Tensorflow04-keras与模型Sequential
一、tf.Keras 介绍
在 tensorflow中使用 keras库 来进行神经网络模型的训练。它是tensorflow的高阶API,可以快速搭建和训练神经网络模型。
特点:
- 面向对象,完全模块化
- 支持神经网络和深度学习的主流算法
- 支持多操作系统的多GPU并行计算
- 可以将其作为深度学习库的前端
在 Keras 中,主要的数据结构是模型(model),我们使用最多的就是 Sequential 模型。
二、Sequential 模型
Sequential 是一个神经网络框架,可以认为是一个容器,其中封装了神经网络的结构,只有一组输入 和 一组输出,各层之间按照先后顺序堆叠,前一层的输出就是后一层的输入,通过多个层的堆叠,构建出神经网络。
1、建立 Sequential 模型
使用 API :model = tf.keras.Sequential()。
通过type方法,可以看到是 Sequential 类的对象,此时这个 model 是一个空的容器。
2、添加层
现在在model里添加层, 构成神经网络,这也是 Sequential 的核心操作。
可以使用 add 方法,逐层添加神经网络中的各个层。
API: model.add( tf.keras.layers.*** )
其中,tf.keras.layers.**表示层的类型,keras 提供了很多,例如拉直层,全连接层,池化层,卷积层,LSTM层等等,他们都是 layers 类中的函数,可以直接作为add方法的参数。下面给出具体用法:
(1)Flatten 拉直层
# 这一层没有计算,只是形状转换,将输入特征拉直变成一维数组 tf.keras.layers.Flatten()
(2)Dense 全连接层
tf.keras.layers.Dense( inputs # 输入该网络层的数据,数字,即该层有几个神经元 activation # 激活函数,可以以字符串的形式给出:'relu','softmax','sigmoid','tanh' input_shape # 输入数据的形状(全连接神经网络的第一层,接受来自输入层的数据,必须要指明形状,后面的层接受前一层的输出,不用再指明形状) kernel_regularizer # 正则化,可选,tf.keras.regularizer.l1()或l2() )
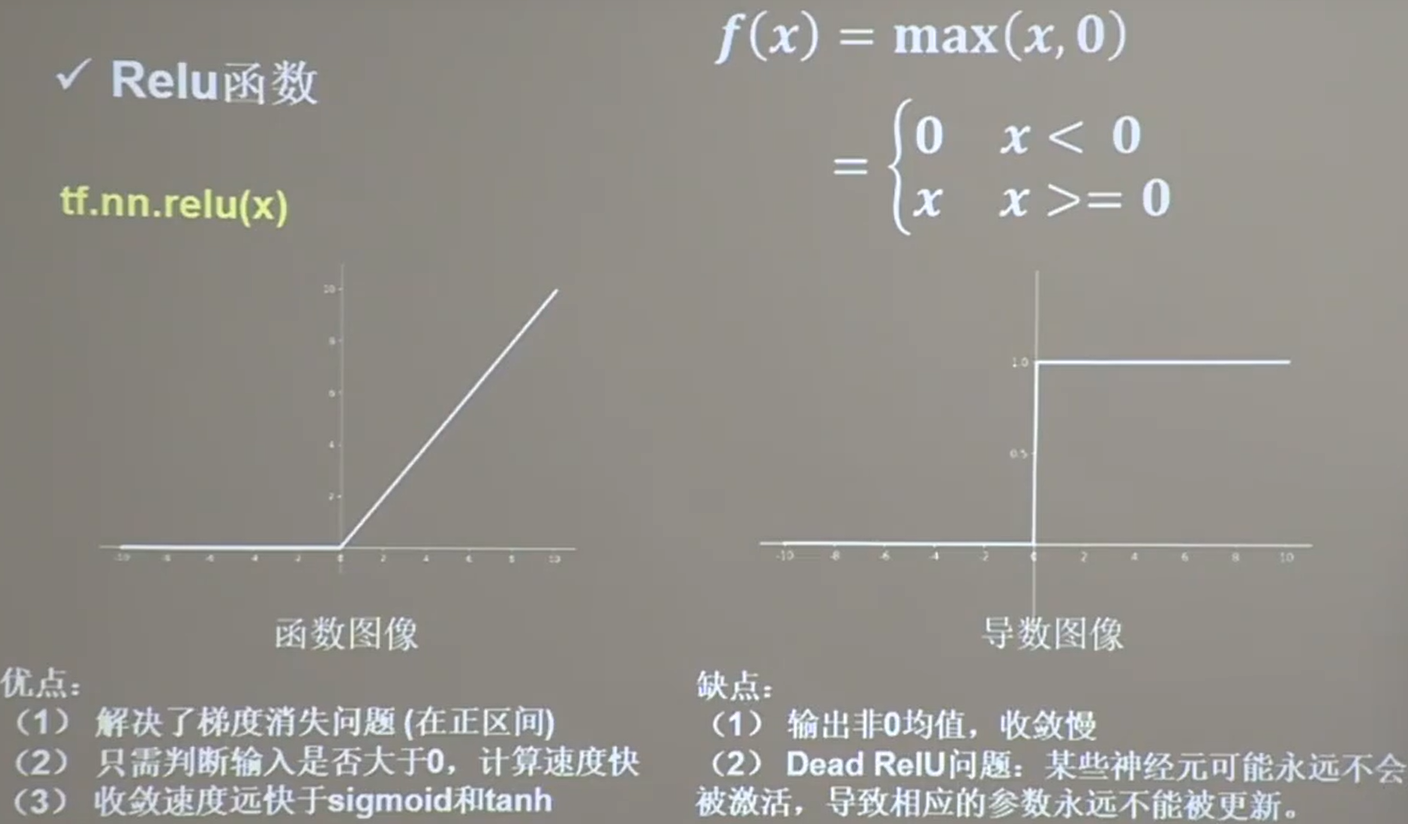
关于激活函数,重点掌握 relu、softmax、sigmoid,其中relu是最常用的。详见本篇最后内容。
关于正则化 l1() 和 l2() 参考博客:https://blog.csdn.net/rocling/article/details/90290576
(3)Conv2D卷积层
tf.keras.layers.Conv2D(filters=卷积核个数, kernel_size=卷积核尺寸, strides=步长, padding="valid" or "same")
(4)LSTM层
tf.keras.layers.LSTM()
3、查看模型结构信息
使用方法:model.summary()。
下面我们利用上面的几个API,给出一个三层神经网络搭建实例。
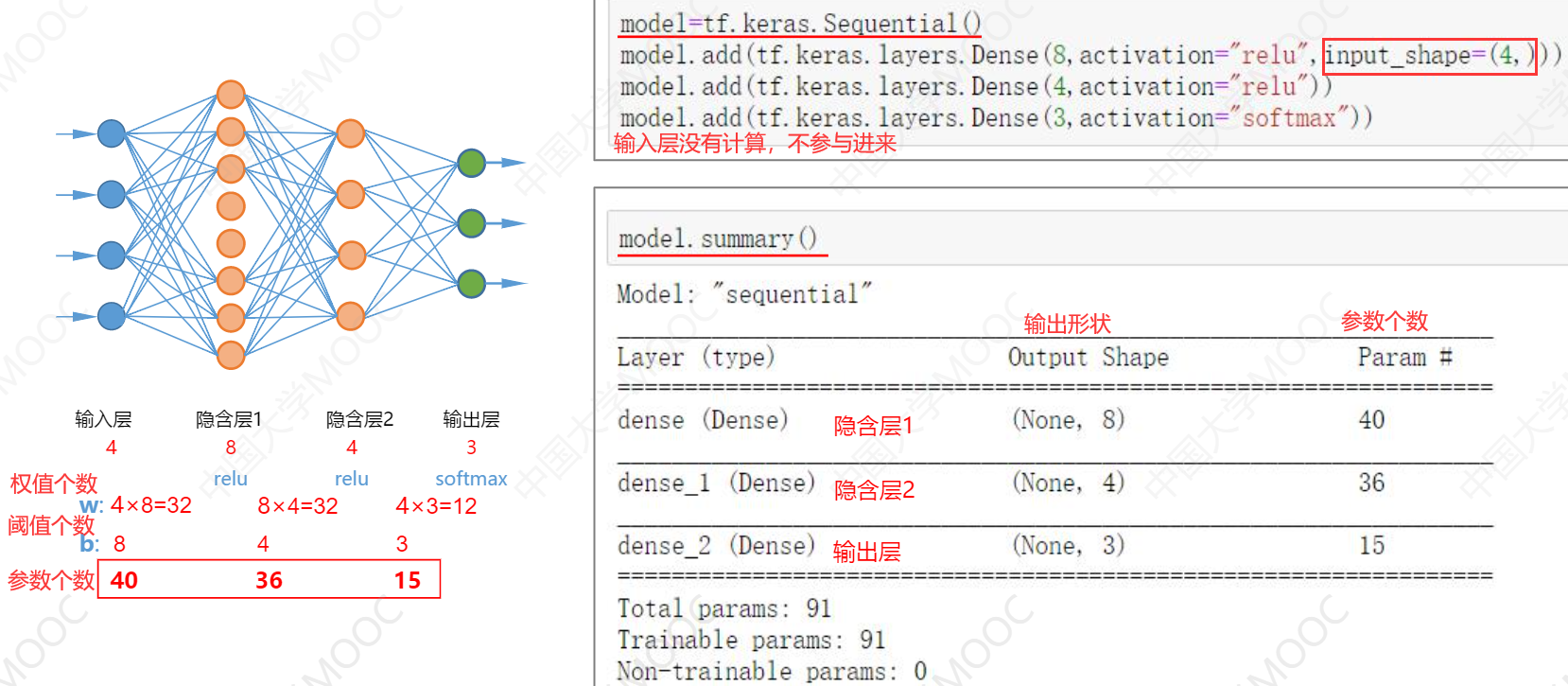
4、配置训练方法
API:model.compile(loss, optimizer, metric)
- loss:损失函数
- optimizer:优化器
- metric:模型训练时我们希望输出的评测指标
下面给出这些参数的可选值:(每个参数都有两种形式,可以给出一个字符串,也可以给出一个函数形式)
loss 损失函数
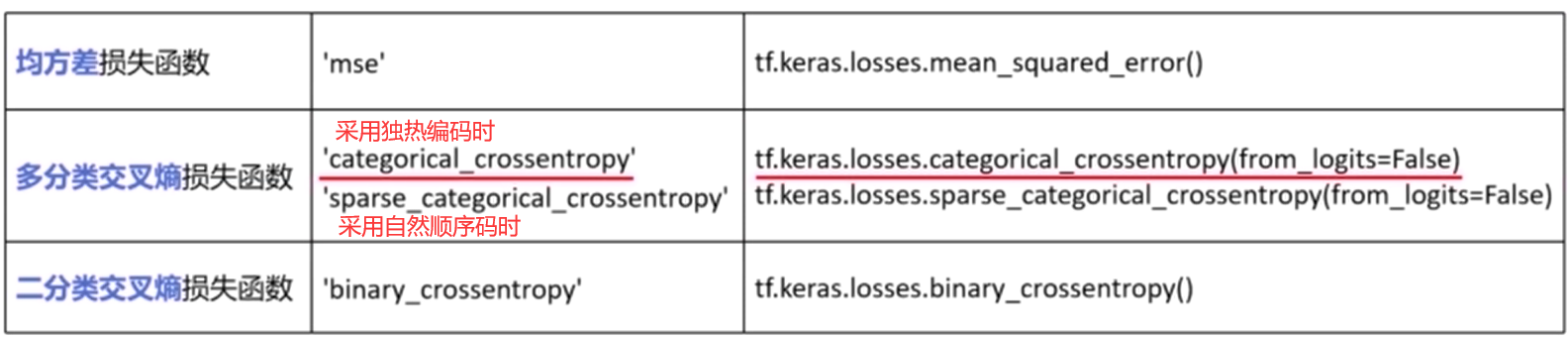
关于多分类损失函数的参数 from_logits:神经网络输出前,已经使用softax函数将预测结果变换为概率分布(我们在多分类习惯这么做),所有的输出之和为 1,则该参数 为 false。如果输出前没有经过softmax变换,则需要设置为 true。
optimizer 优化器

其中函数形式可以设置超参数如学习率 lr,动量 momentum 等。
metrics 训练评价指标
可以使用 Keras 模型性能评估函数,也可以自定义性能评估函数
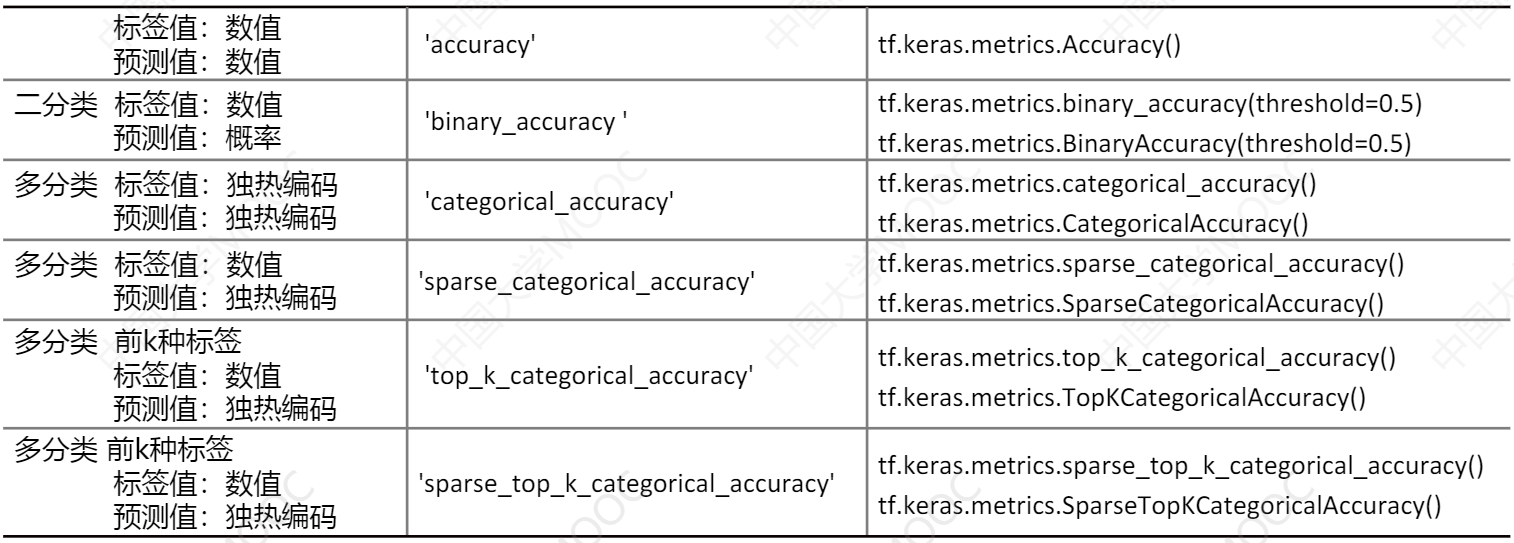

在该参数中,可以使用列表形式,写入多个评估函数。
5、训练模型
主要使用 model.fit 方法,下面是各个参数,和每个参数的默认值。
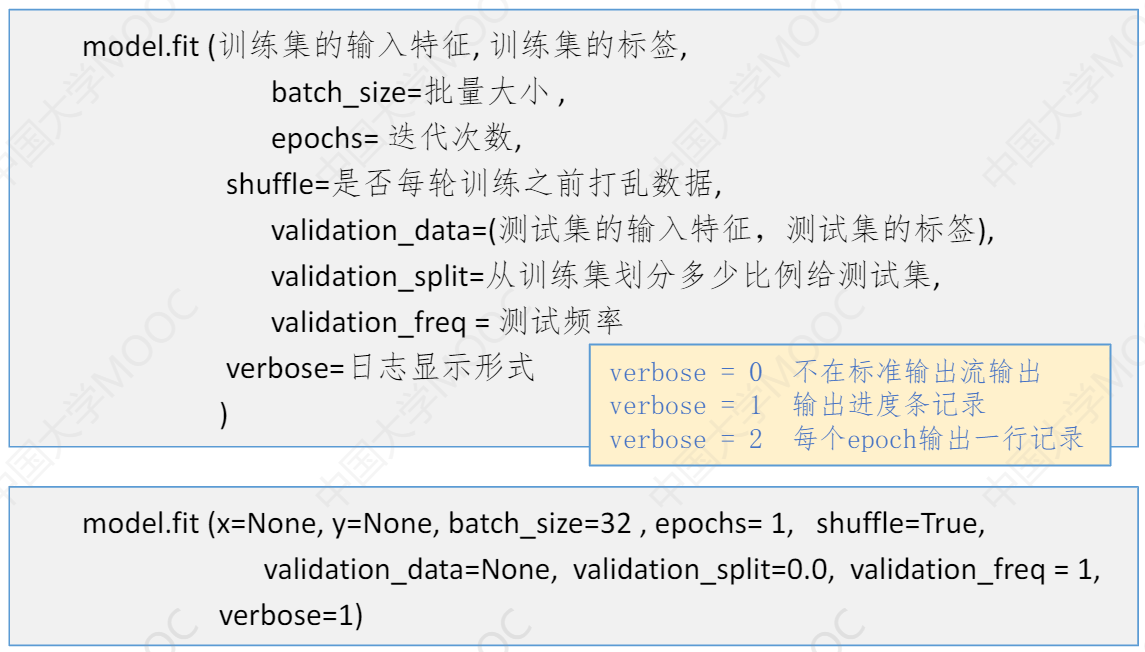
可以通过 函数 model.metrics_names 查看模型的性能指标。
fit方法返回一个 History 对象,可以通过该对象的 history 属性查看。例如:history = model.fit(),history.history 查看,返回一个字典,其中有四个属性,分别是训练集和测试集上的损失和准确率,每个属性的值是一个列表。
注意:fit 函数的validation_split 默认为 0,即不划分测试数据。那样在训练结果只有训练集的损失和准确率了。
如果没有在 fit 训练时划分数据集,则可以在下面的模型评估里进行。
6、模型评估
使用的函数 model.evaluate(test_set_x, test_set_y, batch_size, verbose) 进行模型的评估
参数解释:
- test_set_x, test_set_y:提供测试数据的属性和标签
- batch_size:批量大小
- verbose:输出信息方式
函数的第一个返回值是 损失,第二个返回值是在compiler中指定的性能指标,如下:
loss, acc = model.evaluate(x_test, y_test, verbose=2)
7、分类预测
训练好模型之后,就可以使用它进行模型分类,通过 predict 方法实现。
model.predict(x, batch_size, verbose),当 x 为批量数据时,程序会根据batch_size 的大小分批量的预测数据
参数说明
本篇介绍了Tensorflow中的神经网络的一个搭建框架,掌握以上7步,就能搭建一个属于自己的神经网络。但各个方法中有很多参数,含义众多,此处进行简单说明。
1、激活函数:relu 、sigmoid、softmax


 浙公网安备 33010602011771号
浙公网安备 33010602011771号