优化数据库结构
拆分表的思路是,把1个包含很多字段的表拆分成2个或者多个相对较小的表。这样做的原因是,这些表中某些字段的操作频率很高(热数据),经常要进行查询或者更新操作,
而另外一些字段的使用频率却很低(冷数据),冷热数据分离,可以减小表的宽度。如果放在一个表里面,每次查询都要读取大记录,会消耗较多的资源。
MySQL限制每个表最多存储4096列,并且每一行数据的大小不能超过65535字节。表越宽,把表装载进内存缓冲池时所占用的内存也就越大,也会消耗更多的IO。冷热数据分离的目的是:
①减少磁盘IO,保证热数据的内存缓存命中率。
②更有效的利用缓存,避免读入无用的冷数据。
对于需要经常联合查询的表,可以建立中间表以提高查询效率。通过建立中间表,把需要经常联合查询的数据插入中间表中,然后将原来的联合查询改为对中间表的查询,以此来提高查询效率。
首先,分析经常联合查询表中的字段;然后,使用这些字段建立一个中间表,并将原来联合查询的表的数据插入中间表中;最后,使用中间表来进行查询。
设计数据库表时应尽量遵循范式理论的规约,尽可能减少冗余字段,让数据库设计看起来精致、优雅。但是,合理地加入冗余字段可以提高查询速度。
表的规范化程度越高,表与表之间的关系就越多,需要连接查询的情况也就越多。尤其在数据量大,而且需要频繁进行连接的时候,为了提升效率,我们也可以考虑增加冗余字段来减少连接。
改进表的设计时,可以考虑优化字段的数据类型。这个问题在大家刚从事开发时基本不算是问题。但是,随着你的经验越来越丰富,参与的项目越来越大,数据量也越来越多的时候,
你就不能只从系统稳定性的角度来思考问题了,还要考虑到系统整体的稳定性和效率。此时,优先选择符合存储需要的最小的数据类型。
列的字段越大,建立索引时所需要的空间也就越大,这样一页中所能存储的索引节点的数量也就越少,在遍历时所需要的IO次数也就越多,索引的性能也就越差。
遇到整数类型的字段可以用INT型。这样做的理由是,INT型数据有足够大的取值范围,不用担心数据超出取值范围的问题。刚开始做项目的时候,首先要保证系统的稳定性,
这样设计字段类型是可以的。但在数据量很大的时候,数据类型的定义,在很大程度上会影响到系统整体的执行效率。
对于非负型的数据(如自增ID、整型IP)来说,要优先使用无符号整型UNSIGNED来存储。因为无符号相对于有符号,同样的字节数,存储的数值范围更大。如tinyint有符号为-128-127,
无符号为0-255,多出一倍的存储空间。
- 既可以使用文本类型也可以使用整数类型的字段,要选择使用整数类型
跟文本类型数据相比,大整数往往占用更少的存储空间,因此,在存取和比对的时候,可以占用更少的内存空间。所以,在二者皆可用的情况下,尽量使用整数类型,这样可以提高查询的效率。
如:将IP地址转换成整型数据。
MySQL内存临时表不支持TEXT、BLOB这样的大数据类型,如果查询中包含这样的数据,在排序等操作时,就不能使用内存临时表,必须使用磁盘临时表进行。并且对于这种数据,
MySQL还是要进行二次查询,会使SQL性能变得很差,但是不是说一定不能使用这样的数据类型。
如果一定要使用,建议把BLOB或是TEXT列分离到单独的扩展表中,查询时一定不要使用select*,而只需要取出必要的列,不需要TEXT列的数据时不要对该列进行查询。
修改ENUM值需要使用ALTER语句。
ENUM类型的ORDER BY操作效率低,需要额外操作。使用TINYINT来代替ENUM类型。
TIMESTAMP 存储的时间范围1970-01-01 00:00:01~2038-01-19-03:14:07。TIMESTAMP使用4字节,DATETIME使用8个字节,同时TIMESTAMP具有自动赋值以及自动更新的特性。
- 用DECIMAL代替FLOAT和DOUBLE存储精确浮点数
非精准浮点:float,double
精准浮点:decimal(不会丢失精度)
MyIDAM引擎
禁用索引
alter table table_name disable keys; # 禁用索引
alter table table_name denable keys; # 重新开启索引
禁用唯一性检查
set unique_checks = 0; # 禁用
set unique_checks = 1; # 启用
使用批量插入
使用LOAD DATA INFILE批量导入
InnoDB引擎
禁用唯一性检查
禁用外键检查
set foreign_key_checks=0; # 禁用
set foreign_key_checks=1; # 启用
禁止自动提交
set autocommit = 0; # 禁用
set autocommit = 1; # 启用
在设计字段的时候,如果业务允许,建议尽量使用非空约束。这样做的好处是:
进行比较和计算时,省去要对NULL值的字段判断是否为空的开销,提高存储效率。
非空字段也容易创建索引。因为索引NULL列需要额外的空间来保存,所以要占用更多的空间。使用非空约束,就可以节省存储空间(每个字段1个bit)
MySQL提供了分析表、检查表和优化表的语句。分析表主要是分析关键字的分布,检查表主要是检查表是否存在错误,优化表主要是消除删除或者更新造成的空间浪费。
# 分析表格式
ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name[,tbl_name]…
默认的,MySQL服务会将 ANALYZE TABLE语句写到binlog中,以便在主从架构中,从服务能够同步数据。可以添加参数LOCAL 或者
NO_WRITE_TO_BINLOG取消将语句写到binlog中。
使用 ANALYZE TABLE 分析表的过程中,数据库系统会自动对表加一个 只读锁 。在分析期间,只能读取表中的记录,不能更新和插入记录。
ANALYZE TABLE语句能够分析InnoDB和MyISAM类型的表,但是不能作用于视图
ANALYZE TABLE分析后的统计结果会反应到 cardinality 的值,该值统计了表中某一键所在的列不重复的值的个数。该值越接近表中的总行数,
则在表连接查询或者索引查询时,就越优先被优化器选择使用。也就是索引列的cardinality的值与表中数据的总条数差距越大,即使查询的时候使用了
该索引作为查询条件,存储引擎实际查询的时候使用的概率就越小。下面通过例子来验证下。cardinality可以通过SHOW INDEX FROM 表名查看
MySQL中可以使用 CHECK TABLE 语句来检查表。CHECK TABLE语句能够检查InnoDB和MyISAM类型的表是否存在错误。
CHECK TABLE语句在执行过程中也会给表加上 只读锁
对于MyISAM类型的表,CHECK TABLE语句还会更新关键字统计数据。而且,CHECK TABLE也可以检查视图是否有错误,
比如在视图定义中被引用的表已不存在。该语句的基本语法如下:
CHECK TABLE tbl_name [, tbl_name] ... [option] ...
option = {QUICK | FAST | MEDIUM | EXTENDED | CHANGED}
其中,tbl_name是表名;option参数有5个取值,分别是QUICK、FAST、MEDIUM、EXTENDED和CHANGED。各个选项的意义分别是:
QUICK :不扫描行,不检查错误的连接。
FAST :只检查没有被正确关闭的表。
CHANGED :只检查上次检查后被更改的表和没有被正确关闭的表。
MEDIUM :扫描行,以验证被删除的连接是有效的。也可以计算各行的关键字校验和,并使用计算出的校验和验证这一点。
EXTENDED :对每行的所有关键字进行一个全面的关键字查找。这可以确保表是100%一致的,但是花的时间较长。
option只对MyISAM类型的表有效,对InnoDB类型的表无效
方式1:OPTIMIZE TABLE
MySQL中使用 OPTIMIZE TABLE 语句来优化表。但是,OPTILMIZE TABLE语句只能优化表中的VARCHAR 、 BLOB 或 TEXT 类型的字段。
一个表使用了这些字段的数据类型,若已经 删除 了表的一大部分数据,或者已经对含有可变长度行的表(含有VARCHAR、BLOB或TEXT列的表)
进行了很多 更新 ,则应使用OPTIMIZE TABLE来重新利用未使用的空间,并整理数据文件的 碎片 。
OPTIMIZE TABLE 语句对InnoDB和MyISAM类型的表都有效。该语句在执行过程中也会给表加上 只读锁 。
OPTILMIZE TABLE语句的基本语法如下:
CHECK TABLE tbl_name [, tbl_name] ... [option] ...
option = {QUICK | FAST | MEDIUM | EXTENDED | CHANGED}
OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
LOCAL | NO_WRITE_TO_BINLOG关键字的意义和分析表相同,都是指定不写入二进制日志。
方式2:使用mysqlcheck命令
mysqlcheckl -o DatabaseName tablename -u root -p****
# 优化所有表
mysqlcheckl -o DatabaseName -u root -p****
# 写法2
mysqlcheckl -o --all-databases -u root -p****
# 创建表
CREATE TABLE `user1` (
`id` INT NOT NULL AUTO_INCREMENT,
`name` VARCHAR(255) DEFAULT NULL,
`age` INT DEFAULT NULL,
`sex` VARCHAR(255) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_name` (`name`) USING BTREE
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb3;
# 设置允许创建存储函数
SET GLOBAL log_bin_trust_function_creators = 1;
# 创建存储函数
DELIMITER //
CREATE FUNCTION rand_num (from_num INT ,to_num INT) RETURNS INT(11)
BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(from_num +RAND()*(to_num - from_num+1)) ;
RETURN i;
END //
DELIMITER ;
# 创建存储过程
DELIMITER //
CREATE PROCEDURE insert_user( max_num INT )
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO `user1` ( NAME,age,sex )
VALUES ("atguigu",rand_num(1,20),"male");
UNTIL i = max_num
END REPEAT;
COMMIT;
END //
DELIMITER;
# 插入数据
CALL insert_user(1000);
# 查看索引
SHOW INDEX FROM user1;
# 查看数据
SELECT * FROM user1;
# 更新1条数据
UPDATE user1 SET NAME = 'atguigu03' WHERE id = 3;
# 分析表
ANALYZE TABLE user1;
# 检查表
CHECK TABLE user1;
# 优化表
# 创建t1表
CREATE TABLE t1(id INT,NAME VARCHAR(15)) ENGINE = MYISAM;
OPTIMIZE TABLE t1;
# 创建t2表并优化
CREATE TABLE t2(id INT,NAME VARCHAR(15)) ENGINE = INNODB;
OPTIMIZE TABLE t2;
大表优化
禁止不带任何限制数据范围条件的查询语句。比如:我们当用户在查询订单历史的时候,我们可以控制在一个月的范围内;
经典的数据库拆分方案,主库负责写,从库负责读。
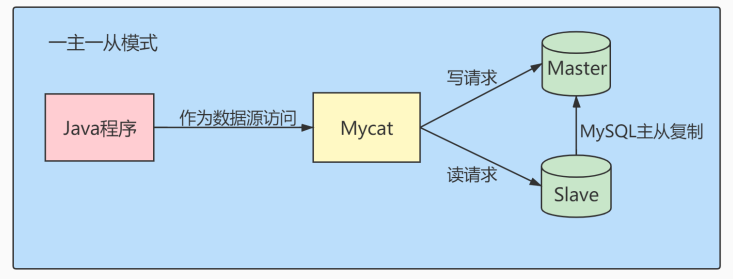
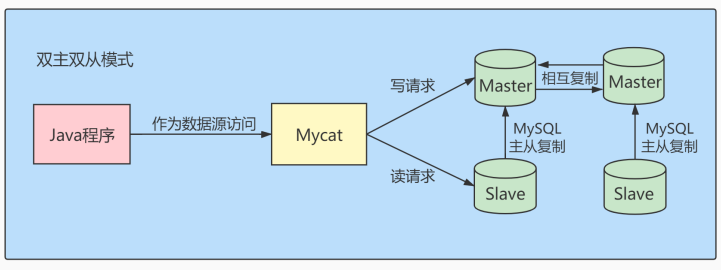
当数据量级达到 千万级 以上时,有时候我们需要把一个数据库切成多份,放到不同的数据库服务器上,减少对单一数据库服务器的访问压力
垂直拆分的优点: 可以使得列数据变小,在查询时减少读取的Block数,减少I/O次数。此外,垂直分区可以简化表的结构,易于维护
垂直拆分的缺点: 主键会出现冗余,需要管理冗余列,并会引起 JOIN 操作。此外,垂直拆分会让事务变得更加复杂
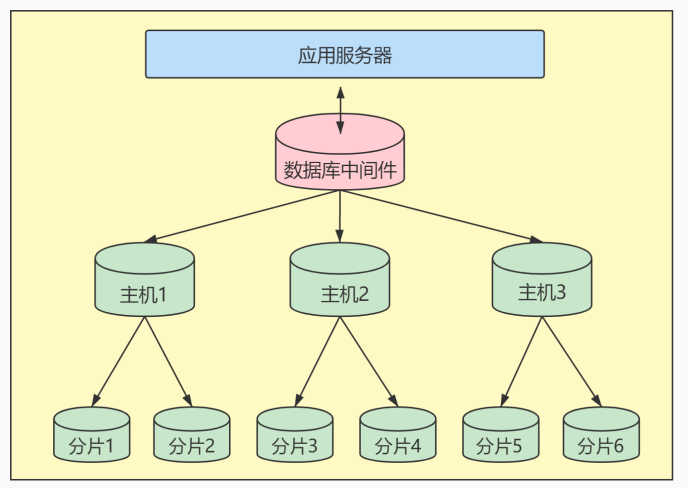
尽量控制单表数据量的大小,建议控制在1000万以内。1000万并不是MySQL数据库的限制,过大会造成修改表结构、备份、恢复都会有很大的问题。此时可以用历史数据归档(应用于日志数据),
水平分表(应用于业务数据)等手段来控制数据量大小。
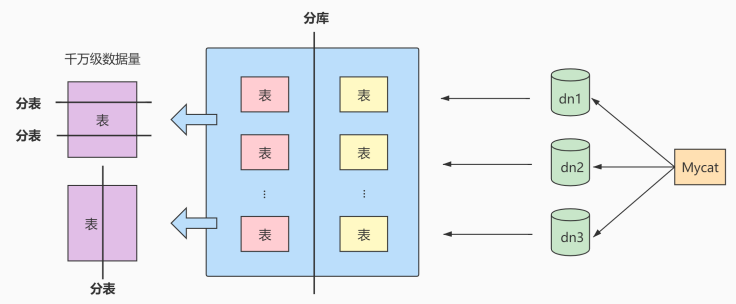
这里我们主要考虑业务数据的水平分表策略。将大的数据表按照某个属性维度分拆成不同的小表,每张小表保持相同的表结构。比如你可以按照年份来划分,把不同年份的数据放到不同的数据表中。
2017年、2018年和2019年的数据就可以分别放到三张数据表中。水平分表仅是解决了单一表数据过大的问题,但由于表的数据还是在同一台机器上,其实对于提升MySQL并发
在MySQL 8.0中可以设置 服务器语句超时的限制 ,单位可以达到 毫秒级别 。当中断的执行语句超过设置的毫秒数后,服务器将终止查询影响不大的事务或连接,然后将错误报给客户端。
设置服务器语句超时的限制,可以通过设置系统变量 MAX_EXECUTION_TIME 来实现。默认情况下,MAX_EXECUTION_TIME的值为0,代表没有时间限制。 例如:
SET GLOBAL MAX_EXECUTION_TIME=2000;
SET SESSION MAX_EXECUTION_TIME=2000; # 指定该会话中SELECT语句的超时时间
# 创建表空间
CREATE TABLESPACE atguigu1 ADD DATAFILE 'atguigu1.ibd' file_block_size=16k;
# 创建表时指定表空间
CREATE TABLE test(id INT,NAME VARCHAR(10)) ENGINE=INNODB DEFAULT CHARSET utf8mb4 TABLESPACE atguigu1;
# 修改表的表空间
ALTER TABLE test TABLESPACE atguigu1;
# 删除表空间
DROP TABLESPACE atguigu1;
# 删除表
DROP TABLE test;
不可见索引的特性对于性能调试非常有用。在MySQL8.0中,索引可以被“隐藏”和“显示”。当一个索引被隐藏时, 它不会被查询优化器所使用。也就是说,管理员可以隐藏一个索引,
然后观察对数据库的影响。如果数据库性能有所下降,就说明这个索引是有用的,于是将其“恢复显示”即可;如果数据库性能看不出变化,就说明这个索引是多余的,可以删掉了。
需要注意的是当索引被隐藏时,它的内容仍然是和正常索引一样实时更新的。如果一个索引需要长期被隐藏,那么可以将其删除,因为索引的存在会影响插入、更新和删除的性能。
数据表中的主键不能被设置为invisible。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号