时处理下单请求,需要通过分布式锁保证库存操作的原子性,避免超卖。
- 分布式任务调度:防止多个节点重复执行同一任务(如定时数据同步)。
- 顺便再说一下自己做的交易分期邀约短信发送。
你在项目中有使用过seata的saga模式吗?(面试有被问到)
在 Java 项目中,我曾在分布式事务场景中使用过 Seata 的 Saga 模式,主要用于解决长事务和跨多个微服务的复杂业务流程一致性问题。以下从使用场景、实现方式、核心原理及实践经验等方面展开,供面试参考:
一、为什么选择 Saga 模式
在分布式系统中,常见的事务模式(如 TCC、AT)有各自的局限性:
- AT 模式:依赖本地事务和 undo log,适合短事务,但对跨多个异构数据库(如 MySQL+MongoDB)支持较差。
- TCC 模式:需要手写 Try/Confirm/Cancel 接口,业务侵入性强,适合核心链路的短事务。
而Saga 模式通过 “长事务拆分 + 补偿事务” 实现一致性,更适合:
- 长事务场景:业务流程步骤多、执行时间长(如订单履约:下单→支付→库存→物流→通知)。
- 跨异构服务:涉及不同技术栈的服务(如 Java 微服务 + Python 数据分析服务)。
- 低侵入性需求:不想对原有业务逻辑做大幅改造。
我参与的电商履约系统中,订单从创建到完成涉及 6 个微服务,流程长且部分服务使用非关系型数据库,因此选择 Saga 模式。
二、Saga 模式的核心原理
Saga 模式将分布式事务拆分为一系列本地事务(正向操作)和对应的补偿事务(逆向操作),通过以下机制保证一致性:
- 正向流程:按顺序执行各本地事务(如 T1→T2→T3→...→Tn)。
- 补偿流程:若某一步骤失败(如 T3 失败),则按逆序执行补偿事务(C3→C2→C1),撤销已执行的操作。
- 状态管理:Seata 通过日志记录各步骤执行状态,确保故障恢复后能继续执行或补偿。
例如,订单履约的 Saga 流程:
正向:创建订单(T1) → 扣减库存(T2) → 支付处理(T3) → 物流调度(T4)
补偿:取消物流(C4) → 退款(C3) → 恢复库存(C2) → 关闭订单(C1)
三、在项目中的具体实现
Seata 的 Saga 模式有两种实现方式,我在项目中主要使用编排式 Saga(通过状态机定义流程):
1. 引入依赖
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-saga-engine</artifactId>
<version>1.5.2</version>
</dependency>
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
<version>1.5.2</version>
</dependency>
2. 定义状态机(核心)
通过 JSON 配置文件描述正向 / 补偿流程,示例(order_saga.json):
{
"name": "OrderSaga",
"startState": "CreateOrder",
"states": {
"CreateOrder": { // 第一步:创建订单
"type": "ServiceTask",
"serviceName": "orderService",
"serviceMethod": "createOrder",
"nextState": "DeductStock",
"compensationState": "CancelOrder" // 对应补偿操作
},
"DeductStock": { // 第二步:扣减库存
"type": "ServiceTask",
"serviceName": "stockService",
"serviceMethod": "deduct",
"nextState": "ProcessPayment",
"compensationState": "RestoreStock"
},
// ... 其他步骤(支付、物流)
"CancelOrder": { // 补偿:关闭订单
"type": "ServiceTask",
"serviceName": "orderService",
"serviceMethod": "cancelOrder"
},
"RestoreStock": { // 补偿:恢复库存
"type": "ServiceTask",
"serviceName": "stockService",
"serviceMethod": "restore"
}
// ... 其他补偿步骤
}
}
3. 业务代码集成
在发起分布式事务的服务中,通过 Saga 引擎执行状态机:
@Autowired
private StateMachineEngine stateMachineEngine;
public void startOrderSaga(OrderDTO order) {
// 构建参数
Map<String, Object> context = new HashMap<>();
context.put("order", order);
// 执行Saga流程
StateMachineInstance instance = stateMachineEngine.start("OrderSaga", null, context);
if (instance.getStatus() == StateMachineInstance.Status.SUCCESS) {
log.info("订单流程执行成功");
} else {
log.error("订单流程执行失败,已触发补偿");
}
}
4. 补偿逻辑设计
补偿事务需要满足幂等性(避免重复执行导致数据异常),例如:
// 库存服务的补偿方法:恢复库存
public void restore(StockDTO stock) {
// 基于唯一订单号判断是否已补偿,避免重复执行
if (hasCompensated(stock.getOrderId())) {
return;
}
// 执行恢复库存逻辑
stockMapper.increase(stock.getProductId(), stock.getQuantity());
markAsCompensated(stock.getOrderId());
}
四、遇到的问题及解决方案
- 补偿逻辑失败:
某次库存补偿因数据库连接超时失败,导致数据不一致。
解决方案:利用 Seata 的重试机制,在状态机配置中设置补偿重试次数和间隔,并通过定时任务扫描未完成的补偿记录。 - 长事务状态存储:
流程执行时间过长时,Seata 默认的内存状态存储可能丢失信息。
解决方案:配置持久化存储(如 MySQL),将状态机实例信息存入数据库,支持故障恢复。 - 性能瓶颈:
同步执行所有步骤导致整体耗时过长。
解决方案:对无依赖关系的步骤采用并行执行(在状态机中配置ParallelGateway)。
五、Saga 模式的优缺点总结
| 优点 | 缺点 |
|---|---|
| 业务侵入性低,无需改造原有方法 | 一致性较弱(最终一致性,非强一致) |
| 支持长事务和异构服务 | 补偿逻辑设计复杂,需保证幂等性 |
| 实现简单,通过状态机配置流程 | 全流程耗时较长(步骤串行) |
总结
在跨多个微服务的长事务场景中,Seata 的 Saga 模式是一种实用的分布式事务解决方案。使用时需重点关注补偿逻辑的幂等性、异常重试机制和状态持久化,结合业务特点设计合理的流程拆分策略。相比 TCC/AT 模式,Saga 更适合业务流程复杂但一致性要求不是极致严格的场景。
seata的XA模式
它更适合并发量不高、一致性要求极高的核心场景(如资金交易),相比 AT/TCC/Saga 模式,XA 模式是 “以性能换一致性” 的选择。使用XA模式的前提是,你使用的数据库得支持XA协议。
XA 规范:是 X/Open 组织定义的分布式事务处理(DTP,Distributed Transaction Processing )标准 。
在 Seata 分布式事务框架内的相关内容:利用事务资源(数据库、消息服务等)对 XA 协议的支持,以 XA 协议的机制来管理分支事务的一种事务模式 。
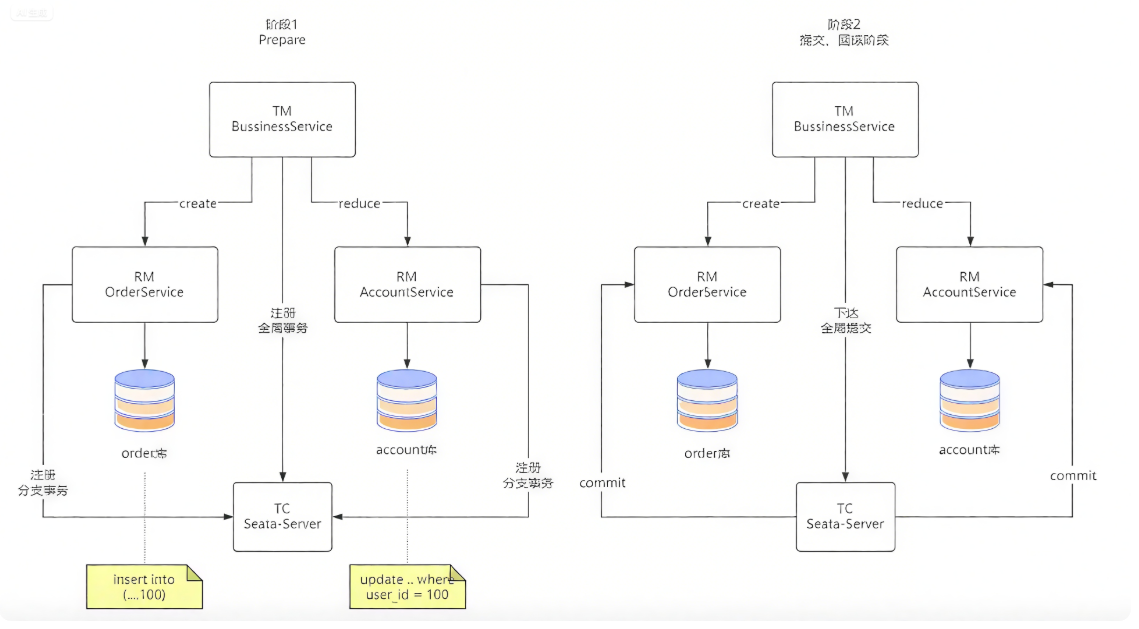
TM:事务管理器
RM:分支事务
TC:全局事务协调器
代码示意
TM 端:BussinessService 规定事务边界
@GlobalTransactional
public void purchase(String userId, String commodityCode, int orderCount, int money, boolean rollback) {
// 账户余额减少
String result = accountFeignClient.reduce(userId, money);
// 向Order服务调用创建订单
result = orderFeignClient.create(userId, commodityCode, orderCount);
}
RM1:OrderService 完成创建订单
Seata 通过 DataSourceProxyXA 包装原生 DataSource 自动实现全局事务控制
@Configuration
public class OrderXADataSourceConfiguration {
@Bean
@ConfigurationProperties(prefix = \"spring.datasource\")
public DruidDataSource druidDataSource() {
return new DruidDataSource();
}
@Bean(\"dataSourceProxy\")
public DataSource dataSource(DruidDataSource druidDataSource) {
// DataSourceProxy for AT mode
// return new DataSourceProxy(druidDataSource);
// DataSourceProxyXA for XA mode
return new DataSourceProxyXA(druidDataSource);
}
}
OrderService 实现业务方法
@Service
public class OrderService {
@Autowired
private JdbcTemplate jdbcTemplate;
@Transactional
public void create(String userId, String commodityCode, Integer count) {
int orderMoney = count * 100;
// 生成订单
jdbcTemplate.update(\"insert order_tbl(user_id,commodity_code,count,money) values(?,?,?,?)\",
new Object[]{userId, commodityCode, count, orderMoney});
}
}
RM2:AccountService 完成账户余额扣减
@Configuration
public class AccountXADataSourceConfiguration {
@Bean
@ConfigurationProperties(prefix = \"spring.datasource\")
public DruidDataSource druidDataSource() {
return new DruidDataSource();
}
@Bean(\"dataSourceProxy\")
public DataSource dataSource(DruidDataSource druidDataSource) {
// DataSourceProxy for AT mode
// return new DataSourceProxy(druidDataSource);
// DataSourceProxyXA for XA mode
return new DataSourceProxyXA(druidDataSource);
}
}
Transactional 实现业务方法
@Service
public class AccountService {
@Autowired
private JdbcTemplate jdbcTemplate;
@Transactional
public void reduce(String userId, int money) {
// 减少余额
jdbcTemplate.update(\"update account_tbl set money = money - ? where user_id = ?\", new Object[]{money, userId});
}
}
XA 的优势:
- 基于 CP 设计,强一致性,不会出现状态不一致
- 主流关系数据库都对 XA 有支持,数据业界标准
- 二段提交实现简单粗暴,成熟稳定
XA 的劣势:
- 执行效率低,基于数据库事务处理,数据会被 hang 住阻塞,高并发系统禁用
- 协议阻塞,收到 XA commit 或 XA rollback 前必须阻塞等待,如果一个参与全局事务的资源 “失联”,其他 RM 资源会 hang 住,等待超时回滚,导致性能进一步下降
- 强制要求数据库特性支持 XA,不支持的就没法用
适用场景:
- 企业级应用系统,低并发、数据冲突较少的系统
- 其实绝大多数系统都这样!!别骗自己 XA 适用于绝大多数企业及应用


 浙公网安备 33010602011771号
浙公网安备 33010602011771号