
(原创)用讯飞语音实现人机交互的功能
目前在做一款车载的项目,其中有一个需求是在开车的时候实现人与手机的对话,全过程不需要用手,只用语音操控。
这个就类似于人与机器人的对话,机器人在后台一直待命,用户说话 机器人做出对应的反映。
但由于用户手机电源的宝贵性,又不能让用户一直开着录音监听,这样很耗费资源。因此使用了讯飞语音提供的唤醒功能。
具体怎么做呢?
看一张流程图吧:这张流程图使用了讯飞的大部分技术(语音唤醒、语音唤醒+命令词识别、语义识别、语音合成),不废话,看图
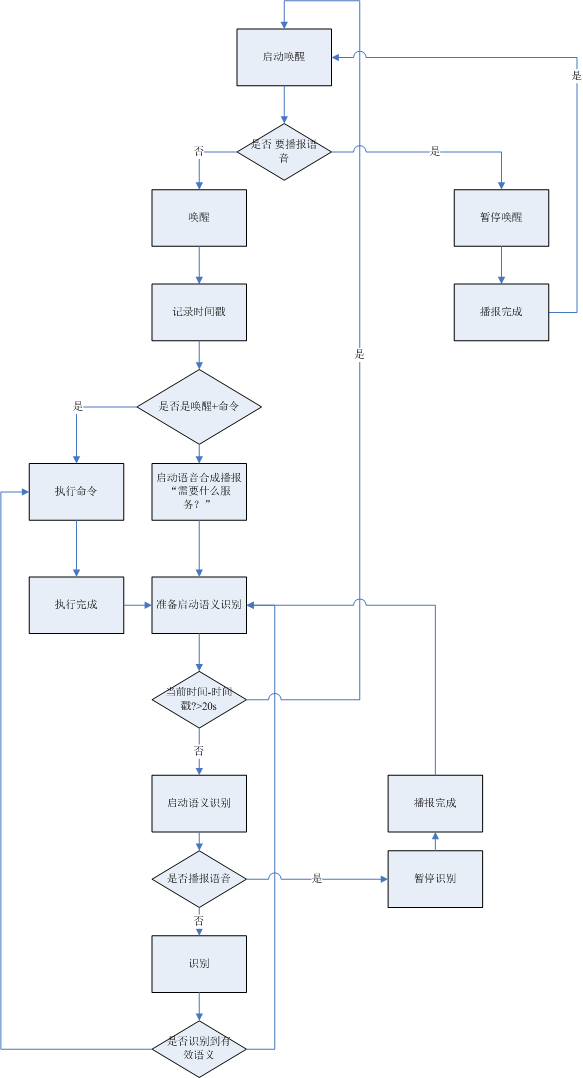
流程图已经写的很清晰了,简单介绍下
在程序启动的时候先启动唤醒,这个时候用户说唤醒词就会将机器唤醒,并 聆听命令。但如果这个时候有播报信息的话会优先播报信息,播报的时候会将唤醒暂停,播报完成后再启动唤醒。这么做有一个重要的原因是讯飞的唤醒是一直占用录音资源的,而这个时候去播报语音会断断续续,听说这个可以设置,但播报的时候用于一般也不会去说唤醒词。
讯飞的唤醒有两种模式:单纯的唤醒和唤醒+命令词识别
单纯的唤醒会有一个唤醒成功的回调,比较简单
而唤醒+命令词识别不仅能够唤醒,如果你在说唤醒词的同时说了一个命令,那么他也会识别这个命令,你可以很干脆的收到这个命令去执行,而不需要在启动什么语义识别后在执行命令了,这对用户来说也是很爽的。
但是命令词有一定的限制,就是命令词使用之前必须先构建语法,而命令词的内容必须得是提前知道的。但是如果用户说了一个 石河子大学怎么走,这个命令在你的命令词构建的语法文件里没有!怎么办?这时候你就得提示用户让用户去语义输入了。
所以我这里的构想是:用户说命令词,启动唤醒,然后识别命令词。识别命令词成功执行命令,识别命令词错误启动语义识别。
这有个缺点就是用户说了唤醒词+语义识别的内容,语义识别的内容被命令词消耗掉了,用户只有再说一次语义识别的内容才可以识别语义。
为了避免这个问题,我们在唤醒词识别后,如果命令词不能识别的时候,用合成语音提示以下用户“请问有什么可以帮您”,这个就代表机器没有识别到用户刚才的语义内容,需要 用户重新说,我是不是很奸诈o(∩_∩)o
接下来就是语义识别了,这个没什么说的,主要的一点就是如果用户不说话你要一直让它保持录音状态吗?当然不行啊,这多耗电啊!为了帮用户省电,我还设计了一个用户不说话20s自动进入等待唤醒的状态的流程。20s怎么来?使用时间戳啊!就是每次用户命令识别成功或者唤醒成功的时候记录一个时间戳。然后下次再启动语义识别前先判断当前时间和时间戳时间是否相差大于20s,如果小于20s则继续启动语义识别,如果大于20s则启动唤醒,准备让用户说命令词来唤醒吧。
好了,差不多了。不要问我为什么不一直让用户说唤醒词再执行对应的命令。如果你要干某一件事情之前总是还要说唤醒词,我估计你会疯掉的,即使你不疯别人也会认为你是神经病的。没有贬义,开玩笑,o(∩_∩)o 哈哈
我的github地址:https://github.com/dongweiq/study
欢迎关注,欢迎star o(∩_∩)o 。有什么问题请邮箱联系 dongweiqmail@gmail.com qq714094450

 浙公网安备 33010602011771号
浙公网安备 33010602011771号