NodeJS stream 一:Buffer
当年是看了朴灵的九浅一深 NodeJS 入门的 Node, 朴大大的书讲实践很少更多的篇幅用在了讲原理上,道理听了那么多,后来开始在前端工程领域使用 NodeJS 却处处掣肘,总结原因发现 NodeJS 中难的部分无非是文件和网络,文件操作和网络都依赖了一个很重要的对象—— Stream,这恰恰是朴大大书中没有提及的。
Buffer 朴大大在书中是有提到过的,但因为流实际上就是在处理 Buffer,所以还是要简单总结一下。
什么是 Buffer
如同官方 API 中介绍的那样,在 ES6 引入 TypedArray 之前,JavaScript 没有读取或者操作二进制数据流的机制。 Buffer 类作为 NodeJS API 的一部分被引入,以便能够和 TCP 等网络流和文件流等进行交互。
现在 TypedArray 已经被添加到了 ES6 中,Buffer 类以一种更优化和适用于 NodeJS 操作的方式实现了 Unit8Array API。
总而言之,Buffer 类是用来处理二进制数据,因为太常用了,所以直接放在了全局变量里,使用的时候无需 require。
Buffer 类的实例类似于整型数组,不过缓冲区的大小在创建时确定,不能调整。Buffer 对象不同之处在于它不经 V8 的内存分配机制,Buffer 是一个 JavaScript 和 C++ 结合的模块,内存由 C++ 申请,JavaScript 分配。
关于 Buffer 内存分配相关知识不展开讨论,感兴趣同学可以看看朴老湿的书。
实例化 Buffer
在 NodeJS v6 之前都是通过调用构造函数的方式实例化 Buffer,根据参数返回不同结果。处于安全性原因,这种方式在 v6 后的版本中已经被废除,提供了
- Buffer.from()
- Buffer.alloc()
- Buffer.allocUnsafe()
三个单独的,职责清晰的函数处理实例化 Buffer 的工作。
- Buffer.from(array):返回一个内容包含所提供的字节副本的 Buffer,数组中每一项是一个表示八位字节的数字,所以值必须在 0 ~ 255 之间,否则会取模
- Buffer.from(arrayBuffer):返回一个与给定的 ArrayBuffer 共享内存的新 Buffer
- Buffer.from(buffer):返回给定 Buffer 的一个副本 Buffer
- Buffer.from(string [, encoding]):返回一个包含给定字符串的 Buffer
- Buffer.alloc(size [, fill [, encoding]]):返回指定大小并且“已填充”的 Buffer
- Buffer.allocUnsafe(size):返回指定大小的 Buffer,内容必须用 buf.fill(0) 等方法填充
// 0x 表示 16 进制
Buffer.from([1, 2, 3]) // [0x1, 0x2, 0x3]
Buffer.from('test', 'utf-8') // [0x74, 0x65, 0x73, 0x74]
Buffer.alloc(5, 1) // [0x1, 0x1, 0x1, 0x1, 0x1]
Buffer.allocUnsafe(5); // 值不确定,后面详谈
Buffer.allocUnsafe() 的执行会快于 Buffer.alloc() 看名字很不安全,确实也不安全。
当调用 Buffer.allocUnsafe() 时分配的内存段尚未初始化(不归零),这样分配内存速度很块,但分配到的内存片段可能包含旧数据。如果在使用的时候不覆盖这些旧数据就可能造成内存泄露,虽然速度快,尽量避免使用。
编码
Buffer 支持以下几种编码格式
- ascii
- utf8
- utf16le
- base64
- binary
- hex
Buffer 和 String 转换
字符串转为 Buffer 比较简单
Buffer.from(string [, encoding])
同时 Buffer 实例也有 toString 方法将 Buffer 转为字符串
buf.toString([encoding[, start[, end]]])
Buffer 拼接
使用 concat 方法可以讲多个 Buffer 实例拼接为一个 Buffer 实例
Buffer.concat(list[, totalLength])
StringDecoder
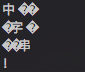
在 NodeJS 中一个汉字由三个字节表示,如果我们处理中文字符的时候使用了不是3的倍数的字节数就会造成字符拼接乱码问题。
const buf = Buffer.from('中文字符串!');
for(let i = 0; i < buf.length; i+=5){
var b = Buffer.allocUnsafe(5);
buf.copy(b, 0, i);
console.log(b.toString());
}
这样可以看到结果中出现了乱码
但如果使用 string_decoder 模块便可以解决这个问题
const StringDecoder = require('string_decoder').StringDecoder;
const decoder = new StringDecoder('utf8');
const buf = Buffer.from('中文字符串!');
for(let i = 0; i < buf.length; i+=5){
var b = Buffer.allocUnsafe(5);
buf.copy(b, 0, i);
console.log(decoder.write(b));
}
StringDecoder 在得到编码后,知道宽字节在utf-8下占3个字节,所以在处理末尾不全的字节时,会保留到第二次 write()。目前只能处理UTF-8、Base64 和 UCS-2/UTF-16LE。
Buffer 其它常用 API
还有一些 Buffer 常用的 API
- Buffer.isBuffer:判断对象是否为 Buffer
- Buffer.isEncoding:判断 Buffer 对象编码
- buf.length:返回 内存为此 Buffer 实例所申请的字节数,并不是 Buffer 实例内容的字节数
- buf.indexOf:和数组的 indexOf 类似,返回某字符串、acsii 码或者 buf 在改 buf 中的位置
- buf.copy:将一个 buf 的(部分)内容复制到另外一个 buf 中

 浙公网安备 33010602011771号
浙公网安备 33010602011771号