

在我的眼中,过去数年间的多股潮流,都指向同一个方向,现在该到将它们总结归纳的时候了。这篇文章没有什么新奇观点,只是将我的思考与观察做一个概括。我不自禁要将心中的图景描绘出来(即便这幅画的背景全由我的痛苦教训涂抹而成)。这就开始吧。
多年忽视分块即使过了16年,我依然清楚记得[Booch OOAD]书中讨论如何使用分层与分块(有的读者可能更偏好"模块"这个同义词)。那时候我开班讲授一门面向对象分析与设计的课程,这本书是教材。我感觉讨论分层很容易,因为当时接触甚多(后来仍然深受影响,下一节会谈及),但要讨论分块就有点难。
在我参与的实际项目中,我们确实一直采取分块的做法,但讲授的时候很难用短小的例子示范分块。而且就我记忆所及,我们采取分块只是出于技术上的限制,并不像分层那样是自然而然地发生的。.
分块没能“物尽其用”的感觉一直伴随着我,我也就听之任之。
滥用分层2001年写第一本书[Nilsson NED]的时候,我对分层的盲目溺爱到达顶峰。图1的分层示意图已经是简化过的版本。
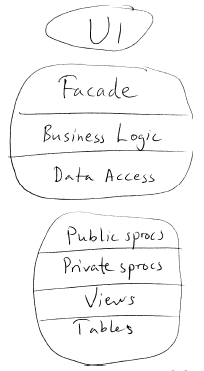
图1. 过去的典型分层(简化版本)
图1可见,中间层包括了Façade层、业务逻辑层和数据访问层。在数据层还有公共存储过程(sproc)层、私有存储过程层,有时候数据表之上还有视图层……(UI部分也是分层的,可想而知……)。
我把这种分层方案称为我的“默认架构”,顾名思义,我每次着手新项目都以此作为出发点。当然具体的架构形态随着时间会有所变化,但重点是我先入为主地认为项目都离不开这种严格的分层方案。
我观察到:
- 当数据库Schema、视图、私有存储过程、公共存储过程、数据访问层,一层层手工编写下来((为了保证一切都恰如意料,比如性能)),很多时候,就没有多少时间花在业务层上了。于是业务层往往非常薄,不外乎做些左手交右手的工作,捎带若干占位用的注释。
- 由图1可见,数据存储受到重重防卫,从UI到数据存储经过的保护层不是一般多。然而在多数情况下,由于使用Recordset模式完成从数据库到UI的数据传输,造成数据库Schema严重暴露。而当UI完成修改回传数据的时候,差不多就是直接写入到数据库了……所谓保护不过如此。
- 引入每一层的依据是“有比没有好”,而不是因为“证明有需要”。违反YAGNI原则的绝佳例子,对吧?
然后当有必要的时候才增加层次,比如需要用户界面的时候才会加上UI层。只要合适,UI层甚至可以直接叠在领域模型之上。要是不合适,再考虑别的需要。
接下来,如果我们希望把领域模型持久化到关系数据库,才把这部分需要放入场景中加以考虑。通常用一个对象/关系映射就能解决得很好,大约能自动解决80%的领域模型到数据库的数据映射需求。请看图2。
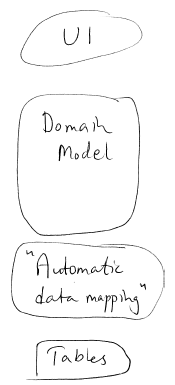 图2. 时下典型分层一例
图2. 时下典型分层一例我还尝试令数据库Schema成为领域模型反映出来的“结果”,自动生成数据库Schema。这样做意味着避免了大量繁重的工作,让我们有时间投入到真正关心的部分——领域模型本身。(同样的做法还可以用到UI上。)
如此一来,我不用再拘泥严格的分层方案,转而把精力集中于寻找恰当的分块。又由于整个解决方案被分为若干小块,从而每一个分块的分层形式可以更加灵活,因为规模更小了。
按技术拆分团队写上面一节的时候,我想起了2005年在挪威Lillehammer举行的软件架构研讨会[Fowler LayeringPrinciples]。当时我们在会上讨论如何把大的团队拆分成若干小团队。
无论那次会议之前或之后,我都有拆分团队的经验,多次拆分中既有按技术拆分的,也有按功能拆分的。我尤其记得一个项目,对其中一名团队成员来说,按功能拆分是失败的,因为他没有什么经验,所以几乎每一个方面他都不得不苦苦挣扎。.
在另一个项目中,按技术拆分看起来非常成功,不过那个项目的成员都很有经验。即使在这个成功项目里,也有很多情况如果按功能拆分会取得更高的效率。比如跨单元的小改动,牵涉到的人可以更少。
总而言之,我偏向按功能拆分团队。每个人肯定有自己特别擅长的部分,但如果不用协调及等待其他人完成相应的工作,那么大部分工作都可以更快地完成。
企业领域模型前些年很流行建立整个企业“一统天下”的数据模型。背后的想法是如果一朝找到并描述出这样的数据模型,就能从中创造出巨大的业务价值。于是传达给业务人员的是这样的信息:
“现在给我们两年时间不受干扰,到时候我们会交给你一个定义好的模型,你想要的一切都能不费吹灰之力就创造出来。”
依我之见,“企业数据模型”是大大失败了。原因肯定不少,但下面这几点可能在最重要之列:
- 即便是中等规模的企业,数据模型的规模也过于庞大。
- 数据模型试图用静态的方法描绘一个动态的目标。而且描绘一个庞大的目标比小的目标要困难得多。
- 大模型或多或少要作一般化的处理,并因此失去上下文信息。
我个人强烈相信大的任务要一口一口地啃,而上下文是王道。
A前面说过,我认为建立企业数据模型的尝试常常以失败告终。现在我又发现一种有点讽刺的情形——还有项目几乎在重复同样的尝试,只不过这一次换成了“企业领域模型”。论据没变,我想结果和造成结果的原因也不会变……
公平来说,更常见的情况倒不是真的追逐“企业领域模型”,而是想建立单一的大型领域模型。此外,团队不时发现有需要切分大的领域模型,但又发现不容易找到满意的方案。
无论如何,我都强烈建议当领域模型出现增大迹象的时候,将它分块。还有别忘了模型是有上下文的。
很有趣,我还听闻一些非常大的SOA项目采取的第一个步骤就是打算建立一套“企业文档模型”。它会比企业数据/领域模型更成功吗?要是打赌的话,我宁愿下注在另一边。
整合数据库就算有意避免巨型的单一领域模型,把模型隔离成几个部分,每一个部分还是有可能膨胀到相当规模。发生这种情况的时候,往往会发现数据库并没有分块。各个领域模型置于同一个数据库之上,也就是共用一个整合的数据库,见图3。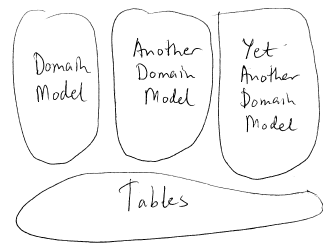 图3. 分块的领域模型,使用整合数据库
图3. 分块的领域模型,使用整合数据库
把多个领域模型置于单一数据库之上,只是整合数据库的其中一种情形。实际上跟多个独立应用共享同一个数据库是一样的。类似情况可谓屡见不鲜。
很不幸这样的安排给维护造成了极大的负担。任何影响到数据库Schema的改动都必须同步修改相应Schema的所有消费者。消费者越多,情况越糟。往往造成改动被限制到最低程度,很可能进而导致从代码中榨取的业务价值大大减少。
大胆地说一句,如今在我眼中,整合数据库是一种反模式。啊,总算说出来了,感觉真好。
那么,有什么别的办法呢?我认为领域模型的分块应该一直延续到数据库,让数据库也遵循同样的分块方案。这种与整合数据库[Fowler IntegrationDatabase]相反的模式称为单应用数据库[Fowler ApplicationDatabase],见图4
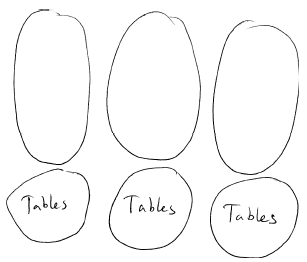
图4. 分块的领域模型,使用各自的单应用数据库
分块之间的通信是通过领域模型之上的服务完成的,不允许抄捷径直接访问其他领域模型的应用数据库。这意味着可以(也通常会)有效地将不同的应用数据库部署到不同的服务器上(或者部署到云中)。
一般认为报表是整合数据库的优势所在。要是换一种方式去处理报表,可以把它看成一个独立的应用,有着自己的数据存储。数据从其他分块搜集而来。其中一种办法是将每个分块都看作一个提供事件源的应用[Fowler Events],让那些事件源都吐出报表应用感兴趣的事件就可以了。
顺便一提,上面的讨论令我记起曾经为ADDDP[Nilsson ADDDP]写过一段文字[Nilsson Bricks](不过最终没有放进书里),介绍另一种应用数据库的用法。不过当时写作的重点落在性能,而非可维护性。文中我介绍了如何根据系统不同部分的特点,让系统发挥最大的功效。
再顺便一提,一定要读一读Greg Young写的DDDD系列文章[Greg Young],他的精彩作品也可以归到这个主题之下。他建议严格切分读和写,籍此取得非常高的可伸缩性等等成效。
整合的UI论点其实差不多,只不过用到UI上没有整合数据库vs.应用数据库那么有力。与其用一个UI套上几个服务,何不让每个服务都有自己的UI,然后将不同的UI用一个UI容器框架集成起来?见图5
图5. UI也分块
这样一来,某个分块的开发者可以全方位地处理问题,从UI一直到存储,不必与其它团队同步。对实际生产率的潜在影响是巨大的。
巨型的团队
经常有人向我们求助,抱怨说他们100人的大团队没办法达到期望的生产效率。
每一次,我都得到同样的结论。不要那样做!100名开发者在同一个团队里,太可怕了,失败风险太大了。即使你再加20个人!
虽然已经出版了30年,读过《人月神话》[Brooks MMM]的人还是少得出奇。真糟糕。(书名“人月神话”的意思是,向一个进度落后的项目增加更多开发者,只会让它更落后。书里还阐述了很多重要的思想。)
所以,就算退一步说你真的有一个规模庞大的问题要解决,你也真的需要100名开发者。请一定要小心谨慎地将大团队分成若干个小规模的、尽可能相互隔离的团队,以便每个团队能够全速运行。
但是当你把大团队分成比如说100个新团队的时候,显然不会因此就消灭了复杂性。例子里面分成10-20个团队比只有1个团队好,并不表示分成100个会更好。请注意平衡。
SOA与松散耦合
说到平衡,两年前我曾经很不理解SOA的一些说法,还写了博客帖子[Nilsson SOA-Qs]请教答案。
我不理解的其中一点是为什么要极端的细粒度。为什么不用“定界上下文(Bounded Context)” [Evans DDD]的思维来看待服务呢,为什么需要粒度细到只有一行代码的服务……
Jim Webber在一篇文章里[Webber Anemic Service Model]讨论过这个问题,我认为他说得很有道理。对松散耦合的关注成了唯一的决定因素,以至于忘了搭配上它的好朋友——高内聚,才导致出现令我困惑不解的奇怪说法。
所以,我把前面讨论的分块看作是“做对了的SOA”。
强迫一种风格
最初我把标题定为“强迫一种信仰”,但又顾虑到Google带来的很多人会失望。我在这里谈的风格/信仰,是指我们当中有很多人喜欢思考和讨论TDD、DDD、BDD、模式、重构、干净的代码等等。但世上还有更多开发者并不同意我们所说的是“唯一的道路”。
有时候会采取的解决办法是完全不理会实际情况,强迫所有的开发者都用同一种风格。会发生什么事呢?我猜下面这几种情况会很常见:
有的开发者会非常低效。
低效的开发者还会很不开心。
最后整个团队围绕的风格是所有成员的“最小公分母”。
于是当初赞同强迫推行那种风格的开发者,现在也变得低效和不开心。
能保持一致是好的,但不能不惜代价去保持一致。实际上我觉得很多时候让不同的分块用不同的风格开发,反而有好处。不同开发者之间的技能差异是其中一个原因。还有另一个经常被忽视的原因,不同的分块当然是有差异的,所以相应地采取不同的风格反而有利。比如有的分块从领域模型方式中肯定得不到什么好处,那么不采取领域模型的路线也没关系,实际上也建议不要那么做!
即使放宽了对分块内部的约束,你还是可以(也应该)对外部表现设立严格的要求,比如要保证自动化测试成功。
我意识到以上做法违反了集体代码所有制的原则,因为人们都圈在自己的分块里。在分块内部,(如果该分块选择了集体所有的风格)肯定是代码集体所有的。
对了,在单个分块内,我认为应该强迫一种风格。
变化率差异
这件事情你可能觉得显而易见,不过我还是要特别指出来:不同分块的变化率可能有极大的差异。在数据库驱动的项目里,有句话在项目前期的会议上经常听到,我也常常拿来开玩笑:
“我们已经定好了数据库Schema,现在可以开始干活了!”
没有取笑谁的意思,我自己也说过这样的话。
虽然我有些犹豫要不要说出来,不过有的分块也许的确能用那样的方式取得很好的结果,定好数据库Schema,以后就不再改了。
而同时其他的分块可以采用DDD项目的典型风格:
“好吧,我们现在了解得还不深,不过让我们先按目前的理解来做,随着我们了解加深,领域模型可以天天改,也一定会天天改!”
现在两种风格可以愉快地并存。以前肯定也有并存的情况,只不过现在明确了界限,成功机会提高了。
名字的来历
有人说任何值得讨论的事物都应该赋予一个名称,我当然不希望这种架构风格仅仅因为没有名称就失去讨论的资格。
那么“分块云计算(Chunk Cloud Computing)”是个好名称吗?争议肯定是少不了的,先放在一边,听我说一下来历吧。
在本届欧洲软件架构研讨会上,Christoffer Skjoldborg提了一个叫做“Chunk Cloud”的论题。“Chunk”就是一小片(分块),“Cloud”是现在的炒作题材。他的描述很接近我近来观察到的一种应用架构方式。(本文就是努力在描述这种架构方式。“强迫一种风格”小节尤其得自Chris的启发。)Chris描述的时候说得有点极端,不过我想主要是为了让他的观点流传开。
最后的“Computing”是研讨会上Nicklas Andersson(http://nickeandersson.blogs.com/)加上去的,大概是因为CCC看着比较酷吧。
最佳实践?
不知道你怎么样,我听到“最佳实践”的时候会警觉起来。可能是由于那些与Dreyfus模型[Dreyfus model of skill acquisition]相关的讨论,还由于见识到一些无视上下文的“最佳实践”……
我不认为“块云计算”是一种最佳实践。我只认为它是一种架构风格,而我经常发现适用这种风格的场合。但别忘了,要看情况。
新问题?
当然有了!可是你不觉得老问题没意思么?我知道这种风格有很多新问题,以后还会冒出更多(肯定的)。最多人提出来的两个问题是同样的数据出现在好几个地方,以及不同的分块之间有数据不一致的风险。这两个问题都必须解决,但请容我放到另一篇文章里。
还有一个经常提出的问题是“怎么做”,尤其是怎么将领域模型拆成几个小块。我会再找时间详谈。
更进一步的观察对此方向是肯定还是否定?
稳妥地说,两方面的观察(及观点)都有,我也期盼着看到您的想法!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号