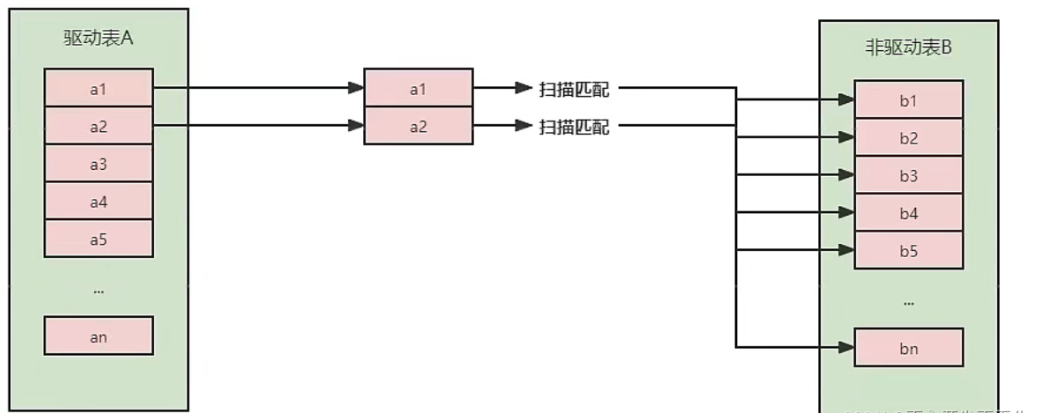
- Simple Nested-Loop Join(简单嵌套循环连接)
从表A中取出一条数据1,遍历表B,将匹配到的数据放到result…以此类推,驱动表A中的每一条记录与被驱动表B的记录进行判断
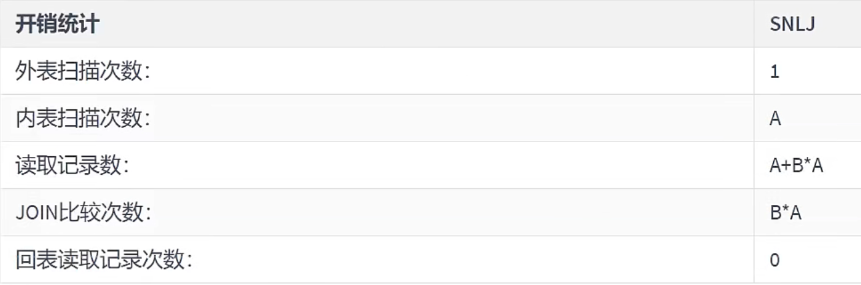
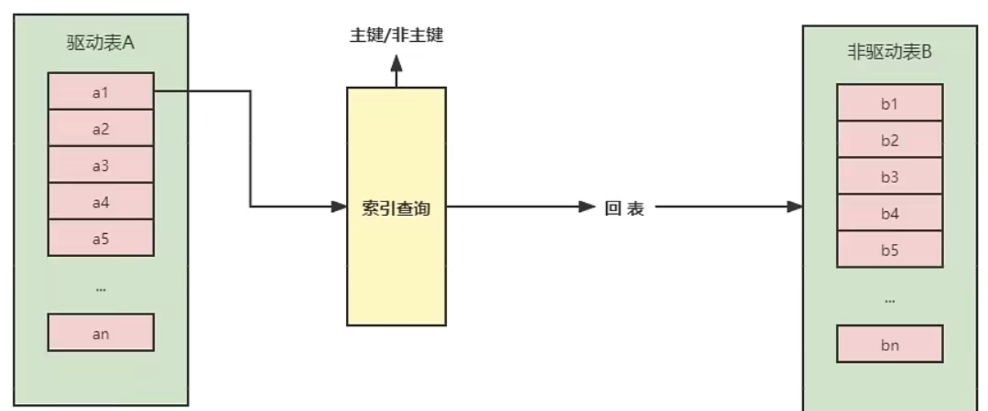
- Index Nested-Loop Join(索引嵌套循环连接)
Index Nested-Loop Join其优化的思路主要是为了减少内层表数据的匹配次数,所以要求被驱动表上必须有索引才行。
通过外层表匹配条件直接与内层表索引进行匹配,避免和内层表的每条记录去进行比较,这样极大的减少了对内层表的匹配次数。
驱动表中的每条记录通过被驱动表的索引进行访问,因为索引查询的成本是比较固定的,故mysql优化器都倾向于使用记录数少的表作为驱动表(外表)

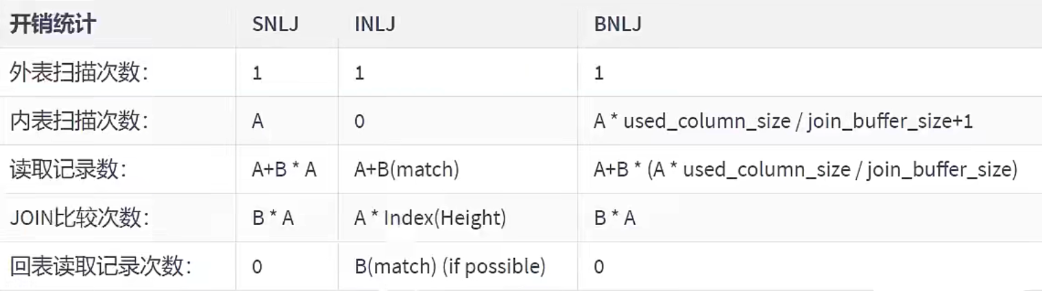
- Block Nested-Loop Join(块嵌套循环连接)
如果存在索引,那么会使用index的方式进行join,,如果join的列没有索引,被驱动表要扫描的次数太多了。每次访问被驱动表,
其表中的记录都会被加载到内存中,“然后再从驱动表中取一条与其匹配,匹配结束后清除内存,然后再从驱动表中加载一条记录,
然后把被驱动表的记录在加载到内存匹配,这样周而复始,大大增加了Io的次数。为了减少被驱动表的IO次数,就出现了
Block Nested-Loop Join的方式。
不再是逐条获取驱动表的数据,而是一块一块的获取,引入了join buffer缓冲区,将驱动表join相关的部分数据列(大小受join buffer的限制)
缓存到join buffer中,然后全表扫描被驱动表,被驱动表的每一条记录一次性和joinbuffer中的所有驱动表记录进行匹配(内存中操作),
将简单嵌套循环中的多次比较合并成一次,降低了被驱动表的访问频率
- 查看block_nested_loop状态,默认为开启
show variables like '%optimizer_switch%'
1、整体效率比较:INLJ>BNLJ>SNLL
2、永远用小结果集驱动大结果集(其本质就是减少外层循环的数据数量,小的度量单位指的是表行数*每行大小)
3、为被驱动表匹配的条件增加索引(减少内层表的循环匹配次数)
4、增大join buffer size的大小(一次缓存的数据越多,那么内层包的扫表次数就越少)
5、减少驱动表不必要的字段查询(字段越少,join buffer所缓存的数据就越多)
从MySQL8.0.18开始,默认使用hash join,8.0.2废弃Block Nested-Loop Join
hash join是做大数据几连接时常用的方式,优化器使用2个表中较小是表利用join key再内存中建立散列表,然后扫描较大的表并探测散列表,
找出与hash表匹配的行
# 创建t2表
CREATE TABLE `t2` (
`id` INT(11) NOT NULL,
`a` INT(11) DEFAULT NULL,
`b` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`),
INDEX `a` (`a`)
) ENGINE=INNODB;
# 向t2表中插入1000条数据
DELIMITER //
CREATE PROCEDURE idata()
BEGIN
DECLARE i INT;
SET i=1;
WHILE(i<=1000)DO
INSERT INTO t2 VALUES(i, i, i);
SET i=i+1;
END WHILE;
END //
DELIMITER ;
# 调用存储函数
CALL idata();
# 创建t1表并复制t1表中前100条数据
CREATE TABLE t1
AS
SELECT * FROM t2
WHERE id <= 100;
# 测试表数据
SELECT COUNT(*) FROM t1;
SELECT COUNT(*) FROM t2;
#查看索引
SHOW INDEX FROM t2;
SHOW INDEX FROM t1;
# 测试
EXPLAIN SELECT * FROM t1 STRAIGHT_JOIN t2 ON (t1.a=t2.a);
EXPLAIN SELECT * FROM t1 STRAIGHT_JOIN t2 ON (t1.a=t2.b);
select t1.b,t2.* from t1 straight_join t2 on (t1.b=t2.b) where t2.id<=100; # 推荐,小结果集驱动大结果集
select t1.b,t2.* from t2 straight_join t1 on (t1.b=t2.b) where t2.id<=100; # 不推荐

 浙公网安备 33010602011771号
浙公网安备 33010602011771号