elasticsearch分布式搜索引擎
elasticsearch
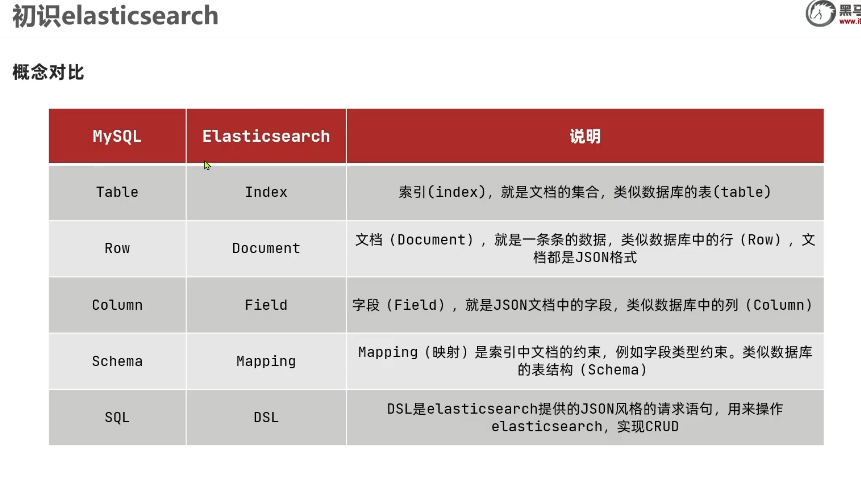
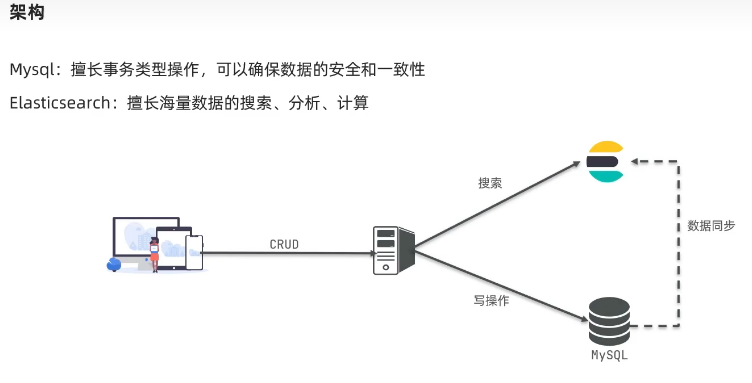
初识elasticsearch
了解ES
elasticsearch是一款非常强大的开源搜索引擎,可以帮助我们从海量数据中快速找到需要的内容


倒排索引
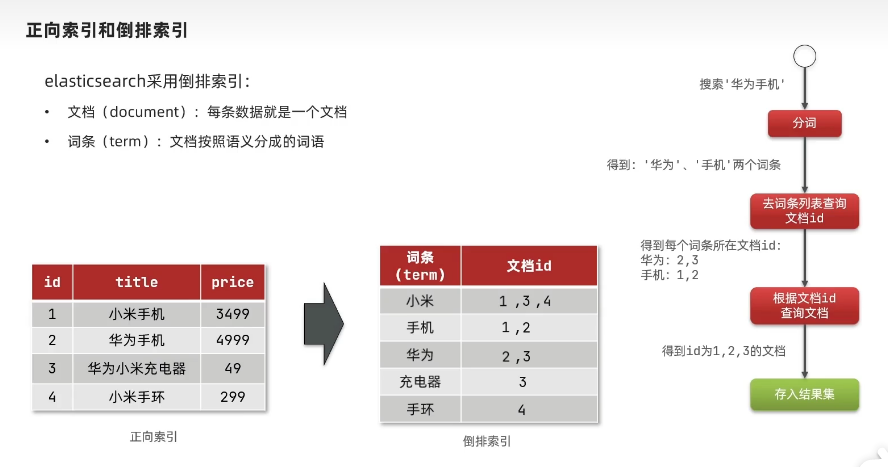

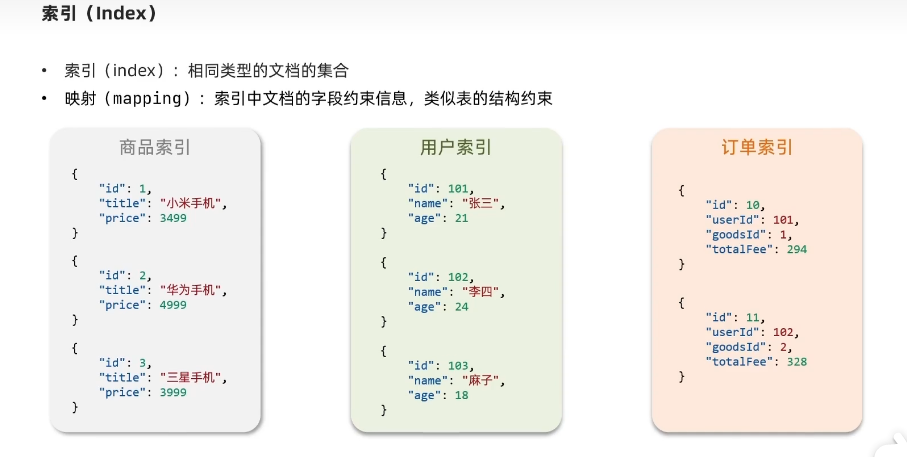
es的一些概念

安装es、kibana
部署单点es
- 创建网络
docker network create es-net
- 加载镜像
将es.tar上传到虚拟机中,然后运行命令加载即可docker load -i es.tar
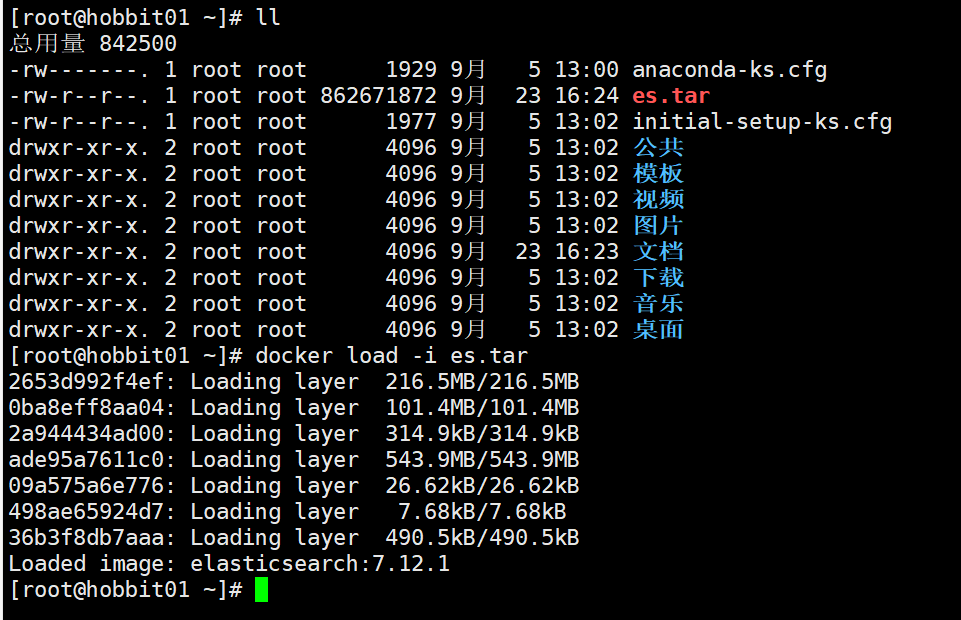
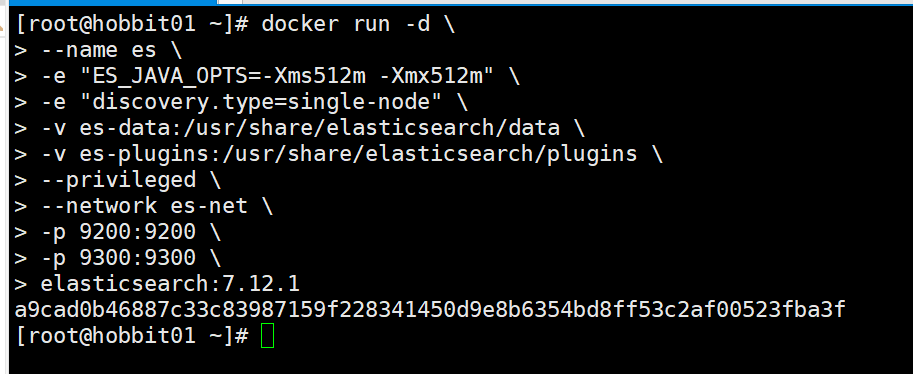
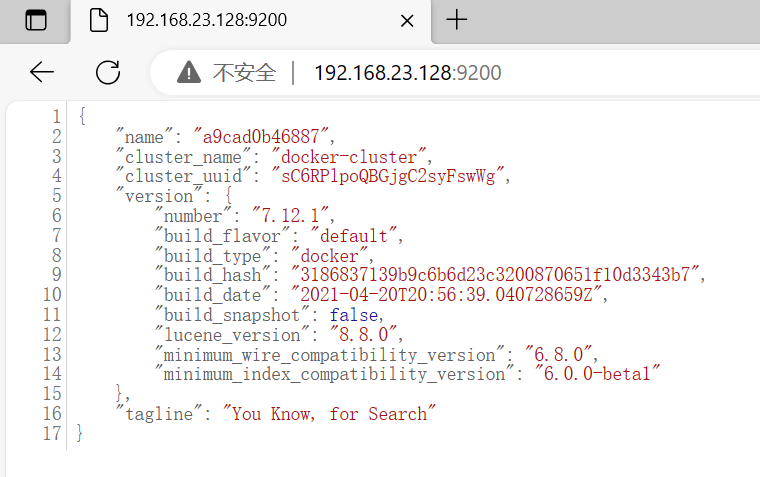
- 运行
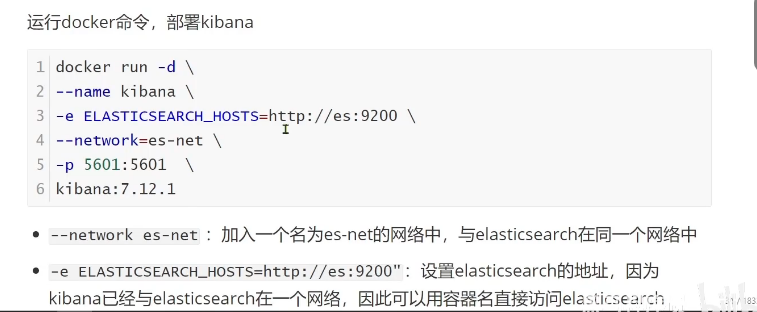
部署kibana
- 加载镜像
将kibana.tar上传到虚拟机中,然后运行命令加载即可docker load -i kibana.tar
- 部署
- DevTools
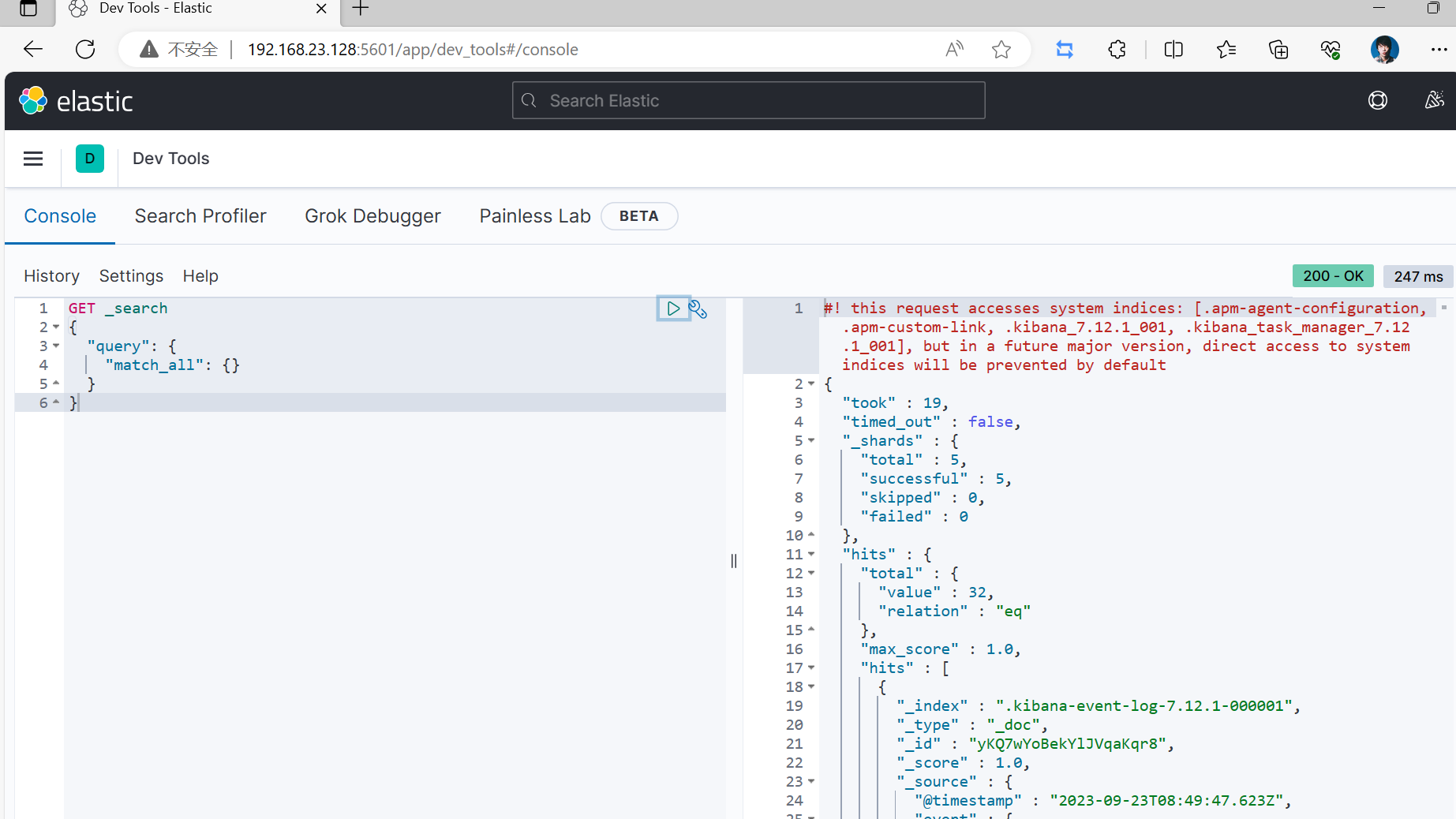
安装IK分词器
- 安装IK插件
-
es在创建倒排索引时需要对文档分词,在搜索时需要对用户输入内容分词,但默认的分词规则对中文处理并不友好
-
处理中文分词一般使用ik分词器
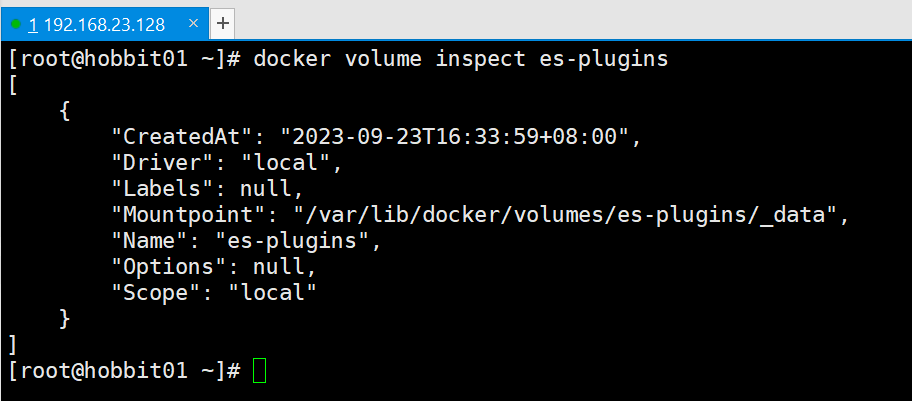
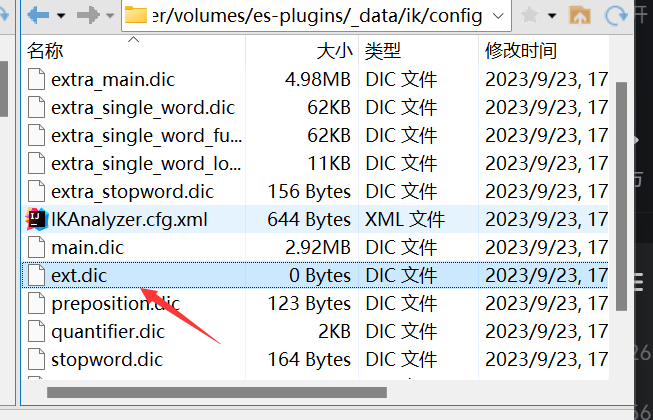
1.1 安装插件需要知道elasticsearch的plugins目录位置,而我们用了数据卷挂载,因此需要查看elasticsearch的数据卷目录,通过下面命令查看:
docker volume inspect es-plugins
1.2 解压缩分词器安装包
- 把ik分词器压缩包解压缩并重命名为ik
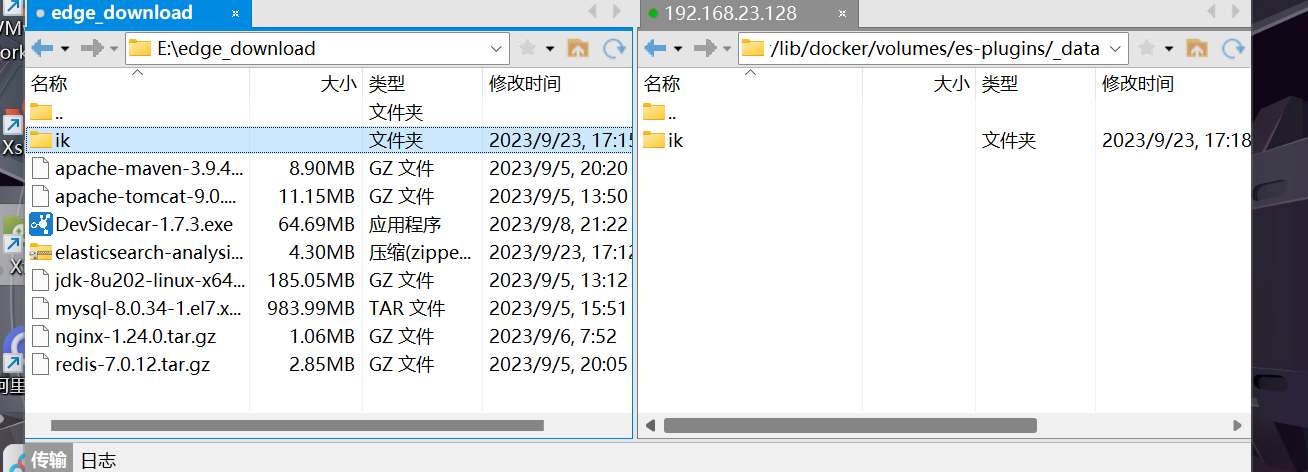
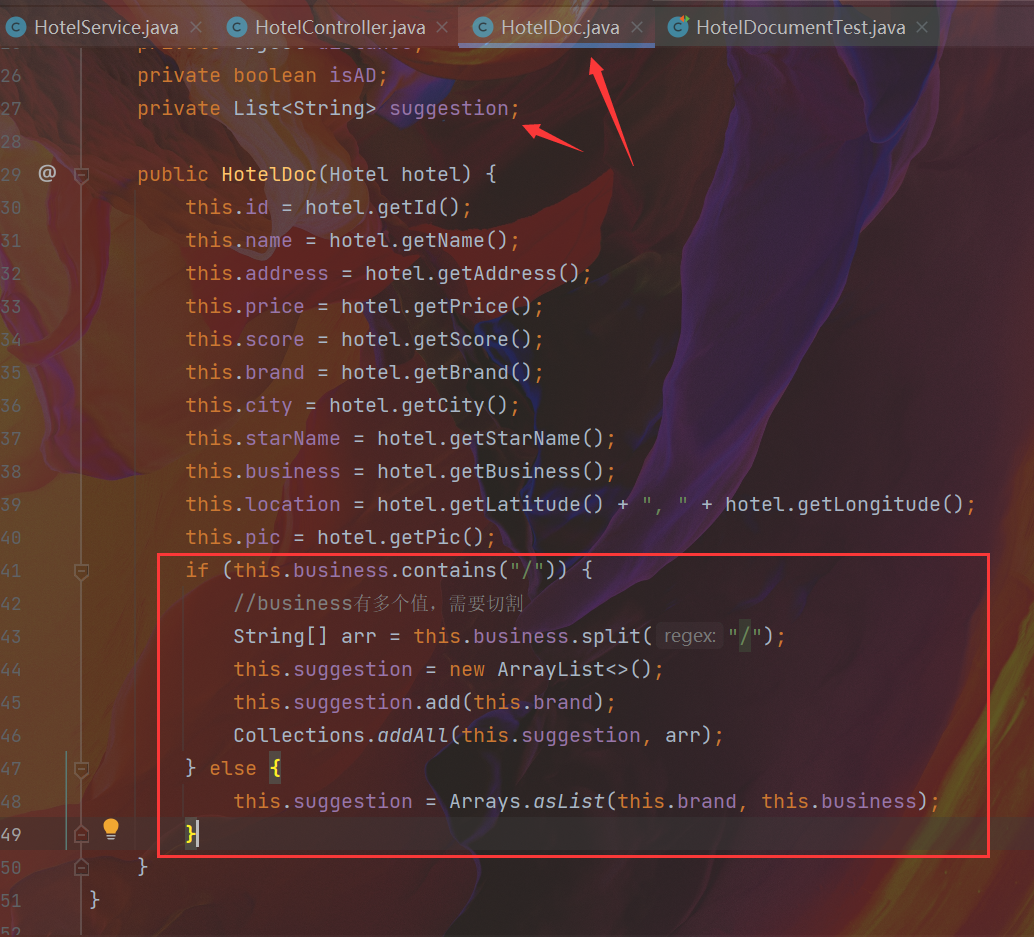
1.3 将解压好的es容器的插件上传到数据卷中
1.4 重启容器
docker restart es
- 查看es日志
docker logs -f es
1.5 测试
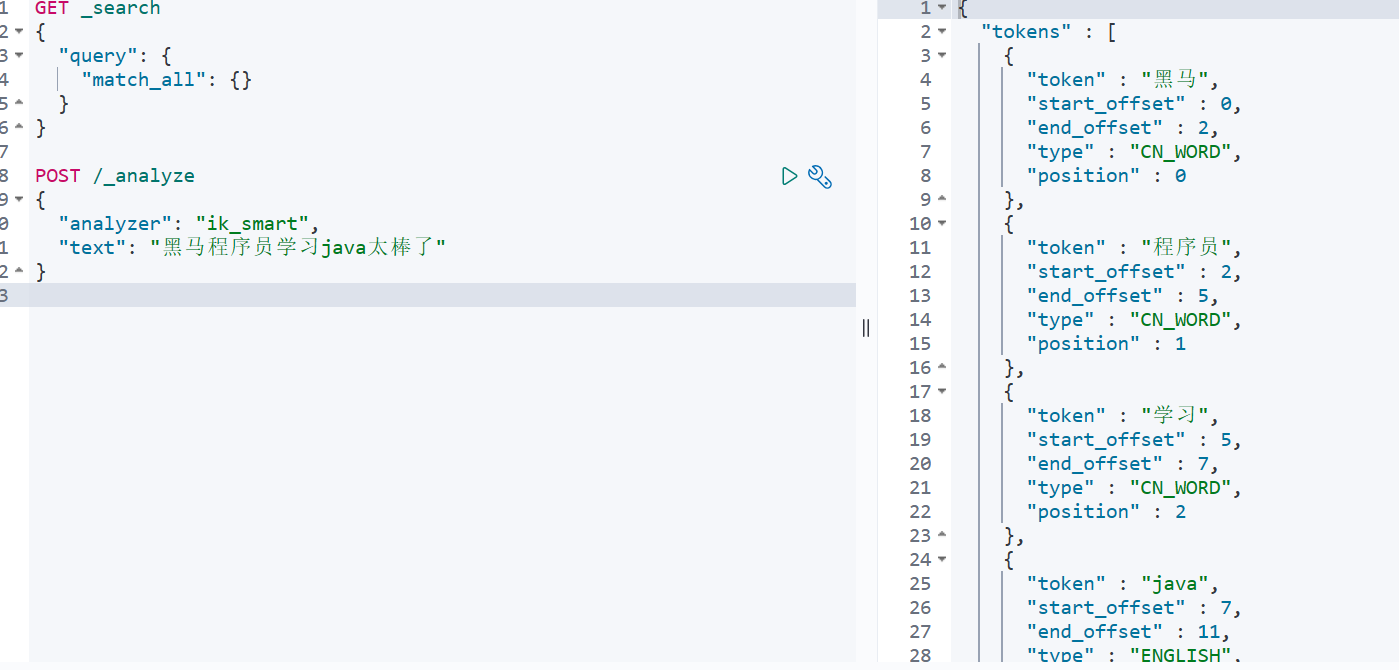
- ik_max_word :最细粒度切分
- ik_smart :粗粒度切分
- 拓展词词典
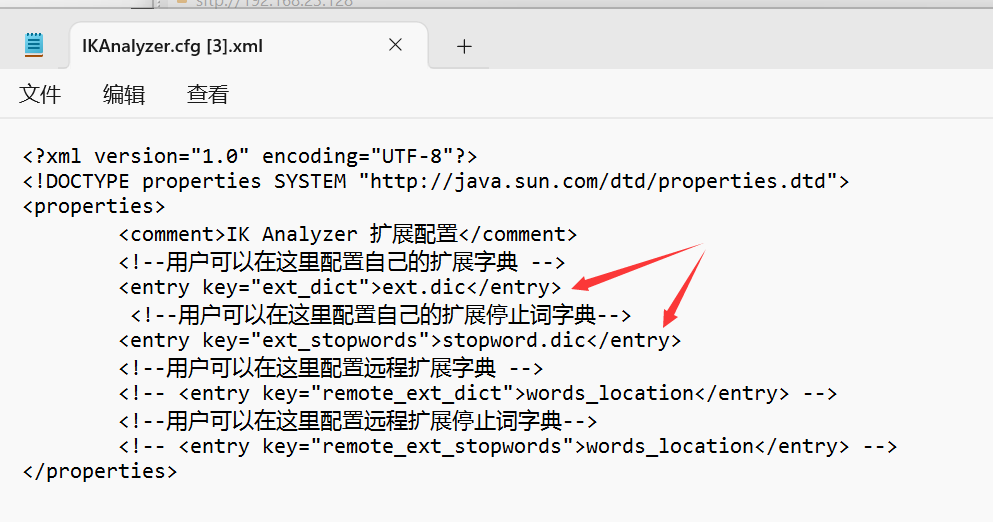
- 想要拓展ik分词器的词库,只需要修改一个ik分词器目录中config目录中的IkAnalyzer.cfg.xml文件:
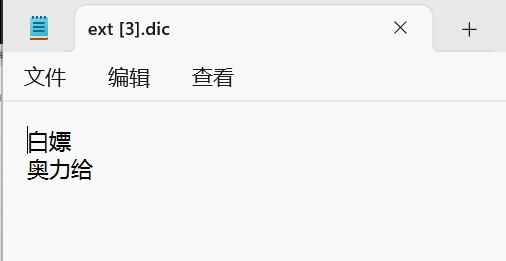
- 然后在名为ext.dic的文件中,添加想要拓展的词语即可:
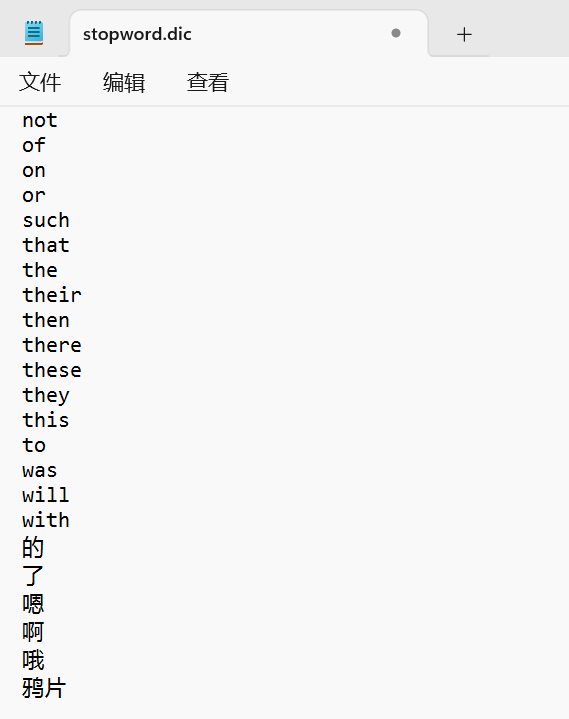
- 停用词词典
- 想要禁用某些敏感词条,只需要修改一个ik分词器目录中的config目录中的IkAnalyzer.cfg.xml文件:
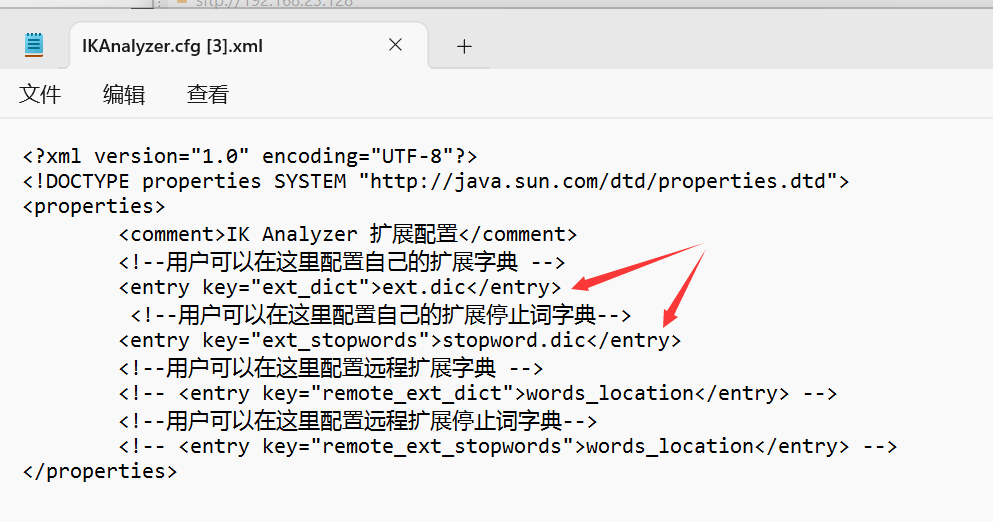
- 然后在名为stopword.dic的文件中,添加想要停用的词语即可:
- 重启es
docker restart es - 效果演示:
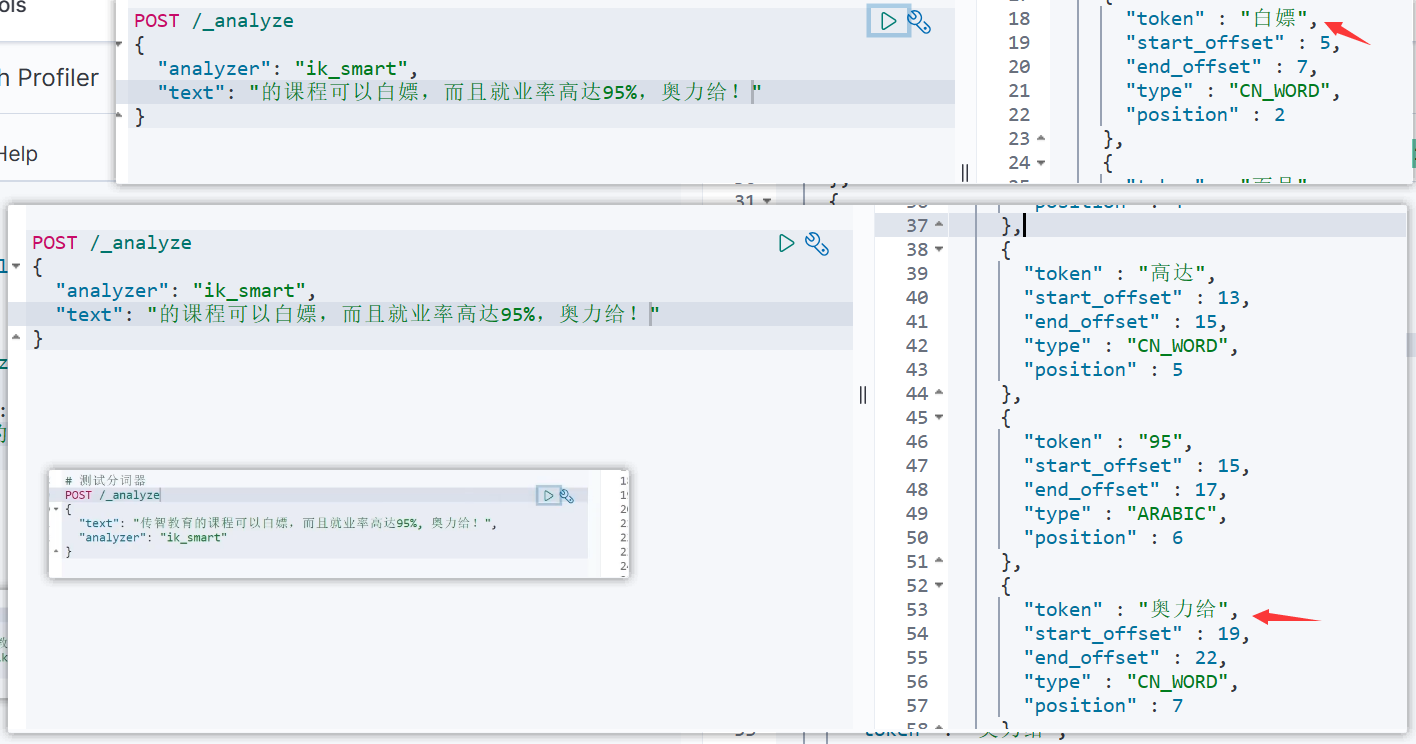
- 而且可以看到 '的' 没有被分词
索引库操作
- mapping映射常见属性↓

- ES中通过Restful请求操作索引库、文档,请求内容用DSL语句来表示
- 创建索引库↓

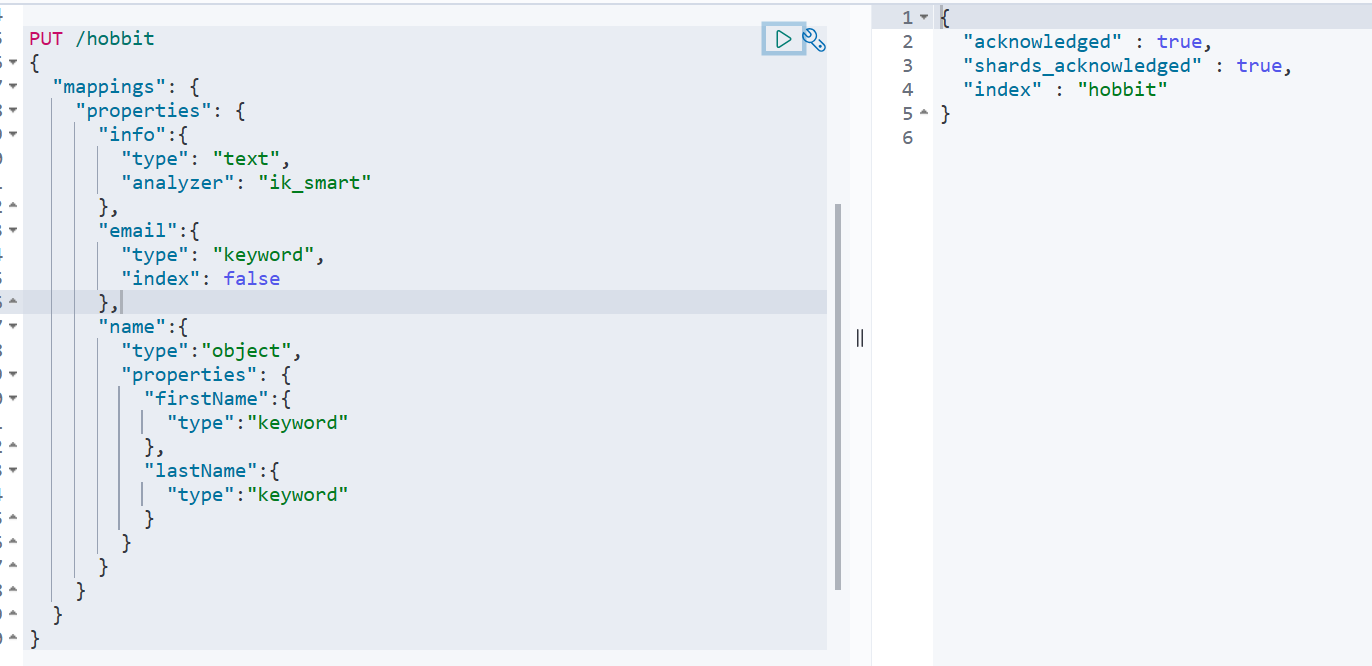
- 操作索引库(查询、删除、修改索引库)↓
- 查看索引库语法:GET /索引库名
- 删除索引库语法:DELETE /索引库名
- 修改索引库↓

文档操作
新增、查询、删除文档
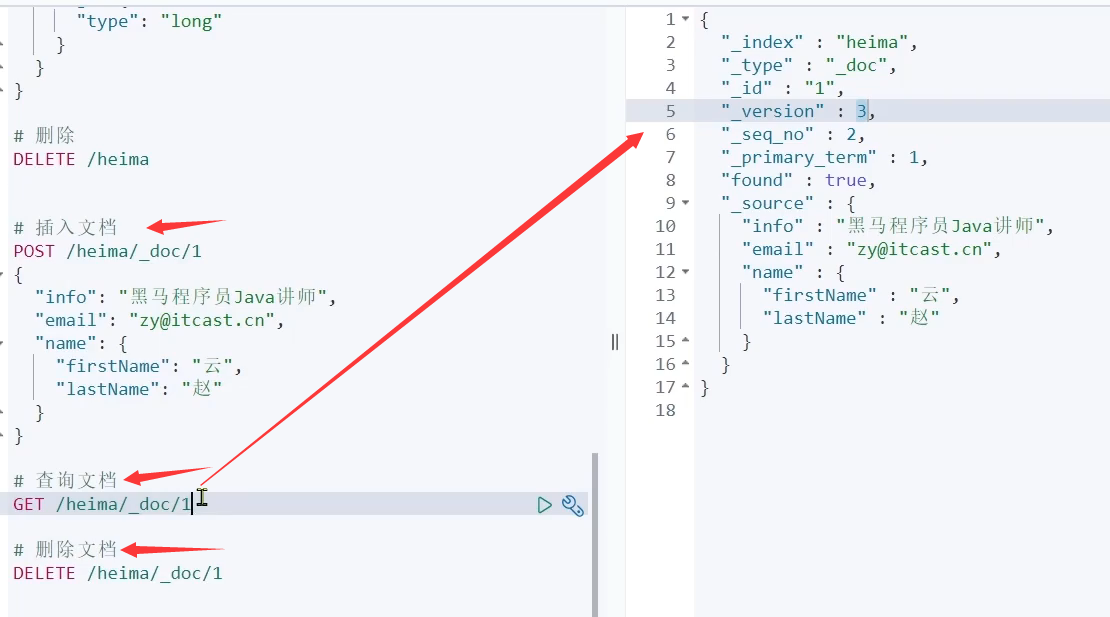
修改文档
- 方式一:全量修改,会删除旧文档,添加新文档,当id在索引库存在就是修改,不存在就是新增文档
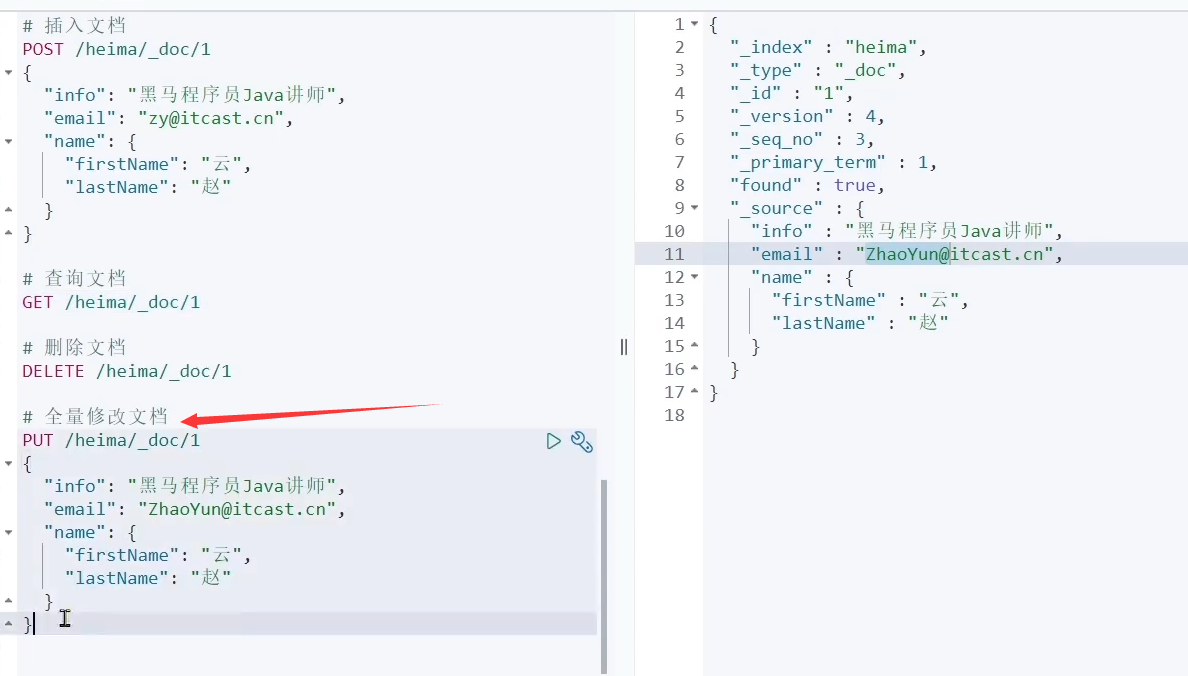
- 方式二:增量修改,修改指定字段值

RestClient操作索引库(案例)
RestClient:ES官方提供了各种不同语言的客户端,用来操作ES,这些客户端本质就是组装DSL语句,通过http请求发送给ES。
1. 导入课前资料Demo
2. 分析数据结构,定义mapping属性
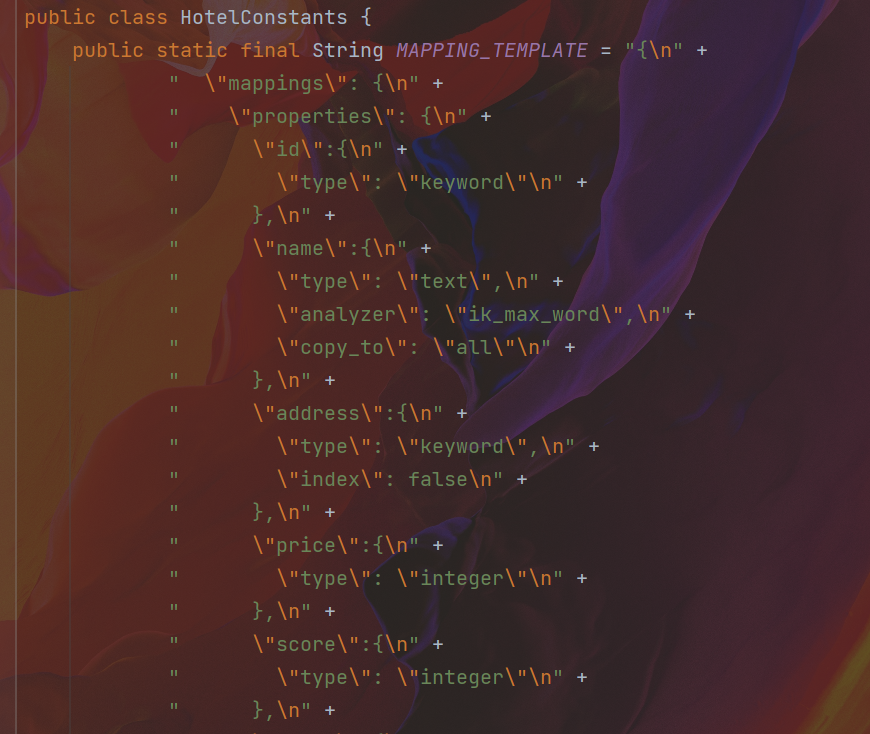
PUT /hotel
{
"mappings": {
"properties": {
"id":{
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "ik_max_word",
"copy_to": "all"
},
"address":{
"type": "keyword",
"index": false
},
"price":{
"type": "integer"
},
"score":{
"type": "integer"
},
"brand":{
"type": "keyword",
"copy_to": "all"
},
"city":{
"type": "keyword"
},
"starName":{
"type": "keyword"
},
"business":{
"type":"keyword",
"copy_to": "all"
},
"location":{
"type": "geo_point"
},
"pic":{
"type": "keyword",
"index": false
},
"all":{
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
3. 初始化JavaRestClient
3.1 引入es的RestHighLevelClient依赖
<!--elasticsearch-->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
3.2 因为SpringBoot默认ES版本是7.6.2,所以要覆盖默认的ES版本
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.12.1</elasticsearch.version>
</properties>
3.3 初始化RestHighLevelClient
public class HotelIndexTest {
private RestHighLevelClient client;
@BeforeEach
void setUp() {
this.client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.23.128:9200")
));
}
@Test
void testInit() {
System.out.println(client);
}
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
}
4. 利用JavaRestClient创建索引库
@Test
void createHotelIndex() throws IOException {
// TODO [hobbit,2023/9/24 14:55]:创建Request对象
CreateIndexRequest request = new CreateIndexRequest("hotel");
// TODO [hobbit,2023/9/24 14:56]:准备请求的参数,DSL语句
request.source(MAPPING_TEMPLATE, XContentType.JSON);
// TODO [hobbit,2023/9/24 14:56]:发送请求
client.indices().create(request, RequestOptions.DEFAULT);
}
5. 利用JavaRestClient删除索引库
@Test
void testDeleteHotelIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("hotel");
client.indices().delete(request, RequestOptions.DEFAULT);
}
6. 利用JavaRestClient判断索引库是否存在
@Test
void testExistsHotelIndex() throws IOException {
GetIndexRequest request = new GetIndexRequest("hotel");
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}
RestClient操作文档

新增文档
- 从数据库查数据,转换成索引库所需要的格式并写到索引库去
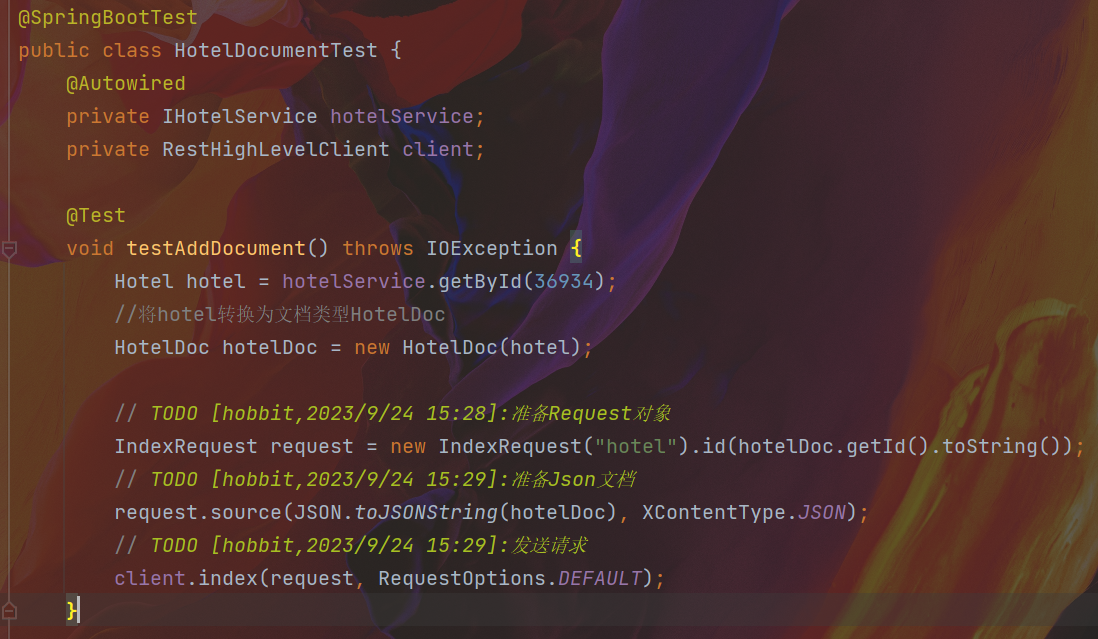
查询文档
@Test
void testGetDocumentById() throws IOException {
GetRequest request = new GetRequest("hotel", "36934");
GetResponse response = client.get(request, RequestOptions.DEFAULT);
String json = response.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
System.out.println(hotelDoc);
}
更新文档
// TODO [hobbit,2023/9/24 15:56]:局部更新,只更新部分字段
@Test
void testUpdateDocumentById() throws IOException {
UpdateRequest request = new UpdateRequest("hotel", "36934");
request.doc(
"name", "7天连锁酒店233(上海宝山路地铁站店)"
);
client.update(request, RequestOptions.DEFAULT);
}
删除文档
@Test
void testDeleteDocumentById() throws IOException {
DeleteRequest request = new DeleteRequest("hotel", "36934");
client.delete(request, RequestOptions.DEFAULT);
}
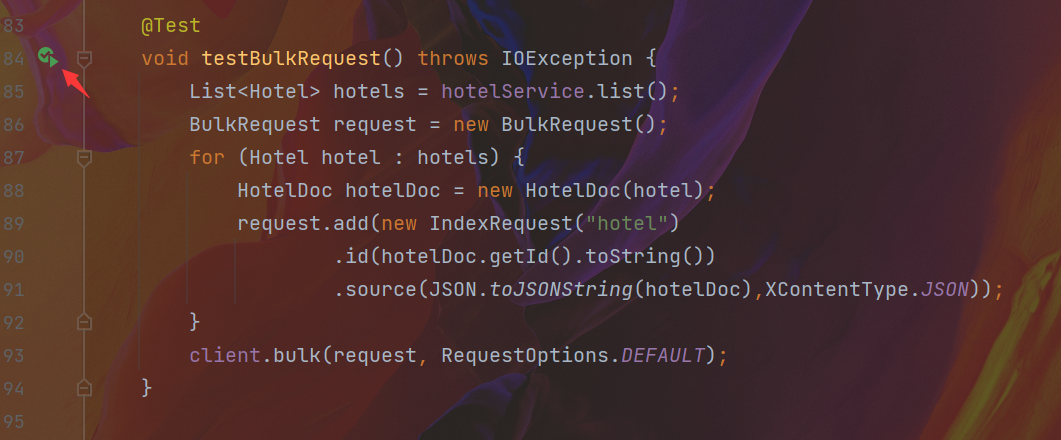
批量导入文档
@Test
void testBulkRequest() throws IOException {
List<Hotel> hotels = hotelService.list();
BulkRequest request = new BulkRequest();
for (Hotel hotel : hotels) {
HotelDoc hotelDoc = new HotelDoc(hotel);
request.add(new IndexRequest("hotel")
.id(hotelDoc.getId().toString())
.source(JSON.toJSONString(hotelDoc),XContentType.JSON));
}
client.bulk(request, RequestOptions.DEFAULT);
}
分布式搜索引擎
DSL查询文档
DSL查询分类及基本语法


全文检索查询
全文检索查询,会对用户输入内容分词,常用于搜索框搜索



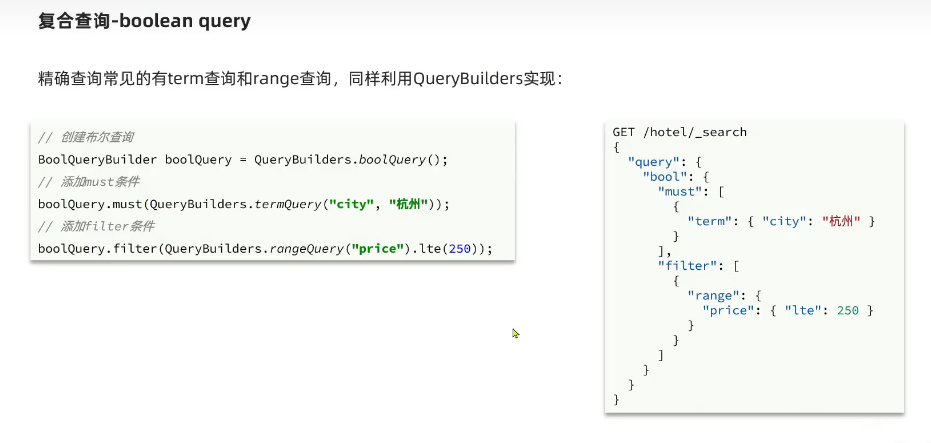
精确查询
精确查询一般是查找keyword、数值、日期、boolean等类型的字段。所以不会对搜索条件分词。
- term:根据词条精确值查询
- range:根据值的范围查询

- range中去掉 gte和lte后面的e就是不等于
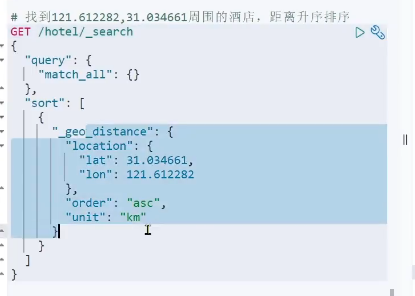
地理坐标查询
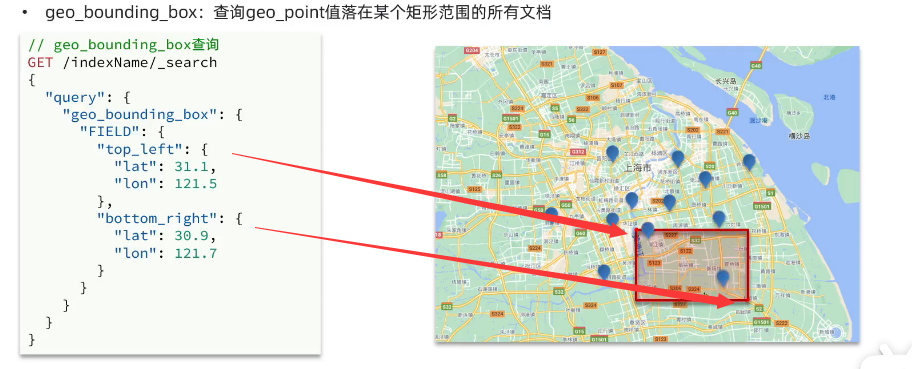
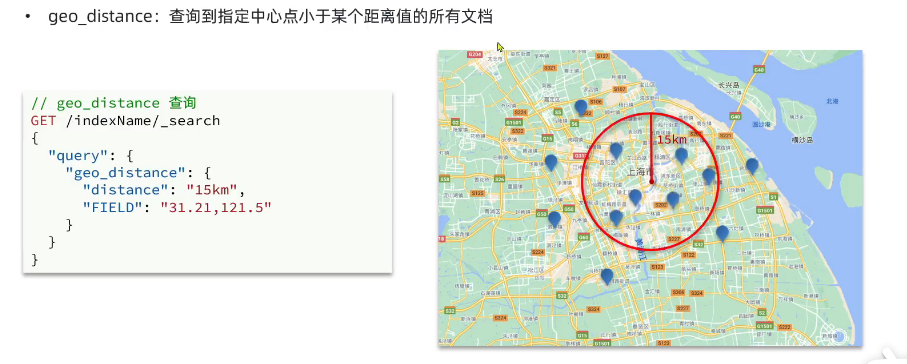
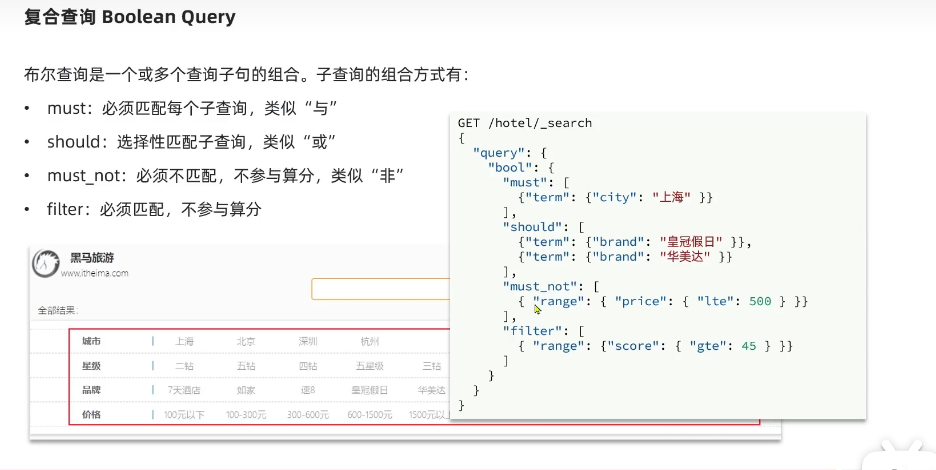
组合查询
- 相关性算分



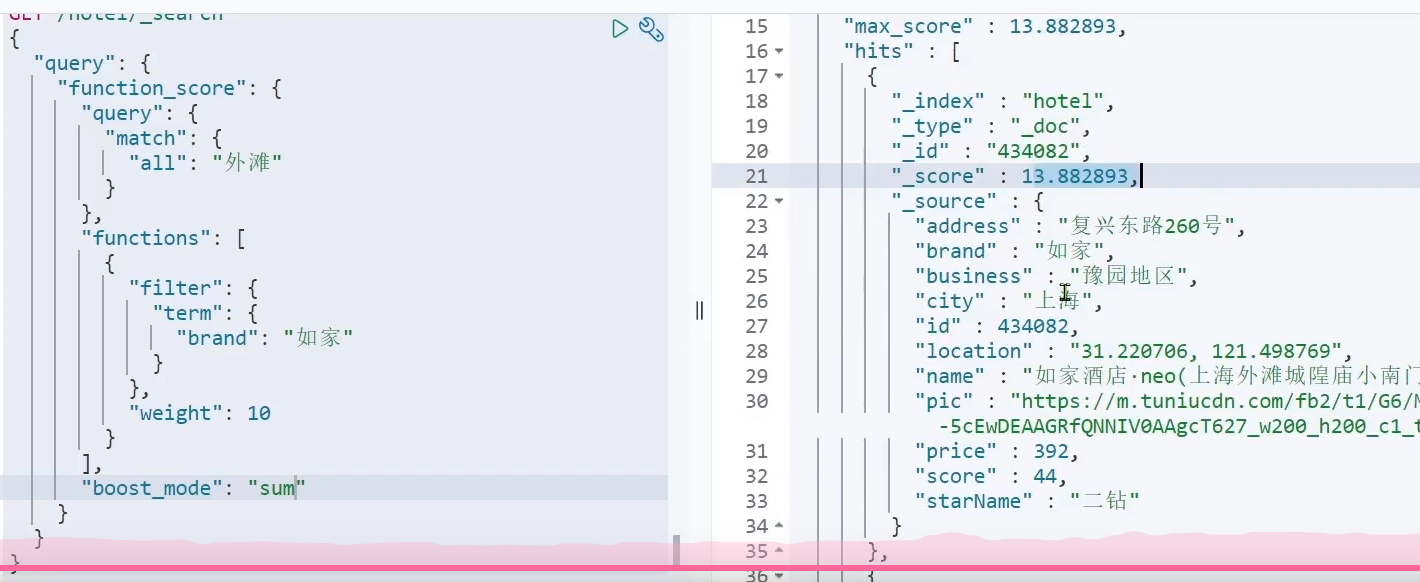

搜索结果处理
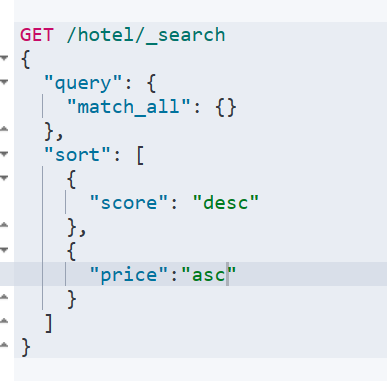
排序


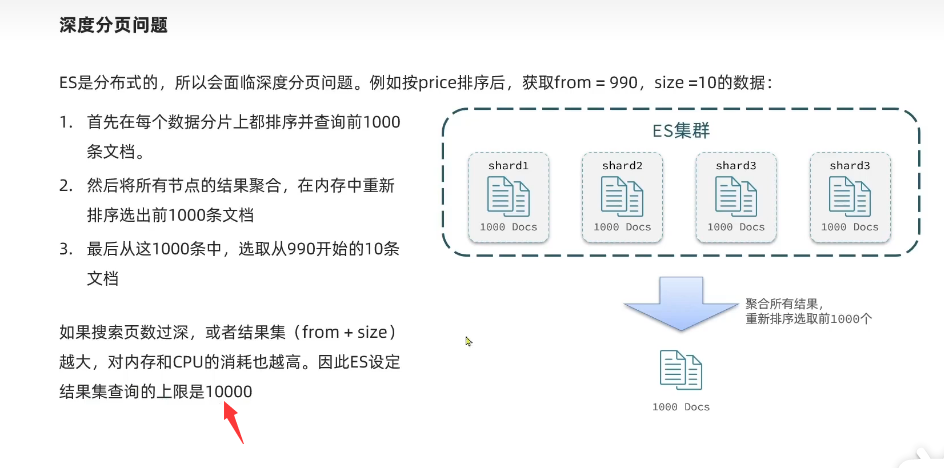
分页


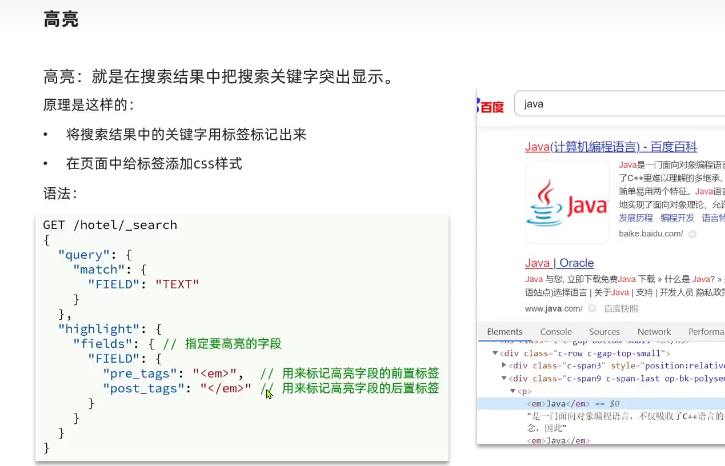
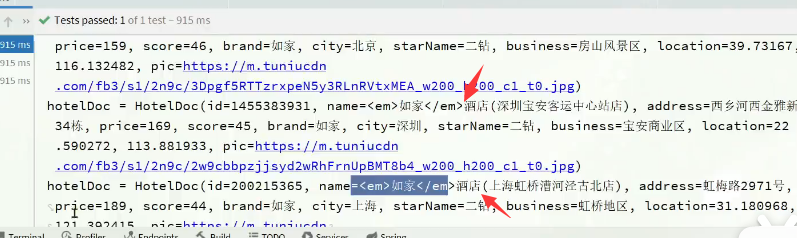
高亮
- 高亮只能用于带关键字的查询(match_all查询就不能高亮)
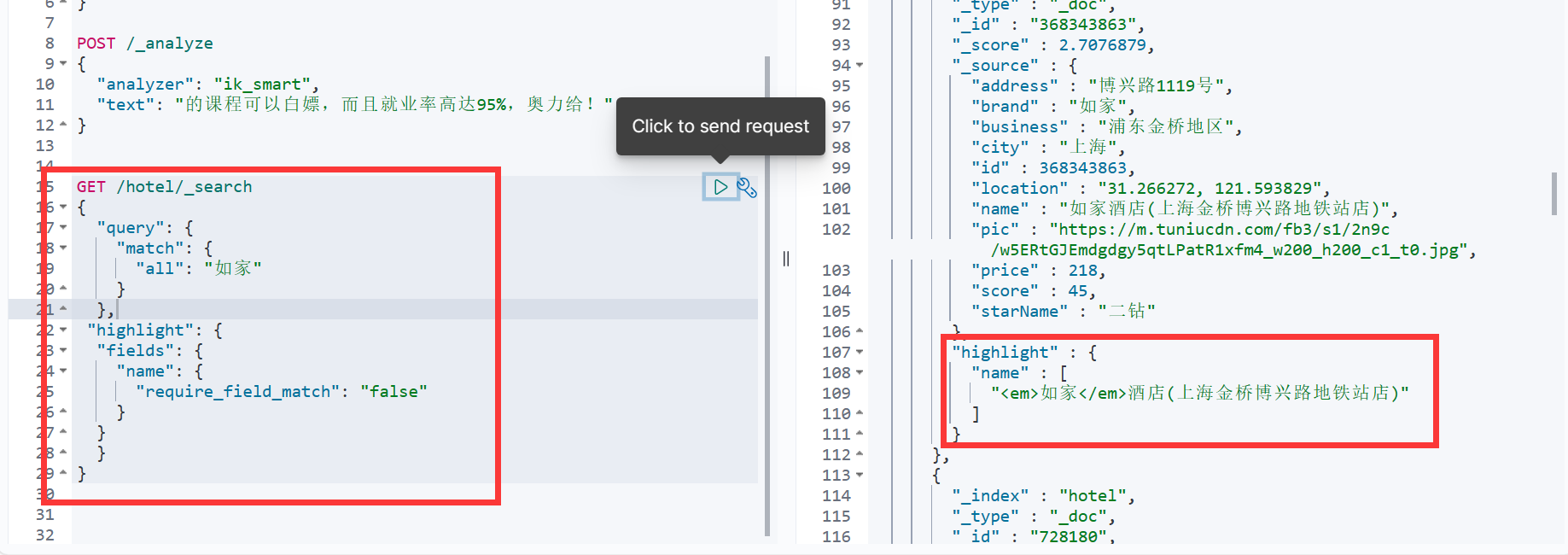
-
高亮字段的默认标签是
<em> </em> -
默认情况下,ES搜索字段必须与高亮字段一致
"required_filed_match": "false"表示不需要字段匹配,即搜索字段与高亮字段不一致时也高亮
RestClient查询文档
快速入门
@Test
void testMatchAll() throws IOException {
// TODO [hobbit,2023/9/25 9:19]:准备Request
SearchRequest request = new SearchRequest("hotel");
// TODO [hobbit,2023/9/25 9:19]:准备DSL
request.source().query(QueryBuilders.matchAllQuery());
// TODO [hobbit,2023/9/25 9:19]:发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// TODO [hobbit,2023/9/25 9:28]:解析结果
SearchHits searchHits = response.getHits();
// TODO [hobbit,2023/9/25 9:29]:获取总条数
long total = searchHits.getTotalHits().value;
System.out.println("总条数:" + total);
// TODO [hobbit,2023/9/25 9:29]:获取文档数组遍历并转换为对象
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
String json = hit.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
System.out.println(hotelDoc);
}
}
查询文档

排序、分页、高亮


- 高亮结果解析↓

黑马旅游案例
D:\Java\_SpringCloud\_7_elasticsearch\hotel-demo
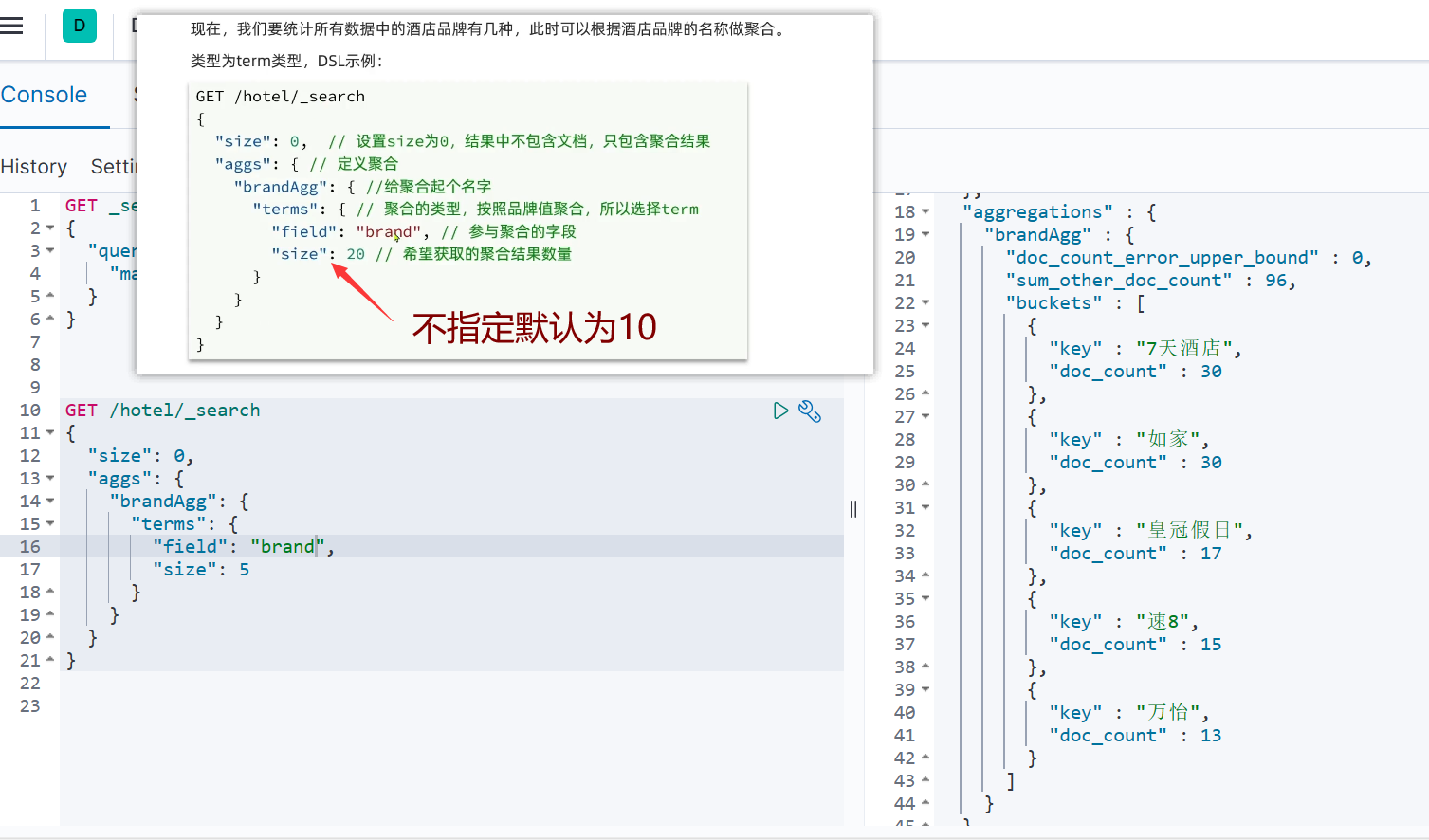
数据聚合
聚合的种类


DSL实现聚合
Bucket聚合


Metrics聚合
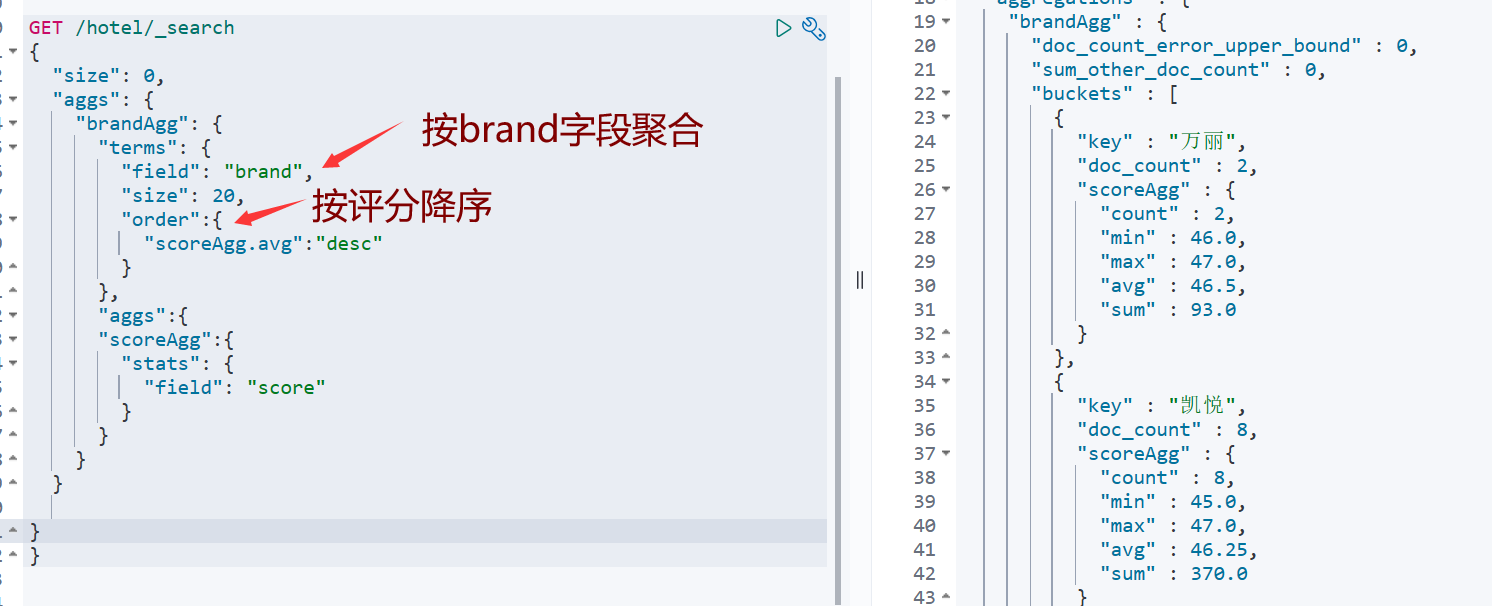
RestClient实现聚合
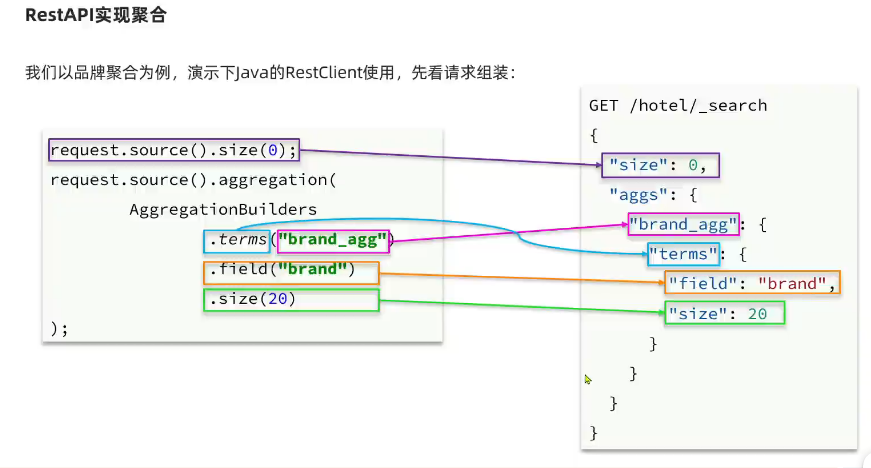
@Test
void testAggregation() throws IOException {
// TODO [hobbit,2023/9/25 16:48]:准备request
SearchRequest request = new SearchRequest("hotel");
// TODO [hobbit,2023/9/25 16:48]:准备DSL
request.source().size(0);
request.source().aggregation(
AggregationBuilders
.terms("brand_agg")
.field("brand")
.size(20)
);
// TODO [hobbit,2023/9/25 16:49]:发请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
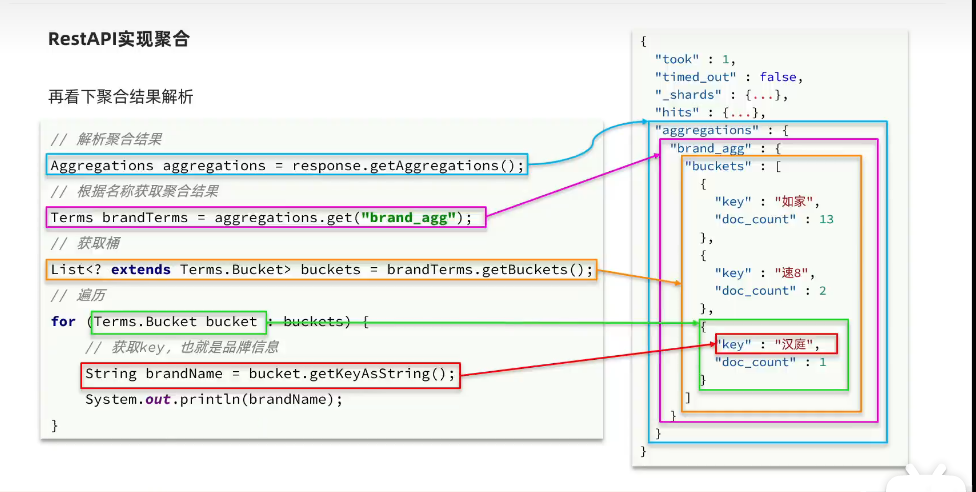
// TODO [hobbit,2023/9/25 16:49]:解析结果
Aggregations aggregations = response.getAggregations();
Terms brandTerms = aggregations.get("brand_agg");
List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();
for (Terms.Bucket bucket : buckets) {
String key = bucket.getKeyAsString();
System.out.print(key + ": ");
long count = bucket.getDocCount();
System.out.println(count);
}
}
多条件聚合
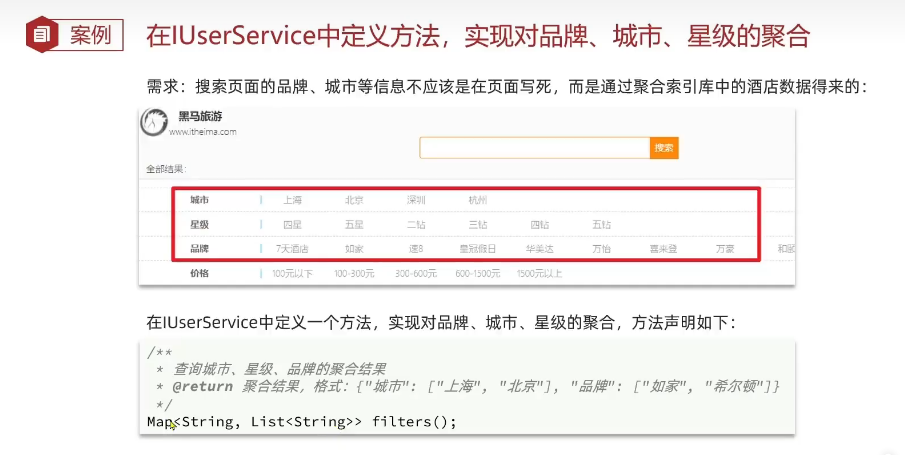
@Override
public Map<String, List<String>> filters() {
try {
// TODO [hobbit,2023/9/25 16:48]:准备request
SearchRequest request = new SearchRequest("hotel");
// TODO [hobbit,2023/9/25 16:48]:准备DSL
request.source().size(0);
request.source().aggregation(
AggregationBuilders
.terms("brandAgg")
.field("brand")
.size(100)
);
request.source().aggregation(
AggregationBuilders
.terms("cityAgg")
.field("city")
.size(100)
);
request.source().aggregation(
AggregationBuilders
.terms("startAgg")
.field("starName")
.size(100)
);
// TODO [hobbit,2023/9/25 16:49]:发请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// TODO [hobbit,2023/9/25 16:49]:解析结果
HashMap<String, List<String>> result = new HashMap<>();
Aggregations aggregations = response.getAggregations();
List<String> brandList = getAggByName(aggregations, "brandAgg");
result.put("品牌", brandList);
List<String> cityList = getAggByName(aggregations, "cityAgg");
result.put("城市", cityList);
List<String> starList = getAggByName(aggregations, "startAgg");
result.put("星级", starList);
return result;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private List<String> getAggByName(Aggregations aggregations, String aggName) {
Terms brandTerms = aggregations.get(aggName);
List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();
List<String> aggList = new ArrayList<>();
for (Terms.Bucket bucket : buckets) {
String key = bucket.getKeyAsString();
aggList.add(key);
}
return aggList;
}
带过滤条件的聚合
@Override
public Map<String, List<String>> filters(RequestParams params) {
try {
// TODO [hobbit,2023/9/25 16:48]:准备request
SearchRequest request = new SearchRequest("hotel");
// TODO [hobbit,2023/9/25 16:48]:准备DSL
buildBasicQuery(params, request);
request.source().size(0);
request.source().aggregation(
AggregationBuilders
.terms("brandAgg")
.field("brand")
.size(100)
);
request.source().aggregation(
AggregationBuilders
.terms("cityAgg")
.field("city")
.size(100)
);
request.source().aggregation(
AggregationBuilders
.terms("startAgg")
.field("starName")
.size(100)
);
// TODO [hobbit,2023/9/25 16:49]:发请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// TODO [hobbit,2023/9/25 16:49]:解析结果
HashMap<String, List<String>> result = new HashMap<>();
Aggregations aggregations = response.getAggregations();
List<String> brandList = getAggByName(aggregations, "brandAgg");
result.put("品牌", brandList);
List<String> cityList = getAggByName(aggregations, "cityAgg");
result.put("城市", cityList);
List<String> starList = getAggByName(aggregations, "startAgg");
result.put("星级", starList);
return result;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private List<String> getAggByName(Aggregations aggregations, String aggName) {
Terms brandTerms = aggregations.get(aggName);
List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();
List<String> aggList = new ArrayList<>();
for (Terms.Bucket bucket : buckets) {
String key = bucket.getKeyAsString();
aggList.add(key);
}
return aggList;
}
private void buildBasicQuery(RequestParams params, SearchRequest request) {
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
String key = params.getKey();
if (key == null || "".equals(key)) {
boolQuery.must(QueryBuilders.matchAllQuery());
} else {
boolQuery.must(QueryBuilders.matchQuery("all", key));
}
// TODO [hobbit,2023/9/25 13:05]:条件过滤
if (params.getCity() != null && !params.getCity().equals("")) {
boolQuery.filter(QueryBuilders.termQuery("city", params.getCity()));
}
if (params.getBrand() != null && !params.getBrand().equals("")) {
boolQuery.filter(QueryBuilders.termQuery("brand", params.getBrand()));
}
if (params.getStartName() != null && !params.getStartName().equals("")) {
boolQuery.filter(QueryBuilders.termQuery("startName", params.getStartName()));
}
if (params.getMinPrice() != null && params.getMaxPrice() != null) {
boolQuery.filter(QueryBuilders
.rangeQuery("price").gte(params.getMinPrice()).lte(params.getMaxPrice()));
}
// TODO [hobbit,2023/9/25 13:46]:算分控制
FunctionScoreQueryBuilder functionScoreQuery =
QueryBuilders.functionScoreQuery(
// TODO [hobbit,2023/9/25 13:51]:原始查询,相关性算分的查询
boolQuery,
// TODO [hobbit,2023/9/25 13:52]:function score的数组
new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{
// TODO [hobbit,2023/9/25 13:52]:其中一个function score 元素
new FunctionScoreQueryBuilder.FilterFunctionBuilder(
// TODO [hobbit,2023/9/25 13:52]:过滤条件
QueryBuilders.termQuery("isAD", true),
// TODO [hobbit,2023/9/25 13:52]:算分函数
ScoreFunctionBuilders.weightFactorFunction(10)
)
});
request.source().query(functionScoreQuery);
}
自动补全
拼音分词器
- 解压
- 上传到虚拟机中,elasticsearch的plugin目录
- 重启elasticsearch
docker restart es
- 测试
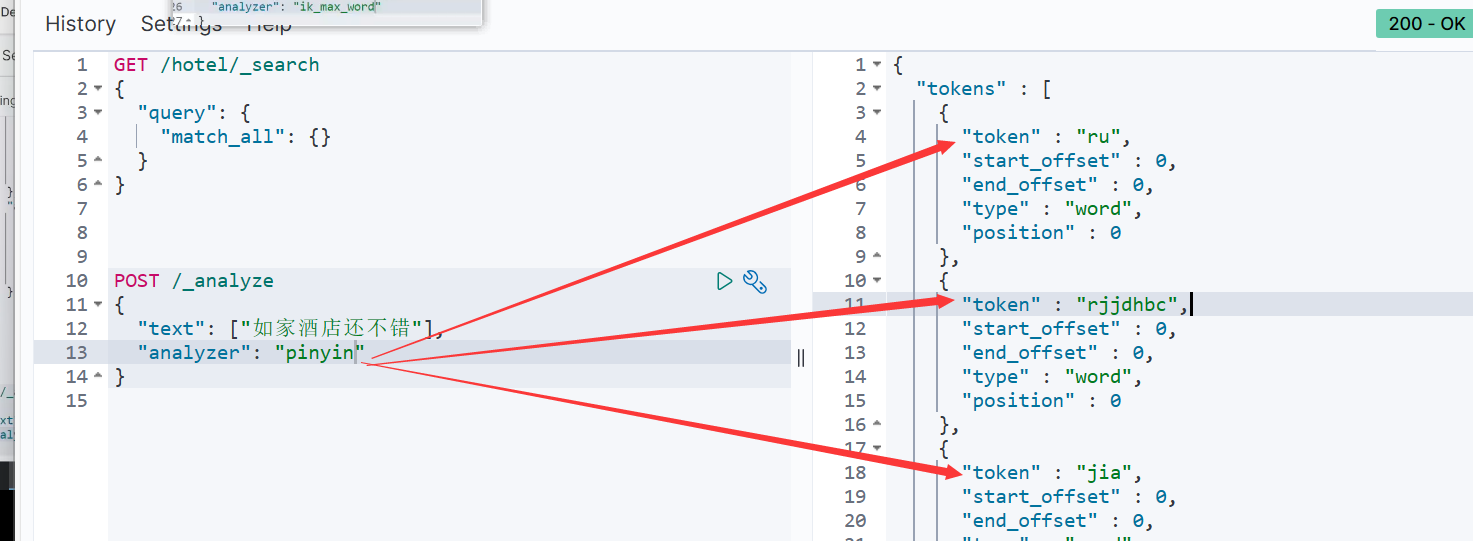
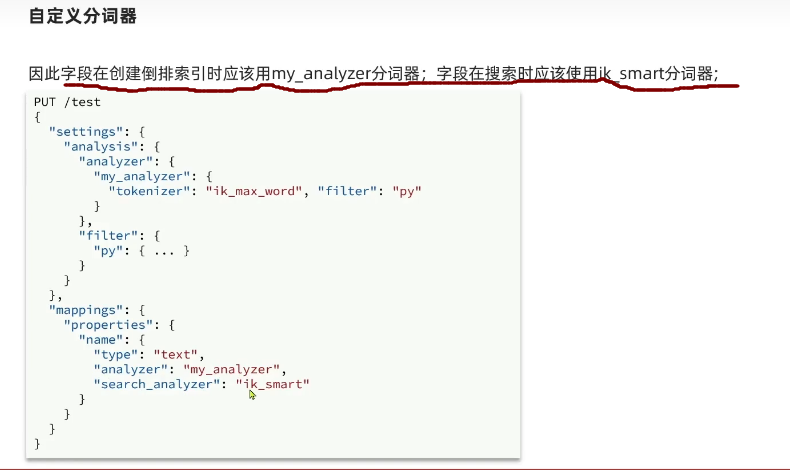
自定义分词器
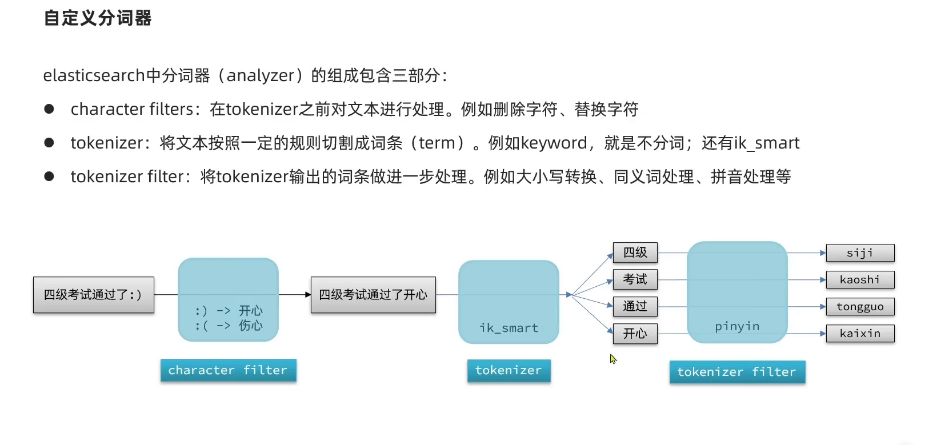
- 我们可以在创建索引时,通过settings来配置自定义的analyzer(分词器)↓
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer":{
"tokenizer":"ik_max_word",
"filter":"py"
}
},
"filter": {
"py":{
"type":"pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "my_analyzer"
}
}
}
}
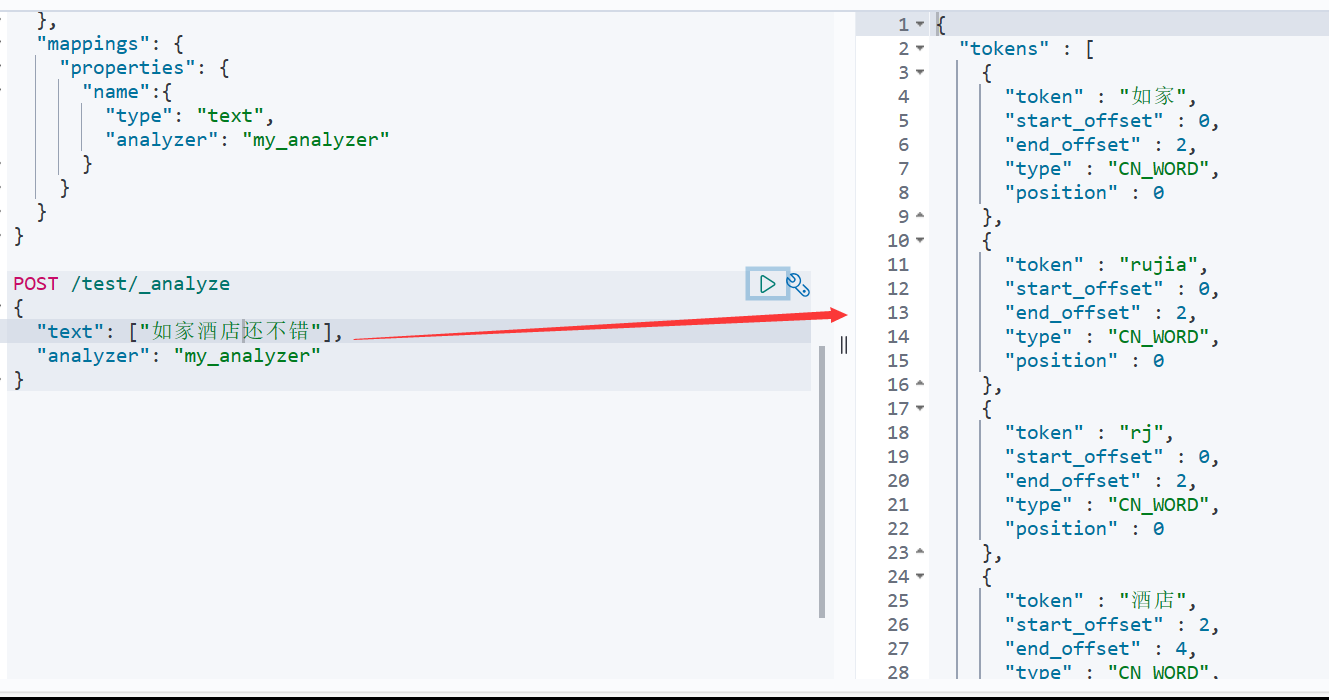

自动补全查询
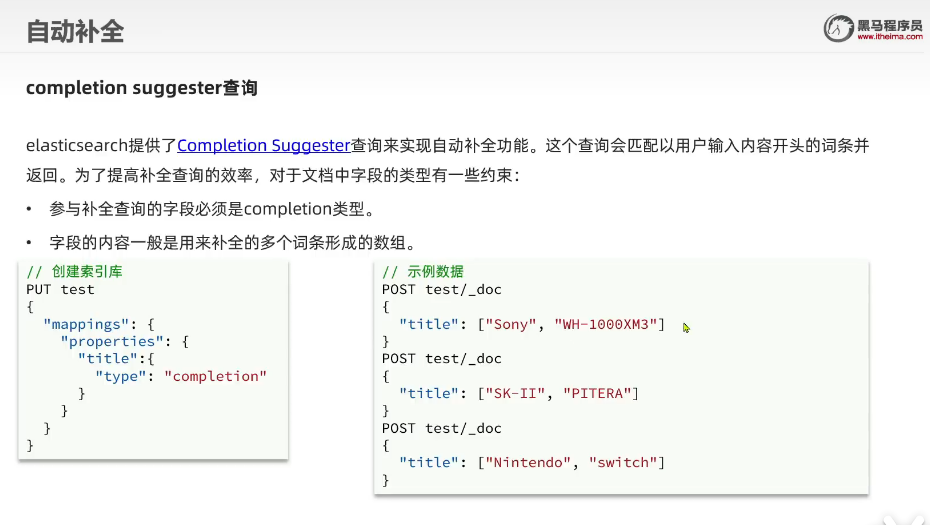

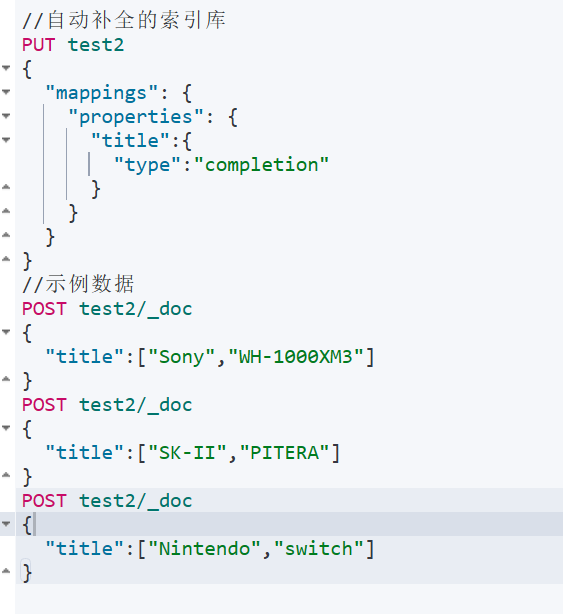
- 测试-准备数据↓
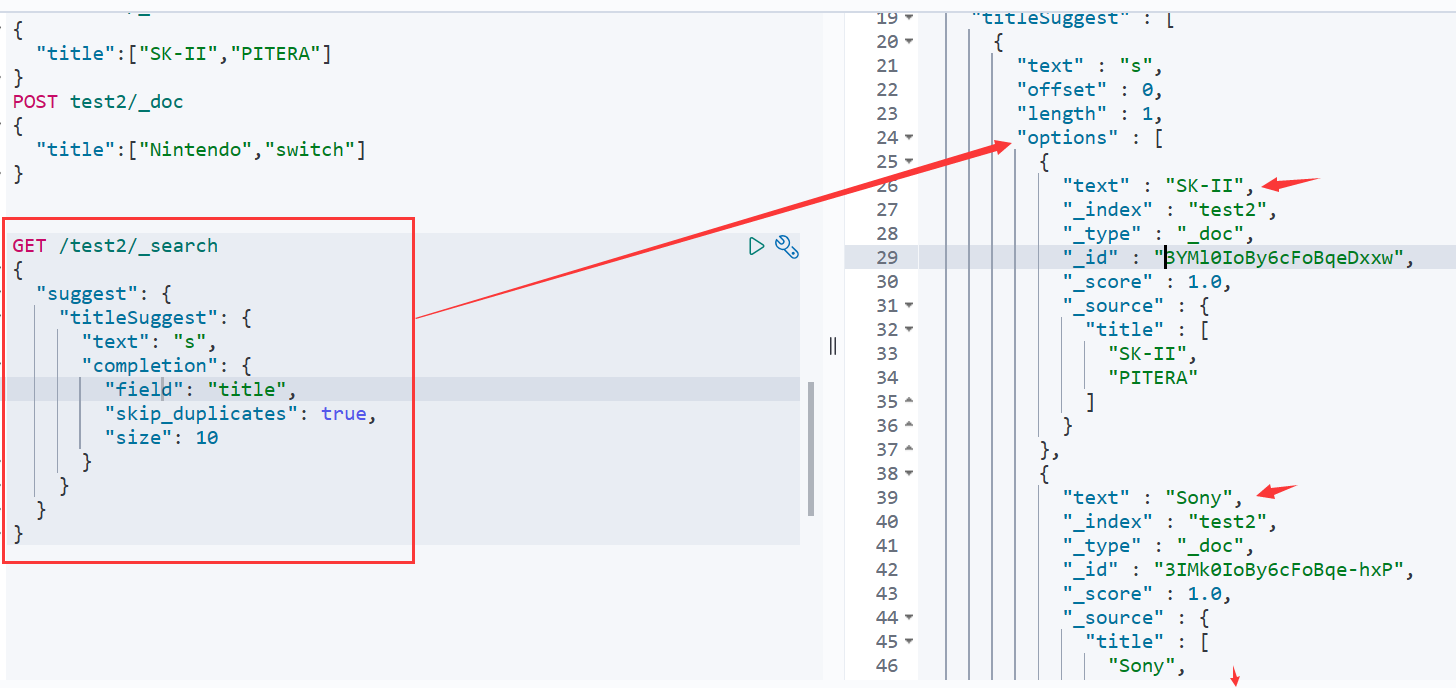
- 自动补全查询↓

实现酒店搜索框自动补全

DELETE /hotel
// 酒店数据索引库
PUT /hotel
{
"settings": {
"analysis": {
"analyzer": {
"text_anlyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
},
"completion_analyzer": {
"tokenizer": "keyword",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"id":{
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart",
"copy_to": "all"
},
"address":{
"type": "keyword",
"index": false
},
"price":{
"type": "integer"
},
"score":{
"type": "integer"
},
"brand":{
"type": "keyword",
"copy_to": "all"
},
"city":{
"type": "keyword"
},
"starName":{
"type": "keyword"
},
"business":{
"type": "keyword",
"copy_to": "all"
},
"location":{
"type": "geo_point"
},
"pic":{
"type": "keyword",
"index": false
},
"all":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart"
},
"suggestion":{
"type": "completion",
"analyzer": "completion_analyzer"
}
}
}
}
- 重新将数据库内容导入到ES中↓
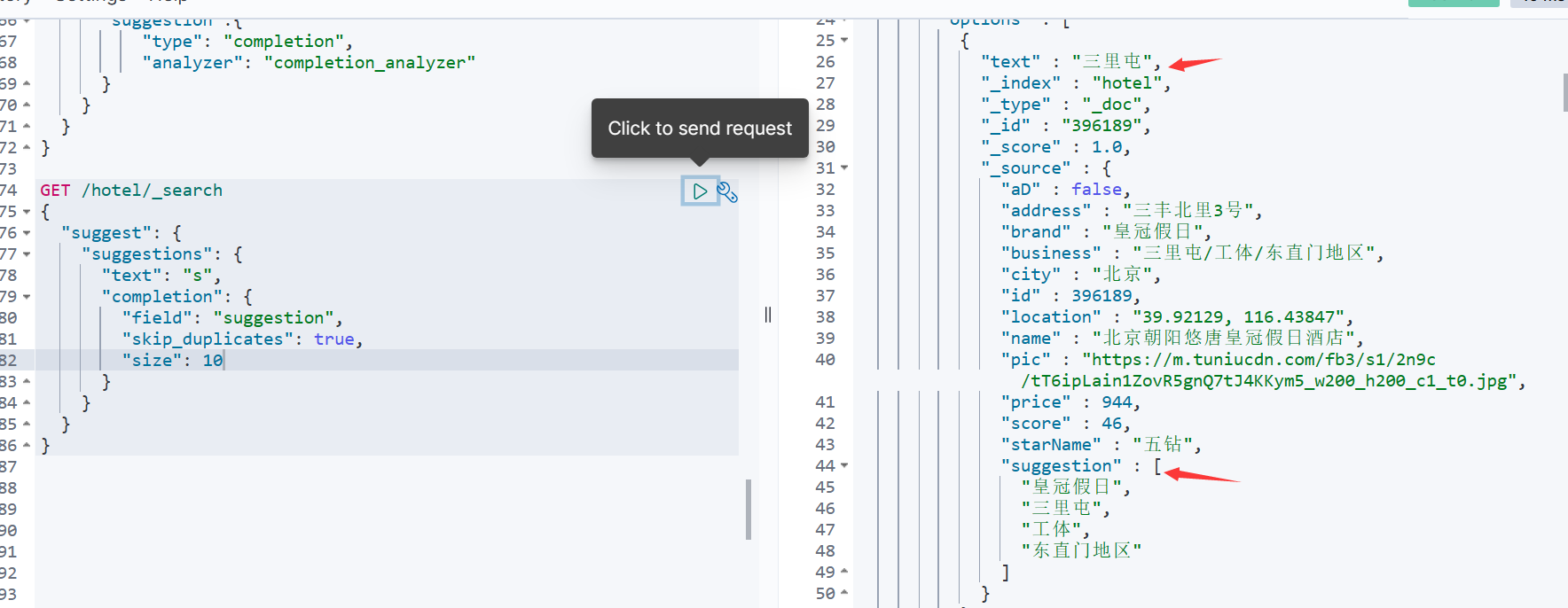
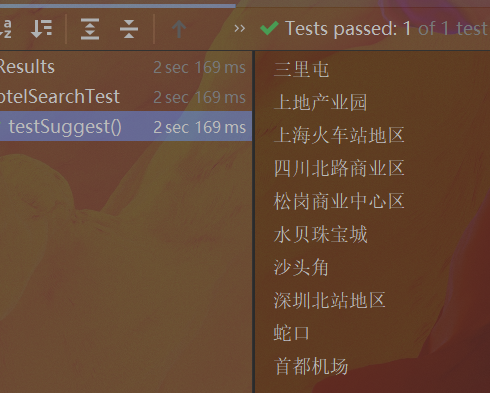
- RestAPI实现自动补全
@Test
void testSuggest() throws IOException {
// TODO [hobbit,2023/9/26 15:01]:准备request
SearchRequest request = new SearchRequest("hotel");
// TODO [hobbit,2023/9/26 15:01]:准备DSL
request.source().suggest(new SuggestBuilder().addSuggestion(
"suggestions",
SuggestBuilders.completionSuggestion("suggestion")
.prefix("s")
.skipDuplicates(true)
.size(10)
));
// TODO [hobbit,2023/9/26 15:01]:发请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// TODO [hobbit,2023/9/26 15:01]:解析结果
Suggest suggest = response.getSuggest();
CompletionSuggestion suggestions = suggest.getSuggestion("suggestions");
List<CompletionSuggestion.Entry.Option> options = suggestions.getOptions();
for (CompletionSuggestion.Entry.Option option : options) {
String test = option.getText().toString();
System.out.println(test);
}
}
- 实现搜索框自动补全
@GetMapping("/suggestion")
public List<String> getSuggestions(@RequestParam("key") String prefix) {
return hotelService.getSuggestions(prefix);
}
@Override
public List<String> getSuggestions(String prefix) {
try {
// TODO [hobbit,2023/9/26 15:01]:准备request
SearchRequest request = new SearchRequest("hotel");
// TODO [hobbit,2023/9/26 15:01]:准备DSL
request.source().suggest(new SuggestBuilder().addSuggestion(
"suggestions",
SuggestBuilders.completionSuggestion("suggestion")
.prefix(prefix)
.skipDuplicates(true)
.size(20)
));
// TODO [hobbit,2023/9/26 15:01]:发请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// TODO [hobbit,2023/9/26 15:01]:解析结果
Suggest suggest = response.getSuggest();
CompletionSuggestion suggestions = suggest.getSuggestion("suggestions");
List<CompletionSuggestion.Entry.Option> options = suggestions.getOptions();
List<String> suggestionList = new ArrayList<>();
for (CompletionSuggestion.Entry.Option option : options) {
String test = option.getText().toString();
suggestionList.add(test);
}
return suggestionList;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
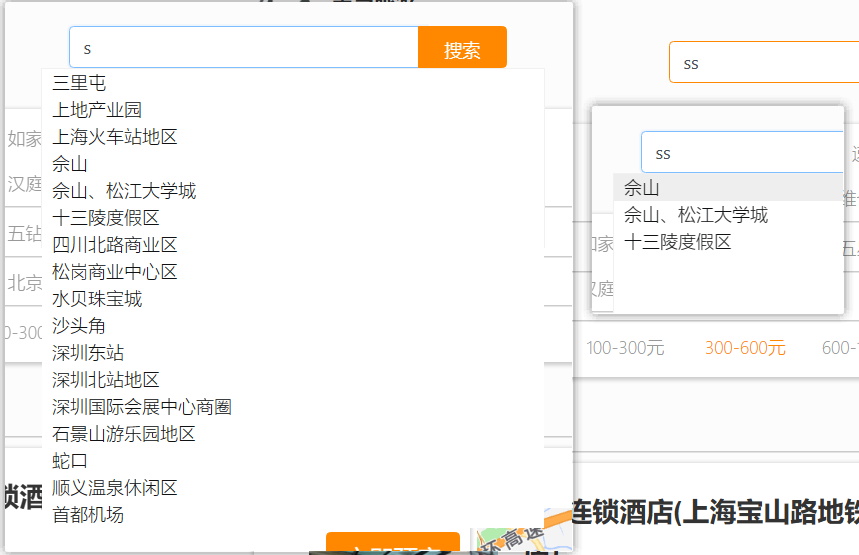
数据同步
数据同步思路分析
在微服务中,负责酒店管理(操作mysql)的业务与负责酒店搜索(操作elasticsearch)的业务可能在两个不同的微服务上。数据同步该如何实现呢?
- 方案1:同步调用(缺点:业务耦合,影响性能)
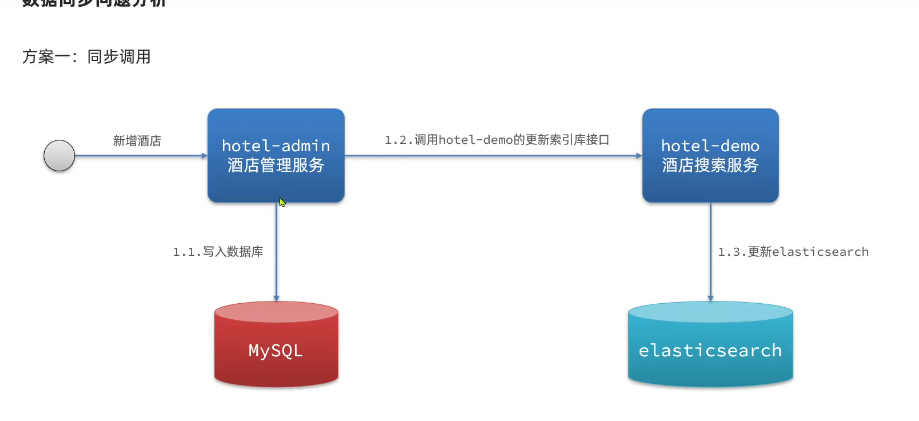
- 方案2:异步通知(依赖MQ的可靠性)
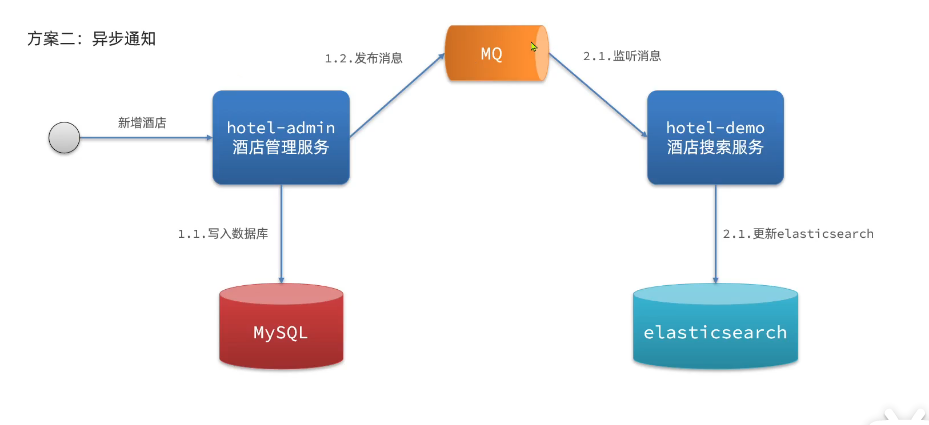
- 方案3:监听binlog(对于mysql压力大,需要引入新的中间件)
- mysql中数据变化了binlog就会变化

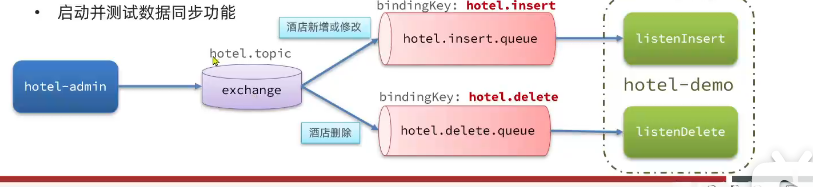
利用MQ实现mysql与elasticsearch数据同步

导入酒店管理项目
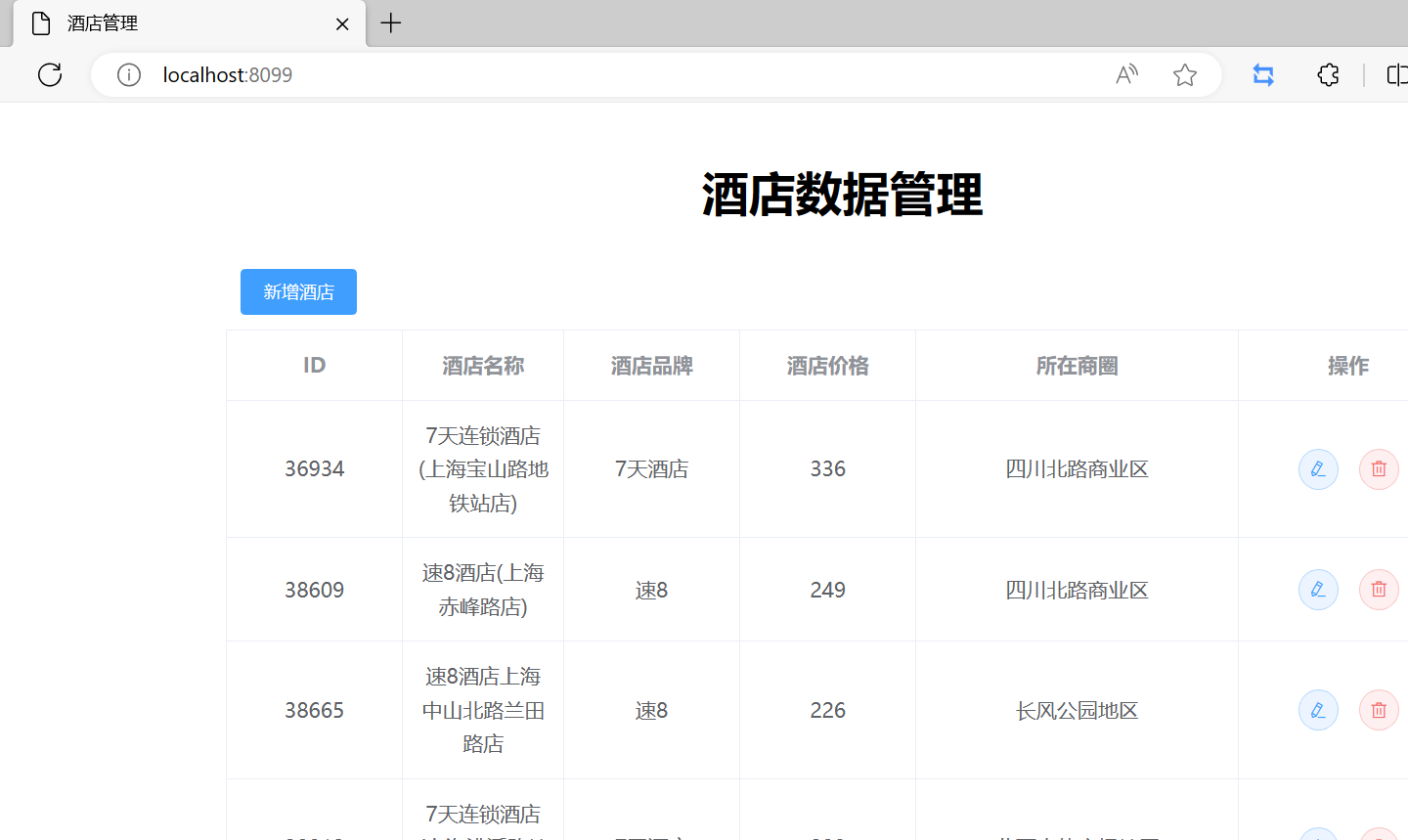
声明队列和交换机(exchange、queue、RoutingKey)
<!--hotel-demo中引入amqp-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
spring:
datasource:
url: jdbc:mysql://localhost:3306/test1?useSSL=false
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
rabbitmq: # 在hotel-demo中配置MQ
host: 192.168.23.128
port: 5672
username:donglin
password:123456
virtual-host: /
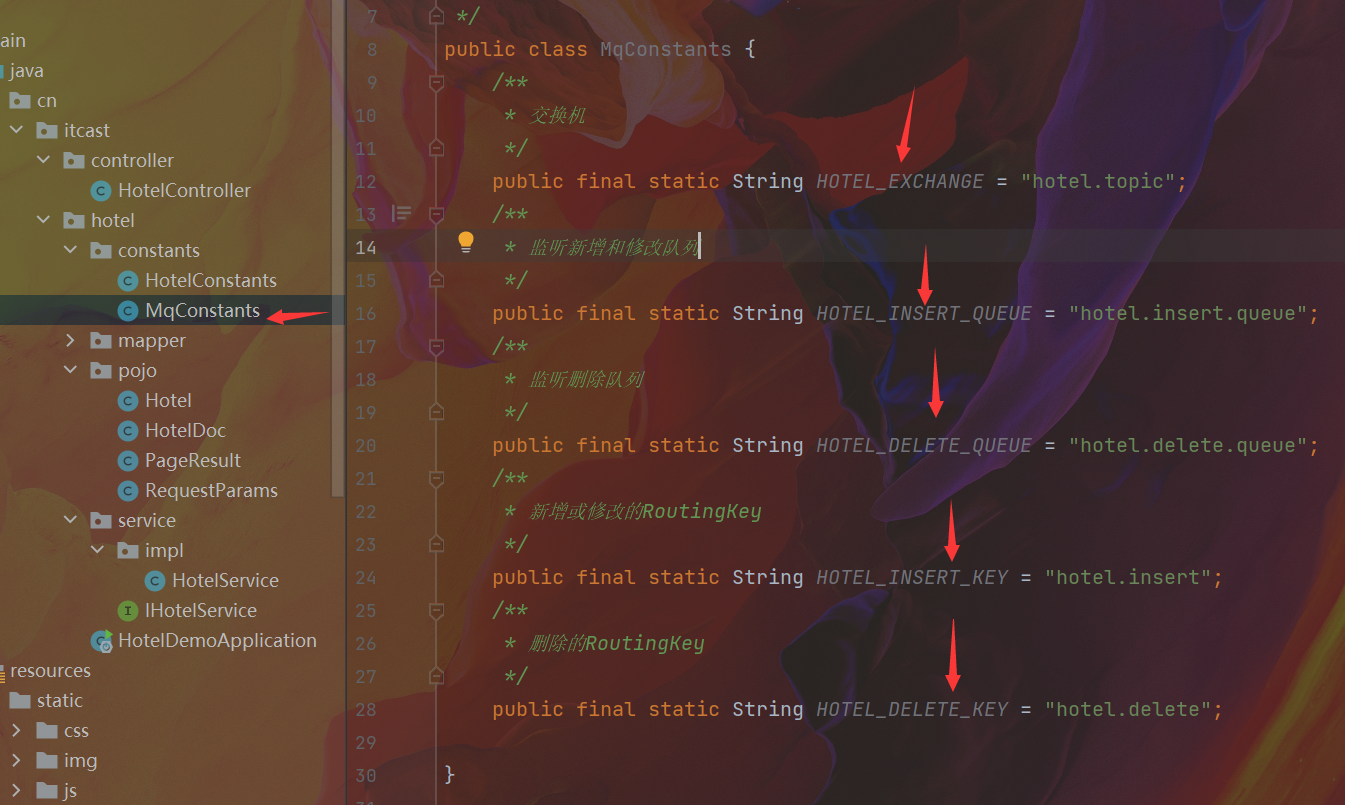
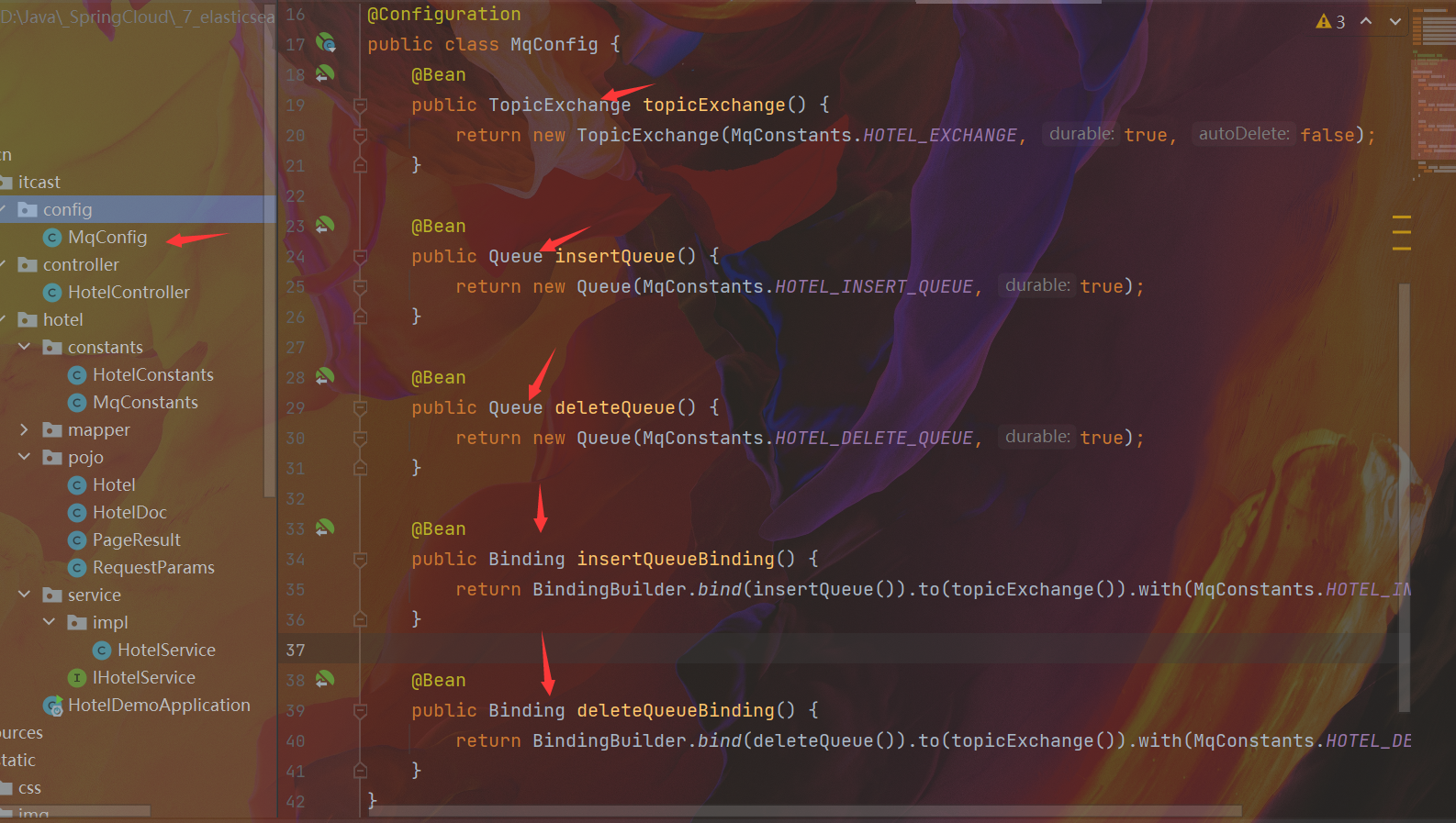
在hotel-admin中的增删改业务中完成MQ消息发送
- hotel-admin中一样要写MQ常量、引入rmqp依赖、配置MQ
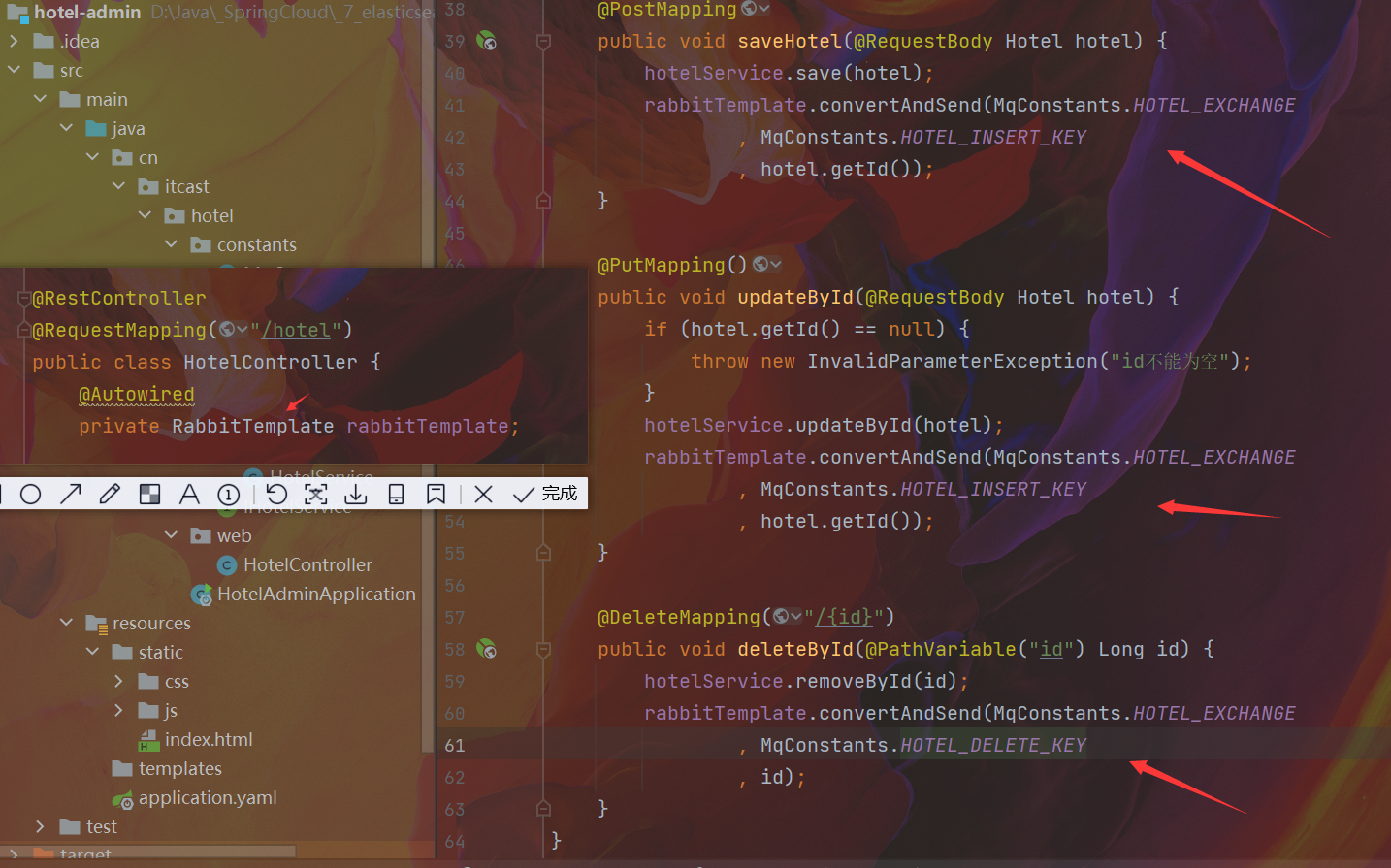
在hotel-demo中完成MQ消息监听,并更新elasticsearch中的数据
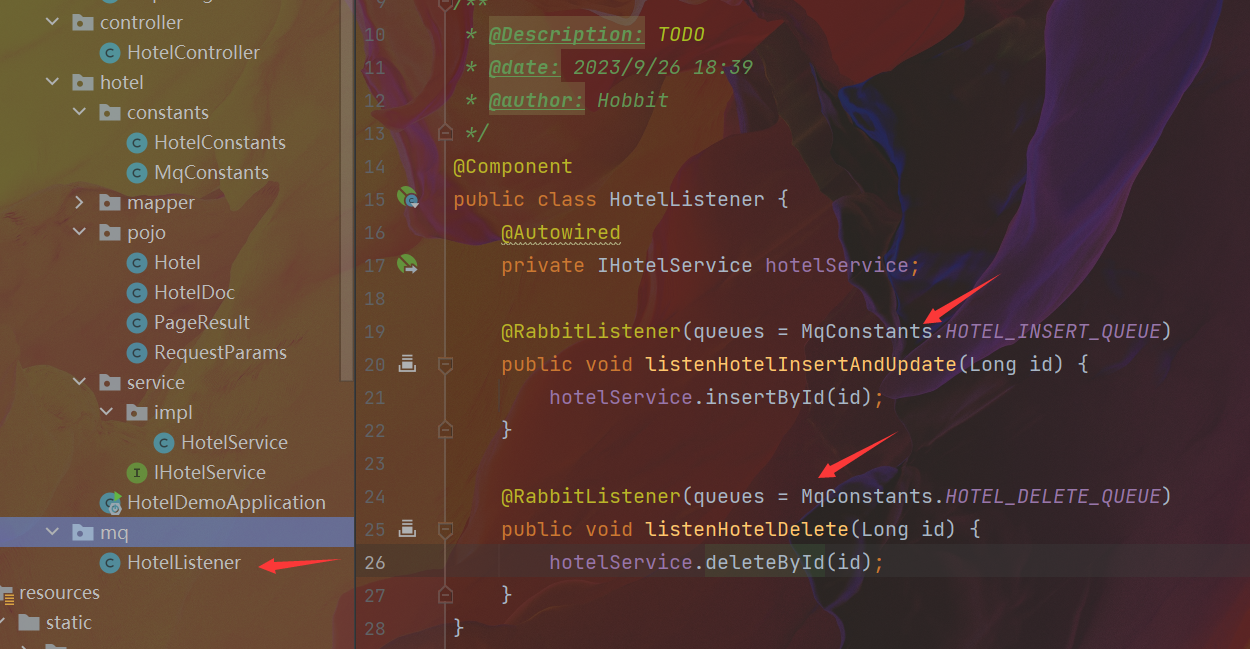
@Override
public void insertById(Long id) {
try {
Hotel hotel = getById(id);
HotelDoc hotelDoc = new HotelDoc(hotel);
IndexRequest request = new IndexRequest("hotel").id(hotelDoc.getId().toString());
request.source(JSON.toJSONString(hotelDoc), XContentType.JSON);
client.index(request, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
@Override
public void deleteById(Long id) {
try {
DeleteRequest request = new DeleteRequest("hotel", id.toString());
client.delete(request, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
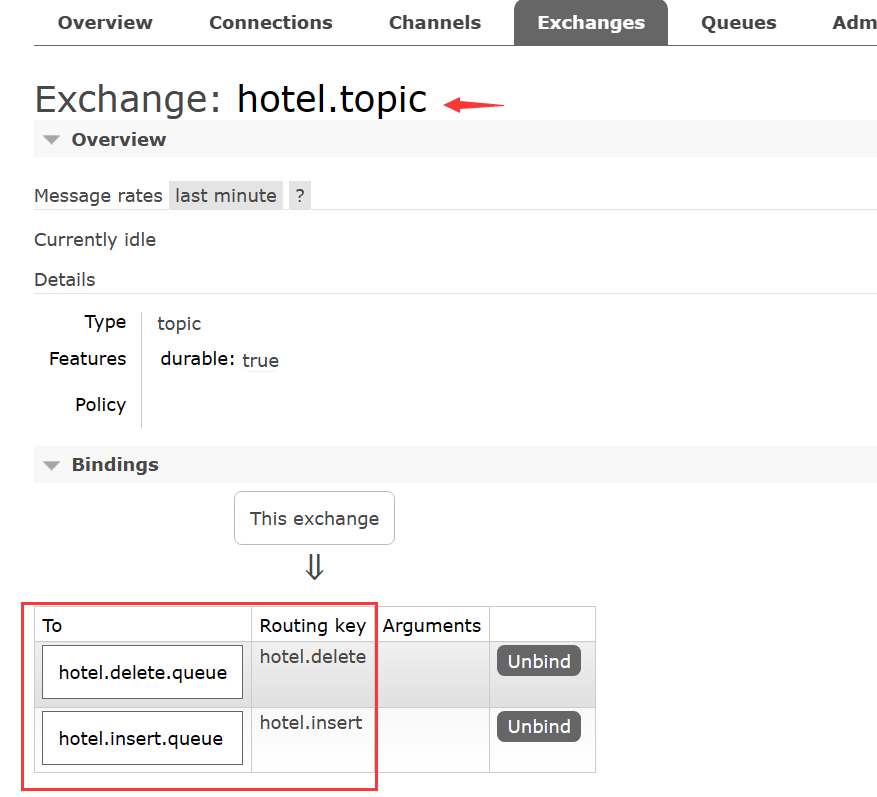
测试数据同步功能
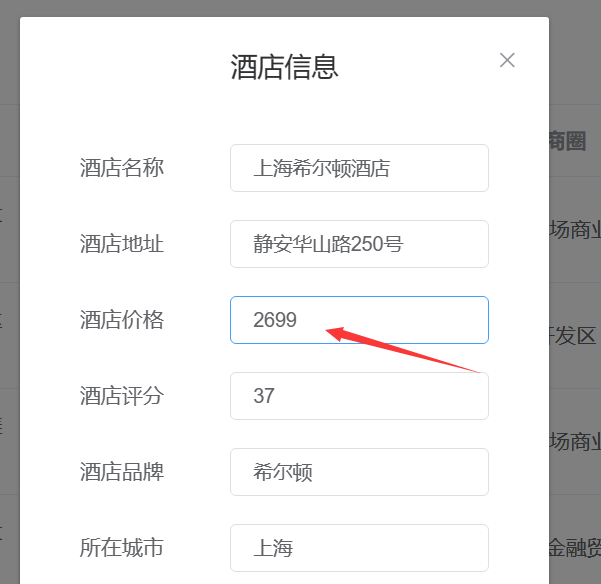
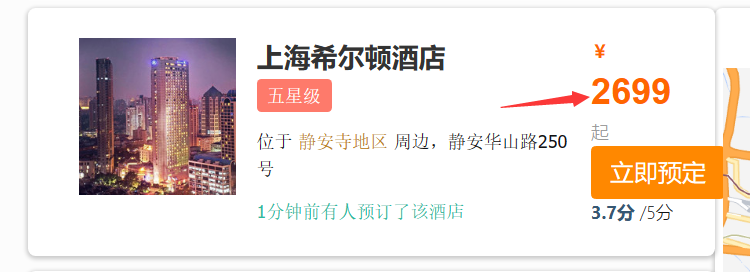
ES集群
集群结构介绍
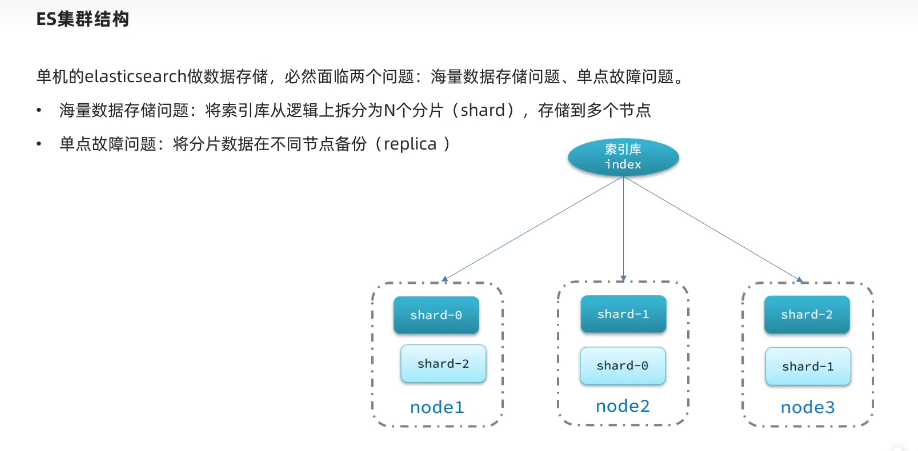
- 主分片和副本分片不能放在同一个结点上
搭建集群
-
学习阶段利用3个docker容器模拟3个es结点,不过生产环境推荐一台服务器结点仅部署一个es实例
-
docker-compose是在一个文本文件中去描述多个容器的部署方式,从而形成一键部署的效果
-
上传docker-compose文件到虚拟机
-
修改linux系统权限
vi /etc/sysctl.conf- 添加内容:
vm.max_map_count=262144 - 执行命令,让配置生效:
sysctl -p
-
运行docker-compose文件:
docker-compose up -d -
kibana可以监控集群,不过最新版本需要依赖es的x-pack,配置比较复杂,推荐使用cerebro来监控集群状态
- 解压.zip文件,双击bin目录下的cerebro.bat即启动了服务,然后访问:localhost:9000
- 然后输入虚拟机上es结点的位置:
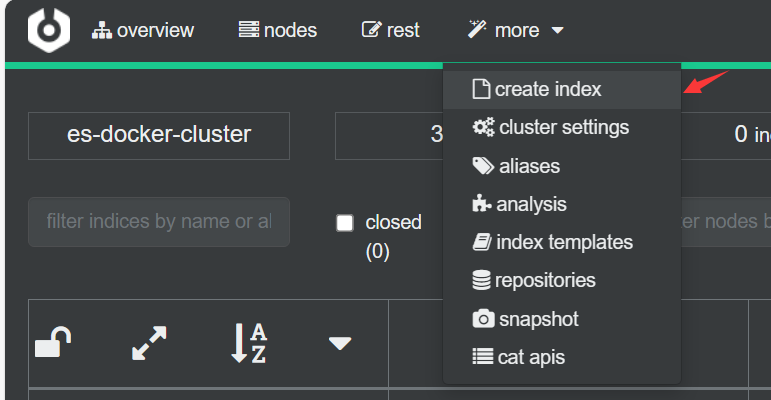
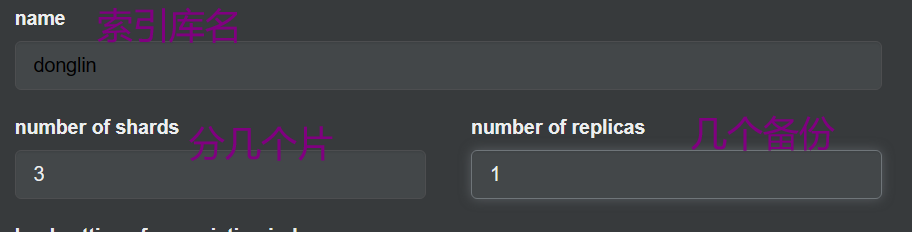
http://192.168.23.128:9200(9201、9202也可以) - 利用cerebro创建索引库
![image-20230927145848430]()
![image-20230927150125187]()
由于使用cerebro创建索引失败,一直没找到原因导致后面实操进行不下去了/(ㄒoㄒ)/~~,所以ES集群的笔记直接参考黑马给出的笔记↓

 浙公网安备 33010602011771号
浙公网安备 33010602011771号